 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolve routing problems with a residual edge-graph attention neural network
Paper and Code
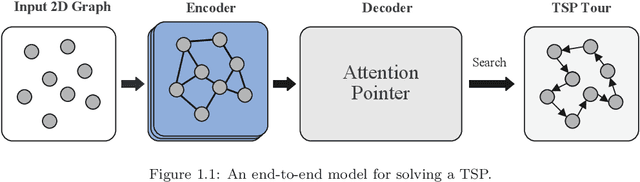
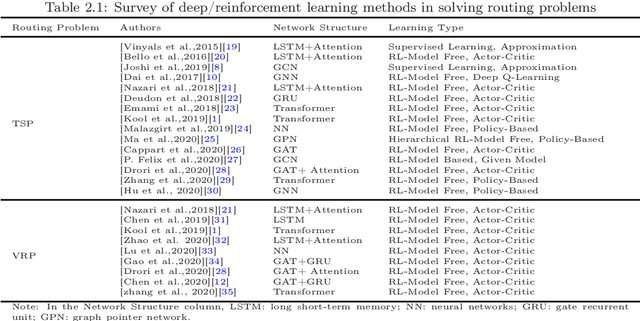
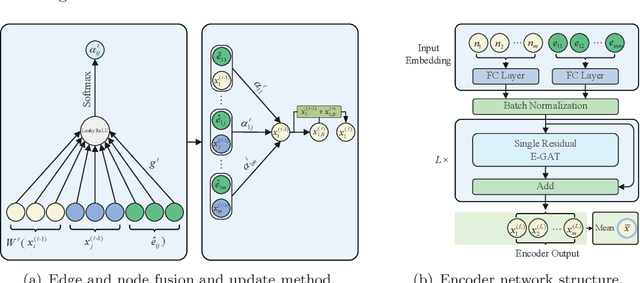
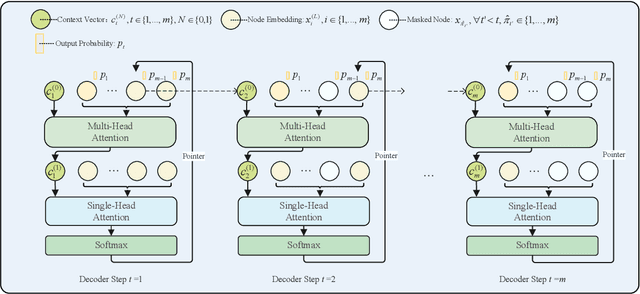
For NP-hard combinatorial optimization problems, it is usually difficult to find high-quality solutions in polynomial time. The design of either an exact algorithm or an approximate algorithm for these problems often requires significantly specialized knowledge. Recently, deep learning methods provide new directions to solve such problems. In this paper, an end-to-end deep reinforcement learning framework is proposed to solve this type of combinatorial optimization problems. This framework can be applied to different problems with only slight changes of input (for example, for a traveling salesman problem (TSP), the input is the two-dimensional coordinates of nodes; while for a capacity-constrained vehicle routing problem (CVRP), the input is simply changed to three-dimensional vectors including the two-dimensional coordinates and the customer demands of nodes), masks and decoder context vectors. The proposed framework is aiming to improve the models in literacy in terms of the neural network model and the training algorithm. The solution quality of TSP and the CVRP up to 100 nodes are significantly improved via our framework. Specifically, the average optimality gap is reduced from 4.53\% (reported best \cite{R22}) to 3.67\% for TSP with 100 nodes and from 7.34\% (reported best \cite{R22}) to 6.68\% for CVRP with 100 nodes when using the greedy decoding strategy. Furthermore, our framework uses about 1/3$\sim$3/4 training samples compared with other existing learning methods while achieving better results. The results performed on randomly generated instances and the benchmark instances from TSPLIB and CVRPLIB confirm that our framework has a linear running time on the problem size (number of nodes) during the testing phase, and has a good generalization performance from random instance training to real-world instance testing.