 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Conditional Image Embedding Framework Leveraging Large Vision Language Models
Dec 26, 2025Conditional image embeddings are feature representations that focus on specific aspects of an image indicated by a given textual condition (e.g., color, genre), which has been a challenging problem. Although recent vision foundation models, such as CLIP, offer rich representations of images, they are not designed to focus on a specified condition. In this paper, we propose DIOR, a method that leverages a large vision-language model (LVLM) to generate conditional image embeddings. DIOR is a training-free approach that prompts the LVLM to describe an image with a single word related to a given condition. The hidden state vector of the LVLM's last token is then extracted as the conditional image embedding. DIOR provides a versatile solution that can be applied to any image and condition without additional training or task-specific priors. Comprehensive experimental results on conditional image similarity tasks demonstrate that DIOR outperforms existing training-free baselines, including CLIP. Furthermore, DIOR achieves superior performance compared to methods that require additional training across multiple settings.
Leveraging Many-To-Many Relationships for Defending Against Visual-Language Adversarial Attacks
May 29, 2024



Recent studies have revealed that vision-language (VL) models are vulnerable to adversarial attacks for image-text retrieval (ITR). However, existing defense strategies for VL models primarily focus on zero-shot image classification, which do not consider the simultaneous manipulation of image and text, as well as the inherent many-to-many (N:N) nature of ITR, where a single image can be described in numerous ways, and vice versa. To this end, this paper studies defense strategies against adversarial attacks on VL models for ITR for the first time. Particularly, we focus on how to leverage the N:N relationship in ITR to enhance adversarial robustness. We found that, although adversarial training easily overfits to specific one-to-one (1:1) image-text pairs in the train data, diverse augmentation techniques to create one-to-many (1:N) / many-to-one (N:1) image-text pairs can significantly improve adversarial robustness in VL models. Additionally, we show that the alignment of the augmented image-text pairs is crucial for the effectiveness of the defense strategy, and that inappropriate augmentations can even degrade the model's performance. Based on these findings, we propose a novel defense strategy that leverages the N:N relationship in ITR, which effectively generates diverse yet highly-aligned N:N pairs using basic augmentations and generative model-based augmentations. This work provides a novel perspective on defending against adversarial attacks in VL tasks and opens up new research directions for future work.
Plaque segmentation via masking of the artery wall
Jan 26, 2022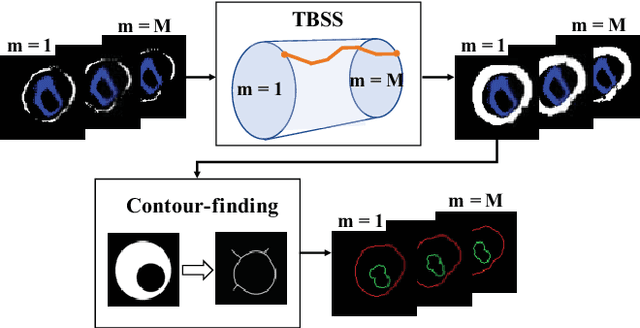

The presence of plaques in the coronary arteries are a major risk to the patients' life. In particular, non-calcified plaques pose a great challenge, as they are harder to detect and more likely to rupture than calcified plaques. While current deep learning techniques allow precise segmentation of regular images, the performance in medical images is still low, caused mostly by blurriness and ambiguous voxel intensities of unrelated parts that fall on the same range. In this paper, we propose a novel methodology for segmenting calcified and non-calcified plaques in CCTA-CPR scans of coronary arteries. The input slices are masked so only the voxels within the wall vessel are considered for segmentation. We also provide an exhaustive evaluation by applying different types of masks, in order to validate the potential of vessel masking for plaque segmentation. Our methodology results in a prominent boost in segmentation performance, in both quantitative and qualitative evaluation, achieving accurate plaque shapes even for the challenging non-calcified plaques. We believe our findings can lead the future research for high-performance plaque segmentation.
Video Ads Content Structuring by Combining Scene Confidence Prediction and Tagging
Aug 20, 2021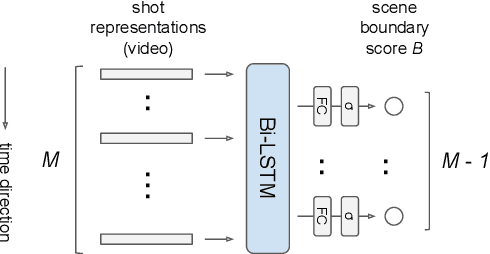

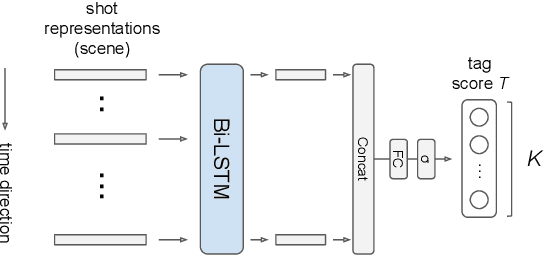
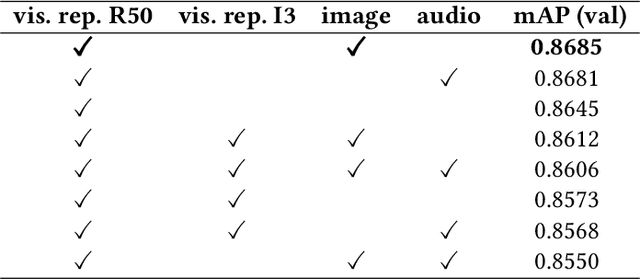
Video ads segmentation and tagging is a challenging task due to two main reasons: (1) the video scene structure is complex and (2) it includes multiple modalities (e.g., visual, audio, text.). While previous work focuses mostly on activity videos (e.g. "cooking", "sports"), it is not clear how they can be leveraged to tackle the task of video ads content structuring. In this paper, we propose a two-stage method that first provides the boundaries of the scenes, and then combines a confidence score for each segmented scene and the tag classes predicted for that scene. We provide extensive experimental results on the network architectures and modalities used for the proposed method. Our combined method improves the previous baselines on the challenging "Tencent Advertisement Video" dataset.
Efficient training for future video generation based on hierarchical disentangled representation of latent variables
Jun 08, 2021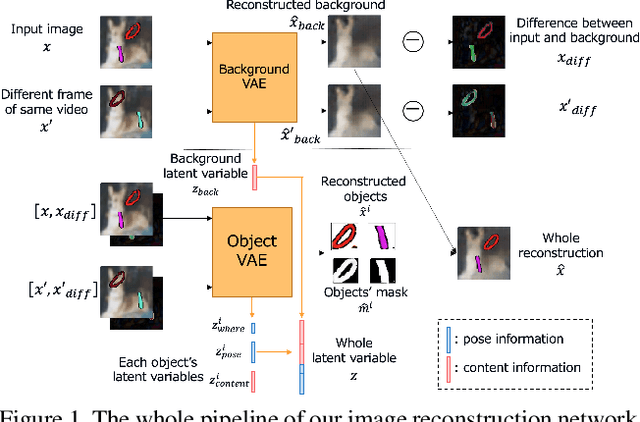
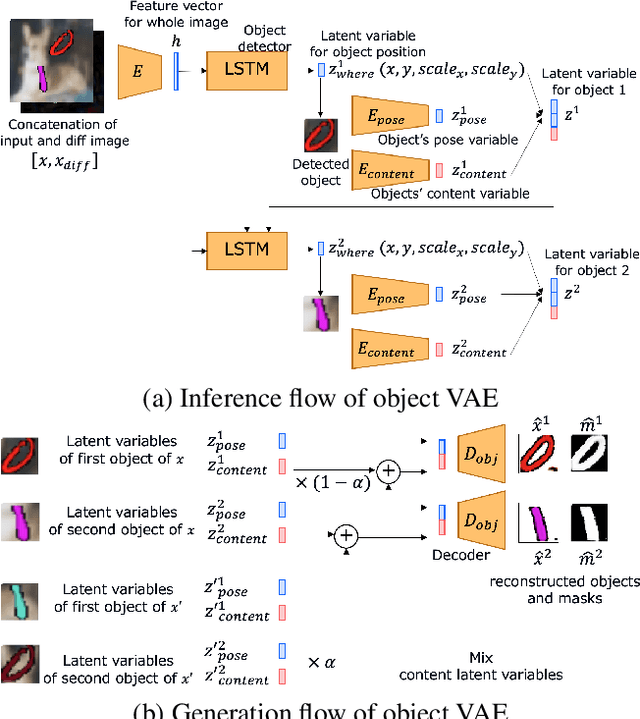


Generating videos predicting the future of a given sequence has been an area of active research in recent years. However, an essential problem remains unsolved: most of the methods require large computational cost and memory usage for training. In this paper, we propose a novel method for generating future prediction videos with less memory usage than the conventional methods. This is a critical stepping stone in the path towards generating videos with high image quality, similar to that of generated images in the latest works in the field of image generation. We achieve high-efficiency by training our method in two stages: (1) image reconstruction to encode video frames into latent variables, and (2) latent variable prediction to generate the future sequence. Our method achieves an efficient compression of video into low-dimensional latent variables by decomposing each frame according to its hierarchical structure. That is, we consider that video can be separated into background and foreground objects, and that each object holds time-varying and time-independent information independently. Our experiments show that the proposed method can efficiently generate future prediction videos, even for complex datasets that cannot be handled by previous methods.
Coronary Wall Segmentation in CCTA Scans via a Hybrid Net with Contours Regularization
Feb 27, 2020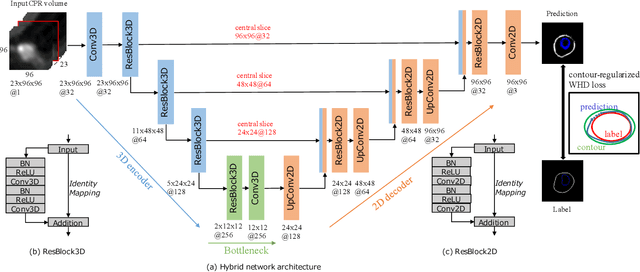
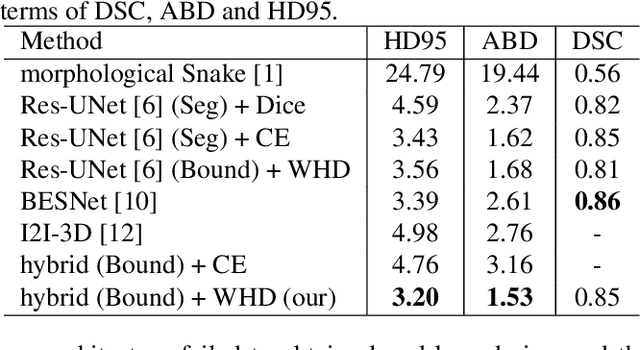

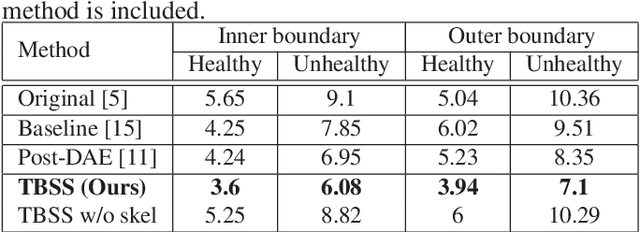
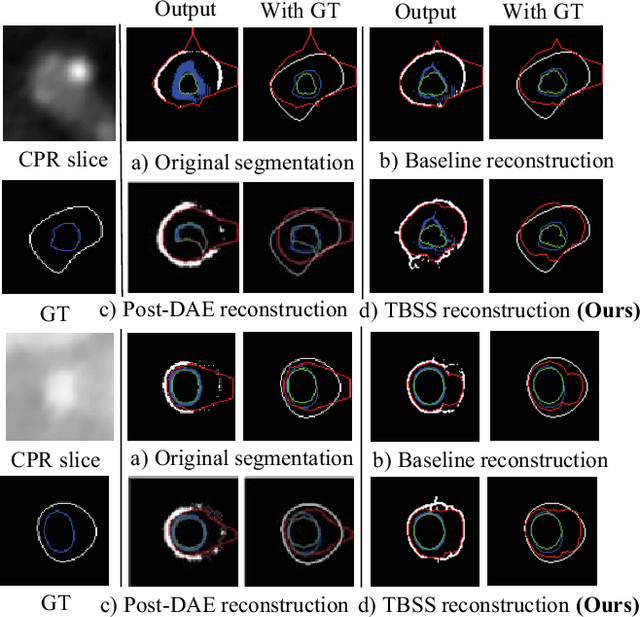
Providing closed and well-connected boundaries of coronary artery is essential to assist cardiologists in the diagnosis of coronary artery disease (CAD). Recently, several deep learning-based methods have been proposed for boundary detection and segmentation in a medical image. However, when applied to coronary wall detection, they tend to produce disconnected and inaccurate boundaries. In this paper, we propose a novel boundary detection method for coronary arteries that focuses on the continuity and connectivity of the boundaries. In order to model the spatial continuity of consecutive images, our hybrid architecture takes a volume (i.e., a segment of the coronary artery) as input and detects the boundary of the target slice (i.e., the central slice of the segment). Then, to ensure closed boundaries, we propose a contour-constrained weighted Hausdorff distance loss. We evaluate our method on a dataset of 34 patients of coronary CT angiography scans with curved planar reconstruction (CCTA-CPR) of the arteries (i.e., cross-sections). Experiment results show that our method can produce smooth closed boundaries outperforming the state-of-the-art accuracy.
Improved Optical Flow for Gesture-based Human-robot Interaction
May 21, 2019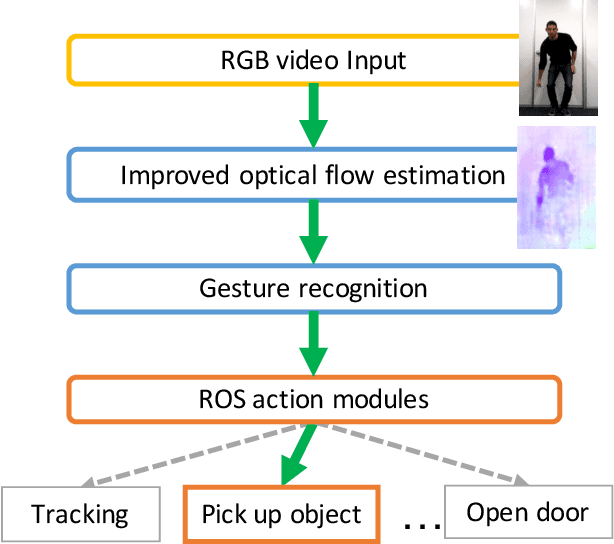

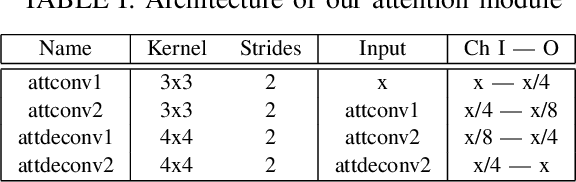
Gesture interaction is a natural way of communicating with a robot as an alternative to speech. Gesture recognition methods leverage optical flow in order to understand human motion. However, while accurate optical flow estimation (i.e., traditional) methods are costly in terms of runtime, fast estimation (i.e., deep learning) methods' accuracy can be improved. In this paper, we present a pipeline for gesture-based human-robot interaction that uses a novel optical flow estimation method in order to achieve an improved speed-accuracy trade-off. Our optical flow estimation method introduces four improvements to previous deep learning-based methods: strong feature extractors, attention to contours, midway features, and a combination of these three. This results in a better understanding of motion, and a finer representation of silhouettes. In order to evaluate our pipeline, we generated our own dataset, MIBURI, which contains gestures to command a house service robot. In our experiments, we show how our method improves not only optical flow estimation, but also gesture recognition, offering a speed-accuracy trade-off more realistic for practical robot applications.
Long-Term Video Generation of Multiple Futures Using Human Poses
Apr 17, 2019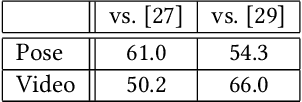
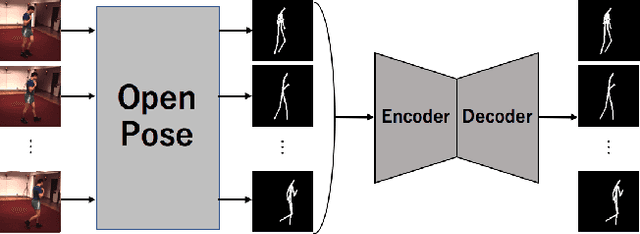
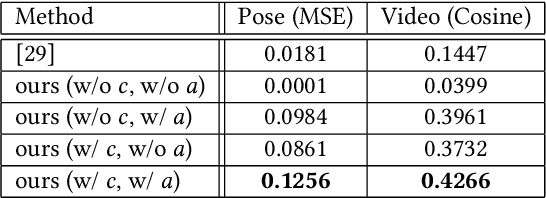
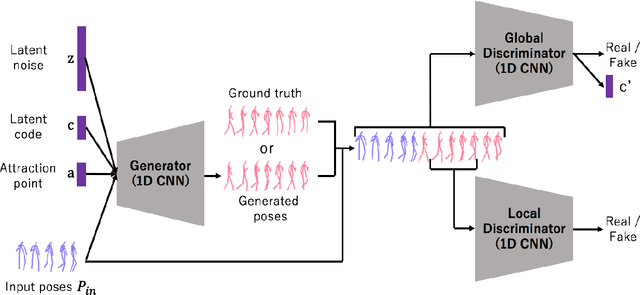
Predicting the near-future from an input video is a useful task for applications such as autonomous driving and robotics. While most previous works predict a single future, multiple futures with different behaviors can possibly occur. Moreover, if the predicted future is too short, it may not be fully usable by a human or other system. In this paper, we propose a novel method for future video prediction capable of generating multiple long-term futures. This makes the predictions more suitable for real applications. First, from an input human video, we generate sequences of future human poses as the image coordinates of their body-joints by adversarial learning. We generate multiple futures by inputting to the generator combinations of a latent code (to reflect various behaviors) and an attraction point (to reflect various trajectories). In addition, we generate long-term future human poses using a novel approach based on unidimensional convolutional neural networks. Last, we generate an output video based on the generated poses for visualization. We evaluate the generated future poses and videos using three criteria (i.e., realism, diversity and accuracy), and show that our proposed method outperforms other state-of-the-art works.
Conditional Video Generation Using Action-Appearance Captions
Dec 05, 2018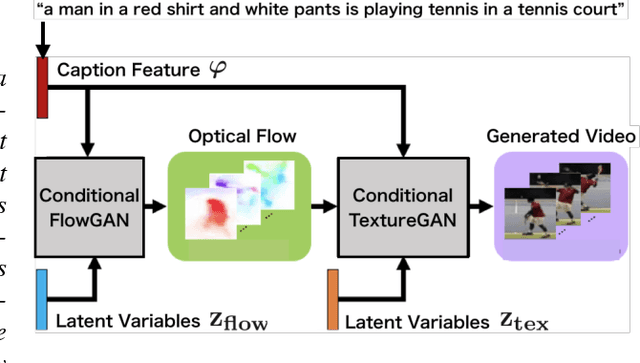

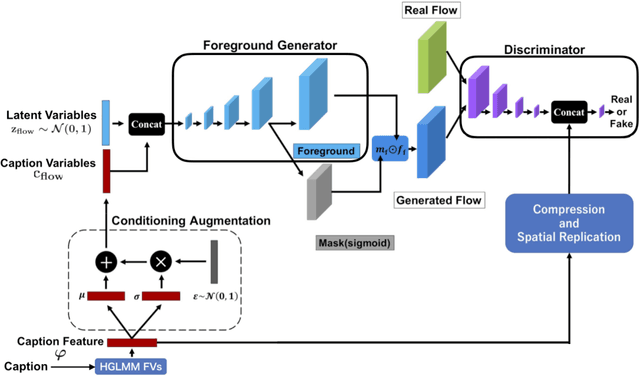

The field of automatic video generation has received a boost thanks to the recent Generative Adversarial Networks (GANs). However, most existing methods cannot control the contents of the generated video using a text caption, losing their usefulness to a large extent. This particularly affects human videos due to their great variety of actions and appearances. This paper presents Conditional Flow and Texture GAN (CFT-GAN), a GAN-based video generation method from action-appearance captions. We propose a novel way of generating video by encoding a caption (e.g., "a man in blue jeans is playing golf") in a two-stage generation pipeline. Our CFT-GAN uses such caption to generate an optical flow (action) and a texture (appearance) for each frame. As a result, the output video reflects the content specified in the caption in a plausible way. Moreover, to train our method, we constructed a new dataset for human video generation with captions. We evaluated the proposed method qualitatively and quantitatively via an ablation study and a user study. The results demonstrate that CFT-GAN is able to successfully generate videos containing the action and appearances indicated in the captions.
Summarization of User-Generated Sports Video by Using Deep Action Recognition Features
Apr 13, 2018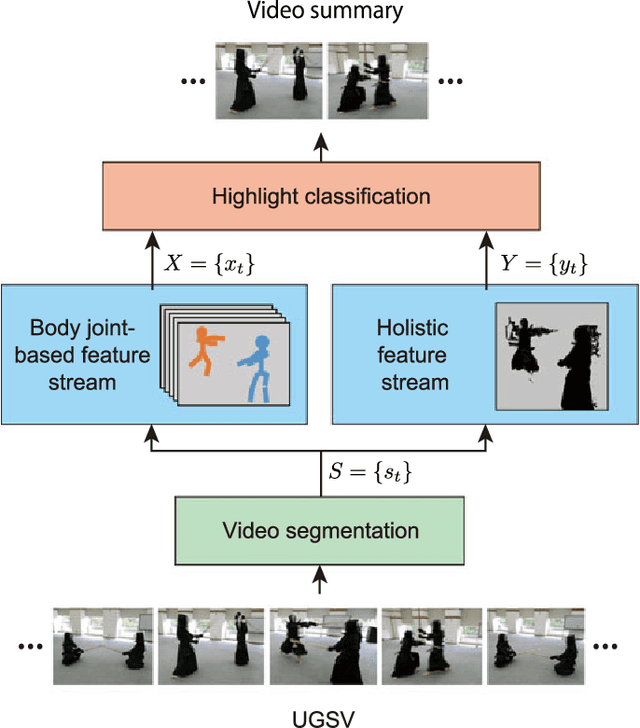
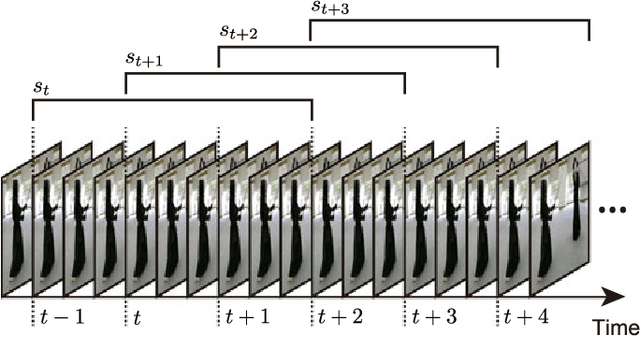
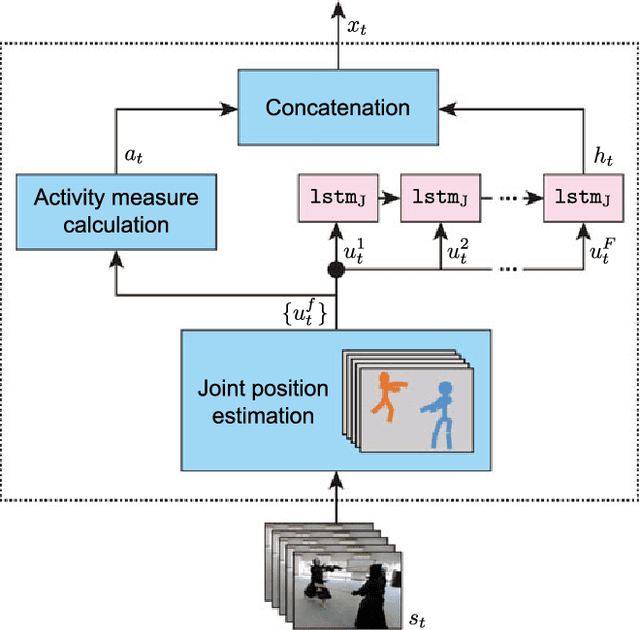
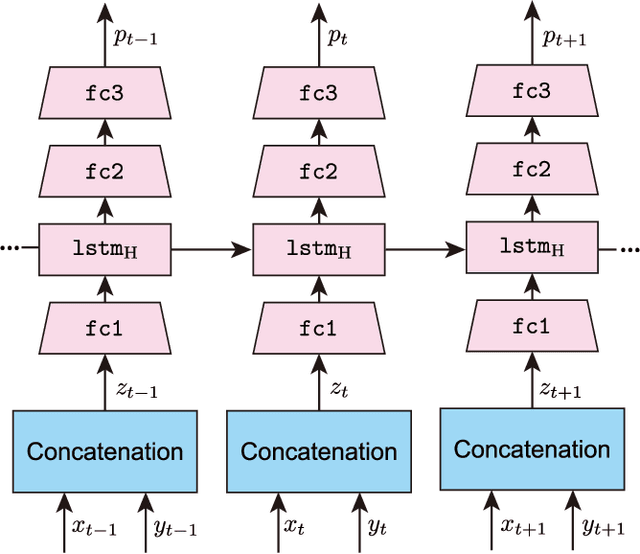
Automatically generating a summary of sports video poses the challenge of detecting interesting moments, or highlights, of a game. Traditional sports video summarization methods leverage editing conventions of broadcast sports video that facilitate the extraction of high-level semantics. However, user-generated videos are not edited, and thus traditional methods are not suitable to generate a summary. In order to solve this problem, this work proposes a novel video summarization method that uses players' actions as a cue to determine the highlights of the original video. A deep neural network-based approach is used to extract two types of action-related features and to classify video segments into interesting or uninteresting parts. The proposed method can be applied to any sports in which games consist of a succession of actions. Especially, this work considers the case of Kendo (Japanese fencing) as an example of a sport to evaluate the proposed method. The method is trained using Kendo videos with ground truth labels that indicate the video highlights. The labels are provided by annotators possessing different experience with respect to Kendo to demonstrate how the proposed method adapts to different needs. The performance of the proposed method is compared with several combinations of different features, and the results show that it outperforms previous summarization methods.