 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Grounding Spatio-Temporal Language with Transformers
Jun 16, 2021
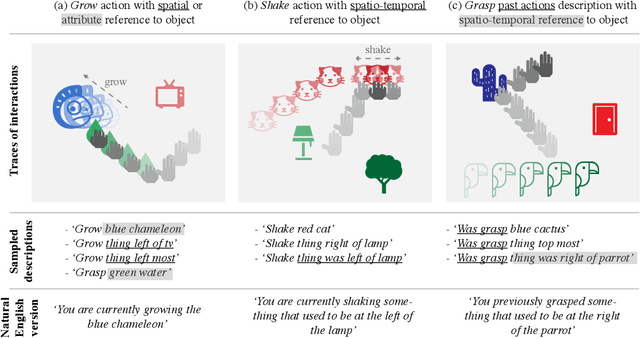
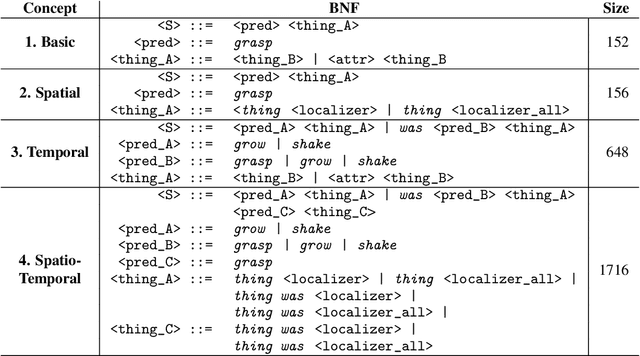
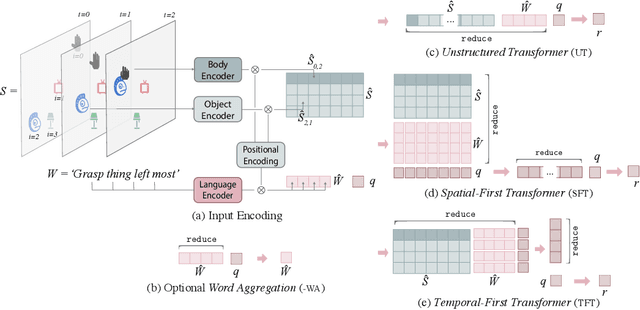
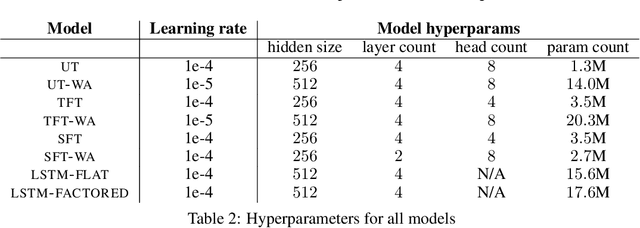
Language is an interface to the outside world. In order for embodied agents to use it, language must be grounded in other, sensorimotor modalities. While there is an extended literature studying how machines can learn grounded language, the topic of how to learn spatio-temporal linguistic concepts is still largely uncharted. To make progress in this direction, we here introduce a novel spatio-temporal language grounding task where the goal is to learn the meaning of spatio-temporal descriptions of behavioral traces of an embodied agent. This is achieved by training a truth function that predicts if a description matches a given history of observations. The descriptions involve time-extended predicates in past and present tense as well as spatio-temporal references to objects in the scene. To study the role of architectural biases in this task, we train several models including multimodal Transformer architectures; the latter implement different attention computations between words and objects across space and time. We test models on two classes of generalization: 1) generalization to randomly held-out sentences; 2) generalization to grammar primitives. We observe that maintaining object identity in the attention computation of our Transformers is instrumental to achieving good performance on generalization overall, and that summarizing object traces in a single token has little influence on performance. We then discuss how this opens new perspectives for language-guided autonomous embodied agents. We also release our code under open-source license as well as pretrained models and datasets to encourage the wider community to build upon and extend our work in the future.
Anomaly Detection Based on Multiple-Hypothesis Autoencoder
Jul 07, 2021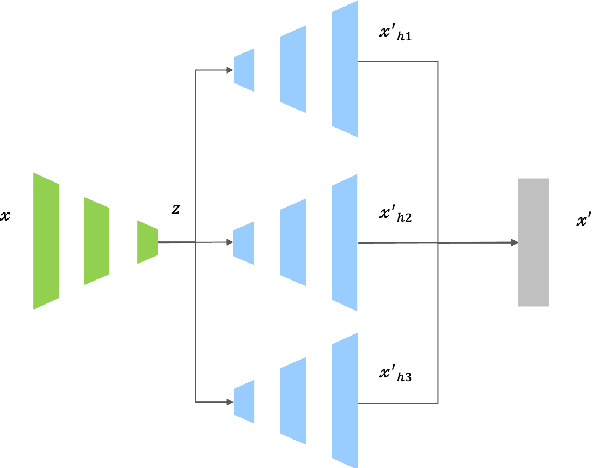
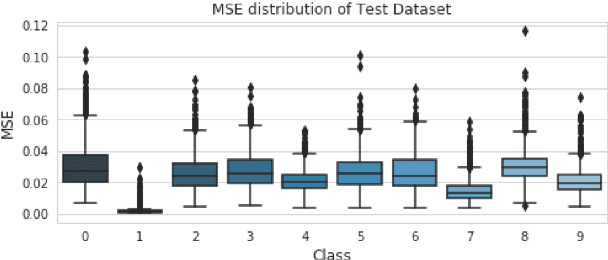

Recently Autoencoder(AE) based models are widely used in the field of anomaly detection. A model trained with normal data generates a larger restoration error for abnormal data. Whether or not abnormal data is determined by observing the restoration error. It takes a lot of cost and time to obtain abnormal data in the industrial field. Therefore the model trains only normal data and detects abnormal data in the inference phase. However, the restoration area for the input data of AE is limited in the latent space. To solve this problem, we propose Multiple-hypothesis Autoencoder(MH-AE) model composed of several decoders. MH-AE model increases the restoration area through contention between decoders. The proposed method shows that the anomaly detection performance is improved compared to the traditional AE for various input datasets.
Context-Conditional Adaptation for Recognizing Unseen Classes in Unseen Domains
Jul 15, 2021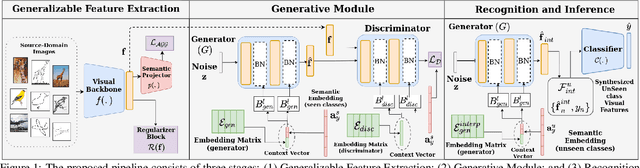
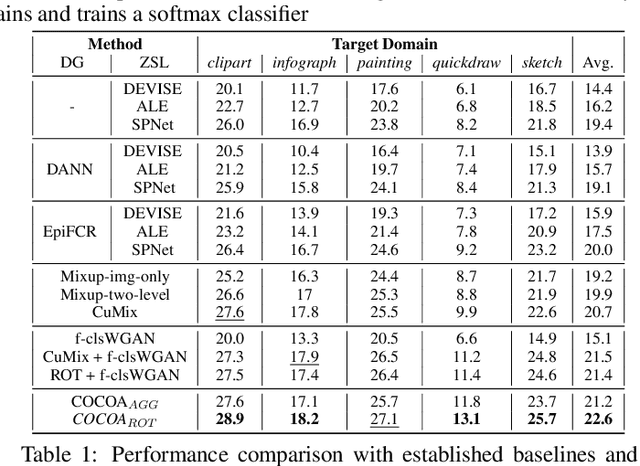
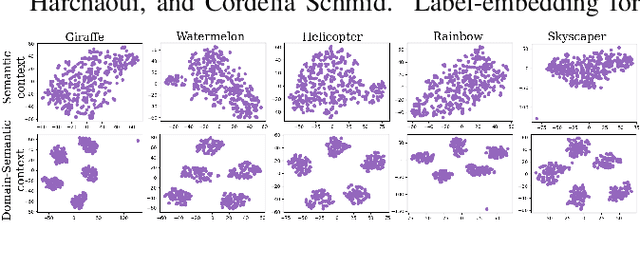
Recent progress towards designing models that can generalize to unseen domains (i.e domain generalization) or unseen classes (i.e zero-shot learning) has embarked interest towards building models that can tackle both domain-shift and semantic shift simultaneously (i.e zero-shot domain generalization). For models to generalize to unseen classes in unseen domains, it is crucial to learn feature representation that preserves class-level (domain-invariant) as well as domain-specific information. Motivated from the success of generative zero-shot approaches, we propose a feature generative framework integrated with a COntext COnditional Adaptive (COCOA) Batch-Normalization to seamlessly integrate class-level semantic and domain-specific information. The generated visual features better capture the underlying data distribution enabling us to generalize to unseen classes and domains at test-time. We thoroughly evaluate and analyse our approach on established large-scale benchmark - DomainNet and demonstrate promising performance over baselines and state-of-art methods.
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction
Aug 09, 2021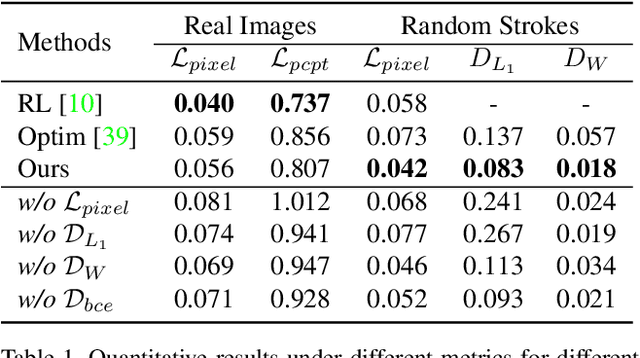
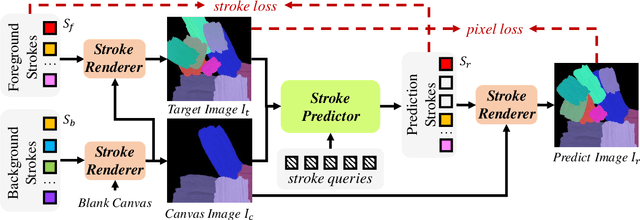
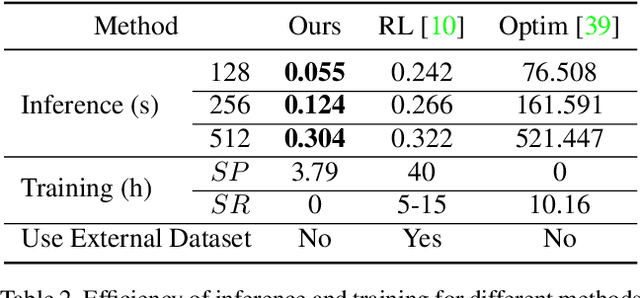
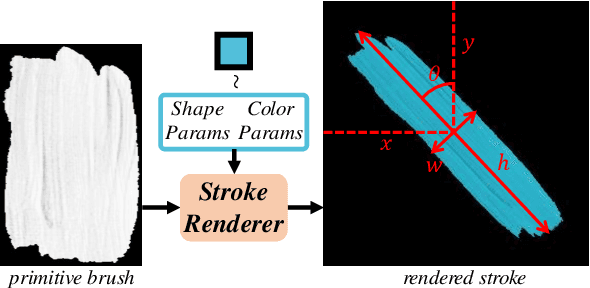
Neural painting refers to the procedure of producing a series of strokes for a given image and non-photo-realistically recreating it using neural networks. While reinforcement learning (RL) based agents can generate a stroke sequence step by step for this task, it is not easy to train a stable RL agent. On the other hand, stroke optimization methods search for a set of stroke parameters iteratively in a large search space; such low efficiency significantly limits their prevalence and practicality. Different from previous methods, in this paper, we formulate the task as a set prediction problem and propose a novel Transformer-based framework, dubbed Paint Transformer, to predict the parameters of a stroke set with a feed forward network. This way, our model can generate a set of strokes in parallel and obtain the final painting of size 512 * 512 in near real time. More importantly, since there is no dataset available for training the Paint Transformer, we devise a self-training pipeline such that it can be trained without any off-the-shelf dataset while still achieving excellent generalization capability. Experiments demonstrate that our method achieves better painting performance than previous ones with cheaper training and inference costs. Codes and models are available.
Latency-Constrained Highly-Reliable mmWave Communication via Multi-point Connectivity
Aug 20, 2021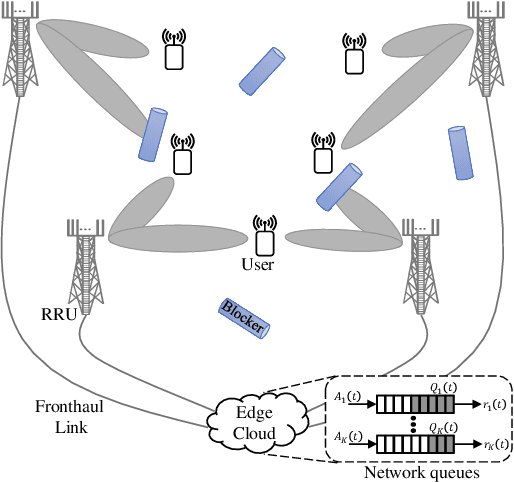
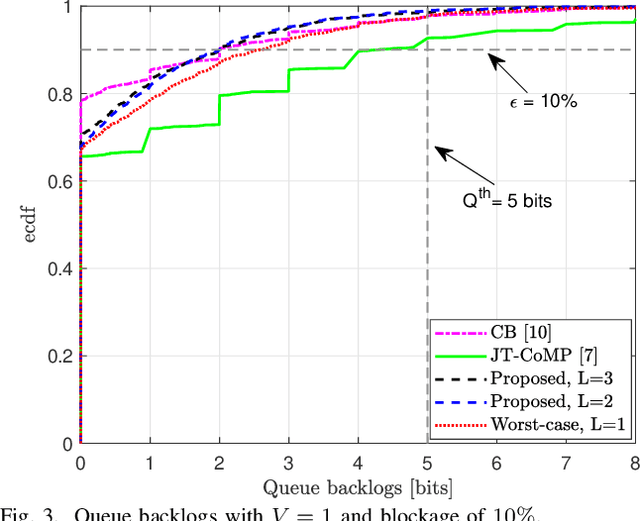
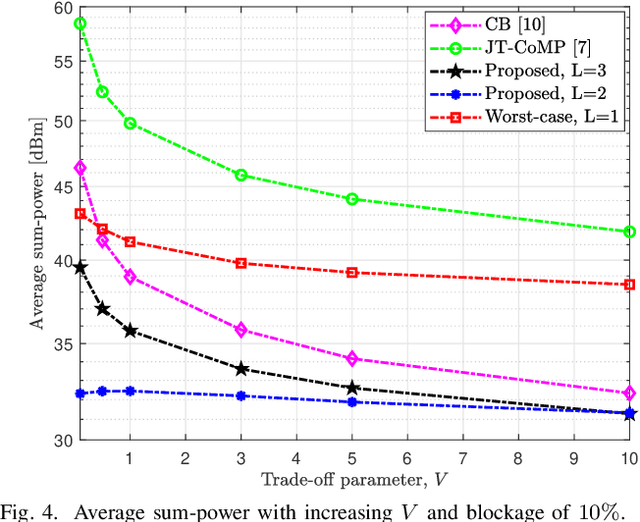
The sensitivity of millimeter-wave (mmWave) radio channel to blockage is a fundamental challenge in achieving low-latency and ultra-reliable connectivity. In this paper, we explore the viability of using coordinated multi-point (CoMP) transmission for a delay bounded and reliable mmWave communication. We propose a novel blockage-aware algorithm for the sum-power minimization problem under the user-specific latency requirements in a dynamic mobile access network. We use the Lyapunov optimization framework, and provide a dynamic control algorithm, which efficiently transforms a time-average stochastic problem into a sequence of deterministic subproblems. A robust beamformer design is then proposed by exploiting the queue backlogs and channel information, that efficiently allocates the required radio and cooperation resources, and proactively leverages the multi-antenna spatial diversity according to the instantaneous needs of the users. Further, to adapt to the uncertainties of the mmWave channel, we consider a pessimistic estimate of the rates over link blockage combinations and an adaptive selection of the CoMP serving set from the available remote radio units (RRUs). Moreover, after the relaxation of coupled and non-convex constraints via the Fractional Program (FP) techniques, a low-complexity closed-form iterative algorithm is provided by solving a system of Karush-Kuhn-Tucker (KKT) optimality conditions. The simulation results manifest that, in the presence of random blockages, the proposed methods outperform the baseline scenarios and provide power-efficient, high-reliable, and low-latency mmWave communication.
Pseudo Relevance Feedback with Deep Language Models and Dense Retrievers: Successes and Pitfalls
Aug 25, 2021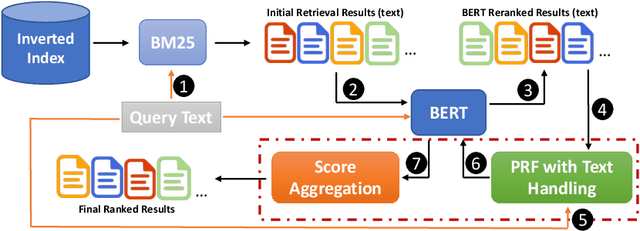
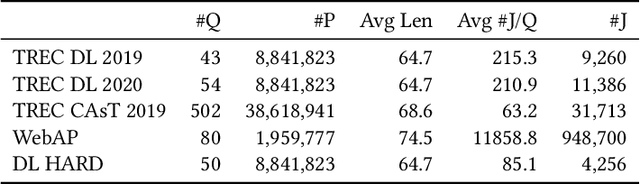
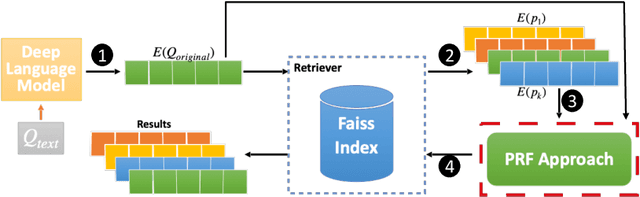
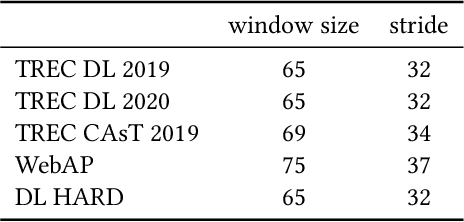
Pseudo Relevance Feedback (PRF) is known to improve the effectiveness of bag-of-words retrievers. At the same time, deep language models have been shown to outperform traditional bag-of-words rerankers. However, it is unclear how to integrate PRF directly with emergent deep language models. In this article, we address this gap by investigating methods for integrating PRF signals into rerankers and dense retrievers based on deep language models. We consider text-based and vector-based PRF approaches, and investigate different ways of combining and scoring relevance signals. An extensive empirical evaluation was conducted across four different datasets and two task settings (retrieval and ranking). Text-based PRF results show that the use of PRF had a mixed effect on deep rerankers across different datasets. We found that the best effectiveness was achieved when (i) directly concatenating each PRF passage with the query, searching with the new set of queries, and then aggregating the scores; (ii) using Borda to aggregate scores from PRF runs. Vector-based PRF results show that the use of PRF enhanced the effectiveness of deep rerankers and dense retrievers over several evaluation metrics. We found that higher effectiveness was achieved when (i) the query retains either the majority or the same weight within the PRF mechanism, and (ii) a shallower PRF signal (i.e., a smaller number of top-ranked passages) was employed, rather than a deeper signal. Our vector-based PRF method is computationally efficient; thus this represents a general PRF method others can use with deep rerankers and dense retrievers.
ZeLiC and ZeChipC: Time Series Interpolation Methods for Lebesgue or Event-based Sampling
Jun 06, 2019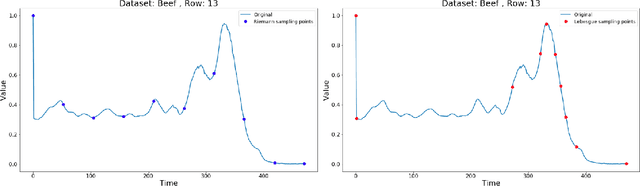
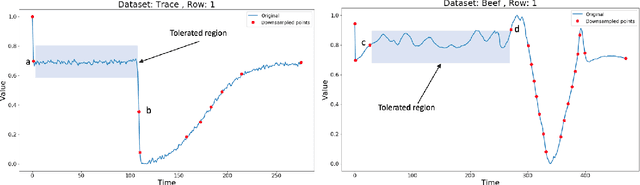
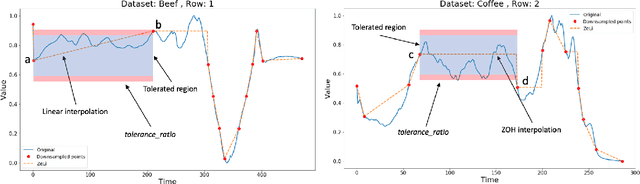
Lebesgue sampling is based on collecting information depending on the values of the signal. Although the interpolation methods for periodic sampling have been a topic of research for a long time, there is a lack of study in methods capable of taking advantage of the Lebesgue sampling characteristics to reconstruct time series more accurately. Indeed, Lebesgue sampling contains additional information about the shape of the signal in-between two sampled points. Using this information would allow us to generate an interpolated signal closer to the original one. That is to say, the average distance between the interpolated signal and the original signal will be smaller than a signal interpolated with other interpolation methods. In this paper, we propose two novel time series interpolation methods specifically designed for Lebesgue sampling called ZeLiC and ZeChipC. ZeLiC is an algorithm that combines both Zero-order hold interpolation and Linear interpolation to reconstruct time series. ZeChipC is a similar idea, it is a combination of Zero-order hold and PCHIP interpolation. Zero-order hold interpolation is favourable for interpolating abrupt changes while Linear and PCHIP interpolation are more suitable for smooth transitions. In order to apply one method or the other, we have introduced a new concept called tolerated region. ZeLiC and ZeChipC include a new functionality to adapt the reconstructed signal to concave/convex regions. The proposed methods have been compared with the state-of-the-art interpolation methods using Lebesgue sampling and have offered higher average performance. Additionally, we have compared the performance of the methods using both Riemann and Lebesgue sampling using an approximate number of sampled points. The performance of the combination "Lebesgue sampling with ZeChipC interpolation method" is clearly much better than any other combination.
MERLOT: Multimodal Neural Script Knowledge Models
Jun 04, 2021
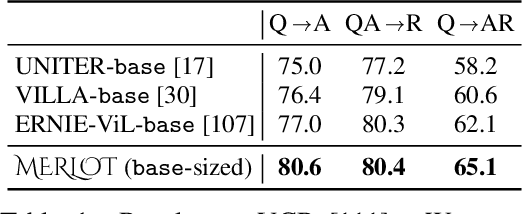
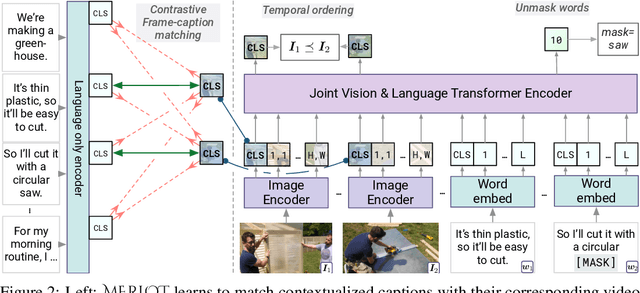
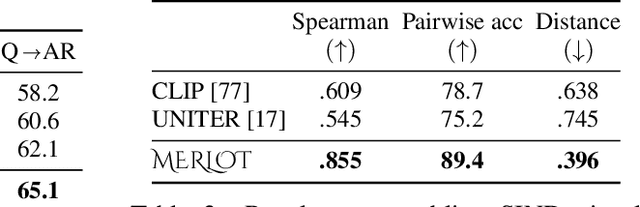
As humans, we understand events in the visual world contextually, performing multimodal reasoning across time to make inferences about the past, present, and future. We introduce MERLOT, a model that learns multimodal script knowledge by watching millions of YouTube videos with transcribed speech -- in an entirely label-free, self-supervised manner. By pretraining with a mix of both frame-level (spatial) and video-level (temporal) objectives, our model not only learns to match images to temporally corresponding words, but also to contextualize what is happening globally over time. As a result, MERLOT exhibits strong out-of-the-box representations of temporal commonsense, and achieves state-of-the-art performance on 12 different video QA datasets when finetuned. It also transfers well to the world of static images, allowing models to reason about the dynamic context behind visual scenes. On Visual Commonsense Reasoning, MERLOT answers questions correctly with 80.6% accuracy, outperforming state-of-the-art models of similar size by over 3%, even those that make heavy use of auxiliary supervised data (like object bounding boxes). Ablation analyses demonstrate the complementary importance of: 1) training on videos versus static images; 2) scaling the magnitude and diversity of the pretraining video corpus; and 3) using diverse objectives that encourage full-stack multimodal reasoning, from the recognition to cognition level.
Move2Hear: Active Audio-Visual Source Separation
May 15, 2021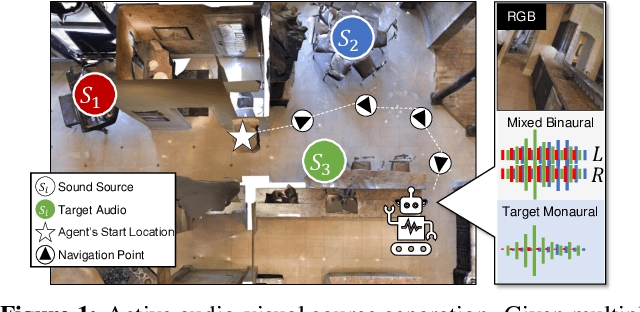
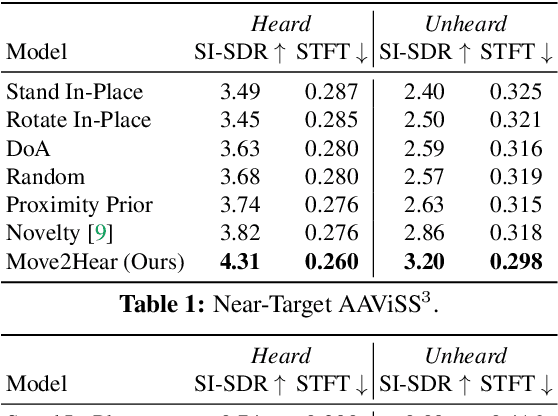
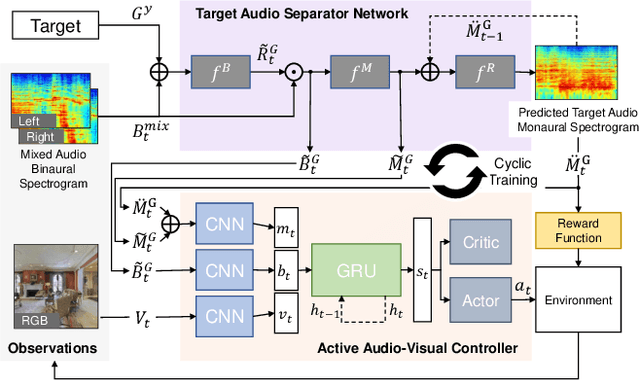
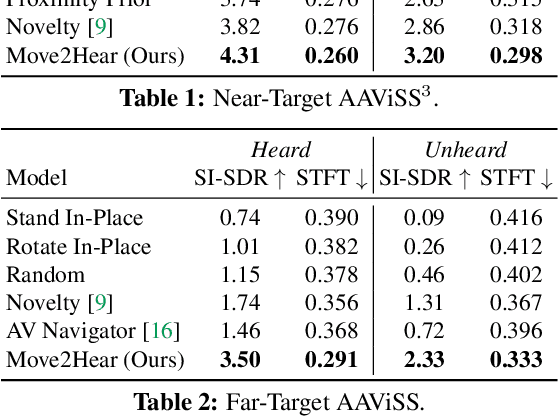
We introduce the active audio-visual source separation problem, where an agent must move intelligently in order to better isolate the sounds coming from an object of interest in its environment. The agent hears multiple audio sources simultaneously (e.g., a person speaking down the hall in a noisy household) and must use its eyes and ears to automatically separate out the sounds originating from the target object within a limited time budget. Towards this goal, we introduce a reinforcement learning approach that trains movement policies controlling the agent's camera and microphone placement over time, guided by the improvement in predicted audio separation quality. We demonstrate our approach in scenarios motivated by both augmented reality (system is already co-located with the target object) and mobile robotics (agent begins arbitrarily far from the target object). Using state-of-the-art realistic audio-visual simulations in 3D environments, we demonstrate our model's ability to find minimal movement sequences with maximal payoff for audio source separation. Project: http://vision.cs.utexas.edu/projects/move2hear.
GenRadar: Self-supervised Probabilistic Camera Synthesis based on Radar Frequencies
Jul 19, 2021
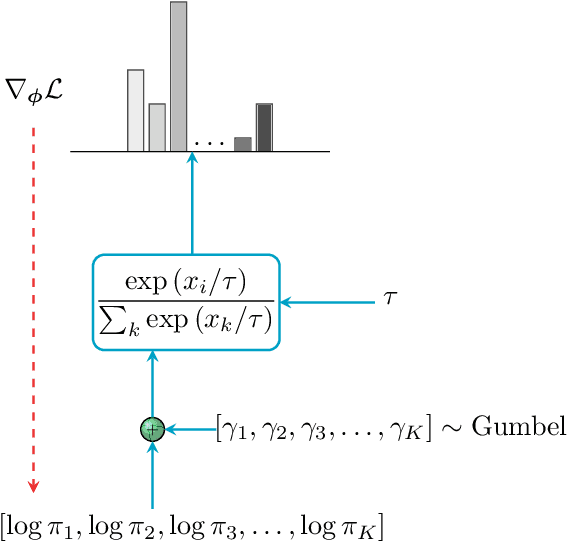
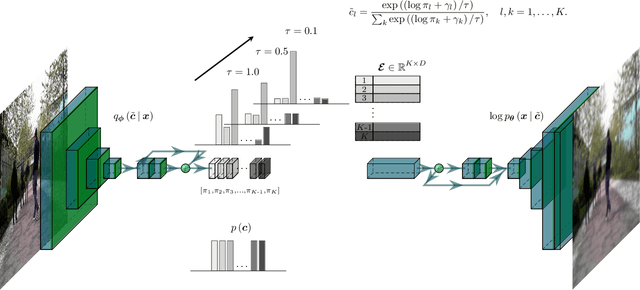
Autonomous systems require a continuous and dependable environment perception for navigation and decision-making, which is best achieved by combining different sensor types. Radar continues to function robustly in compromised circumstances in which cameras become impaired, guaranteeing a steady inflow of information. Yet, camera images provide a more intuitive and readily applicable impression of the world. This work combines the complementary strengths of both sensor types in a unique self-learning fusion approach for a probabilistic scene reconstruction in adverse surrounding conditions. After reducing the memory requirements of both high-dimensional measurements through a decoupled stochastic self-supervised compression technique, the proposed algorithm exploits similarities and establishes correspondences between both domains at different feature levels during training. Then, at inference time, relying exclusively on radio frequencies, the model successively predicts camera constituents in an autoregressive and self-contained process. These discrete tokens are finally transformed back into an instructive view of the respective surrounding, allowing to visually perceive potential dangers for important tasks downstream.