 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Reinforcement Learning for Time Optimal Velocity Control using Prior Knowledge
Mar 12, 2019
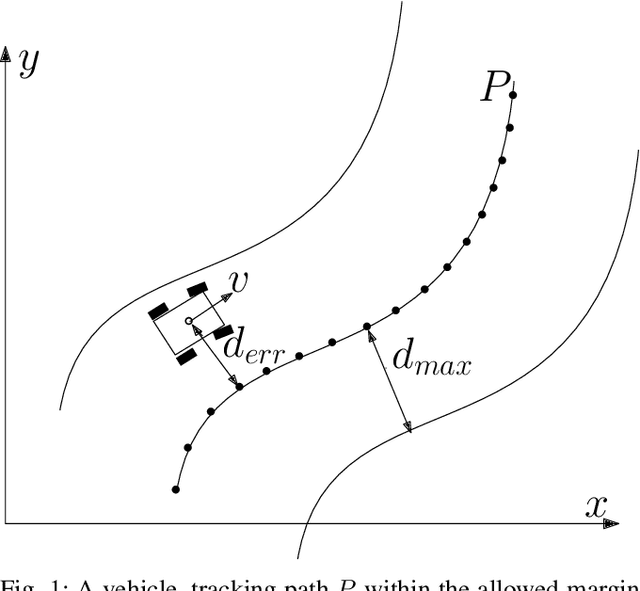
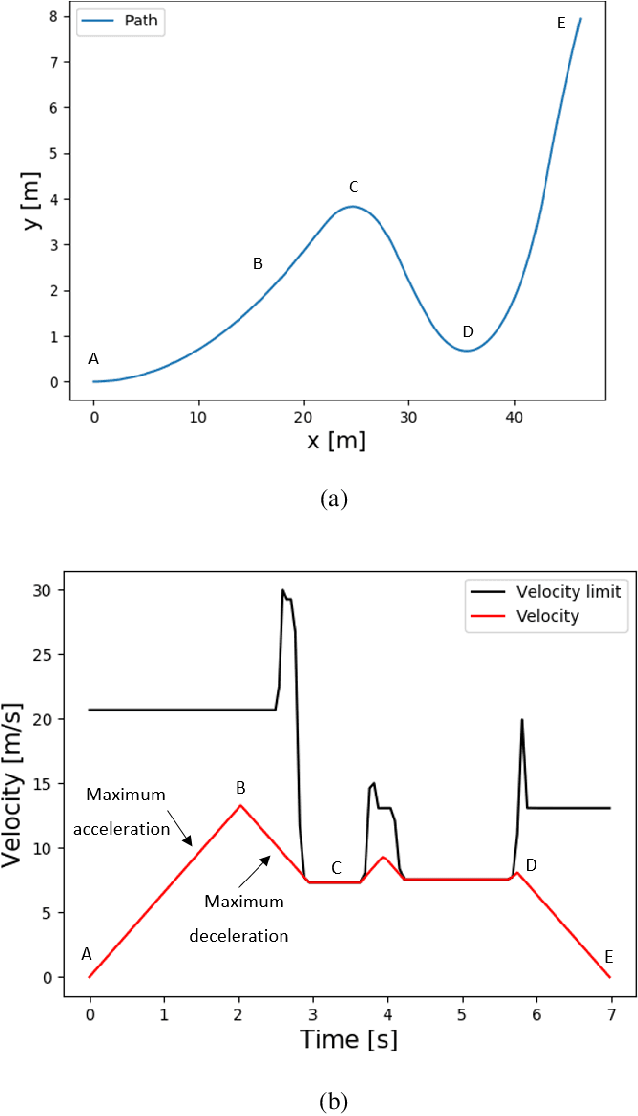
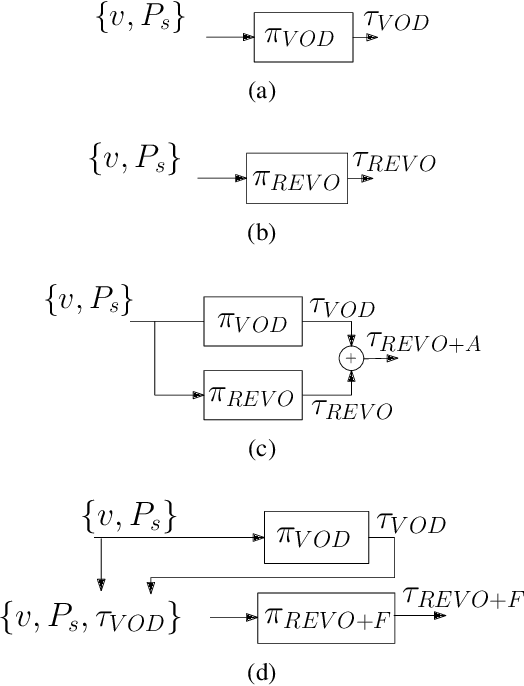
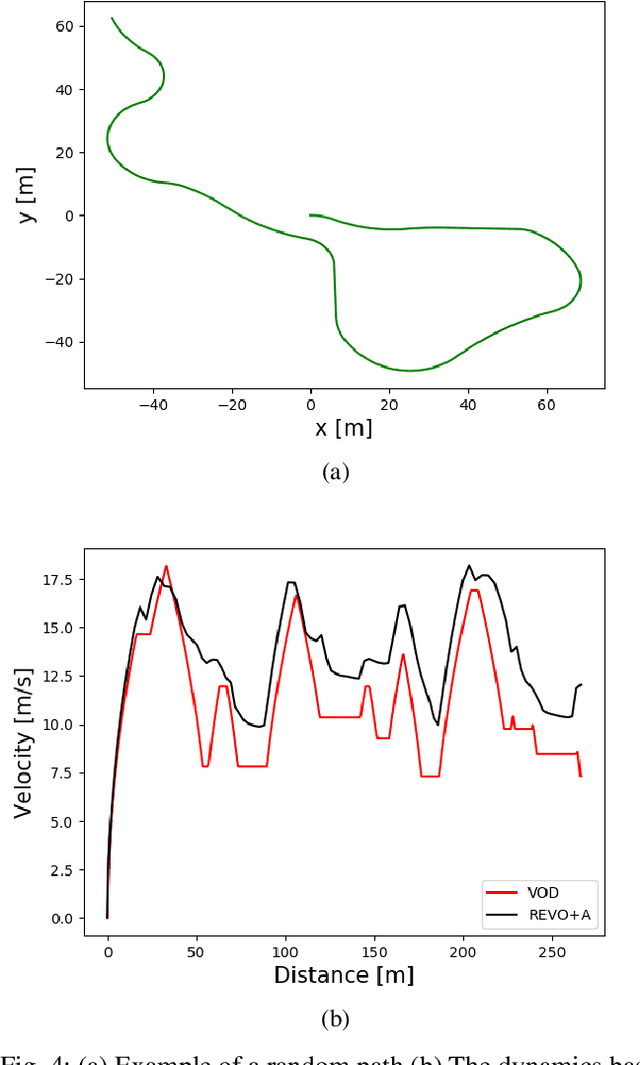
While autonomous navigation has recently gained great interest in the field of reinforcement learning, only a few works in this field have focused on the time optimal velocity control problem, i.e. controlling a vehicle such that it travels at the maximal speed without becoming dynamically unstable. Achieving maximal speed is important in many situations, such as emergency vehicles traveling at high speeds to their destinations, and regular vehicles executing emergency maneuvers to avoid imminent collisions. Time optimal velocity control can be solved numerically using existing methods that are based on optimal control and vehicle dynamics. In this paper, we use deep reinforcement learning to generate the time optimal velocity control. Furthermore, we use the numerical solution to further improve the performance of the reinforcement learner. It is shown that the reinforcement learner outperforms the numerically derived solution, and that the hybrid approach (combining learning with the numerical solution) speeds up the learning process.
On the Characterizations of OTFS Modulation over multipath Rapid Fading Channel
Mar 18, 2021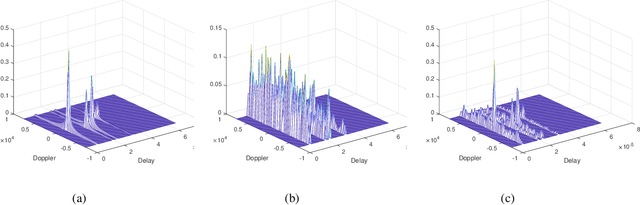
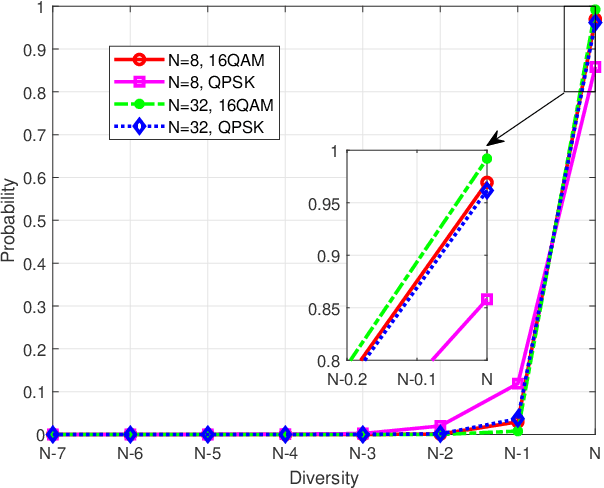
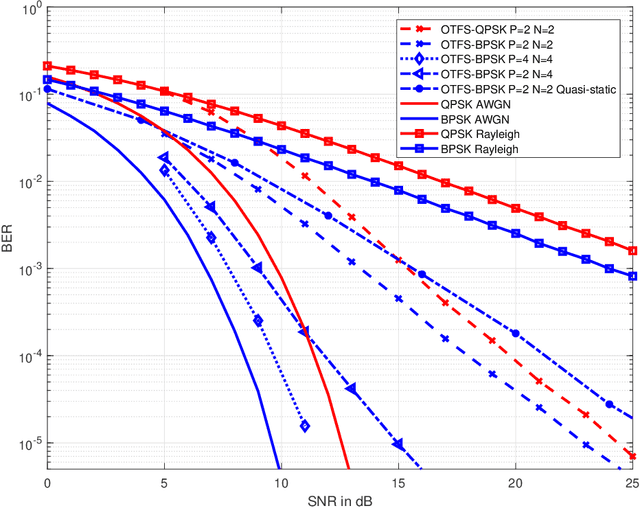
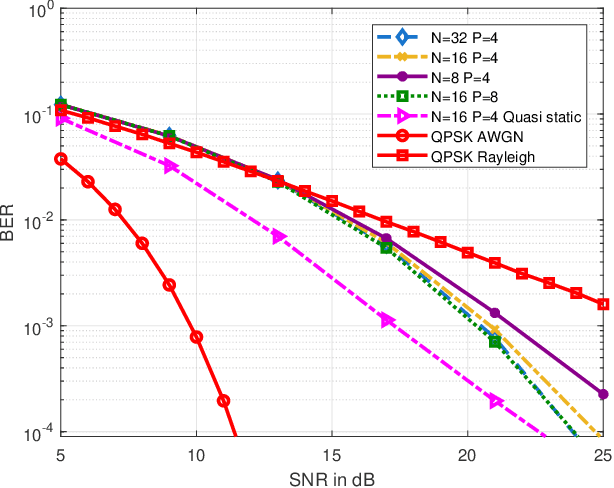
Orthogonal time frequency space (OTFS) modulation has been verified to provide significant performance advantages against Doppler in high-mobility scenarios. The core feature of OTFS is that the time-variant channel is converted into a non-fading 2D channel in the delay-Doppler (DD) domain so that all symbols experience the same channel gain. In now available literatures, the channel is assumed to be quasi-static over an OTFS frame. As for more practical channels, the input-output relation will be time-variant as the environment or medium changes. In this paper, we analyze the characterizations of OTFS Modulation over a more general multipath Channel, where the signal of each path has experienced a unique rapid fading. First, we derive the explicit input-output relationship of OTFS in the DD domain for the case of ideal pulse and rectangular pulse. It is shown that the rapid fading will produce extra Doppler dispersion without impacting on delay domain. We next domenstrate that OTFS can be interpreted as an efficient time diversity technology that combines space-time encoding and interleaving. The simulation results reveal that OTFS is insensitive to rapid fading and still outperforms orthogonal frequency-division multiplexing (OFDM) in such channel.
Learning Autonomous Mobility Using Real Demonstration Data
Aug 10, 2021
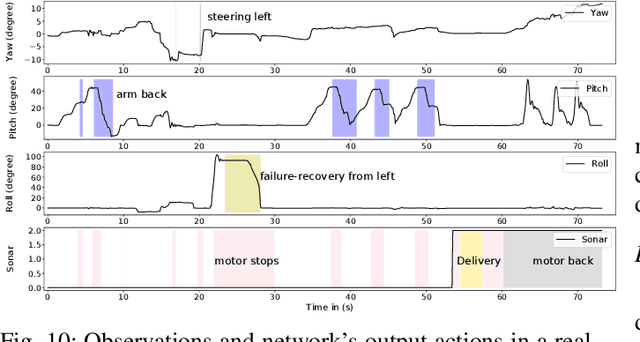
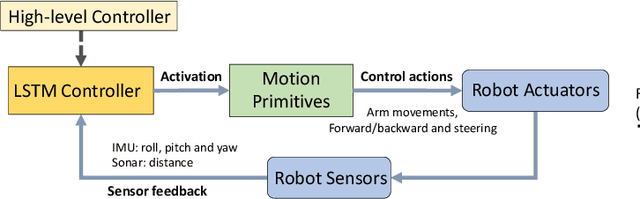
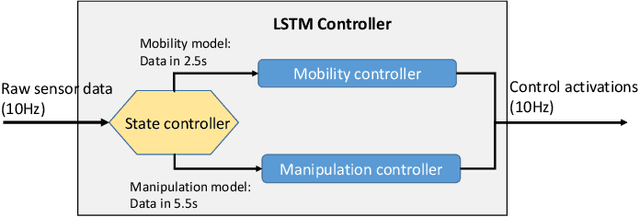
This work proposed an efficient learning-based framework to learn feedback control policies from human teleoperated demonstrations, which achieved obstacle negotiation, staircase traversal, slipping control and parcel delivery for a tracked robot. Due to uncertainties in real-world scenarios, eg obstacle and slippage, closed-loop feedback control plays an important role in improving robustness and resilience, but the control laws are difficult to program manually for achieving autonomous behaviours. We formulated an architecture based on a long-short-term-memory (LSTM) neural network, which effectively learn reactive control policies from human demonstrations. Using datasets from a few real demonstrations, our algorithm can directly learn successful policies, including obstacle-negotiation, stair-climbing and delivery, fall recovery and corrective control of slippage. We proposed decomposition of complex robot actions to reduce the difficulty of learning the long-term dependencies. Furthermore, we proposed a method to efficiently handle non-optimal demos and to learn new skills, since collecting enough demonstration can be time-consuming and sometimes very difficult on a real robotic system.
DynSTGAT: Dynamic Spatial-Temporal Graph Attention Network for Traffic Signal Control
Sep 12, 2021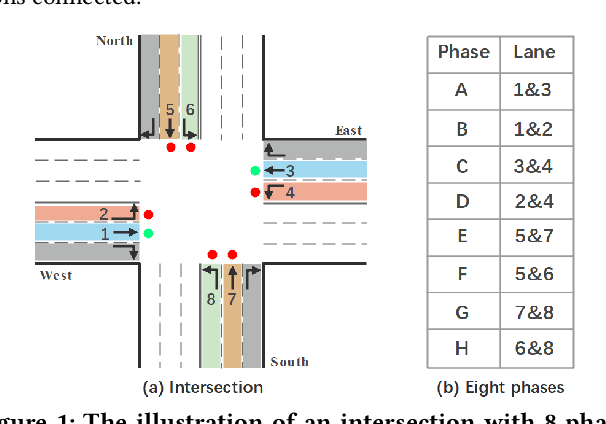
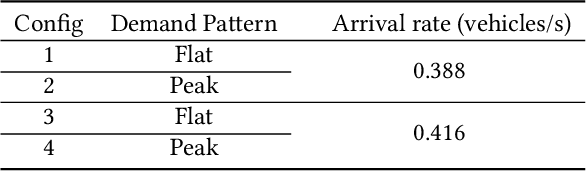
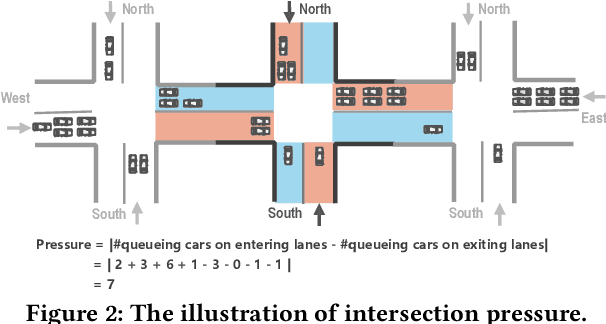

Adaptive traffic signal control plays a significant role in the construction of smart cities. This task is challenging because of many essential factors, such as cooperation among neighboring intersections and dynamic traffic scenarios. First, to facilitate cooperation of traffic signals, existing work adopts graph neural networks to incorporate the temporal and spatial influences of the surrounding intersections into the target intersection, where spatial-temporal information is used separately. However, one drawback of these methods is that the spatial-temporal correlations are not adequately exploited to obtain a better control scheme. Second, in a dynamic traffic environment, the historical state of the intersection is also critical for predicting future signal switching. Previous work mainly solves this problem using the current intersection's state, neglecting the fact that traffic flow is continuously changing both spatially and temporally and does not handle the historical state. In this paper, we propose a novel neural network framework named DynSTGAT, which integrates dynamic historical state into a new spatial-temporal graph attention network to address the above two problems. More specifically, our DynSTGAT model employs a novel multi-head graph attention mechanism, which aims to adequately exploit the joint relations of spatial-temporal information. Then, to efficiently utilize the historical state information of the intersection, we design a sequence model with the temporal convolutional network (TCN) to capture the historical information and further merge it with the spatial information to improve its performance. Extensive experiments conducted in the multi-intersection scenario on synthetic data and real-world data confirm that our method can achieve superior performance in travel time and throughput against the state-of-the-art methods.
PRECODE - A Generic Model Extension to Prevent Deep Gradient Leakage
Aug 10, 2021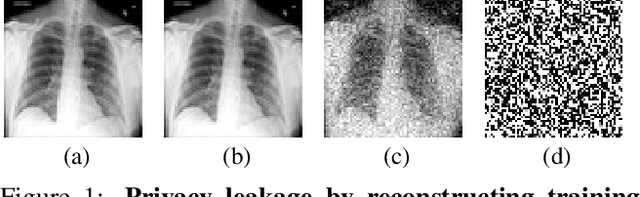
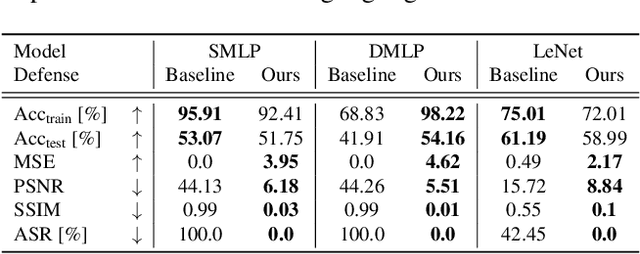

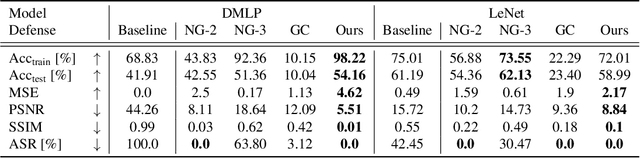
Collaborative training of neural networks leverages distributed data by exchanging gradient information between different clients. Although training data entirely resides with the clients, recent work shows that training data can be reconstructed from such exchanged gradient information. To enhance privacy, gradient perturbation techniques have been proposed. However, they come at the cost of reduced model performance, increased convergence time, or increased data demand. In this paper, we introduce PRECODE, a PRivacy EnhanCing mODulE that can be used as generic extension for arbitrary model architectures. We propose a simple yet effective realization of PRECODE using variational modeling. The stochastic sampling induced by variational modeling effectively prevents privacy leakage from gradients and in turn preserves privacy of data owners. We evaluate PRECODE using state of the art gradient inversion attacks on two different model architectures trained on three datasets. In contrast to commonly used defense mechanisms, we find that our proposed modification consistently reduces the attack success rate to 0% while having almost no negative impact on model training and final performance. As a result, PRECODE reveals a promising path towards privacy enhancing model extensions.
Online Sub-Sampling for Reinforcement Learning with General Function Approximation
Jun 14, 2021Designing provably efficient algorithms with general function approximation is an important open problem in reinforcement learning. Recently, Wang et al.~[2020c] establish a value-based algorithm with general function approximation that enjoys $\widetilde{O}(\mathrm{poly}(dH)\sqrt{K})$\footnote{Throughout the paper, we use $\widetilde{O}(\cdot)$ to suppress logarithm factors. } regret bound, where $d$ depends on the complexity of the function class, $H$ is the planning horizon, and $K$ is the total number of episodes. However, their algorithm requires $\Omega(K)$ computation time per round, rendering the algorithm inefficient for practical use. In this paper, by applying online sub-sampling techniques, we develop an algorithm that takes $\widetilde{O}(\mathrm{poly}(dH))$ computation time per round on average, and enjoys nearly the same regret bound. Furthermore, the algorithm achieves low switching cost, i.e., it changes the policy only $\widetilde{O}(\mathrm{poly}(dH))$ times during its execution, making it appealing to be implemented in real-life scenarios. Moreover, by using an upper-confidence based exploration-driven reward function, the algorithm provably explores the environment in the reward-free setting. In particular, after $\widetilde{O}(\mathrm{poly}(dH))/\epsilon^2$ rounds of exploration, the algorithm outputs an $\epsilon$-optimal policy for any given reward function.
Efficient Iterative Amortized Inference for Learning Symmetric and Disentangled Multi-Object Representations
Jun 07, 2021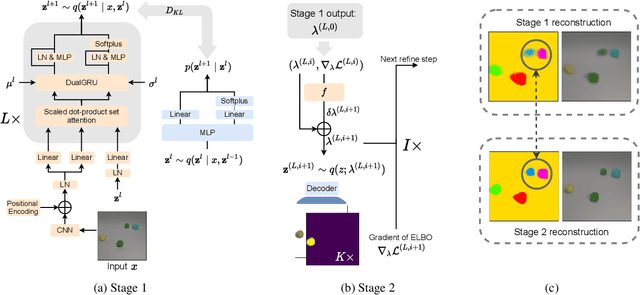
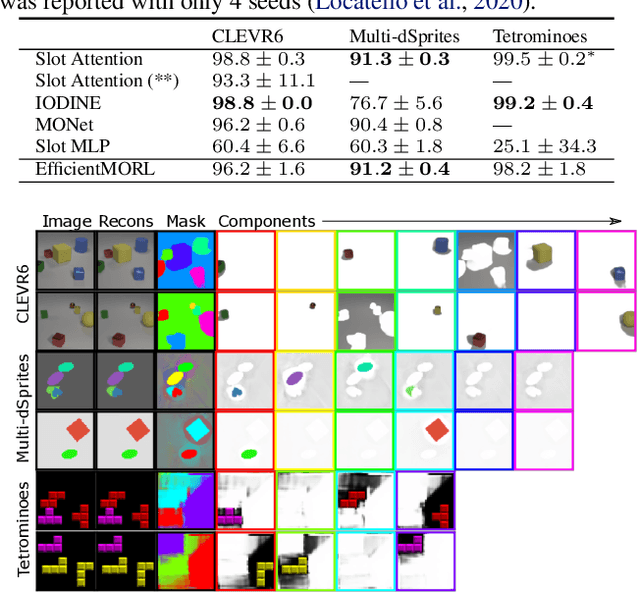
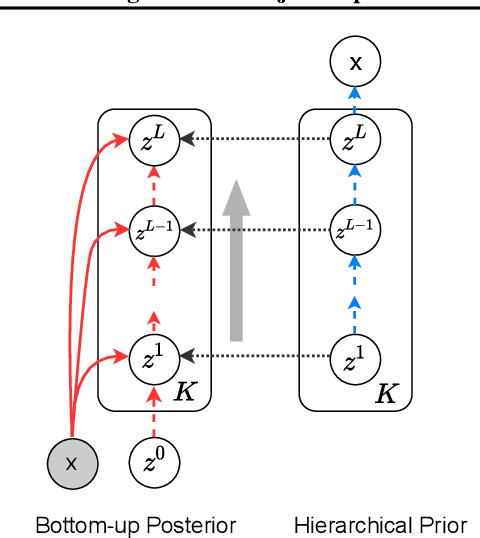
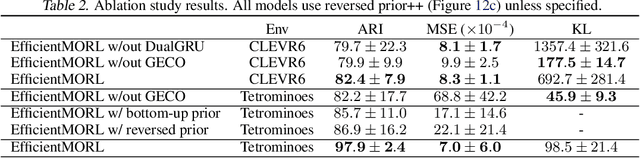
Unsupervised multi-object representation learning depends on inductive biases to guide the discovery of object-centric representations that generalize. However, we observe that methods for learning these representations are either impractical due to long training times and large memory consumption or forego key inductive biases. In this work, we introduce EfficientMORL, an efficient framework for the unsupervised learning of object-centric representations. We show that optimization challenges caused by requiring both symmetry and disentanglement can in fact be addressed by high-cost iterative amortized inference by designing the framework to minimize its dependence on it. We take a two-stage approach to inference: first, a hierarchical variational autoencoder extracts symmetric and disentangled representations through bottom-up inference, and second, a lightweight network refines the representations with top-down feedback. The number of refinement steps taken during training is reduced following a curriculum, so that at test time with zero steps the model achieves 99.1% of the refined decomposition performance. We demonstrate strong object decomposition and disentanglement on the standard multi-object benchmark while achieving nearly an order of magnitude faster training and test time inference over the previous state-of-the-art model.
Retweet communities reveal the main sources of hate speech
May 31, 2021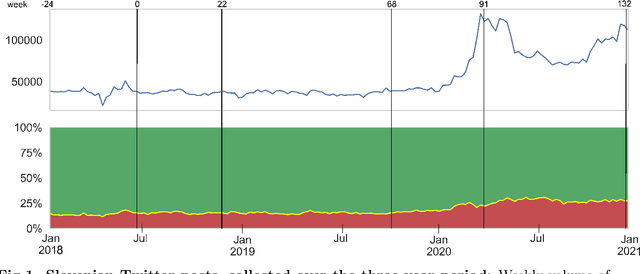

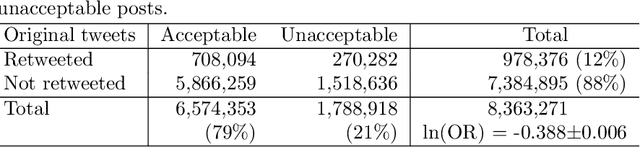
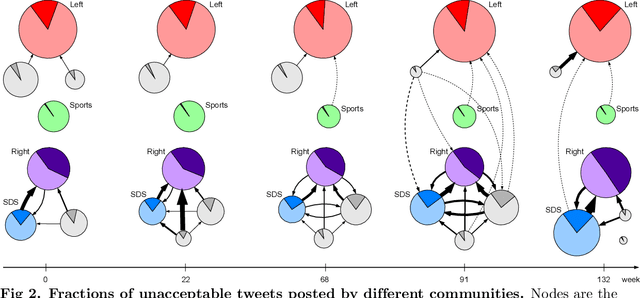
We address a challenging problem of identifying main sources of hate speech on Twitter. On one hand, we carefully annotate a large set of tweets for hate speech, and deploy advanced deep learning to produce high quality hate speech classification models. On the other hand, we create retweet networks, detect communities and monitor their evolution through time. This combined approach is applied to three years of Slovenian Twitter data. We report a number of interesting results. Hate speech is dominated by offensive tweets, related to political and ideological issues. The share of unacceptable tweets is moderately increasing with time, from the initial 20% to 30% by the end of 2020. Unacceptable tweets are retweeted significantly more often than acceptable tweets. About 60% of unacceptable tweets are produced by a single right-wing community of only moderate size. Institutional Twitter accounts and media accounts post significantly less unacceptable tweets than individual accounts. However, the main sources of unacceptable tweets are anonymous accounts, and accounts that were suspended or closed during the last three years.
Embedding digital chronotherapy into medical devices -- A canine case study in controlling status epilepticus through multi-scale rhythmic brain stimulation
Jul 07, 2021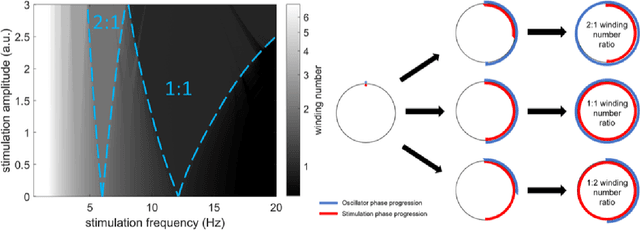
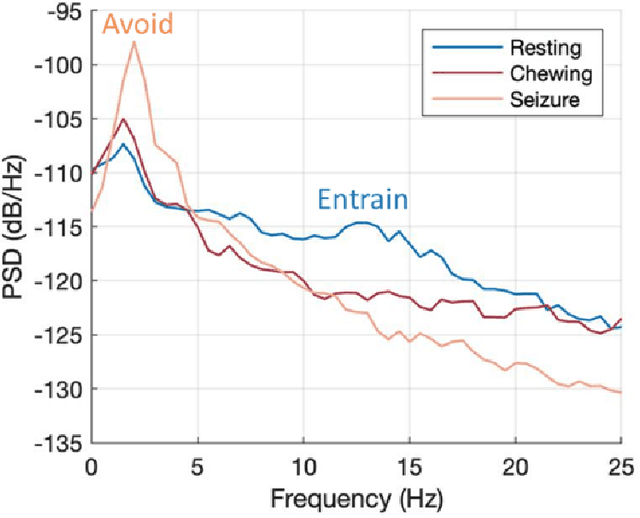
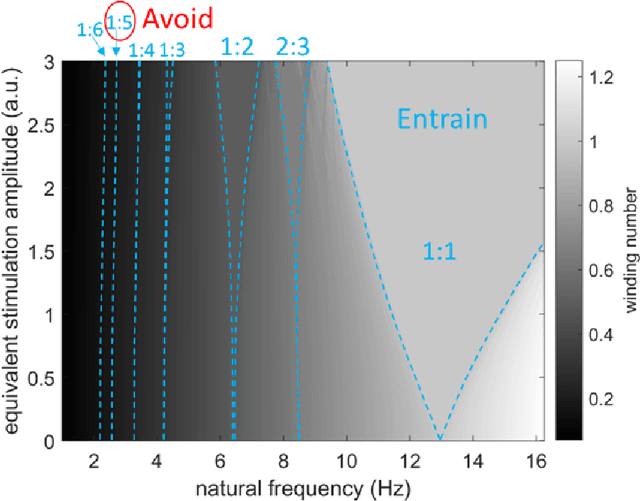
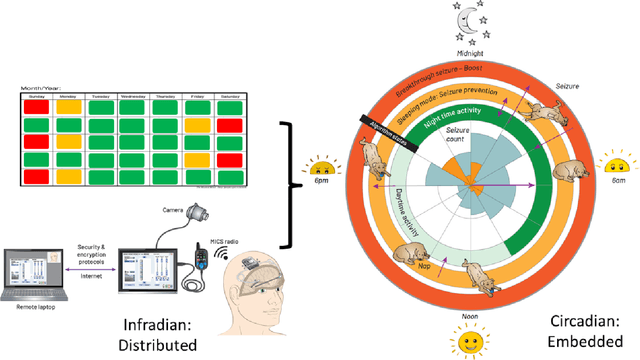
Circadian and other physiological rhythms play a key role in both normal homeostasis and disease processes. Such is the case of circadian and infradian seizure patterns observed in epilepsy. However, these rhythms are not fully exploited in the design of active implantable medical devices. In this paper we explore a new implantable stimulator that implements chronotherapy as a feedforward input to supplement both open-loop and closed-loop methods. This integrated algorithm allows for stimulation to be adjusted to the ultradian, circadian, and infradian patterns observed in patients through slowly-varying temporal adjustments of stimulation and algorithm sub-components, while also enabling adaption of stimulation based on immediate physiological needs such as a breakthrough seizure or change of posture. Embedded physiological sensors in the stimulator can be used to refine the baseline stimulation circadian pattern as a "digital zeitgeber". This algorithmic approach is tested on a canine with severe drug-resistant idiopathic generalized epilepsy exhibiting a characteristic diurnal pattern correlated with sleep-wake cycles. Prior to implantation, the canine's cluster seizures evolved to status epilepticus (SE) and required emergency pharmacological intervention. The cranially-mounted system was fully-implanted bilaterally into the centromedian nucleus of the thalamus. Using combinations of time-based modulation, thalamocortical rhythm-specific tuning of frequency parameters, and fast-adaptive modes based on activity, the canine has experienced no further SE events post-implant at the time of writing (7 months), and no significant clusters are observed any longer. The use of digitally-enabled chronotherapy as a feedforward signal to augment adaptive neurostimulators could prove a useful algorithmic method where sensitivity to temporal patterns are characteristics of the disease state.
Efficient training for future video generation based on hierarchical disentangled representation of latent variables
Jun 07, 2021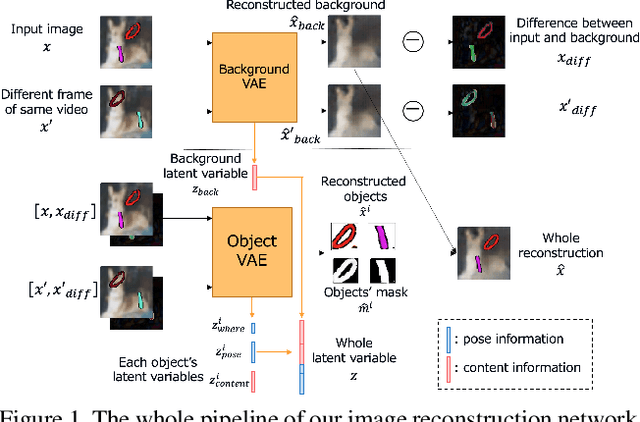
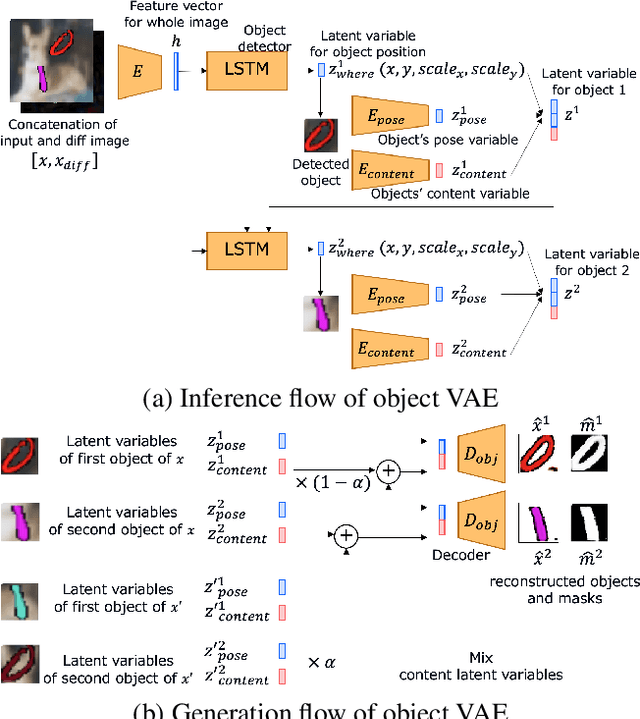


Generating videos predicting the future of a given sequence has been an area of active research in recent years. However, an essential problem remains unsolved: most of the methods require large computational cost and memory usage for training. In this paper, we propose a novel method for generating future prediction videos with less memory usage than the conventional methods. This is a critical stepping stone in the path towards generating videos with high image quality, similar to that of generated images in the latest works in the field of image generation. We achieve high-efficiency by training our method in two stages: (1) image reconstruction to encode video frames into latent variables, and (2) latent variable prediction to generate the future sequence. Our method achieves an efficient compression of video into low-dimensional latent variables by decomposing each frame according to its hierarchical structure. That is, we consider that video can be separated into background and foreground objects, and that each object holds time-varying and time-independent information independently. Our experiments show that the proposed method can efficiently generate future prediction videos, even for complex datasets that cannot be handled by previous methods.