 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ContractNLI: A Dataset for Document-level Natural Language Inference for Contracts
Oct 05, 2021

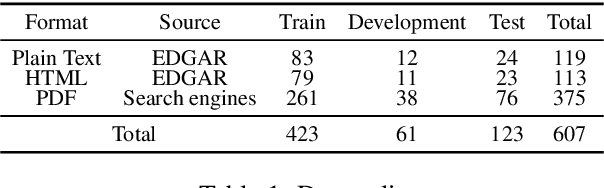

Reviewing contracts is a time-consuming procedure that incurs large expenses to companies and social inequality to those who cannot afford it. In this work, we propose "document-level natural language inference (NLI) for contracts", a novel, real-world application of NLI that addresses such problems. In this task, a system is given a set of hypotheses (such as "Some obligations of Agreement may survive termination.") and a contract, and it is asked to classify whether each hypothesis is "entailed by", "contradicting to" or "not mentioned by" (neutral to) the contract as well as identifying "evidence" for the decision as spans in the contract. We annotated and release the largest corpus to date consisting of 607 annotated contracts. We then show that existing models fail badly on our task and introduce a strong baseline, which (1) models evidence identification as multi-label classification over spans instead of trying to predict start and end tokens, and (2) employs more sophisticated context segmentation for dealing with long documents. We also show that linguistic characteristics of contracts, such as negations by exceptions, are contributing to the difficulty of this task and that there is much room for improvement.
A Real-time Vision Framework for Pedestrian Behavior Recognition and Intention Prediction at Intersections Using 3D Pose Estimation
Sep 23, 2020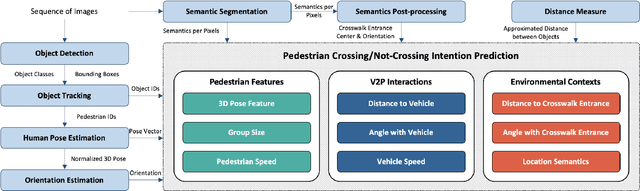
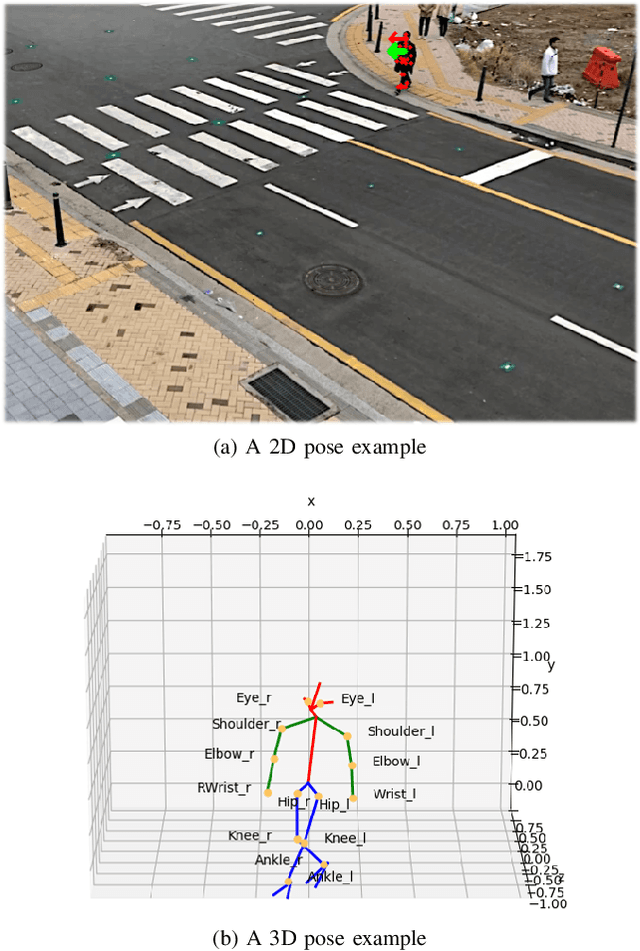
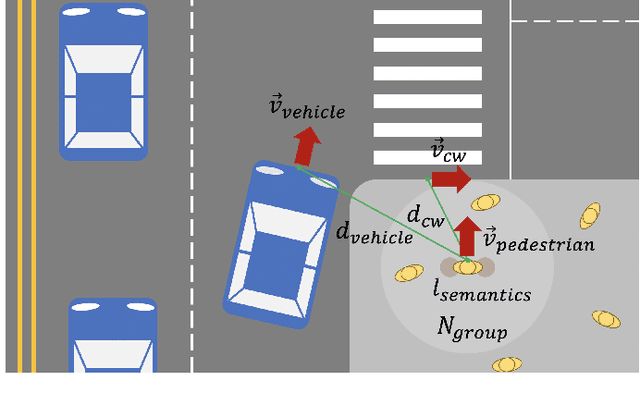

Minimizing traffic accidents between vehicles and pedestrians is one of the primary research goals in intelligent transportation systems. To achieve the goal, pedestrian behavior recognition and prediction of pedestrian's crossing or not-crossing intention play a central role. Contemporary approaches do not guarantee satisfactory performance due to lack of generalization, the requirement of manual data labeling, and high computational complexity. To overcome these limitations, we propose a real-time vision framework for two tasks: pedestrian behavior recognition (100.53 FPS) and intention prediction (35.76 FPS). Our framework obtains satisfying generalization over multiple sites because of the proposed site-independent features. At the center of the feature extraction lies 3D pose estimation. The 3D pose analysis enables robust and accurate recognition of pedestrian behaviors and prediction of intentions over multiple sites. The proposed vision framework realizes 89.3% accuracy in the behavior recognition task on the TUD dataset without any training process and 91.28% accuracy in intention prediction on our dataset achieving new state-of-the-art performance. To contribute to the corresponding research community, we make our source codes public which are available at https://github.com/Uehwan/VisionForPedestrian
Cooperative Assistance in Robotic Surgery through Multi-Agent Reinforcement Learning
Oct 10, 2021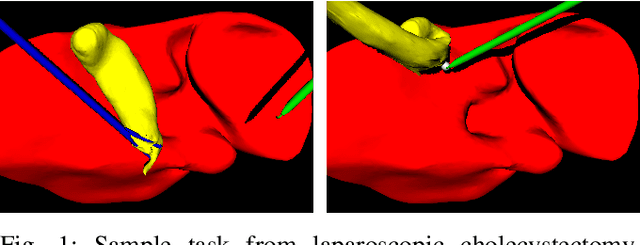

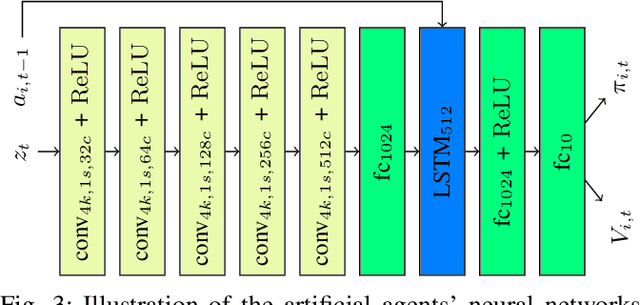
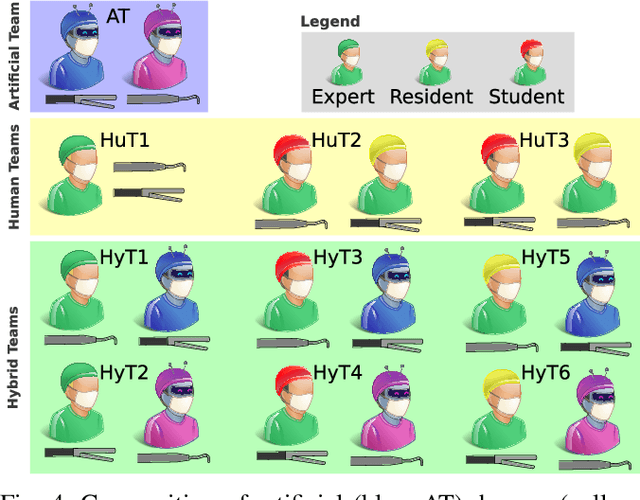
Cognitive cooperative assistance in robot-assisted surgery holds the potential to increase quality of care in minimally invasive interventions. Automation of surgical tasks promises to reduce the mental exertion and fatigue of surgeons. In this work, multi-agent reinforcement learning is demonstrated to be robust to the distribution shift introduced by pairing a learned policy with a human team member. Multi-agent policies are trained directly from images in simulation to control multiple instruments in a sub task of the minimally invasive removal of the gallbladder. These agents are evaluated individually and in cooperation with humans to demonstrate their suitability as autonomous assistants. Compared to human teams, the hybrid teams with artificial agents perform better considering completion time (44.4% to 71.2% shorter) as well as number of collisions (44.7% to 98.0% fewer). Path lengths, however, increase under control of an artificial agent (11.4% to 33.5% longer). A multi-agent formulation of the learning problem was favored over a single-agent formulation on this surgical sub task, due to the sequential learning of the two instruments. This approach may be extended to other tasks that are difficult to formulate within the standard reinforcement learning framework. Multi-agent reinforcement learning may shift the paradigm of cognitive robotic surgery towards seamless cooperation between surgeons and assistive technologies.
A Deep Reinforcement Learning Framework for Contention-Based Spectrum Sharing
Oct 05, 2021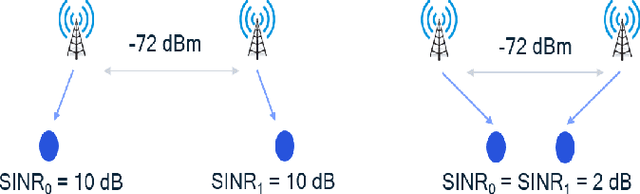
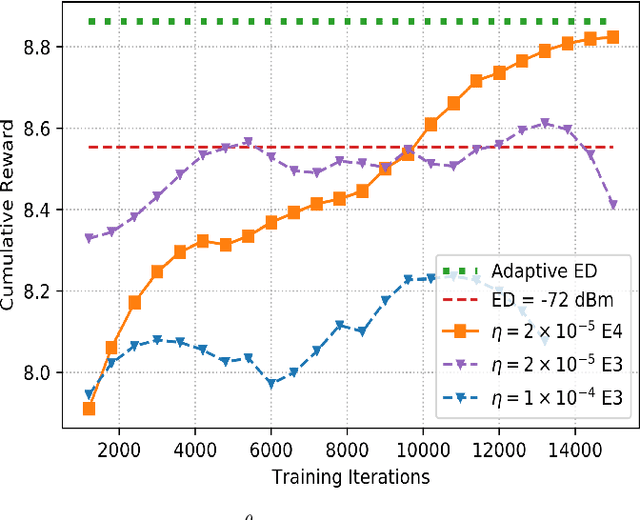
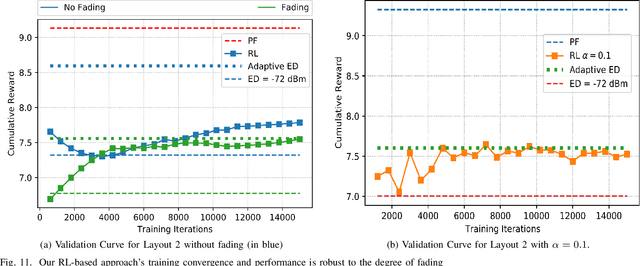
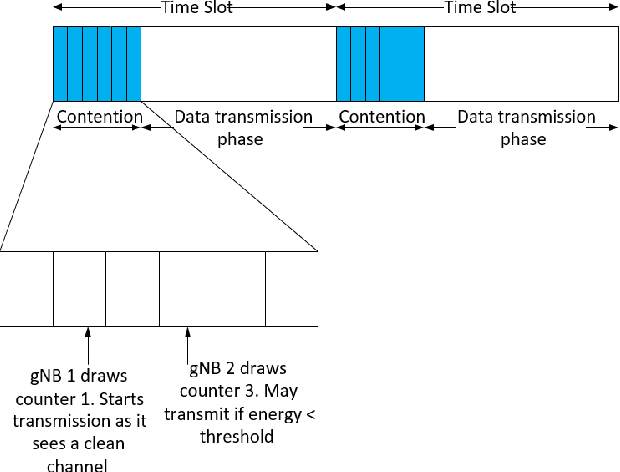
The increasing number of wireless devices operating in unlicensed spectrum motivates the development of intelligent adaptive approaches to spectrum access. We consider decentralized contention-based medium access for base stations (BSs) operating on unlicensed shared spectrum, where each BS autonomously decides whether or not to transmit on a given resource. The contention decision attempts to maximize not its own downlink throughput, but rather a network-wide objective. We formulate this problem as a decentralized partially observable Markov decision process with a novel reward structure that provides long term proportional fairness in terms of throughput. We then introduce a two-stage Markov decision process in each time slot that uses information from spectrum sensing and reception quality to make a medium access decision. Finally, we incorporate these features into a distributed reinforcement learning framework for contention-based spectrum access. Our formulation provides decentralized inference, online adaptability and also caters to partial observability of the environment through recurrent Q-learning. Empirically, we find its maximization of the proportional fairness metric to be competitive with a genie-aided adaptive energy detection threshold, while being robust to channel fading and small contention windows.
* 14 pages, 11 figures, 4 tables
Meta Learning on a Sequence of Imbalanced Domains with Difficulty Awareness
Sep 29, 2021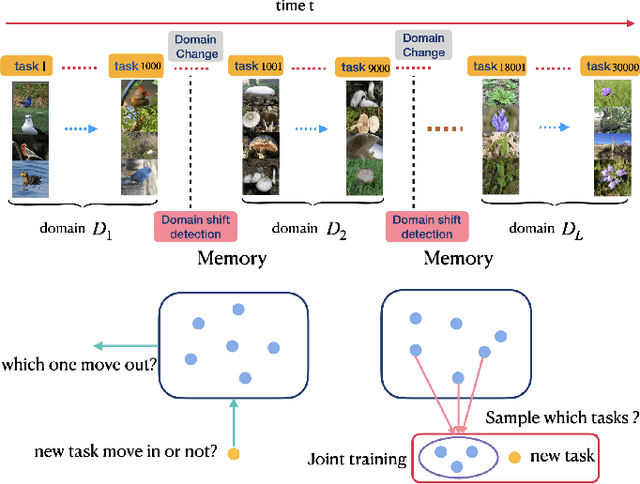
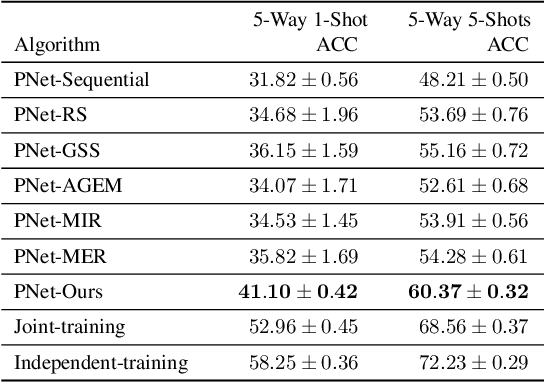
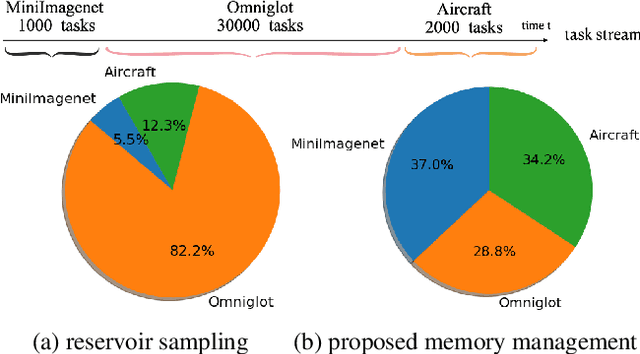
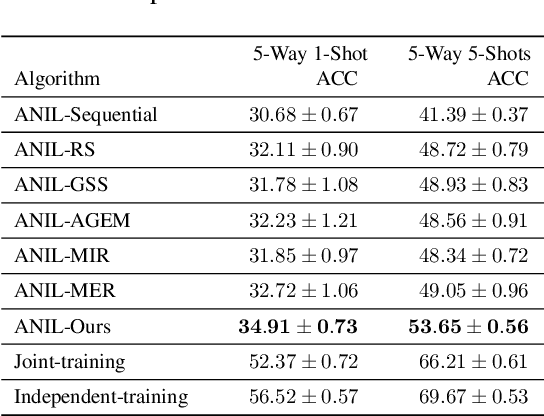
Recognizing new objects by learning from a few labeled examples in an evolving environment is crucial to obtain excellent generalization ability for real-world machine learning systems. A typical setting across current meta learning algorithms assumes a stationary task distribution during meta training. In this paper, we explore a more practical and challenging setting where task distribution changes over time with domain shift. Particularly, we consider realistic scenarios where task distribution is highly imbalanced with domain labels unavailable in nature. We propose a kernel-based method for domain change detection and a difficulty-aware memory management mechanism that jointly considers the imbalanced domain size and domain importance to learn across domains continuously. Furthermore, we introduce an efficient adaptive task sampling method during meta training, which significantly reduces task gradient variance with theoretical guarantees. Finally, we propose a challenging benchmark with imbalanced domain sequences and varied domain difficulty. We have performed extensive evaluations on the proposed benchmark, demonstrating the effectiveness of our method. We made our code publicly available.
Active Sampling for Linear Regression Beyond the $\ell_2$ Norm
Nov 09, 2021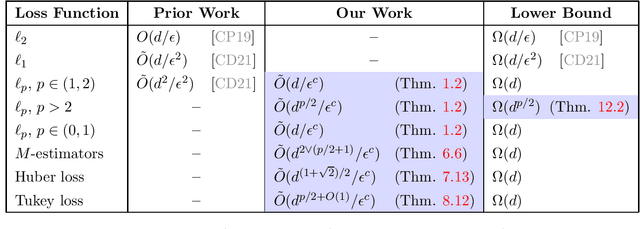
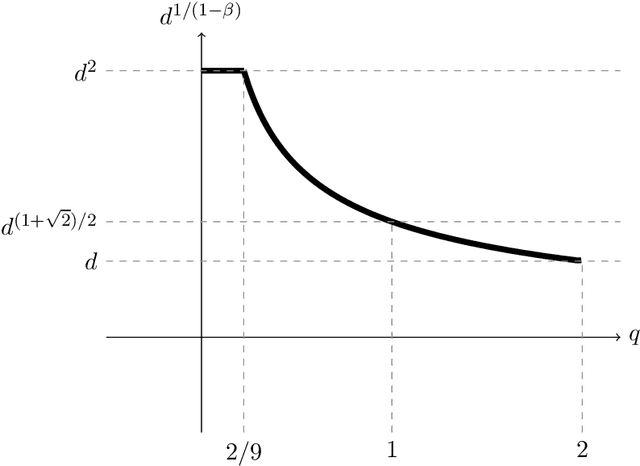
We study active sampling algorithms for linear regression, which aim to query only a small number of entries of a target vector $b\in\mathbb{R}^n$ and output a near minimizer to $\min_{x\in\mathbb{R}^d}\|Ax-b\|$, where $A\in\mathbb{R}^{n \times d}$ is a design matrix and $\|\cdot\|$ is some loss function. For $\ell_p$ norm regression for any $0<p<\infty$, we give an algorithm based on Lewis weight sampling that outputs a $(1+\epsilon)$ approximate solution using just $\tilde{O}(d^{\max(1,{p/2})}/\mathrm{poly}(\epsilon))$ queries to $b$. We show that this dependence on $d$ is optimal, up to logarithmic factors. Our result resolves a recent open question of Chen and Derezi\'{n}ski, who gave near optimal bounds for the $\ell_1$ norm, and suboptimal bounds for $\ell_p$ regression with $p\in(1,2)$. We also provide the first total sensitivity upper bound of $O(d^{\max\{1,p/2\}}\log^2 n)$ for loss functions with at most degree $p$ polynomial growth. This improves a recent result of Tukan, Maalouf, and Feldman. By combining this with our techniques for the $\ell_p$ regression result, we obtain an active regression algorithm making $\tilde O(d^{1+\max\{1,p/2\}}/\mathrm{poly}(\epsilon))$ queries, answering another open question of Chen and Derezi\'{n}ski. For the important special case of the Huber loss, we further improve our bound to an active sample complexity of $\tilde O(d^{(1+\sqrt2)/2}/\epsilon^c)$ and a non-active sample complexity of $\tilde O(d^{4-2\sqrt 2}/\epsilon^c)$, improving a previous $d^4$ bound for Huber regression due to Clarkson and Woodruff. Our sensitivity bounds have further implications, improving a variety of previous results using sensitivity sampling, including Orlicz norm subspace embeddings and robust subspace approximation. Finally, our active sampling results give the first sublinear time algorithms for Kronecker product regression under every $\ell_p$ norm.
Multi-axis Attentive Prediction for Sparse EventData: An Application to Crime Prediction
Oct 05, 2021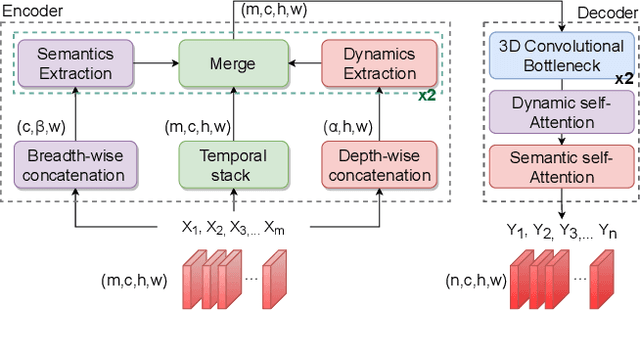

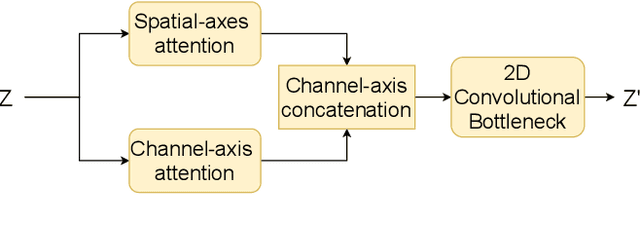
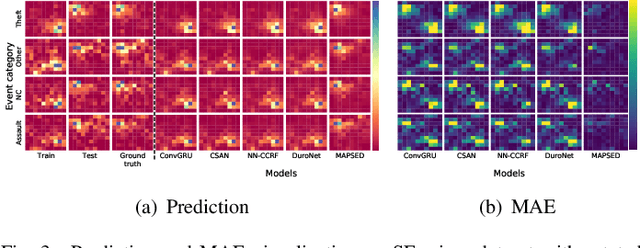
Spatiotemporal prediction of event data is a challenging task with a long history of research. While recent work in spatiotemporal prediction has leveraged deep sequential models that substantially improve over classical approaches, these models are prone to overfitting when the observation is extremely sparse, as in the task of crime event prediction. To overcome these sparsity issues, we present Multi-axis Attentive Prediction for Sparse Event Data (MAPSED). We propose a purely attentional approach to extract both short-term dynamics and long-term semantics of event propagation through two observation angles. Unlike existing temporal prediction models that propagate latent information primarily along the temporal dimension, the MAPSED simultaneously operates over all axes (time, 2D space, event type) of the embedded data tensor. We additionally introduce a novel Frobenius norm-based contrastive learning objective to improve latent representational generalization.Empirically, we validate MAPSED on two publicly accessible urban crime datasets for spatiotemporal sparse event prediction, where MAPSED outperforms both classical and state-of-the-art deep learning models. The proposed contrastive learning objective significantly enhances the MAPSED's ability to capture the semantics and dynamics of the events, resulting in better generalization ability to combat sparse observations.
EVARS-GPR: EVent-triggered Augmented Refitting of Gaussian Process Regression for Seasonal Data
Jul 06, 2021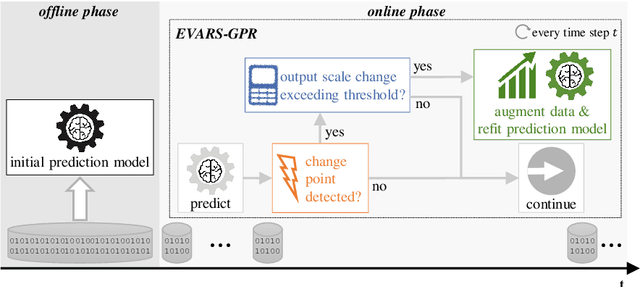
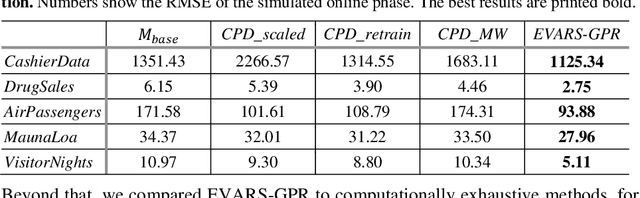
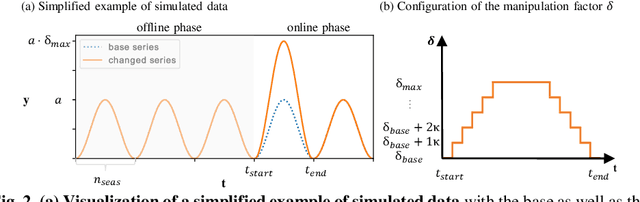
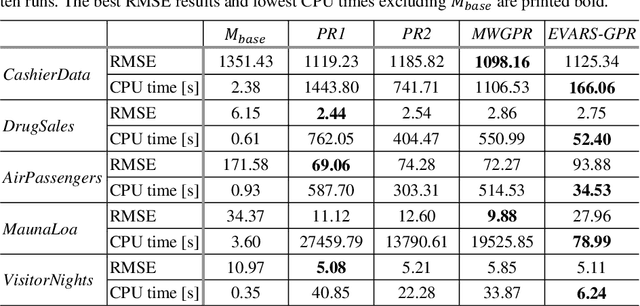
Time series forecasting is a growing domain with diverse applications. However, changes of the system behavior over time due to internal or external influences are challenging. Therefore, predictions of a previously learned fore-casting model might not be useful anymore. In this paper, we present EVent-triggered Augmented Refitting of Gaussian Process Regression for Seasonal Data (EVARS-GPR), a novel online algorithm that is able to handle sudden shifts in the target variable scale of seasonal data. For this purpose, EVARS-GPR com-bines online change point detection with a refitting of the prediction model using data augmentation for samples prior to a change point. Our experiments on sim-ulated data show that EVARS-GPR is applicable for a wide range of output scale changes. EVARS-GPR has on average a 20.8 % lower RMSE on different real-world datasets compared to methods with a similar computational resource con-sumption. Furthermore, we show that our algorithm leads to a six-fold reduction of the averaged runtime in relation to all comparison partners with a periodical refitting strategy. In summary, we present a computationally efficient online fore-casting algorithm for seasonal time series with changes of the target variable scale and demonstrate its functionality on simulated as well as real-world data. All code is publicly available on GitHub: https://github.com/grimmlab/evars-gpr.
Nothing Wasted: Full Contribution Enforcement in Federated Edge Learning
Oct 15, 2021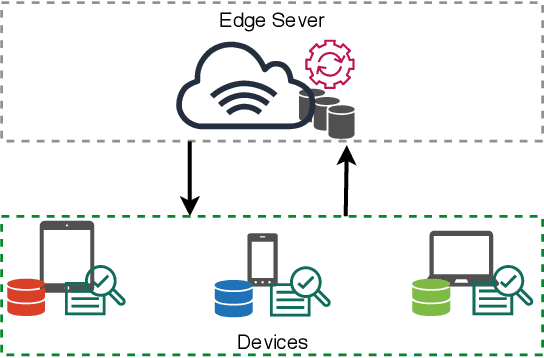

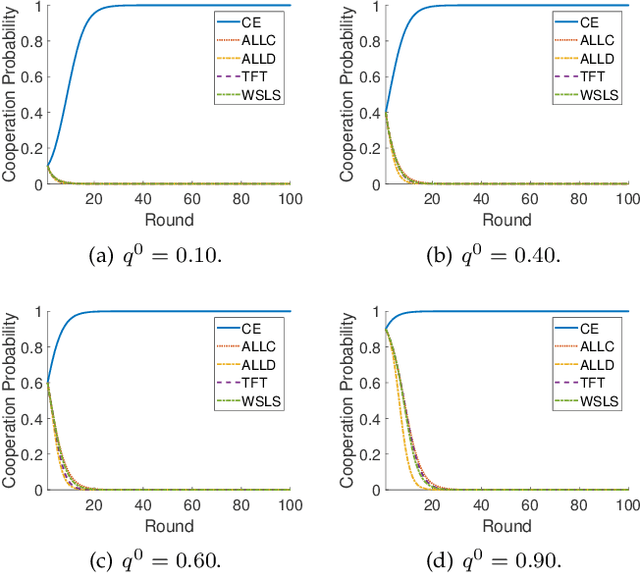
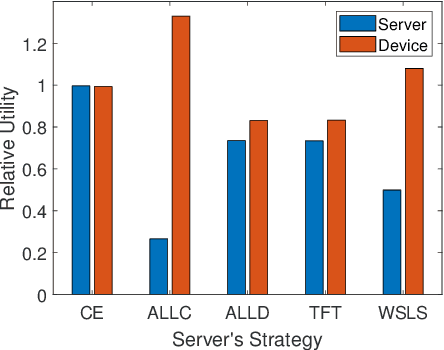
The explosive amount of data generated at the network edge makes mobile edge computing an essential technology to support real-time applications, calling for powerful data processing and analysis provided by machine learning (ML) techniques. In particular, federated edge learning (FEL) becomes prominent in securing the privacy of data owners by keeping the data locally used to train ML models. Existing studies on FEL either utilize in-process optimization or remove unqualified participants in advance. In this paper, we enhance the collaboration from all edge devices in FEL to guarantee that the ML model is trained using all available local data to accelerate the learning process. To that aim, we propose a collective extortion (CE) strategy under the imperfect-information multi-player FEL game, which is proved to be effective in helping the server efficiently elicit the full contribution of all devices without worrying about suffering from any economic loss. Technically, our proposed CE strategy extends the classical extortion strategy in controlling the proportionate share of expected utilities for a single opponent to the swiftly homogeneous control over a group of players, which further presents an attractive trait of being impartial for all participants. Moreover, the CE strategy enriches the game theory hierarchy, facilitating a wider application scope of the extortion strategy. Both theoretical analysis and experimental evaluations validate the effectiveness and fairness of our proposed scheme.
Dynamic Hilbert Maps: Real-Time Occupancy Predictions in Changing Environment
Dec 04, 2019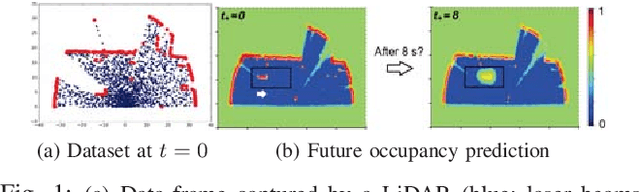
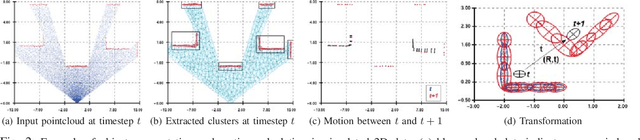
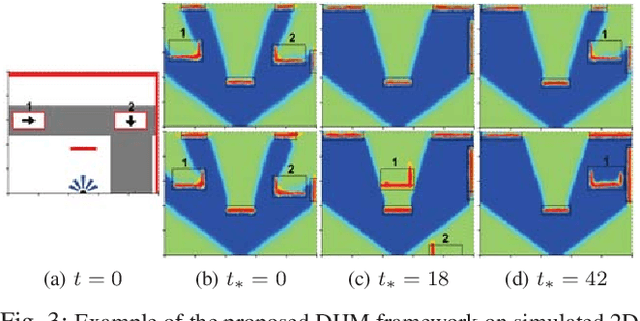
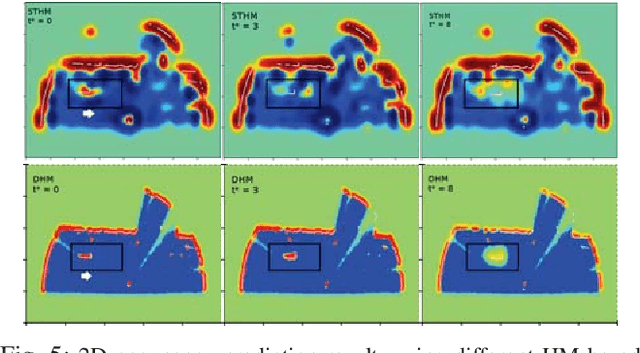
This paper addresses the problem of learning instantaneous occupancy levels of dynamic environments and predicting future occupancy levels. Due to the complexity of most real-world environments, such as urban streets or crowded areas, the efficient and robust incorporation of temporal dependencies into otherwise static occupancy models remains a challenge. We propose a method to capture the spatial uncertainty of moving objects and incorporate this uncertainty information into a continuous occupancy map represented in a rich high-dimensional feature space. Experiments performed using LIDAR data verified the real-time performance of the algorithm.