 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Molecular Graph Explanations with Chemical Identity via InChIfied Invariants
May 23, 2026Obtaining consistent explanations for machine learning on molecular graphs requires predictions and attributions to be aligned with chemical identity. However, chemically equivalent drawings of the same molecule can induce different molecular representations, leading to inconsistent predictions and explanations. Here, we introduce InChIfied Invariants, a class of node, edge, and graph features based on the International Chemical Identifier (InChI) and designed to be invariant under transformations that preserve chemical identity. Using one million molecular graphs from PubChem Substances, we show that InChIfied Invariants produce identical representations for chemically equivalent graphs in 99.62% of cases, whereas standard Daylight invariants do so in only 0.35% of cases. Across MoleculeNet tasks, InChIfied Invariants preserve predictive performance while significantly improving prediction consistency across alternative graph depictions of the same molecules. We further perform a quantitative attribution analysis and show that explanations produced with standard molecular featurization methods vary substantially across chemically equivalent graphs, while InChIfied Invariants enforce consistent attributions by construction. We release open-source software implementing InChIfied Invariants, which can be used as a drop-in replacement for standard molecular graph features.
An Explainable Probabilistic Classifier for Categorical Data Inspired to Quantum Physics
May 26, 2021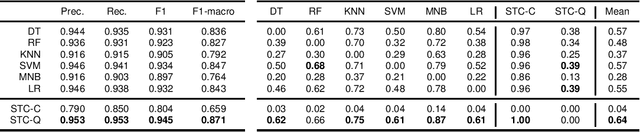

This paper presents Sparse Tensor Classifier (STC), a supervised classification algorithm for categorical data inspired by the notion of superposition of states in quantum physics. By regarding an observation as a superposition of features, we introduce the concept of wave-particle duality in machine learning and propose a generalized framework that unifies the classical and the quantum probability. We show that STC possesses a wide range of desirable properties not available in most other machine learning methods but it is at the same time exceptionally easy to comprehend and use. Empirical evaluation of STC on structured data and text classification demonstrates that our methodology achieves state-of-the-art performances compared to both standard classifiers and deep learning, at the additional benefit of requiring minimal data pre-processing and hyper-parameter tuning. Moreover, STC provides a native explanation of its predictions both for single instances and for each target label globally.