 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving the Accuracy of Early Exits in Multi-Exit Architectures via Curriculum Learning
Apr 22, 2021
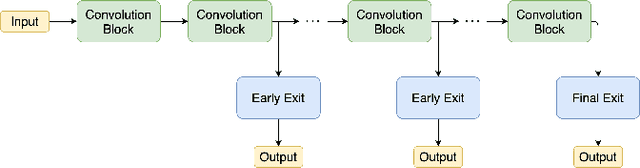
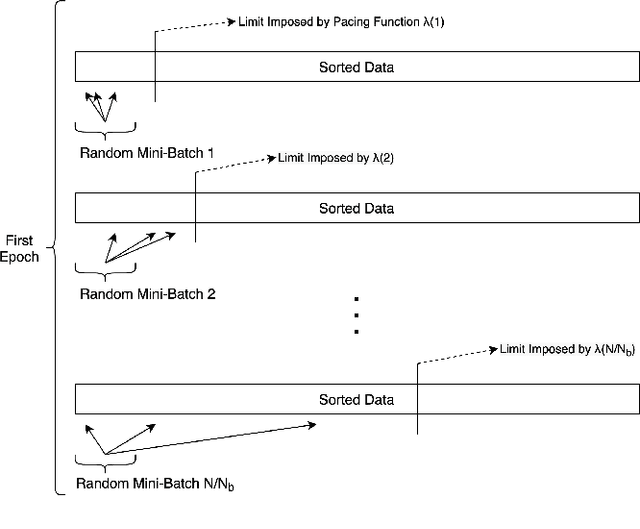


Deploying deep learning services for time-sensitive and resource-constrained settings such as IoT using edge computing systems is a challenging task that requires dynamic adjustment of inference time. Multi-exit architectures allow deep neural networks to terminate their execution early in order to adhere to tight deadlines at the cost of accuracy. To mitigate this cost, in this paper we introduce a novel method called Multi-Exit Curriculum Learning that utilizes curriculum learning, a training strategy for neural networks that imitates human learning by sorting the training samples based on their difficulty and gradually introducing them to the network. Experiments on CIFAR-10 and CIFAR-100 datasets and various configurations of multi-exit architectures show that our method consistently improves the accuracy of early exits compared to the standard training approach.
Decision-making Oriented Clustering: Application to Pricing and Power Consumption Scheduling
Jun 02, 2021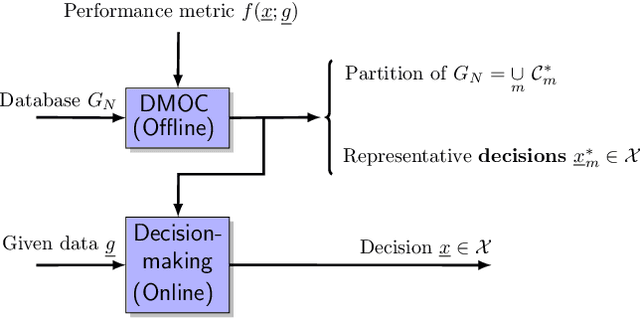
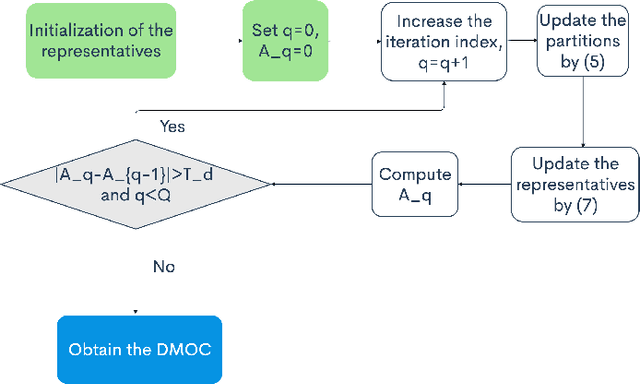
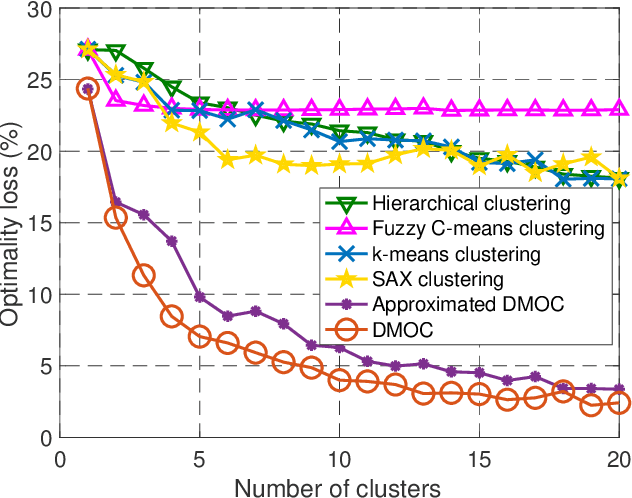
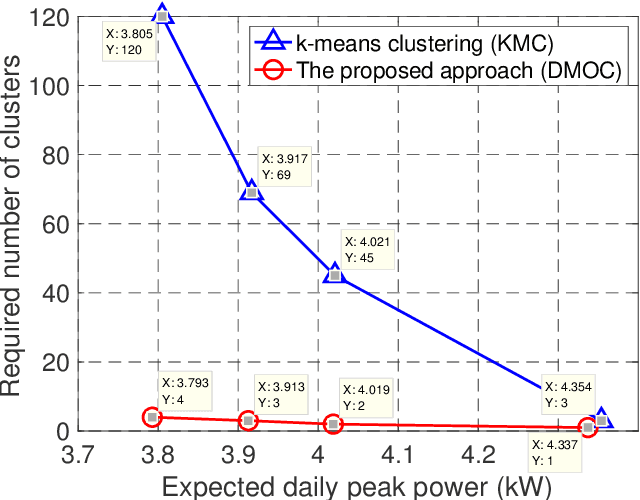
Data clustering is an instrumental tool in the area of energy resource management. One problem with conventional clustering is that it does not take the final use of the clustered data into account, which may lead to a very suboptimal use of energy or computational resources. When clustered data are used by a decision-making entity, it turns out that significant gains can be obtained by tailoring the clustering scheme to the final task performed by the decision-making entity. The key to having good final performance is to automatically extract the important attributes of the data space that are inherently relevant to the subsequent decision-making entity, and partition the data space based on these attributes instead of partitioning the data space based on predefined conventional metrics. For this purpose, we formulate the framework of decision-making oriented clustering and propose an algorithm providing a decision-based partition of the data space and good representative decisions. By applying this novel framework and algorithm to a typical problem of real-time pricing and that of power consumption scheduling, we obtain several insightful analytical results such as the expression of the best representative price profiles for real-time pricing and a very significant reduction in terms of required clusters to perform power consumption scheduling as shown by our simulations.
* Published in Applied Energy
BEHAVIOR: Benchmark for Everyday Household Activities in Virtual, Interactive, and Ecological Environments
Aug 06, 2021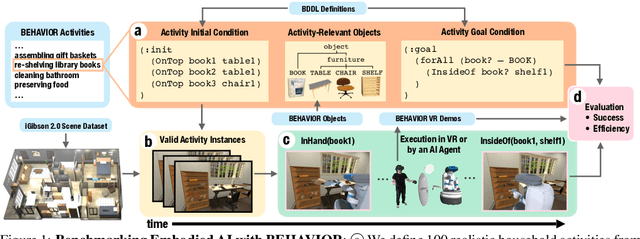
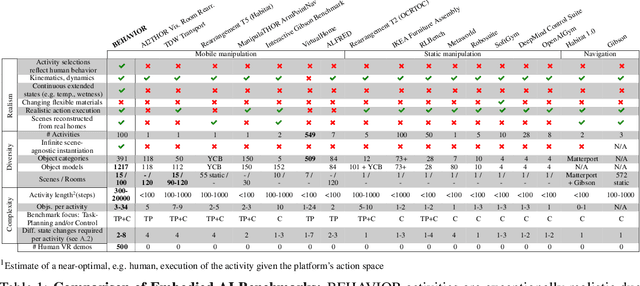

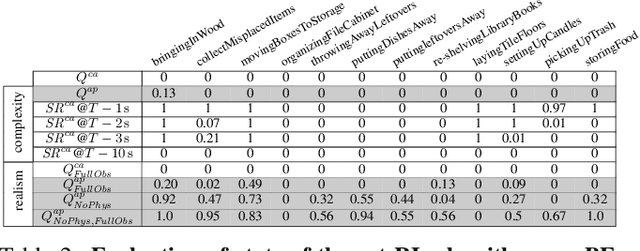
We introduce BEHAVIOR, a benchmark for embodied AI with 100 activities in simulation, spanning a range of everyday household chores such as cleaning, maintenance, and food preparation. These activities are designed to be realistic, diverse, and complex, aiming to reproduce the challenges that agents must face in the real world. Building such a benchmark poses three fundamental difficulties for each activity: definition (it can differ by time, place, or person), instantiation in a simulator, and evaluation. BEHAVIOR addresses these with three innovations. First, we propose an object-centric, predicate logic-based description language for expressing an activity's initial and goal conditions, enabling generation of diverse instances for any activity. Second, we identify the simulator-agnostic features required by an underlying environment to support BEHAVIOR, and demonstrate its realization in one such simulator. Third, we introduce a set of metrics to measure task progress and efficiency, absolute and relative to human demonstrators. We include 500 human demonstrations in virtual reality (VR) to serve as the human ground truth. Our experiments demonstrate that even state of the art embodied AI solutions struggle with the level of realism, diversity, and complexity imposed by the activities in our benchmark. We make BEHAVIOR publicly available at behavior.stanford.edu to facilitate and calibrate the development of new embodied AI solutions.
How Self-Supervised Learning Can be Used for Fine-Grained Head Pose Estimation?
Aug 12, 2021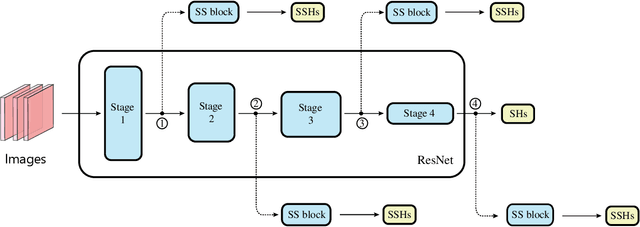
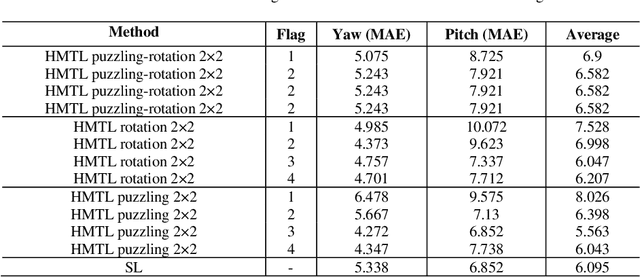
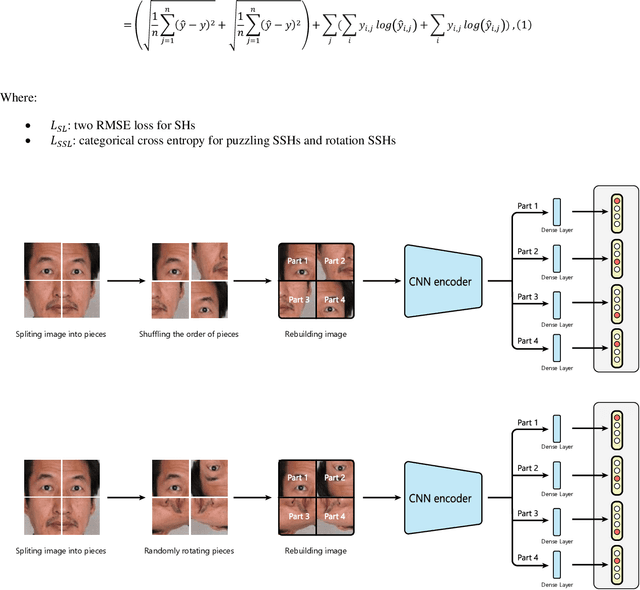

Recent progress of Self-Supervised Learning (SSL) demonstrates the capability of these methods in computer vision field. However, this progress could not show any promises for fine-grained tasks such as Head Pose estimation. In this article, we have tried to answer a question: How SSL can be used for Head Pose estimation? In general, there are two main approaches to use SSL: 1. Using pre-trained weights which can be done via weights pre-training on ImageNet or via SSL tasks. 2. Leveraging SSL as an auxiliary co-training task besides of Supervised Learning (SL) tasks at the same time. In this study, modified versions of jigsaw puzzling and rotation as SSL pre-text tasks are used and the best architecture for our proposed Hybrid Multi-Task Learning (HMTL) is found. Finally, the HopeNet method as a baseline is selected and the impact of SSL pre-training and ImageNet pre-training on both HMTL and SL are compared. The error rate reduced by the HTML method up to 11% compare to the SL. Moreover, HMTL method showed that it was good with all kinds of initial weights: random, ImageNet and SSL pre-training weights. Also, it was observed, when puzzled images are used for SL alone, the average error rate placed between SL and HMTL which showed the importance of local spatial features compare to global spatial features.
Fed-TGAN: Federated Learning Framework for Synthesizing Tabular Data
Aug 18, 2021
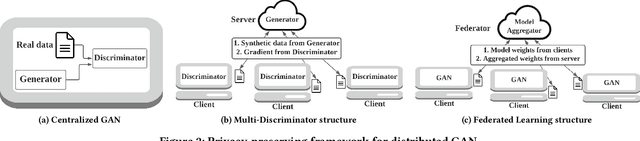
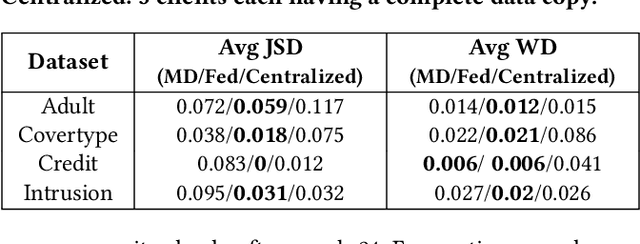
Generative Adversarial Networks (GANs) are typically trained to synthesize data, from images and more recently tabular data, under the assumption of directly accessible training data. Recently, federated learning (FL) is an emerging paradigm that features decentralized learning on client's local data with a privacy-preserving capability. And, while learning GANs to synthesize images on FL systems has just been demonstrated, it is unknown if GANs for tabular data can be learned from decentralized data sources. Moreover, it remains unclear which distributed architecture suits them best. Different from image GANs, state-of-the-art tabular GANs require prior knowledge on the data distribution of each (discrete and continuous) column to agree on a common encoding -- risking privacy guarantees. In this paper, we propose Fed-TGAN, the first Federated learning framework for Tabular GANs. To effectively learn a complex tabular GAN on non-identical participants, Fed-TGAN designs two novel features: (i) a privacy-preserving multi-source feature encoding for model initialization; and (ii) table similarity aware weighting strategies to aggregate local models for countering data skew. We extensively evaluate the proposed Fed-TGAN against variants of decentralized learning architectures on four widely used datasets. Results show that Fed-TGAN accelerates training time per epoch up to 200% compared to the alternative architectures, for both IID and Non-IID data. Overall, Fed-TGAN not only stabilizes the training loss, but also achieves better similarity between generated and original data.
Hand-Object Contact Consistency Reasoning for Human Grasps Generation
Apr 07, 2021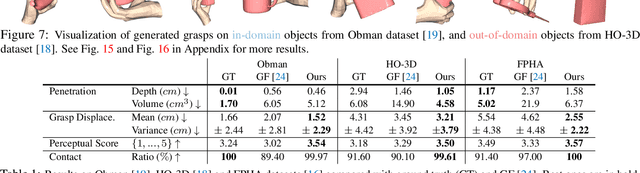
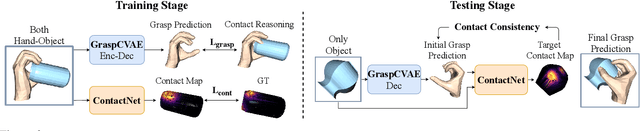

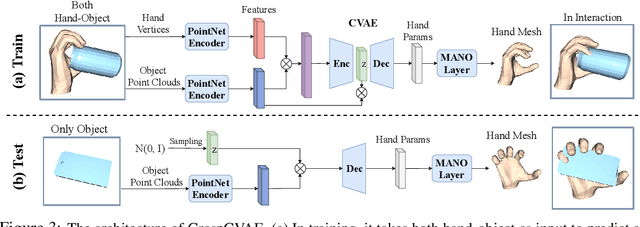
While predicting robot grasps with parallel jaw grippers have been well studied and widely applied in robot manipulation tasks, the study on natural human grasp generation with a multi-finger hand remains a very challenging problem. In this paper, we propose to generate human grasps given a 3D object in the world. Our key observation is that it is crucial to model the consistency between the hand contact points and object contact regions. That is, we encourage the prior hand contact points to be close to the object surface and the object common contact regions to be touched by the hand at the same time. Based on the hand-object contact consistency, we design novel objectives in training the human grasp generation model and also a new self-supervised task which allows the grasp generation network to be adjusted even during test time. Our experiments show significant improvement in human grasp generation over state-of-the-art approaches by a large margin. More interestingly, by optimizing the model during test time with the self-supervised task, it helps achieve larger gain on unseen and out-of-domain objects. Project page: https://hwjiang1510.github.io/GraspTTA/
Single-shot structured illumination microscopy
Jul 13, 2021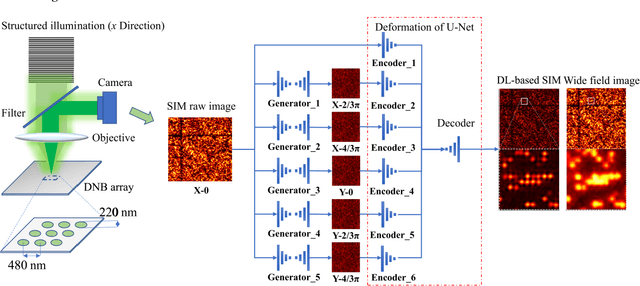



Structured illumination microscopy (SIM) can double the resolution beyond the light diffraction limit, but it comes at the cost of multiple camera exposures and the heavy computation burden of multiple Fourier transforms. In this paper, we report a novel technique termed single-shot SIM, to overcome these limitations. A multi-task joint deep-learning strategy is proposed. Generative adversative networks (GAN) are employed to generate five structured illumination images based on the single-shot structured illumination image. U-Net is employed to reconstruct the super-resolution image from these six generated images without time-consuming Fourier transform. By imaging a self-assembling DNB array, we experimentally verified that this technique could perform single-shot super-resolution reconstruction comparing favorably with conventional SIM. This single-shot SIM technique may ultimately overcome the limitations of multiple exposures and Fourier transforms and is potentially applied for high-throughput gene sequencing.
RLTutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions
Jul 31, 2021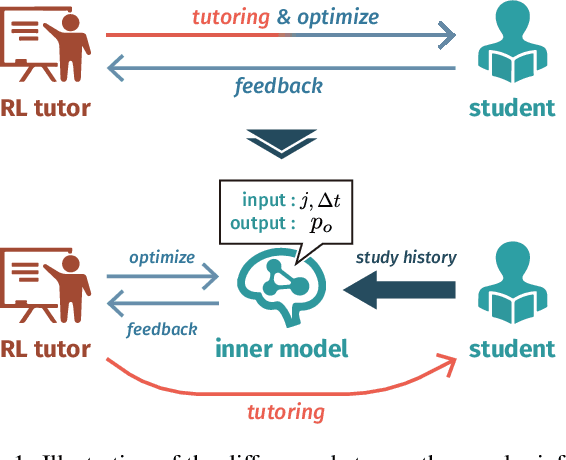
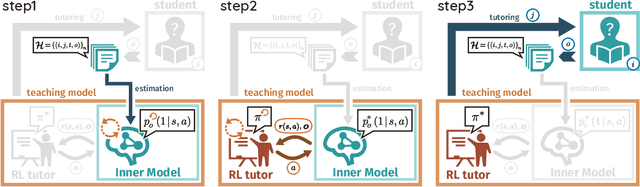
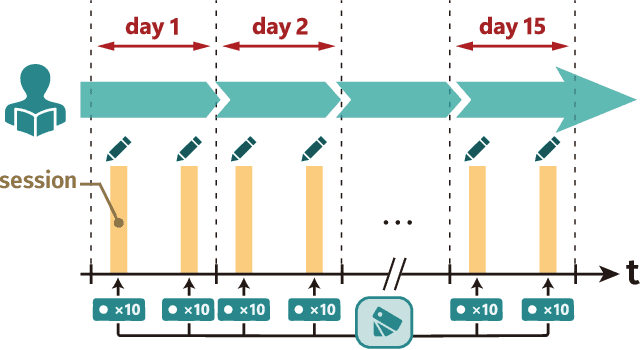
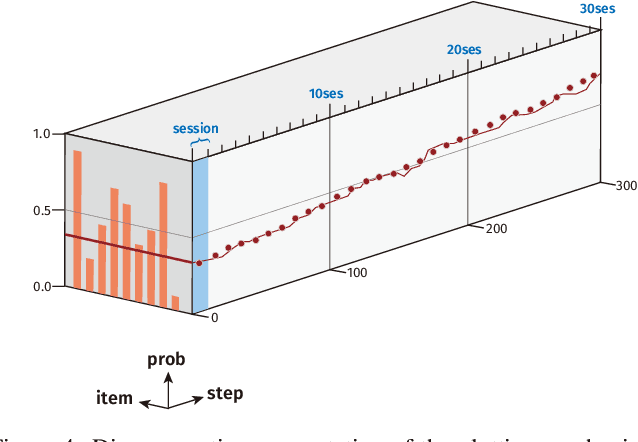
A major challenge in the field of education is providing review schedules that present learned items at appropriate intervals to each student so that memory is retained over time. In recent years, attempts have been made to formulate item reviews as sequential decision-making problems to realize adaptive instruction based on the knowledge state of students. It has been reported previously that reinforcement learning can help realize mathematical models of students learning strategies to maintain a high memory rate. However, optimization using reinforcement learning requires a large number of interactions, and thus it cannot be applied directly to actual students. In this study, we propose a framework for optimizing teaching strategies by constructing a virtual model of the student while minimizing the interaction with the actual teaching target. In addition, we conducted an experiment considering actual instructions using the mathematical model and confirmed that the model performance is comparable to that of conventional teaching methods. Our framework can directly substitute mathematical models used in experiments with human students, and our results can serve as a buffer between theoretical instructional optimization and practical applications in e-learning systems.
CCC/Code 8.7: Applying AI in the Fight Against Modern Slavery
Jun 24, 2021On any given day, tens of millions of people find themselves trapped in instances of modern slavery. The terms "human trafficking," "trafficking in persons," and "modern slavery" are sometimes used interchangeably to refer to both sex trafficking and forced labor. Human trafficking occurs when a trafficker compels someone to provide labor or services through the use of force, fraud, and/or coercion. The wide range of stakeholders in human trafficking presents major challenges. Direct stakeholders are law enforcement, NGOs and INGOs, businesses, local/planning government authorities, and survivors. Viewed from a very high level, all stakeholders share in a rich network of interactions that produce and consume enormous amounts of information. The problems of making efficient use of such information for the purposes of fighting trafficking while at the same time adhering to community standards of privacy and ethics are formidable. At the same time they help us, technologies that increase surveillance of populations can also undermine basic human rights. In early March 2020, the Computing Community Consortium (CCC), in collaboration with the Code 8.7 Initiative, brought together over fifty members of the computing research community along with anti-slavery practitioners and survivors to lay out a research roadmap. The primary goal was to explore ways in which long-range research in artificial intelligence (AI) could be applied to the fight against human trafficking. Building on the kickoff Code 8.7 conference held at the headquarters of the United Nations in February 2019, the focus for this workshop was to link the ambitious goals outlined in the A 20-Year Community Roadmap for Artificial Intelligence Research in the US (AI Roadmap) to challenges vital in achieving the UN's Sustainable Development Goal Target 8.7, the elimination of modern slavery.
Drowsiness Detection Based On Driver Temporal Behavior Using a New Developed Dataset
Mar 31, 2021

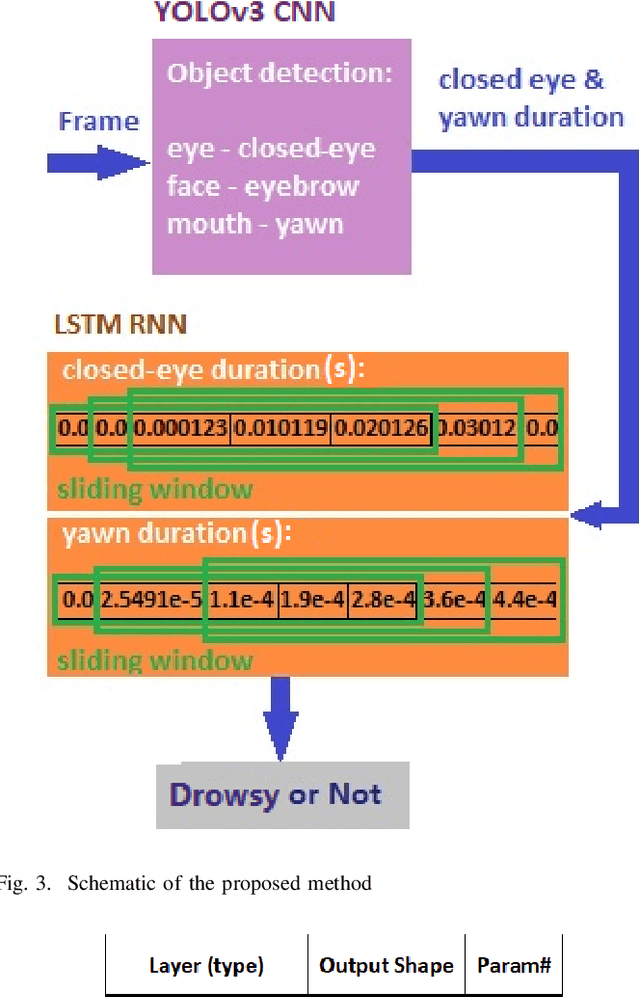
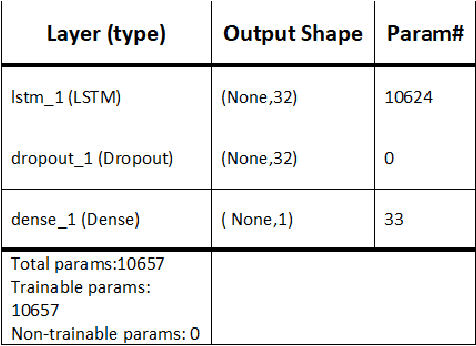
Driver drowsiness detection has been the subject of many researches in the past few decades and various methods have been developed to detect it. In this study, as an image-based approach with adequate accuracy, along with the expedite process, we applied YOLOv3 (You Look Only Once-version3) CNN (Convolutional Neural Network) for extracting facial features automatically. Then, LSTM (Long-Short Term Memory) neural network is employed to learn driver temporal behaviors including yawning and blinking time period as well as sequence classification. To train YOLOv3, we utilized our collected dataset alongside the transfer learning method. Moreover, the dataset for the LSTM training process is produced by the mentioned CNN and is formatted as a two-dimensional sequence comprised of eye blinking and yawning time durations. The developed dataset considers both disturbances such as illumination and drivers' head posture. To have real-time experiments a multi-thread framework is developed to run both CNN and LSTM in parallel. Finally, results indicate the hybrid of CNN and LSTM ability in drowsiness detection and the effectiveness of the proposed method.