 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Dense Retrievers with LLM Utility via DistillationAligning Dense Retrievers with LLM Utility via Distillation
Apr 24, 2026Dense vector retrieval is the practical backbone of Retrieval- Augmented Generation (RAG), but similarity search can suffer from precision limitations. Conversely, utility-based approaches leveraging LLM re-ranking often achieve superior performance but are computationally prohibitive and prone to noise inherent in perplexity estimation. We propose Utility-Aligned Embeddings (UAE), a framework designed to merge these advantages into a practical, high-performance retrieval method. We formulate retrieval as a distribution matching problem, training a bi-encoder to imitate a utility distribution derived from perplexity reduction using a Utility-Modulated InfoNCE objective. This approach injects graded utility signals directly into the embedding space without requiring test-time LLM inference. On the QASPER benchmark, UAE improves retrieval Recall@1 by 30.59%, MAP by 30.16% and Token F1 by 17.3% over the strong semantic baseline BGE-Base. Crucially, UAE is over 180x faster than the efficient LLM re-ranking methods preserving competitive performance, demonstrating that aligning retrieval with generative utility yields reliable contexts at scale.
Response Quality Assessment for Retrieval-Augmented Generation via Conditional Conformal Factuality
Jun 26, 2025Existing research on Retrieval-Augmented Generation (RAG) primarily focuses on improving overall question-answering accuracy, often overlooking the quality of sub-claims within generated responses. Recent methods that attempt to improve RAG trustworthiness, such as through auto-evaluation metrics, lack probabilistic guarantees or require ground truth answers. To address these limitations, we propose Conformal-RAG, a novel framework inspired by recent applications of conformal prediction (CP) on large language models (LLMs). Conformal-RAG leverages CP and internal information from the RAG mechanism to offer statistical guarantees on response quality. It ensures group-conditional coverage spanning multiple sub-domains without requiring manual labelling of conformal sets, making it suitable for complex RAG applications. Compared to existing RAG auto-evaluation methods, Conformal-RAG offers statistical guarantees on the quality of refined sub-claims, ensuring response reliability without the need for ground truth answers. Additionally, our experiments demonstrate that by leveraging information from the RAG system, Conformal-RAG retains up to 60\% more high-quality sub-claims from the response compared to direct applications of CP to LLMs, while maintaining the same reliability guarantee.
Towards Understanding the Feasibility of Machine Unlearning
Oct 03, 2024In light of recent privacy regulations, machine unlearning has attracted significant attention in the research community. However, current studies predominantly assess the overall success of unlearning approaches, overlooking the varying difficulty of unlearning individual training samples. As a result, the broader feasibility of machine unlearning remains under-explored. This paper presents a set of novel metrics for quantifying the difficulty of unlearning by jointly considering the properties of target model and data distribution. Specifically, we propose several heuristics to assess the conditions necessary for a successful unlearning operation, examine the variations in unlearning difficulty across different training samples, and present a ranking mechanism to identify the most challenging samples to unlearn. We highlight the effectiveness of the Kernelized Stein Discrepancy (KSD), a parameterized kernel function tailored to each model and dataset, as a heuristic for evaluating unlearning difficulty. Our approach is validated through multiple classification tasks and established machine unlearning algorithms, demonstrating the practical feasibility of unlearning operations across diverse scenarios.
Towards Understanding Human Emotional Fluctuations with Sparse Check-In Data
Sep 10, 2024Data sparsity is a key challenge limiting the power of AI tools across various domains. The problem is especially pronounced in domains that require active user input rather than measurements derived from automated sensors. It is a critical barrier to harnessing the full potential of AI in domains requiring active user engagement, such as self-reported mood check-ins, where capturing a continuous picture of emotional states is essential. In this context, sparse data can hinder efforts to capture the nuances of individual emotional experiences such as causes, triggers, and contributing factors. Existing methods for addressing data scarcity often rely on heuristics or large established datasets, favoring deep learning models that lack adaptability to new domains. This paper proposes a novel probabilistic framework that integrates user-centric feedback-based learning, allowing for personalized predictions despite limited data. Achieving 60% accuracy in predicting user states among 64 options (chance of 1/64), this framework effectively mitigates data sparsity. It is versatile across various applications, bridging the gap between theoretical AI research and practical deployment.
Resolving Lexical Bias in Edit Scoping with Projector Editor Networks
Aug 19, 2024



Weight-preserving model editing techniques heavily rely on the scoping mechanism that decides when to apply an edit to the base model. These scoping mechanisms utilize distance functions in the representation space to ascertain the scope of the edit. In this work, we show that distance-based scoping functions grapple with lexical biases leading to issues such as misfires with irrelevant prompts that share similar lexical characteristics. To address this problem, we introduce, Projector Editor Networks for Model Editing (PENME),is a model editing approach that employs a compact adapter with a projection network trained via a contrastive learning objective. We demonstrate the efficacy of PENME in achieving superior results while being compute efficient and flexible to adapt across model architectures.
Data-centric Prediction Explanation via Kernelized Stein Discrepancy
Mar 22, 2024Existing example-based prediction explanation methods often bridge test and training data points through the model's parameters or latent representations. While these methods offer clues to the causes of model predictions, they often exhibit innate shortcomings, such as incurring significant computational overhead or producing coarse-grained explanations. This paper presents a Highly-precise and Data-centric Explanation (HD-Explain), a straightforward prediction explanation method exploiting properties of Kernelized Stein Discrepancy (KSD). Specifically, the KSD uniquely defines a parameterized kernel function for a trained model that encodes model-dependent data correlation. By leveraging the kernel function, one can identify training samples that provide the best predictive support to a test point efficiently. We conducted thorough analyses and experiments across multiple classification domains, where we show that HD-Explain outperforms existing methods from various aspects, including 1) preciseness (fine-grained explanation), 2) consistency, and 3) computation efficiency, leading to a surprisingly simple, effective, and robust prediction explanation solution.
Within-basket Recommendation via Neural Pattern Associator
Jan 25, 2024



Within-basket recommendation (WBR) refers to the task of recommending items to the end of completing a non-empty shopping basket during a shopping session. While the latest innovations in this space demonstrate remarkable performance improvement on benchmark datasets, they often overlook the complexity of user behaviors in practice, such as 1) co-existence of multiple shopping intentions, 2) multi-granularity of such intentions, and 3) interleaving behavior (switching intentions) in a shopping session. This paper presents Neural Pattern Associator (NPA), a deep item-association-mining model that explicitly models the aforementioned factors. Specifically, inspired by vector quantization, the NPA model learns to encode common user intentions (or item-combination patterns) as quantized representations (a.k.a. codebook), which permits identification of users's shopping intentions via attention-driven lookup during the reasoning phase. This yields coherent and self-interpretable recommendations. We evaluated the proposed NPA model across multiple extensive datasets, encompassing the domains of grocery e-commerce (shopping basket completion) and music (playlist extension), where our quantitative evaluations show that the NPA model significantly outperforms a wide range of existing WBR solutions, reflecting the benefit of explicitly modeling complex user intentions.
Self-supervised Representation Learning From Random Data Projectors
Oct 11, 2023

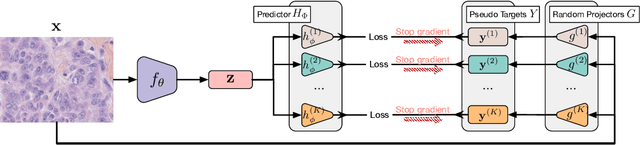
Self-supervised representation learning~(SSRL) has advanced considerably by exploiting the transformation invariance assumption under artificially designed data augmentations. While augmentation-based SSRL algorithms push the boundaries of performance in computer vision and natural language processing, they are often not directly applicable to other data modalities, and can conflict with application-specific data augmentation constraints. This paper presents an SSRL approach that can be applied to any data modality and network architecture because it does not rely on augmentations or masking. Specifically, we show that high-quality data representations can be learned by reconstructing random data projections. We evaluate the proposed approach on a wide range of representation learning tasks that span diverse modalities and real-world applications. We show that it outperforms multiple state-of-the-art SSRL baselines. Due to its wide applicability and strong empirical results, we argue that learning from randomness is a fruitful research direction worthy of attention and further study.
fAux: Testing Individual Fairness via Gradient Alignment
Oct 10, 2022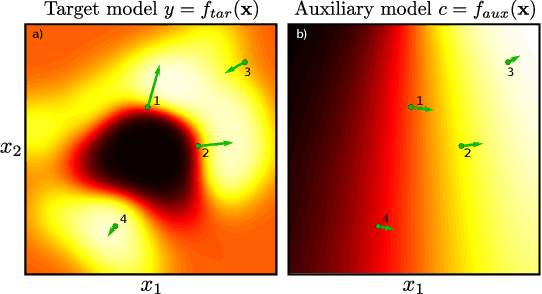
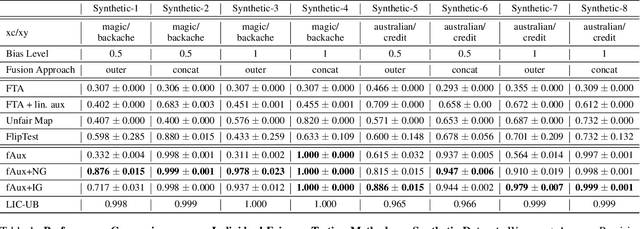
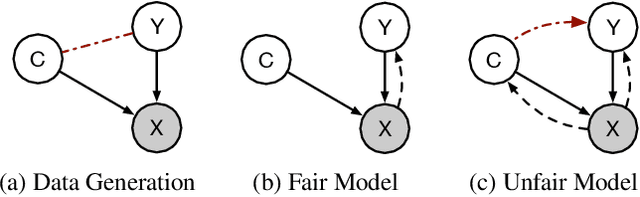
Machine learning models are vulnerable to biases that result in unfair treatment of individuals from different populations. Recent work that aims to test a model's fairness at the individual level either relies on domain knowledge to choose metrics, or on input transformations that risk generating out-of-domain samples. We describe a new approach for testing individual fairness that does not have either requirement. We propose a novel criterion for evaluating individual fairness and develop a practical testing method based on this criterion which we call fAux (pronounced fox). This is based on comparing the derivatives of the predictions of the model to be tested with those of an auxiliary model, which predicts the protected variable from the observed data. We show that the proposed method effectively identifies discrimination on both synthetic and real-world datasets, and has quantitative and qualitative advantages over contemporary methods.
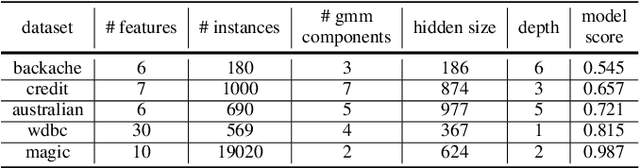
Scalable Whitebox Attacks on Tree-based Models
Mar 31, 2022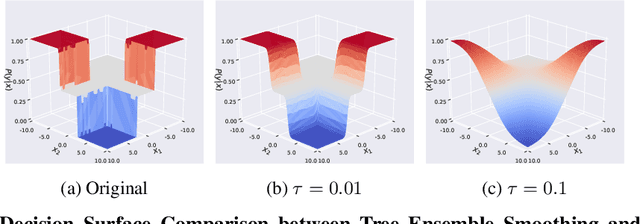
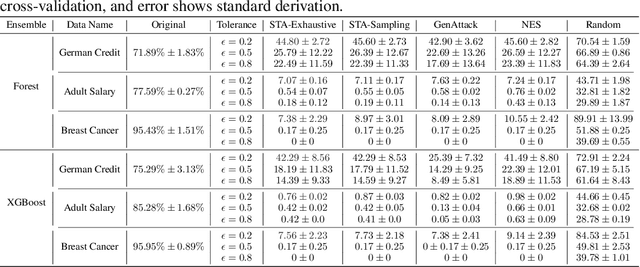
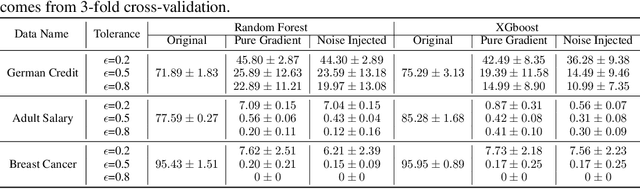
Adversarial robustness is one of the essential safety criteria for guaranteeing the reliability of machine learning models. While various adversarial robustness testing approaches were introduced in the last decade, we note that most of them are incompatible with non-differentiable models such as tree ensembles. Since tree ensembles are widely used in industry, this reveals a crucial gap between adversarial robustness research and practical applications. This paper proposes a novel whitebox adversarial robustness testing approach for tree ensemble models. Concretely, the proposed approach smooths the tree ensembles through temperature controlled sigmoid functions, which enables gradient descent-based adversarial attacks. By leveraging sampling and the log-derivative trick, the proposed approach can scale up to testing tasks that were previously unmanageable. We compare the approach against both random perturbations and blackbox approaches on multiple public datasets (and corresponding models). Our results show that the proposed method can 1) successfully reveal the adversarial vulnerability of tree ensemble models without causing computational pressure for testing and 2) flexibly balance the search performance and time complexity to meet various testing criteria.