 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalk, Evaluate, Diagnose: User-aware Agent Evaluation with Automated Error Analysis
Mar 16, 2026Agent applications are increasingly adopted to automate workflows across diverse tasks. However, due to the heterogeneous domains they operate in, it is challenging to create a scalable evaluation framework. Prior works each employ their own methods to determine task success, such as database lookups, regex match, etc., adding complexity to the development of a unified agent evaluation approach. Moreover, they do not systematically account for the user's role nor expertise in the interaction, providing incomplete insights into the agent's performance. We argue that effective agent evaluation goes beyond correctness alone, incorporating conversation quality, efficiency and systematic diagnosis of agent errors. To address this, we introduce the TED framework (Talk, Evaluate, Diagnose). (1) Talk: We leverage reusable, generic expert and non-expert user persona templates for user-agent interaction. (2) Evaluate: We adapt existing datasets by representing subgoals-such as tool signatures, and responses-as natural language grading notes, evaluated automatically with LLM-as-a-judge. We propose new metrics that capture both turn efficiency and intermediate progress of the agent complementing the user-aware setup. (3) Diagnose: We introduce an automated error analysis tool that analyzes the inconsistencies of the judge and agents, uncovering common errors, and providing actionable feedback for agent improvement. We show that our TED framework reveals new insights regarding agent performance across models and user expertise levels. We also demonstrate potential gains in agent performance with peaks of 8-10% on our proposed metrics after incorporating the identified error remedies into the agent's design.
MS-GAGA: Metric-Selective Guided Adversarial Generation Attack
Oct 14, 2025We present MS-GAGA (Metric-Selective Guided Adversarial Generation Attack), a two-stage framework for crafting transferable and visually imperceptible adversarial examples against deepfake detectors in black-box settings. In Stage 1, a dual-stream attack module generates adversarial candidates: MNTD-PGD applies enhanced gradient calculations optimized for small perturbation budgets, while SG-PGD focuses perturbations on visually salient regions. This complementary design expands the adversarial search space and improves transferability across unseen models. In Stage 2, a metric-aware selection module evaluates candidates based on both their success against black-box models and their structural similarity (SSIM) to the original image. By jointly optimizing transferability and imperceptibility, MS-GAGA achieves up to 27% higher misclassification rates on unseen detectors compared to state-of-the-art attacks.
Audio Spectral Enhancement: Leveraging Autoencoders for Low Latency Reconstruction of Long, Lossy Audio Sequences
Aug 08, 2021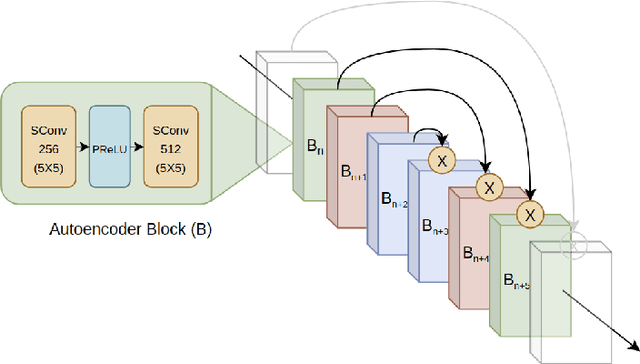
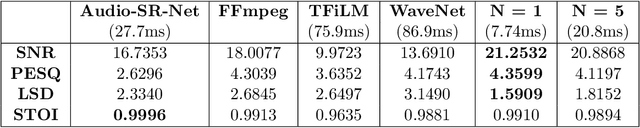
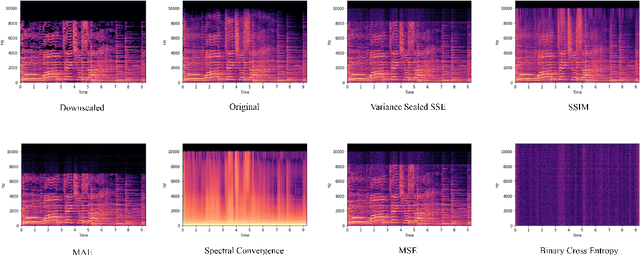
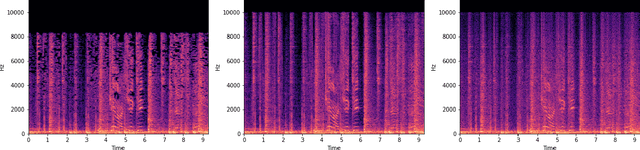
With active research in audio compression techniques yielding substantial breakthroughs, spectral reconstruction of low-quality audio waves remains a less indulged topic. In this paper, we propose a novel approach for reconstructing higher frequencies from considerably longer sequences of low-quality MP3 audio waves. Our technique involves inpainting audio spectrograms with residually stacked autoencoder blocks by manipulating individual amplitude and phase values in relation to perceptual differences. Our architecture presents several bottlenecks while preserving the spectral structure of the audio wave via skip-connections. We also compare several task metrics and demonstrate our visual guide to loss selection. Moreover, we show how to leverage differential quantization techniques to reduce the initial model size by more than half while simultaneously reducing inference time, which is crucial in real-world applications.