 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffective Polarization across European Parliaments
Aug 26, 2025



Affective polarization, characterized by increased negativity and hostility towards opposing groups, has become a prominent feature of political discourse worldwide. Our study examines the presence of this type of polarization in a selection of European parliaments in a fully automated manner. Utilizing a comprehensive corpus of parliamentary speeches from the parliaments of six European countries, we employ natural language processing techniques to estimate parliamentarian sentiment. By comparing the levels of negativity conveyed in references to individuals from opposing groups versus one's own, we discover patterns of affectively polarized interactions. The findings demonstrate the existence of consistent affective polarization across all six European parliaments. Although activity correlates with negativity, there is no observed difference in affective polarization between less active and more active members of parliament. Finally, we show that reciprocity is a contributing mechanism in affective polarization between parliamentarians across all six parliaments.
XAI in Computational Linguistics: Understanding Political Leanings in the Slovenian Parliament
May 08, 2023



The work covers the development and explainability of machine learning models for predicting political leanings through parliamentary transcriptions. We concentrate on the Slovenian parliament and the heated debate on the European migrant crisis, with transcriptions from 2014 to 2020. We develop both classical machine learning and transformer language models to predict the left- or right-leaning of parliamentarians based on their given speeches on the topic of migrants. With both types of models showing great predictive success, we continue with explaining their decisions. Using explainability techniques, we identify keywords and phrases that have the strongest influence in predicting political leanings on the topic, with left-leaning parliamentarians using concepts such as people and unity and speak about refugees, and right-leaning parliamentarians using concepts such as nationality and focus more on illegal migrants. This research is an example that understanding the reasoning behind predictions can not just be beneficial for AI engineers to improve their models, but it can also be helpful as a tool in the qualitative analysis steps in interdisciplinary research.
Retweet communities reveal the main sources of hate speech
May 31, 2021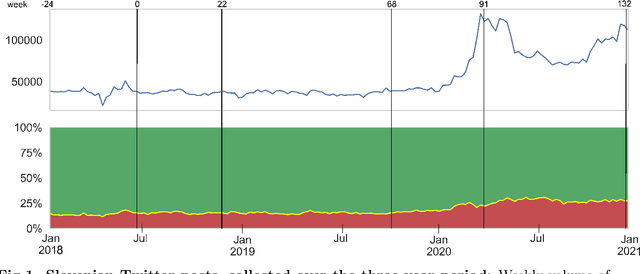

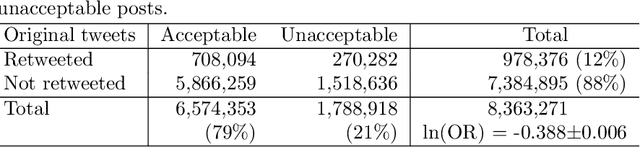
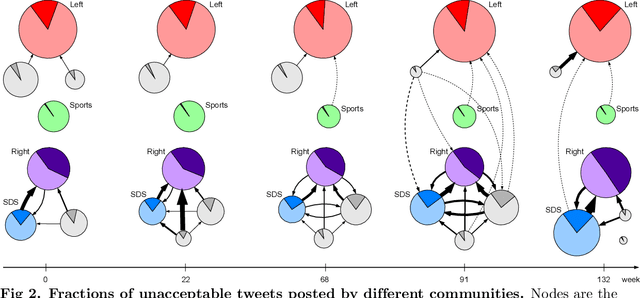
We address a challenging problem of identifying main sources of hate speech on Twitter. On one hand, we carefully annotate a large set of tweets for hate speech, and deploy advanced deep learning to produce high quality hate speech classification models. On the other hand, we create retweet networks, detect communities and monitor their evolution through time. This combined approach is applied to three years of Slovenian Twitter data. We report a number of interesting results. Hate speech is dominated by offensive tweets, related to political and ideological issues. The share of unacceptable tweets is moderately increasing with time, from the initial 20% to 30% by the end of 2020. Unacceptable tweets are retweeted significantly more often than acceptable tweets. About 60% of unacceptable tweets are produced by a single right-wing community of only moderate size. Institutional Twitter accounts and media accounts post significantly less unacceptable tweets than individual accounts. However, the main sources of unacceptable tweets are anonymous accounts, and accounts that were suspended or closed during the last three years.