 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Close Look At World Model Recovery In Supervised Fine-Tuned LLM Planners
Jun 02, 2026Supervised fine-tuning (SFT) improves end-to-end classical planning in large language models (LLMs), but do these models also learn to represent and reason about the planning problems they are solving? Due to the relative complexity of classical planning problems and the challenge that end-to-end plan generation poses for LLMs, it has been difficult to explore this question. In our work, we devise and perform a series of interpretability experiments that holistically interrogate world model recovery by examining both internal representations and generative capabilities of fine-tuned LLMs. We find that: a) Supervised fine-tuning on valid action sequences enables LLMs to linearly encode action validity and some state predicates. b) Models that struggle to use output probabilities for classifying action validity may still learn internal representations that separate valid from invalid actions. c) Broader state space coverage during fine-tuning, such as from random walk data, yields more accurate recovery of the underlying world model. In summary, this work contributes a recipe for applying interpretability techniques to planning LLMs and generates insights that shed light on open questions about how knowledge is represented in LLMs.
SCICONVBENCH: Benchmarking LLMs on Multi-Turn Clarification for Task Formulation in Computational Science
May 18, 2026Large Language Models (LLMs) are increasingly deployed as scientific AI as- sistants, and a growing body of benchmarks evaluates their capabilities across knowledge retrieval, reasoning, code generation, and tool use. These evaluations, however, typically assume the scientific problem is already well-posed, whereas practical scientific assistance often begins with an ill-posed user request that must be refined through dialogue before any computation, analysis, or experiment can be carried out reliably. We introduce SCICONVBENCH, a benchmark for multi- turn clarification in scientific task formulation across four computational science problem domains: fluid mechanics, solid mechanics, materials science, and par- tial differential equations (PDEs). SCICONVBENCH targets two complementary capabilities: eliciting missing information (disambiguation) and detecting and correcting erroneous requests containing internally contradictory information (in- consistency resolution). Our benchmark pairs a structured task ontology with a rubric-based evaluation framework, enabling systematic measurement of LLM per- formance across three dimensions: clarification behavior, conversational grounding, and final-specification fidelity. Current frontier models perform relatively well on inconsistency resolution, but even the best model resolves only 52.7% of the disambiguation cases in fluid mechanics. We further find that frontier LLMs fre- quently make silent assumptions and perform implicit specification repairs that are not grounded in the conversation with users. SCICONVBENCH establishes a foundation for evaluating the upstream conversational reasoning that a reliable computational science assistant requires. The code and data can be found at https://github.com/csml-rpi/SciConvBench.
SysCaps: Language Interfaces for Simulation Surrogates of Complex Systems
May 30, 2024



Data-driven simulation surrogates help computational scientists study complex systems. They can also help inform impactful policy decisions. We introduce a learning framework for surrogate modeling where language is used to interface with the underlying system being simulated. We call a language description of a system a "system caption", or SysCap. To address the lack of datasets of paired natural language SysCaps and simulation runs, we use large language models (LLMs) to synthesize high-quality captions. Using our framework, we train multimodal text and timeseries regression models for two real-world simulators of complex energy systems. Our experiments demonstrate the feasibility of designing language interfaces for real-world surrogate models at comparable accuracy to standard baselines. We qualitatively and quantitatively show that SysCaps unlock text-prompt-style surrogate modeling and new generalization abilities beyond what was previously possible. We will release the generated SysCaps datasets and our code to support follow-on studies.
Three Pathways to Neurosymbolic Reinforcement Learning with Interpretable Model and Policy Networks
Feb 07, 2024



Neurosymbolic AI combines the interpretability, parsimony, and explicit reasoning of classical symbolic approaches with the statistical learning of data-driven neural approaches. Models and policies that are simultaneously differentiable and interpretable may be key enablers of this marriage. This paper demonstrates three pathways to implementing such models and policies in a real-world reinforcement learning setting. Specifically, we study a broad class of neural networks that build interpretable semantics directly into their architecture. We reveal and highlight both the potential and the essential difficulties of combining logic, simulation, and learning. One lesson is that learning benefits from continuity and differentiability, but classical logic is discrete and non-differentiable. The relaxation to real-valued, differentiable representations presents a trade-off; the more learnable, the less interpretable. Another lesson is that using logic in the context of a numerical simulation involves a non-trivial mapping from raw (e.g., real-valued time series) simulation data to logical predicates. Some open questions this note exposes include: What are the limits of rule-based controllers, and how learnable are they? Do the differentiable interpretable approaches discussed here scale to large, complex, uncertain systems? Can we truly achieve interpretability? We highlight these and other themes across the three approaches.
Non-Stationary Policy Learning for Multi-Timescale Multi-Agent Reinforcement Learning
Jul 17, 2023



In multi-timescale multi-agent reinforcement learning (MARL), agents interact across different timescales. In general, policies for time-dependent behaviors, such as those induced by multiple timescales, are non-stationary. Learning non-stationary policies is challenging and typically requires sophisticated or inefficient algorithms. Motivated by the prevalence of this control problem in real-world complex systems, we introduce a simple framework for learning non-stationary policies for multi-timescale MARL. Our approach uses available information about agent timescales to define a periodic time encoding. In detail, we theoretically demonstrate that the effects of non-stationarity introduced by multiple timescales can be learned by a periodic multi-agent policy. To learn such policies, we propose a policy gradient algorithm that parameterizes the actor and critic with phase-functioned neural networks, which provide an inductive bias for periodicity. The framework's ability to effectively learn multi-timescale policies is validated on a gridworld and building energy management environment.
BuildingsBench: A Large-Scale Dataset of 900K Buildings and Benchmark for Short-Term Load Forecasting
Jun 30, 2023Short-term forecasting of residential and commercial building energy consumption is widely used in power systems and continues to grow in importance. Data-driven short-term load forecasting (STLF), although promising, has suffered from a lack of open, large-scale datasets with high building diversity. This has hindered exploring the pretrain-then-finetune paradigm for STLF. To help address this, we present BuildingsBench, which consists of 1) Buildings-900K, a large-scale dataset of 900K simulated buildings representing the U.S. building stock, and 2) an evaluation platform with over 1,900 real residential and commercial buildings from 7 open datasets. BuildingsBench benchmarks two under-explored tasks: zero-shot STLF, where a pretrained model is evaluated on unseen buildings without fine-tuning, and transfer learning, where a pretrained model is fine-tuned on a target building. The main finding of our benchmark analysis is that synthetically pretrained models generalize surprisingly well to real commercial buildings. An exploration of the effect of increasing dataset size and diversity on zero-shot commercial building performance reveals a power-law with diminishing returns. We also show that fine-tuning pretrained models on real commercial and residential buildings improves performance for a majority of target buildings. We hope that BuildingsBench encourages and facilitates future research on generalizable STLF. All datasets and code can be accessed from \url{https://github.com/NREL/BuildingsBench}.
Plug & Play Directed Evolution of Proteins with Gradient-based Discrete MCMC
Dec 20, 2022A long-standing goal of machine-learning-based protein engineering is to accelerate the discovery of novel mutations that improve the function of a known protein. We introduce a sampling framework for evolving proteins in silico that supports mixing and matching a variety of unsupervised models, such as protein language models, and supervised models that predict protein function from sequence. By composing these models, we aim to improve our ability to evaluate unseen mutations and constrain search to regions of sequence space likely to contain functional proteins. Our framework achieves this without any model fine-tuning or re-training by constructing a product of experts distribution directly in discrete protein space. Instead of resorting to brute force search or random sampling, which is typical of classic directed evolution, we introduce a fast MCMC sampler that uses gradients to propose promising mutations. We conduct in silico directed evolution experiments on wide fitness landscapes and across a range of different pre-trained unsupervised models, including a 650M parameter protein language model. Our results demonstrate an ability to efficiently discover variants with high evolutionary likelihood as well as estimated activity multiple mutations away from a wild type protein, suggesting our sampler provides a practical and effective new paradigm for machine-learning-based protein engineering.
Learning Canonical Embeddings for Unsupervised Shape Correspondence with Locally Linear Transformations
Sep 07, 2022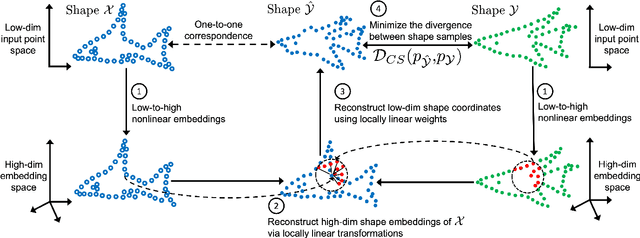
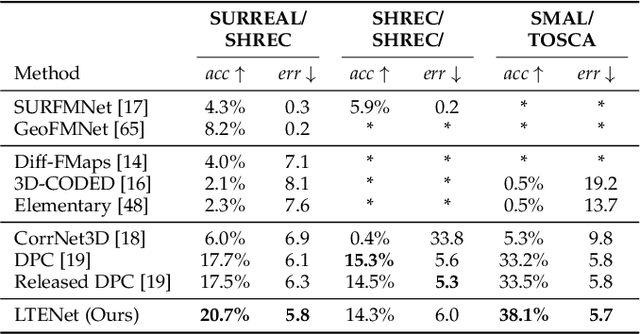
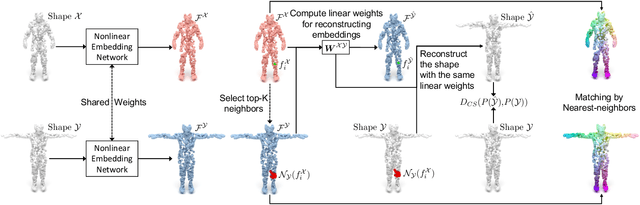

We present a new approach to unsupervised shape correspondence learning between pairs of point clouds. We make the first attempt to adapt the classical locally linear embedding algorithm (LLE) -- originally designed for nonlinear dimensionality reduction -- for shape correspondence. The key idea is to find dense correspondences between shapes by first obtaining high-dimensional neighborhood-preserving embeddings of low-dimensional point clouds and subsequently aligning the source and target embeddings using locally linear transformations. We demonstrate that learning the embedding using a new LLE-inspired point cloud reconstruction objective results in accurate shape correspondences. More specifically, the approach comprises an end-to-end learnable framework of extracting high-dimensional neighborhood-preserving embeddings, estimating locally linear transformations in the embedding space, and reconstructing shapes via divergence measure-based alignment of probabilistic density functions built over reconstructed and target shapes. Our approach enforces embeddings of shapes in correspondence to lie in the same universal/canonical embedding space, which eventually helps regularize the learning process and leads to a simple nearest neighbors approach between shape embeddings for finding reliable correspondences. Comprehensive experiments show that the new method makes noticeable improvements over state-of-the-art approaches on standard shape correspondence benchmark datasets covering both human and nonhuman shapes.
Slot Order Matters for Compositional Scene Understanding
Jun 03, 2022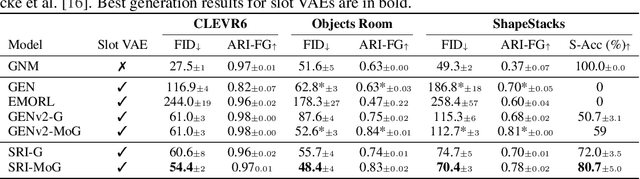
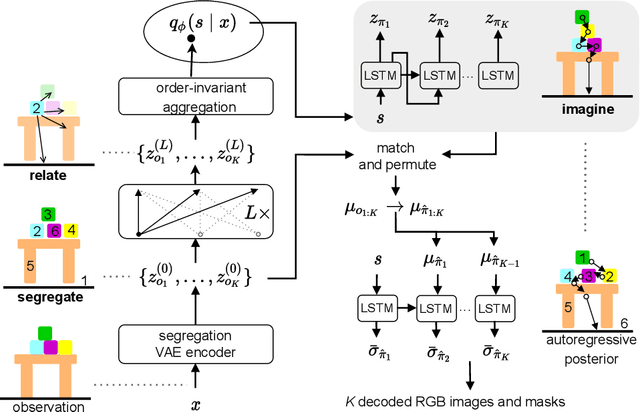


Empowering agents with a compositional understanding of their environment is a promising next step toward solving long-horizon planning problems. On the one hand, we have seen encouraging progress on variational inference algorithms for obtaining sets of object-centric latent representations ("slots") from unstructured scene observations. On the other hand, generating scenes from slots has received less attention, in part because it is complicated by the lack of a canonical object order. A canonical object order is useful for learning the object correlations necessary to generate physically plausible scenes similar to how raster scan order facilitates learning pixel correlations for pixel-level autoregressive image generation. In this work, we address this lack by learning a fixed object order for a hierarchical variational autoencoder with a single level of autoregressive slots and a global scene prior. We cast autoregressive slot inference as a set-to-sequence modeling problem. We introduce an auxiliary loss to train the slot prior to generate objects in a fixed order. During inference, we align a set of inferred slots to the object order obtained from a slot prior rollout. To ensure the rolled out objects are meaningful for the given scene, we condition the prior on an inferred global summary of the input. Experiments on compositional environments and ablations demonstrate that our model with global prior, inference with aligned slot order, and auxiliary loss achieves state-of-the-art sample quality.
Self-Supervised Robust Scene Flow Estimation via the Alignment of Probability Density Functions
Mar 23, 2022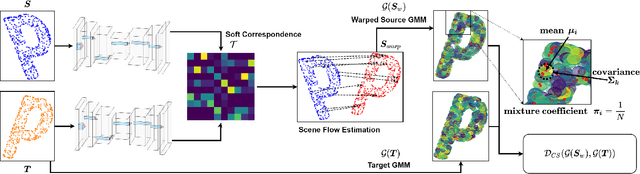
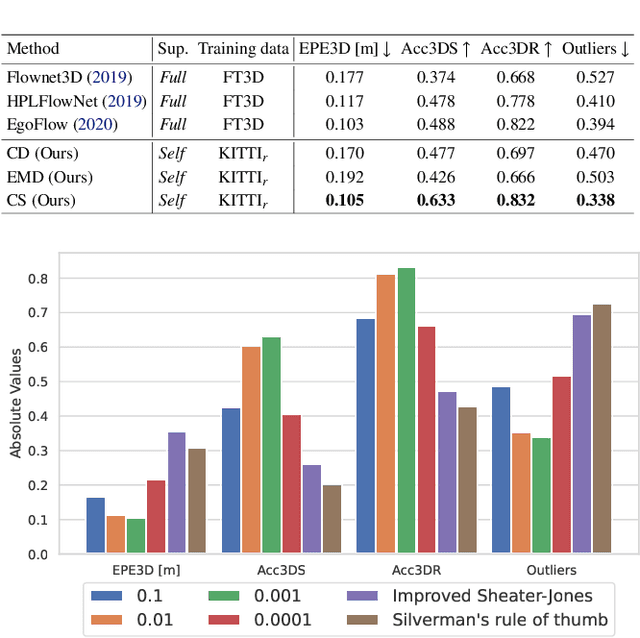
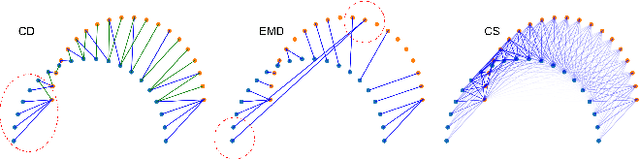
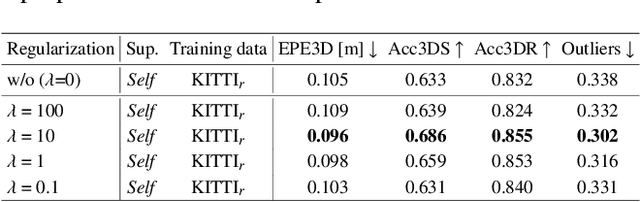
In this paper, we present a new self-supervised scene flow estimation approach for a pair of consecutive point clouds. The key idea of our approach is to represent discrete point clouds as continuous probability density functions using Gaussian mixture models. Scene flow estimation is therefore converted into the problem of recovering motion from the alignment of probability density functions, which we achieve using a closed-form expression of the classic Cauchy-Schwarz divergence. Unlike existing nearest-neighbor-based approaches that use hard pairwise correspondences, our proposed approach establishes soft and implicit point correspondences between point clouds and generates more robust and accurate scene flow in the presence of missing correspondences and outliers. Comprehensive experiments show that our method makes noticeable gains over the Chamfer Distance and the Earth Mover's Distance in real-world environments and achieves state-of-the-art performance among self-supervised learning methods on FlyingThings3D and KITTI, even outperforming some supervised methods with ground truth annotations.