 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomizing an Affective Tutoring System Based on Facial Expression and Head Pose Estimation
Nov 21, 2021



In recent years, the main problem in e-learning has shifted from analyzing content to personalization of learning environment by Intelligence Tutoring Systems (ITSs). Therefore, by designing personalized teaching models, learners are able to have a successful and satisfying experience in achieving their learning goals. Affective Tutoring Systems (ATSs) are some kinds of ITS that can recognize and respond to affective states of learner. In this study, we designed, implemented, and evaluated a system to personalize the learning environment based on the facial emotions recognition, head pose estimation, and cognitive style of learners. First, a unit called Intelligent Analyzer (AI) created which was responsible for recognizing facial expression and head angles of learners. Next, the ATS was built which mainly made of two units: ITS, IA. Results indicated that with the ATS, participants needed less efforts to pass the tests. In other words, we observed when the IA unit was activated, learners could pass the final tests in fewer attempts than those for whom the IA unit was deactivated. Additionally, they showed an improvement in terms of the mean passing score and academic satisfaction.
How Self-Supervised Learning Can be Used for Fine-Grained Head Pose Estimation?
Aug 13, 2021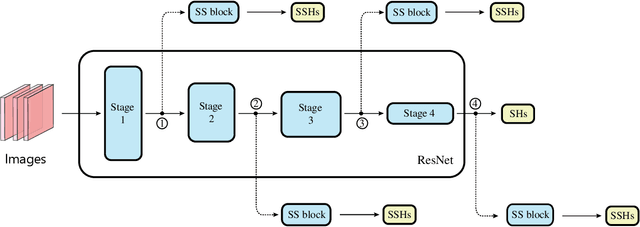
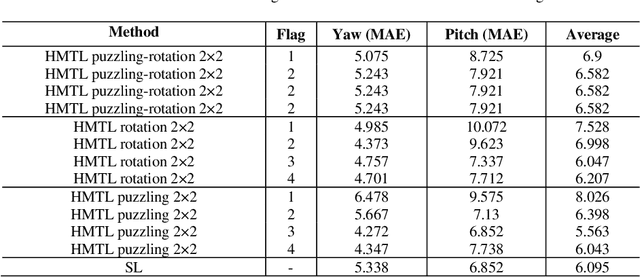
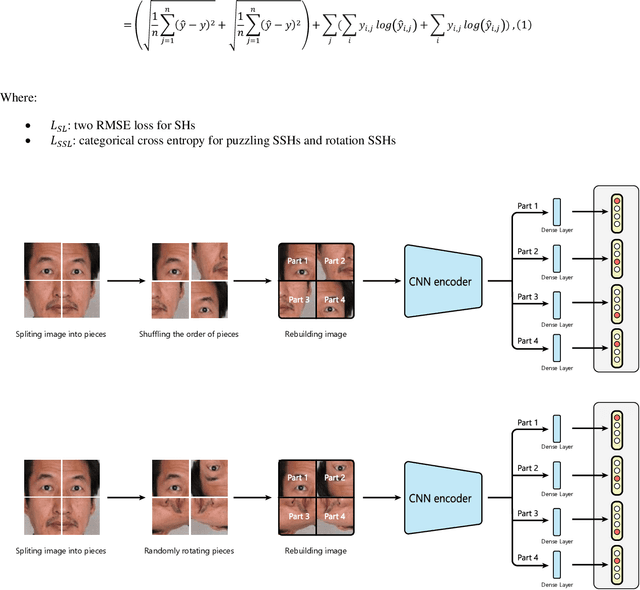

Recent progress of Self-Supervised Learning (SSL) demonstrates the capability of these methods in computer vision field. However, this progress could not show any promises for fine-grained tasks such as Head Pose estimation. In this article, we have tried to answer a question: How SSL can be used for Head Pose estimation? In general, there are two main approaches to use SSL: (1) Using pre-trained weights which can be done via SSL tasks, (2) Leveraging SSL as an auxiliary co-training task besides of Supervised Learning (SL) tasks at the same time. In this study, modified versions of jigsaw puzzling and rotation as SSL pre-text tasks are used and the best architecture for our proposed Hybrid Multi-Task Learning (HMTL) is found. Finally, the HopeNet method as a baseline SL is selected and the impact of SSL pre-training and ImageNet pre-training on both HMTL and SL are compared. The error rate reduced by the HMTL method up to 13% compare to the SL. Moreover, HMTL method showed that it was good with all kinds of initial weights: random, ImageNet and SSL pre-training weights. Also, it was observed, when puzzled images are used for SL alone, the average error rate placed between SL and HMTL, showed the importance of local spatial features compare to global spatial features.
Using Self-Supervised Co-Training to Improve Facial Representation
May 13, 2021
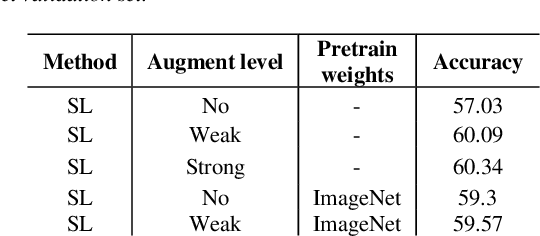
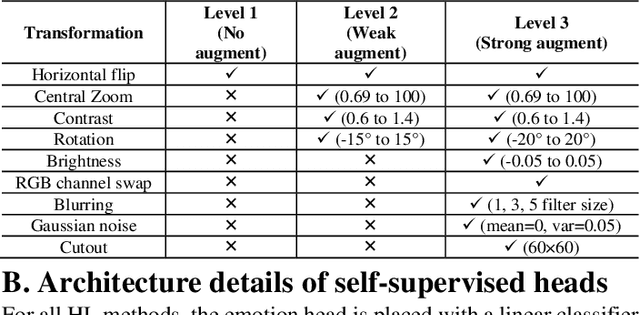
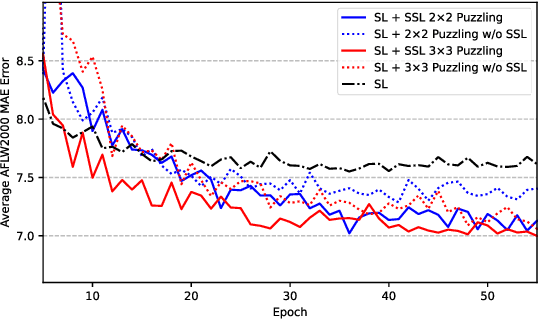
In this paper, at first, the impact of ImageNet pre-training on Facial Expression Recognition (FER) was tested under different augmentation levels. It could be seen from the results that training from scratch could reach better performance compared to ImageNet fine-tuning at stronger augmentation levels. After that, a framework was proposed for standard Supervised Learning (SL), called Hybrid Learning (HL) which used Self-Supervised co-training with SL in Multi-Task Learning (MTL) manner. Leveraging Self-Supervised Learning (SSL) could gain additional information from input data like spatial information from faces which helped the main SL task. It is been investigated how this method could be used for FER problems with self-supervised pre-tasks such as Jigsaw puzzling and in-painting. The supervised head (SH) was helped by these two methods to lower the error rate under different augmentations and low data regime in the same training settings. The state-of-the-art was reached on AffectNet via two completely different HL methods, without utilizing additional datasets. Moreover, HL's effect was shown on two different facial-related problem, head poses estimation and gender recognition, which concluded to reduce in error rate by up to 9% and 1% respectively. Also, we saw that the HL methods prevented the model from reaching overfitting.