 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stationary Density Estimation of Itô Diffusions Using Deep Learning
Sep 09, 2021
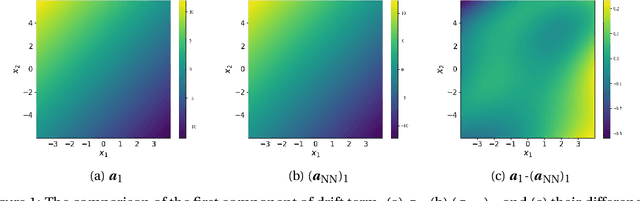
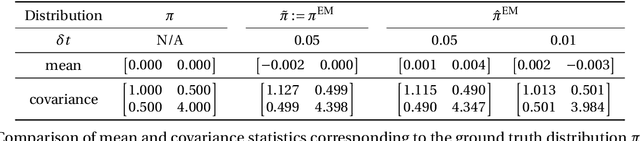
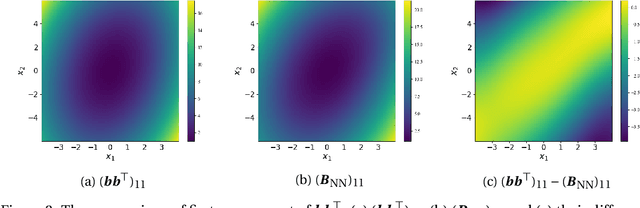
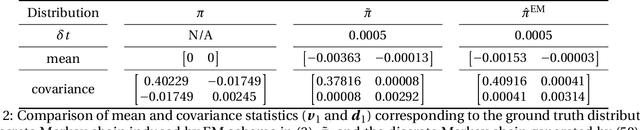
In this paper, we consider the density estimation problem associated with the stationary measure of ergodic It\^o diffusions from a discrete-time series that approximate the solutions of the stochastic differential equations. To take an advantage of the characterization of density function through the stationary solution of a parabolic-type Fokker-Planck PDE, we proceed as follows. First, we employ deep neural networks to approximate the drift and diffusion terms of the SDE by solving appropriate supervised learning tasks. Subsequently, we solve a steady-state Fokker-Plank equation associated with the estimated drift and diffusion coefficients with a neural-network-based least-squares method. We establish the convergence of the proposed scheme under appropriate mathematical assumptions, accounting for the generalization errors induced by regressing the drift and diffusion coefficients, and the PDE solvers. This theoretical study relies on a recent perturbation theory of Markov chain result that shows a linear dependence of the density estimation to the error in estimating the drift term, and generalization error results of nonparametric regression and of PDE regression solution obtained with neural-network models. The effectiveness of this method is reflected by numerical simulations of a two-dimensional Student's t distribution and a 20-dimensional Langevin dynamics.
Iterative Imitation Policy Improvement for Interactive Autonomous Driving
Sep 03, 2021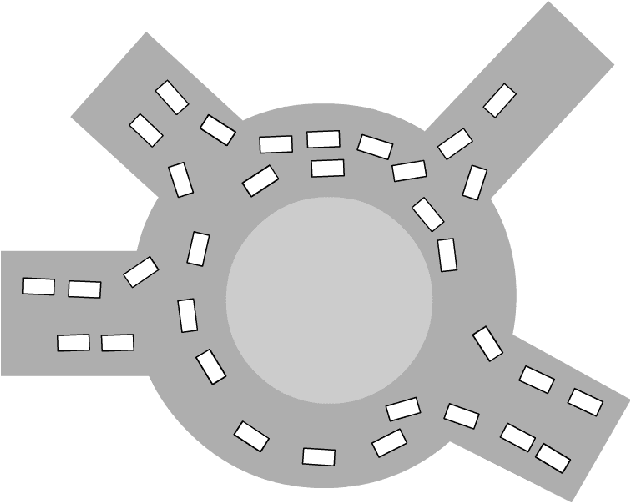
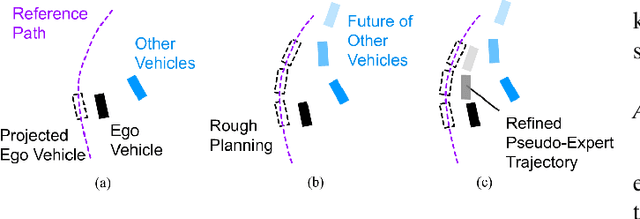
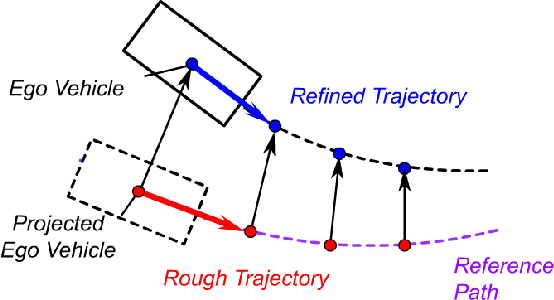
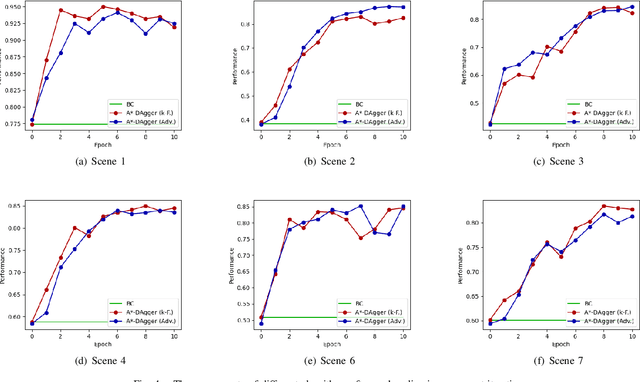
We propose an imitation learning system for autonomous driving in urban traffic with interactions. We train a Behavioral Cloning~(BC) policy to imitate driving behavior collected from the real urban traffic, and apply the data aggregation algorithm to improve its performance iteratively. Applying data aggregation in this setting comes with two challenges. The first challenge is that it is expensive and dangerous to collect online rollout data in the real urban traffic. Creating similar traffic scenarios in simulator like CARLA for online rollout collection can also be difficult. Instead, we propose to create a weak simulator from the training dataset, in which all the surrounding vehicles follow the data trajectory provided by the dataset. We find that the collected online data in such a simulator can still be used to improve BC policy's performance. The second challenge is the tedious and time-consuming process of human labelling process during online rollout. To solve this problem, we use an A$^*$ planner as a pseudo-expert to provide expert-like demonstration. We validate our proposed imitation learning system in the real urban traffic scenarios. The experimental results show that our system can significantly improve the performance of baseline BC policy.
Audio Spectral Enhancement: Leveraging Autoencoders for Low Latency Reconstruction of Long, Lossy Audio Sequences
Aug 08, 2021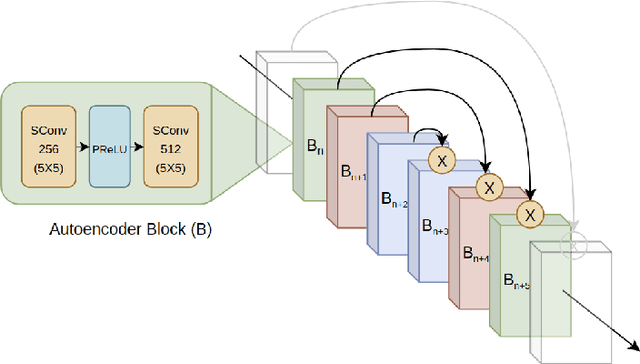
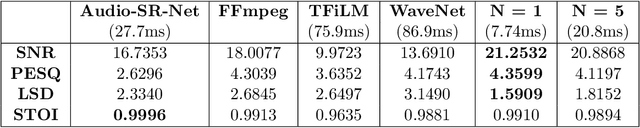
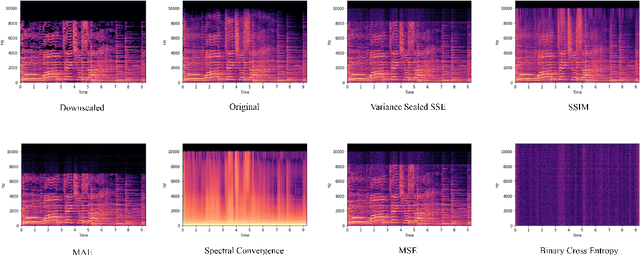
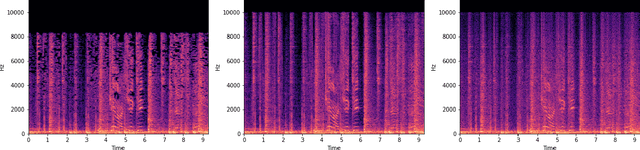
With active research in audio compression techniques yielding substantial breakthroughs, spectral reconstruction of low-quality audio waves remains a less indulged topic. In this paper, we propose a novel approach for reconstructing higher frequencies from considerably longer sequences of low-quality MP3 audio waves. Our technique involves inpainting audio spectrograms with residually stacked autoencoder blocks by manipulating individual amplitude and phase values in relation to perceptual differences. Our architecture presents several bottlenecks while preserving the spectral structure of the audio wave via skip-connections. We also compare several task metrics and demonstrate our visual guide to loss selection. Moreover, we show how to leverage differential quantization techniques to reduce the initial model size by more than half while simultaneously reducing inference time, which is crucial in real-world applications.
TE-YOLOF: Tiny and efficient YOLOF for blood cell detection
Aug 27, 2021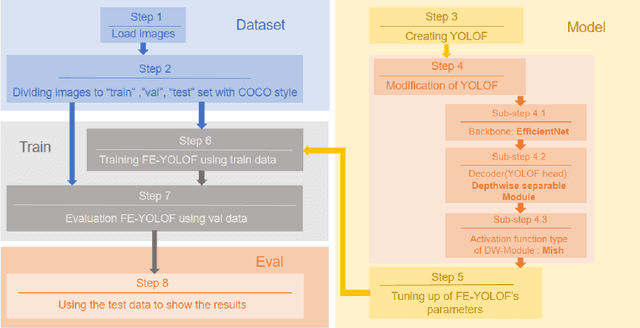
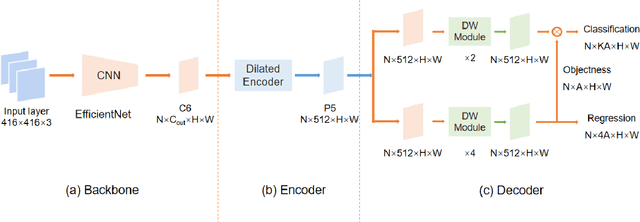
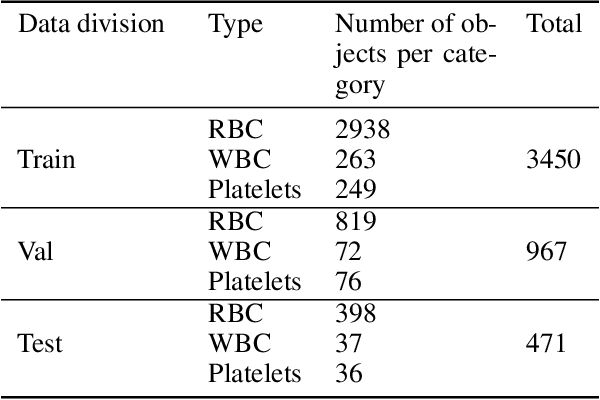
Blood cell detection in microscopic images is an essential branch of medical image processing research. Since disease detection based on manual checking of blood cells is time-consuming and full of errors, testing of blood cells using object detectors with Deep Convolutional Neural Network can be regarded as a feasible solution. In this work, an object detector based on YOLOF has been proposed to detect blood cell objects such as red blood cells, white blood cells and platelets. This object detector is called TE-YOLOF, Tiny and Efficient YOLOF, and it is a One-Stage detector using dilated encoder to extract information from single-level feature maps. For increasing efficiency and flexibility, the EfficientNet Convolutional Neural Network is utilized as the backbone for the proposed object detector. Furthermore, the Depthwise Separable Convolution is applied to enhance the performance and minimize the parameters of the network. In addition, the Mish activation function is employed to increase the precision. Extensive experiments on the BCCD dataset prove the effectiveness of the proposed model, which is more efficient than other existing studies for blood cell detection.
Convolutional Neural Network (CNN) vs Visual Transformer (ViT) for Digital Holography
Aug 20, 2021
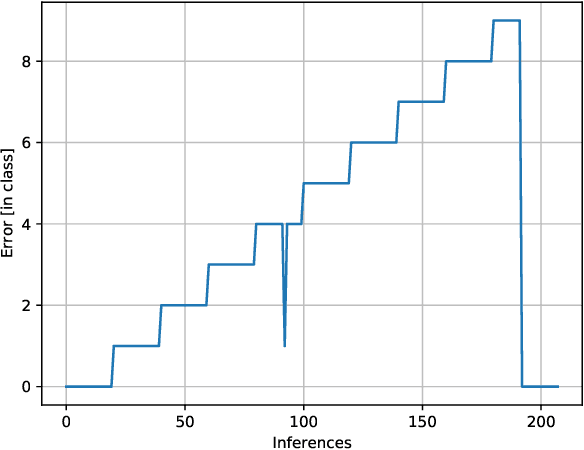
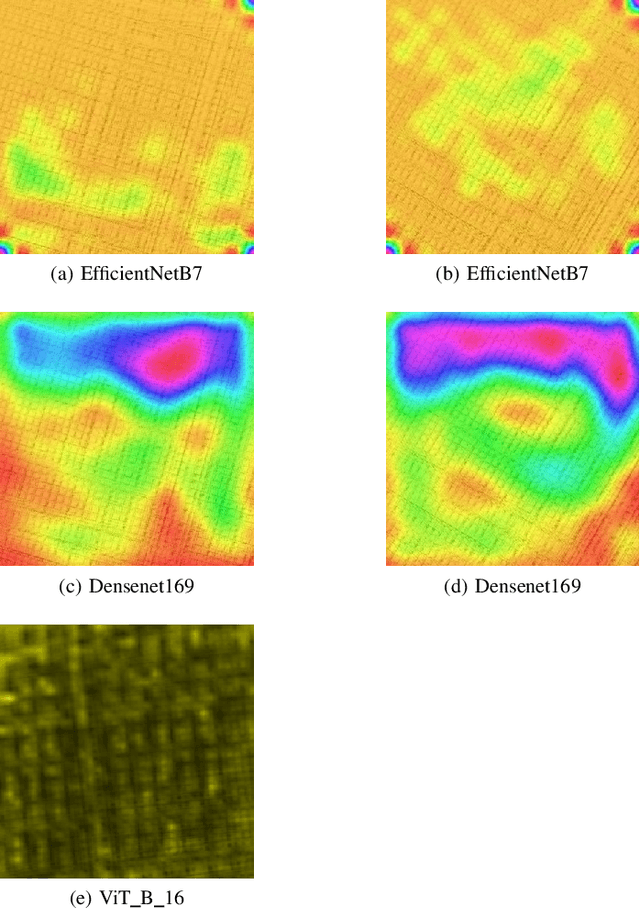

In Digital Holography (DH), it is crucial to extract the object distance from a hologram in order to reconstruct its amplitude and phase. This step is called auto-focusing and it is conventionally solved by first reconstructing a stack of images and then by sharpening each reconstructed image using a focus metric such as entropy or variance. The distance corresponding to the sharpest image is considered the focal position. This approach, while effective, is computationally demanding and time-consuming. In this paper, the determination of the distance is performed by Deep Learning (DL). Two deep learning (DL) architectures are compared: Convolutional Neural Network (CNN)and Visual transformer (ViT). ViT and CNN are used to cope with the problem of auto-focusing as a classification problem. Compared to a first attempt [11] in which the distance between two consecutive classes was 100{\mu}m, our proposal allows us to drastically reduce this distance to 1{\mu}m. Moreover, ViT reaches similar accuracy and is more robust than CNN.
CARRNN: A Continuous Autoregressive Recurrent Neural Network for Deep Representation Learning from Sporadic Temporal Data
Apr 08, 2021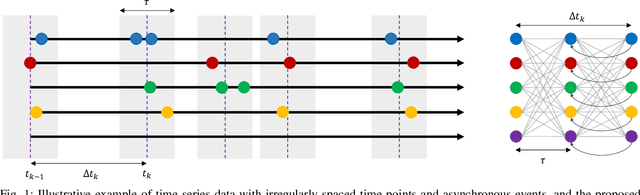
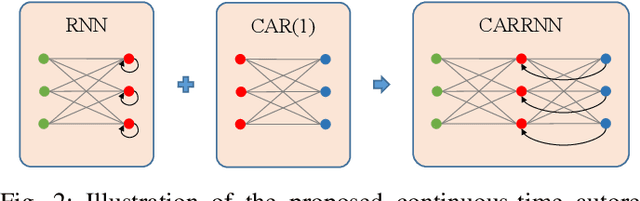
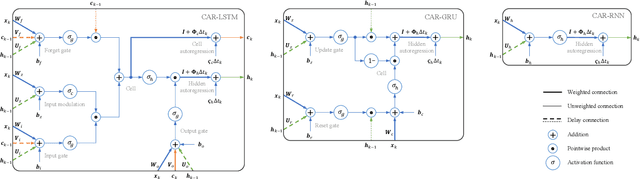
Learning temporal patterns from multivariate longitudinal data is challenging especially in cases when data is sporadic, as often seen in, e.g., healthcare applications where the data can suffer from irregularity and asynchronicity as the time between consecutive data points can vary across features and samples, hindering the application of existing deep learning models that are constructed for complete, evenly spaced data with fixed sequence lengths. In this paper, a novel deep learning-based model is developed for modeling multiple temporal features in sporadic data using an integrated deep learning architecture based on a recurrent neural network (RNN) unit and a continuous-time autoregressive (CAR) model. The proposed model, called CARRNN, uses a generalized discrete-time autoregressive model that is trainable end-to-end using neural networks modulated by time lags to describe the changes caused by the irregularity and asynchronicity. It is applied to multivariate time-series regression tasks using data provided for Alzheimer's disease progression modeling and intensive care unit (ICU) mortality rate prediction, where the proposed model based on a gated recurrent unit (GRU) achieves the lowest prediction errors among the proposed RNN-based models and state-of-the-art methods using GRUs and long short-term memory (LSTM) networks in their architecture.
pAElla: Edge-AI based Real-Time Malware Detection in Data Centers
Apr 07, 2020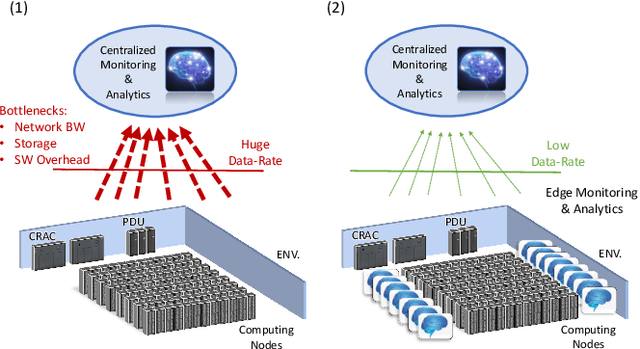
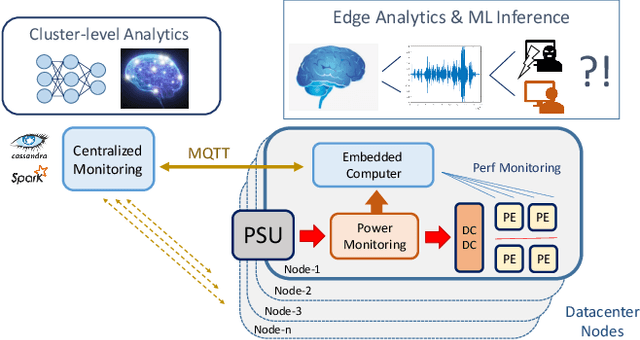
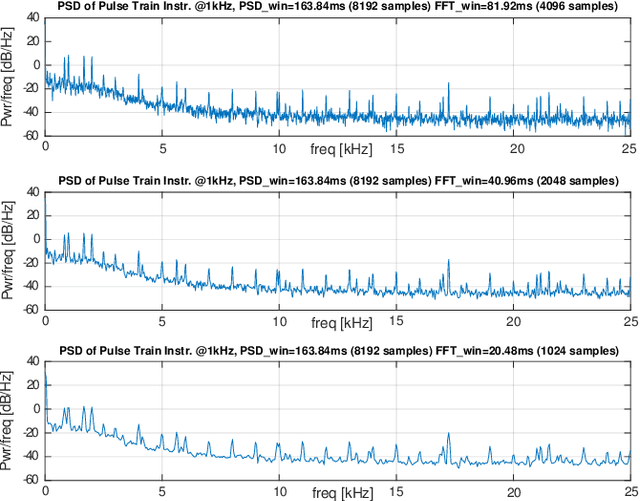
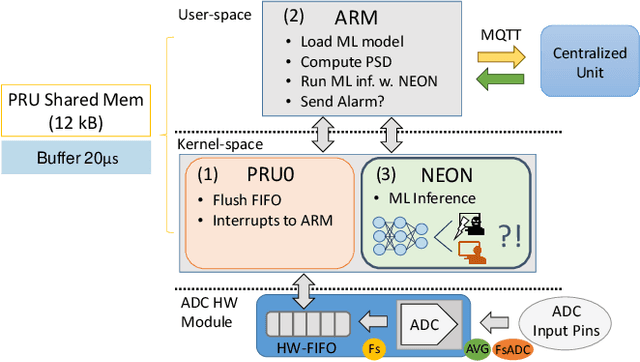
The increasing use of Internet-of-Things (IoT) devices for monitoring a wide spectrum of applications, along with the challenges of "big data" streaming support they often require for data analysis, is nowadays pushing for an increased attention to the emerging edge computing paradigm. In particular, smart approaches to manage and analyze data directly on the network edge, are more and more investigated, and Artificial Intelligence (AI) powered edge computing is envisaged to be a promising direction. In this paper, we focus on Data Centers (DCs) and Supercomputers (SCs), where a new generation of high-resolution monitoring systems is being deployed, opening new opportunities for analysis like anomaly detection and security, but introducing new challenges for handling the vast amount of data it produces. In detail, we report on a novel lightweight and scalable approach to increase the security of DCs/SCs, that involves AI-powered edge computing on high-resolution power consumption. The method -- called pAElla -- targets real-time Malware Detection (MD), it runs on an out-of-band IoT-based monitoring system for DCs/SCs, and involves Power Spectral Density of power measurements, along with AutoEncoders. Results are promising, with an F1-score close to 1, and a False Alarm and Malware Miss rate close to 0%. We compare our method with State-of-the-Art MD techniques and show that, in the context of DCs/SCs, pAElla can cover a wider range of malware, significantly outperforming SoA approaches in terms of accuracy. Moreover, we propose a methodology for online training suitable for DCs/SCs in production, and release open dataset and code.
Adversarial Generation of Time-Frequency Features with application in audio synthesis
Feb 11, 2019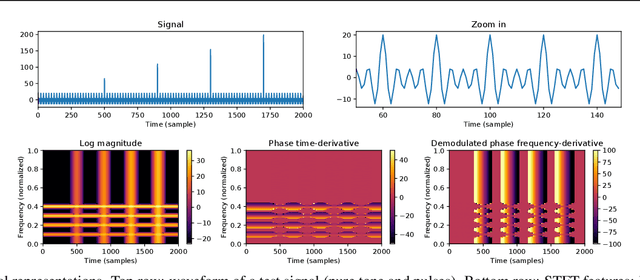

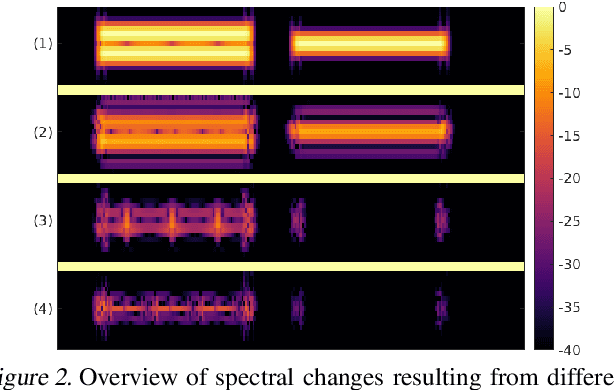
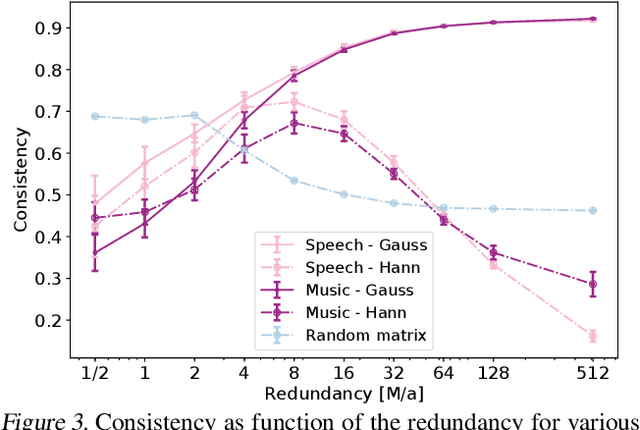
Time-frequency (TF) representations provide powerful and intuitive features for the analysis of time series such as audio. But still, generative modeling of audio in the TF domain is a subtle matter. Consequently, neural audio synthesis widely relies on directly modeling the waveform and previous attempts at unconditionally synthesizing audio from neurally generated TF features still struggle to produce audio at satisfying quality. In this contribution, focusing on the short-time Fourier transform, we discuss the challenges that arise in audio synthesis based on generated TF features and how to overcome them. We demonstrate the potential of deliberate generative TF modeling by training a generative adversarial network (GAN) on short-time Fourier features. We show that our TF-based network was able to outperform the state-of-the-art GAN generating waveform, despite the similar architecture in the two networks.
Semi-supervised Network Embedding with Differentiable Deep Quantisation
Aug 20, 2021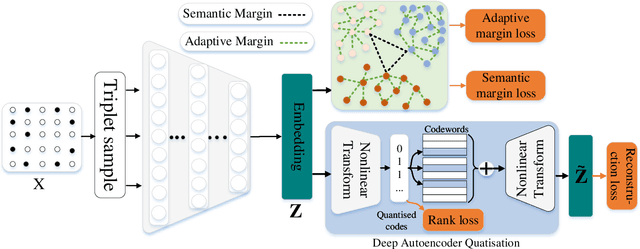
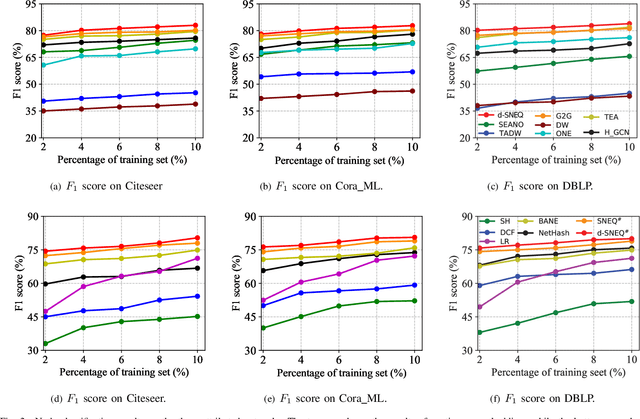
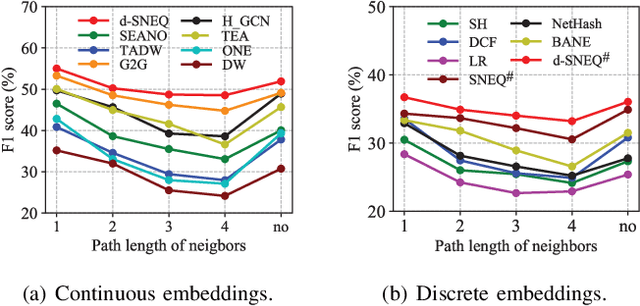
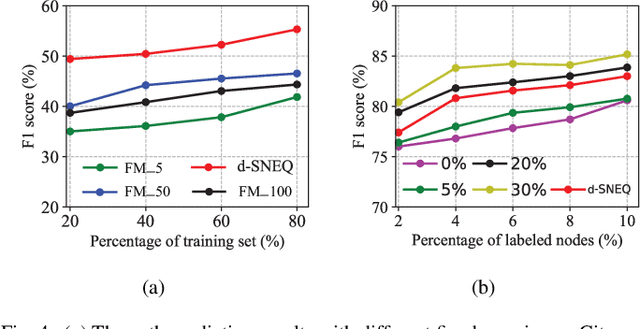
Learning accurate low-dimensional embeddings for a network is a crucial task as it facilitates many downstream network analytics tasks. For large networks, the trained embeddings often require a significant amount of space to store, making storage and processing a challenge. Building on our previous work on semi-supervised network embedding, we develop d-SNEQ, a differentiable DNN-based quantisation method for network embedding. d-SNEQ incorporates a rank loss to equip the learned quantisation codes with rich high-order information and is able to substantially compress the size of trained embeddings, thus reducing storage footprint and accelerating retrieval speed. We also propose a new evaluation metric, path prediction, to fairly and more directly evaluate model performance on the preservation of high-order information. Our evaluation on four real-world networks of diverse characteristics shows that d-SNEQ outperforms a number of state-of-the-art embedding methods in link prediction, path prediction, node classification, and node recommendation while being far more space- and time-efficient.
Improved Image Matting via Real-time User Clicks and Uncertainty Estimation
Dec 15, 2020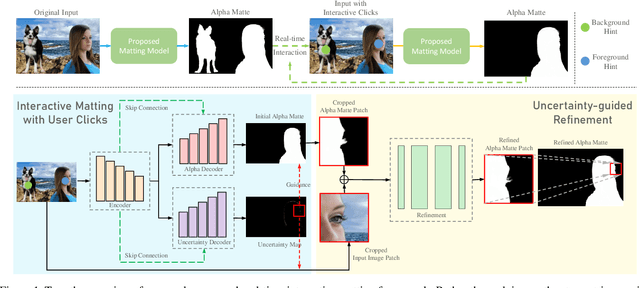
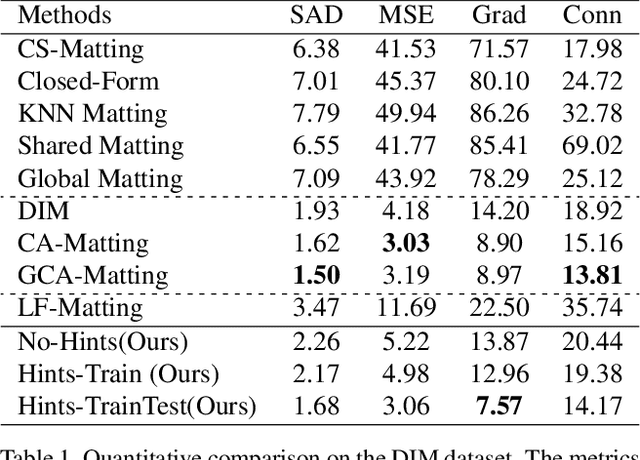

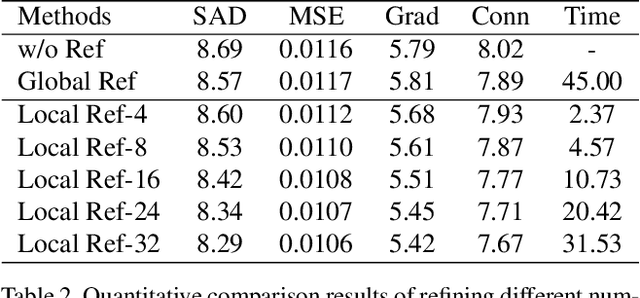
Image matting is a fundamental and challenging problem in computer vision and graphics. Most existing matting methods leverage a user-supplied trimap as an auxiliary input to produce good alpha matte. However, obtaining high-quality trimap itself is arduous, thus restricting the application of these methods. Recently, some trimap-free methods have emerged, however, the matting quality is still far behind the trimap-based methods. The main reason is that, without the trimap guidance in some cases, the target network is ambiguous about which is the foreground target. In fact, choosing the foreground is a subjective procedure and depends on the user's intention. To this end, this paper proposes an improved deep image matting framework which is trimap-free and only needs several user click interactions to eliminate the ambiguity. Moreover, we introduce a new uncertainty estimation module that can predict which parts need polishing and a following local refinement module. Based on the computation budget, users can choose how many local parts to improve with the uncertainty guidance. Quantitative and qualitative results show that our method performs better than existing trimap-free methods and comparably to state-of-the-art trimap-based methods with minimal user effort.