 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolySHAP: Extending KernelSHAP with Interaction-Informed Polynomial Regression
Jan 26, 2026Shapley values have emerged as a central game-theoretic tool in explainable AI (XAI). However, computing Shapley values exactly requires $2^d$ game evaluations for a model with $d$ features. Lundberg and Lee's KernelSHAP algorithm has emerged as a leading method for avoiding this exponential cost. KernelSHAP approximates Shapley values by approximating the game as a linear function, which is fit using a small number of game evaluations for random feature subsets. In this work, we extend KernelSHAP by approximating the game via higher degree polynomials, which capture non-linear interactions between features. Our resulting PolySHAP method yields empirically better Shapley value estimates for various benchmark datasets, and we prove that these estimates are consistent. Moreover, we connect our approach to paired sampling (antithetic sampling), a ubiquitous modification to KernelSHAP that improves empirical accuracy. We prove that paired sampling outputs exactly the same Shapley value approximations as second-order PolySHAP, without ever fitting a degree 2 polynomial. To the best of our knowledge, this finding provides the first strong theoretical justification for the excellent practical performance of the paired sampling heuristic.
Efficiently Constructing Sparse Navigable Graphs
Jul 17, 2025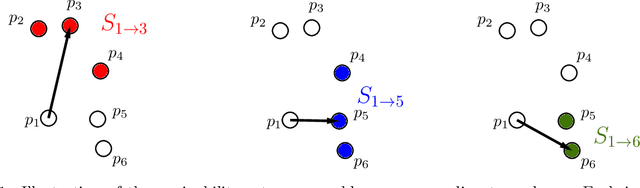



Graph-based nearest neighbor search methods have seen a surge of popularity in recent years, offering state-of-the-art performance across a wide variety of applications. Central to these methods is the task of constructing a sparse navigable search graph for a given dataset endowed with a distance function. Unfortunately, doing so is computationally expensive, so heuristics are universally used in practice. In this work, we initiate the study of fast algorithms with provable guarantees for search graph construction. For a dataset with $n$ data points, the problem of constructing an optimally sparse navigable graph can be framed as $n$ separate but highly correlated minimum set cover instances. This yields a naive $O(n^3)$ time greedy algorithm that returns a navigable graph whose sparsity is at most $O(\log n)$ higher than optimal. We improve significantly on this baseline, taking advantage of correlation between the set cover instances to leverage techniques from streaming and sublinear-time set cover algorithms. Combined with problem-specific pre-processing techniques, we present an $\tilde{O}(n^2)$ time algorithm for constructing an $O(\log n)$-approximate sparsest navigable graph under any distance function. The runtime of our method is optimal up to logarithmic factors under the Strong Exponential Time Hypothesis via a reduction from Monochromatic Closest Pair. Moreover, we prove that, as with general set cover, obtaining better than an $O(\log n)$-approximation is NP-hard, despite the significant additional structure present in the navigable graph problem. Finally, we show that our techniques can also beat cubic time for the closely related and practically important problems of constructing $\alpha$-shortcut reachable and $\tau$-monotonic graphs, which are also used for nearest neighbor search. For such graphs, we obtain $\tilde{O}(n^{2.5})$ time or better algorithms.
Regression-adjusted Monte Carlo Estimators for Shapley Values and Probabilistic Values
Jun 13, 2025



With origins in game theory, probabilistic values like Shapley values, Banzhaf values, and semi-values have emerged as a central tool in explainable AI. They are used for feature attribution, data attribution, data valuation, and more. Since all of these values require exponential time to compute exactly, research has focused on efficient approximation methods using two techniques: Monte Carlo sampling and linear regression formulations. In this work, we present a new way of combining both of these techniques. Our approach is more flexible than prior algorithms, allowing for linear regression to be replaced with any function family whose probabilistic values can be computed efficiently. This allows us to harness the accuracy of tree-based models like XGBoost, while still producing unbiased estimates. From experiments across eight datasets, we find that our methods give state-of-the-art performance for estimating probabilistic values. For Shapley values, the error of our methods can be $6.5\times$ lower than Permutation SHAP (the most popular Monte Carlo method), $3.8\times$ lower than Kernel SHAP (the most popular linear regression method), and $2.6\times$ lower than Leverage SHAP (the prior state-of-the-art Shapley value estimator). For more general probabilistic values, we can obtain error $215\times$ lower than the best estimator from prior work.
The Polar Express: Optimal Matrix Sign Methods and Their Application to the Muon Algorithm
May 22, 2025



Computing the polar decomposition and the related matrix sign function, has been a well-studied problem in numerical analysis for decades. More recently, it has emerged as an important subroutine in deep learning, particularly within the Muon optimization framework. However, the requirements in this setting differ significantly from those of traditional numerical analysis. In deep learning, methods must be highly efficient and GPU-compatible, but high accuracy is often unnecessary. As a result, classical algorithms like Newton-Schulz (which suffers from slow initial convergence) and methods based on rational functions (which rely on QR decompositions or matrix inverses) are poorly suited to this context. In this work, we introduce Polar Express, a GPU-friendly algorithm for computing the polar decomposition. Like classical polynomial methods such as Newton-Schulz, our approach uses only matrix-matrix multiplications, making it GPU-compatible. Motivated by earlier work of Chen & Chow and Nakatsukasa & Freund, Polar Express adapts the polynomial update rule at each iteration by solving a minimax optimization problem, and we prove that it enjoys a strong worst-case optimality guarantee. This property ensures both rapid early convergence and fast asymptotic convergence. We also address finite-precision issues, making it stable in bfloat16 in practice. We apply Polar Express within the Muon optimization framework and show consistent improvements in validation loss on large-scale models such as GPT-2, outperforming recent alternatives across a range of learning rates.
Distance Adaptive Beam Search for Provably Accurate Graph-Based Nearest Neighbor Search
May 21, 2025Nearest neighbor search is central in machine learning, information retrieval, and databases. For high-dimensional datasets, graph-based methods such as HNSW, DiskANN, and NSG have become popular thanks to their empirical accuracy and efficiency. These methods construct a directed graph over the dataset and perform beam search on the graph to find nodes close to a given query. While significant work has focused on practical refinements and theoretical understanding of graph-based methods, many questions remain. We propose a new distance-based termination condition for beam search to replace the commonly used condition based on beam width. We prove that, as long as the search graph is navigable, our resulting Adaptive Beam Search method is guaranteed to approximately solve the nearest-neighbor problem, establishing a connection between navigability and the performance of graph-based search. We also provide extensive experiments on our new termination condition for both navigable graphs and approximately navigable graphs used in practice, such as HNSW and Vamana graphs. We find that Adaptive Beam Search outperforms standard beam search over a range of recall values, data sets, graph constructions, and target number of nearest neighbors. It thus provides a simple and practical way to improve the performance of popular methods.
Matrix Product Sketching via Coordinated Sampling
Jan 29, 2025



We revisit the well-studied problem of approximating a matrix product, $\mathbf{A}^T\mathbf{B}$, based on small space sketches $\mathcal{S}(\mathbf{A})$ and $\mathcal{S}(\mathbf{B})$ of $\mathbf{A} \in \R^{n \times d}$ and $\mathbf{B}\in \R^{n \times m}$. We are interested in the setting where the sketches must be computed independently of each other, except for the use of a shared random seed. We prove that, when $\mathbf{A}$ and $\mathbf{B}$ are sparse, methods based on \emph{coordinated random sampling} can outperform classical linear sketching approaches, like Johnson-Lindenstrauss Projection or CountSketch. For example, to obtain Frobenius norm error $\epsilon\|\mathbf{A}\|_F\|\mathbf{B}\|_F$, coordinated sampling requires sketches of size $O(s/\epsilon^2)$ when $\mathbf{A}$ and $\mathbf{B}$ have at most $s \leq d,m$ non-zeros per row. In contrast, linear sketching leads to sketches of size $O(d/\epsilon^2)$ and $O(m/\epsilon^2)$ for $\mathbf{A}$ and $\mathbf{B}$. We empirically evaluate our approach on two applications: 1) distributed linear regression in databases, a problem motivated by tasks like dataset discovery and augmentation, and 2) approximating attention matrices in transformer-based language models. In both cases, our sampling algorithms yield an order of magnitude improvement over linear sketching.
Provably Accurate Shapley Value Estimation via Leverage Score Sampling
Oct 02, 2024



Originally introduced in game theory, Shapley values have emerged as a central tool in explainable machine learning, where they are used to attribute model predictions to specific input features. However, computing Shapley values exactly is expensive: for a general model with $n$ features, $O(2^n)$ model evaluations are necessary. To address this issue, approximation algorithms are widely used. One of the most popular is the Kernel SHAP algorithm, which is model agnostic and remarkably effective in practice. However, to the best of our knowledge, Kernel SHAP has no strong non-asymptotic complexity guarantees. We address this issue by introducing Leverage SHAP, a light-weight modification of Kernel SHAP that provides provably accurate Shapley value estimates with just $O(n\log n)$ model evaluations. Our approach takes advantage of a connection between Shapley value estimation and agnostic active learning by employing leverage score sampling, a powerful regression tool. Beyond theoretical guarantees, we show that Leverage SHAP consistently outperforms even the highly optimized implementation of Kernel SHAP available in the ubiquitous SHAP library [Lundberg & Lee, 2017].
Benchmarking Estimators for Natural Experiments: A Novel Dataset and a Doubly Robust Algorithm
Sep 06, 2024



Estimating the effect of treatments from natural experiments, where treatments are pre-assigned, is an important and well-studied problem. We introduce a novel natural experiment dataset obtained from an early childhood literacy nonprofit. Surprisingly, applying over 20 established estimators to the dataset produces inconsistent results in evaluating the nonprofit's efficacy. To address this, we create a benchmark to evaluate estimator accuracy using synthetic outcomes, whose design was guided by domain experts. The benchmark extensively explores performance as real world conditions like sample size, treatment correlation, and propensity score accuracy vary. Based on our benchmark, we observe that the class of doubly robust treatment effect estimators, which are based on simple and intuitive regression adjustment, generally outperform other more complicated estimators by orders of magnitude. To better support our theoretical understanding of doubly robust estimators, we derive a closed form expression for the variance of any such estimator that uses dataset splitting to obtain an unbiased estimate. This expression motivates the design of a new doubly robust estimator that uses a novel loss function when fitting functions for regression adjustment. We release the dataset and benchmark in a Python package; the package is built in a modular way to facilitate new datasets and estimators.
Sharper Bounds for Chebyshev Moment Matching with Applications to Differential Privacy and Beyond
Aug 22, 2024We study the problem of approximately recovering a probability distribution given noisy measurements of its Chebyshev polynomial moments. We sharpen prior work, proving that accurate recovery in the Wasserstein distance is possible with more noise than previously known. As a main application, our result yields a simple "linear query" algorithm for constructing a differentially private synthetic data distribution with Wasserstein-1 error $\tilde{O}(1/n)$ based on a dataset of $n$ points in $[-1,1]$. This bound is optimal up to log factors and matches a recent breakthrough of Boedihardjo, Strohmer, and Vershynin [Probab. Theory. Rel., 2024], which uses a more complex "superregular random walk" method to beat an $O(1/\sqrt{n})$ accuracy barrier inherent to earlier approaches. We illustrate a second application of our new moment-based recovery bound in numerical linear algebra: by improving an approach of Braverman, Krishnan, and Musco [STOC 2022], our result yields a faster algorithm for estimating the spectral density of a symmetric matrix up to small error in the Wasserstein distance.
Coupling without Communication and Drafter-Invariant Speculative Decoding
Aug 15, 2024



Suppose Alice has a distribution $P$ and Bob has a distribution $Q$. Alice wants to generate a sample $a\sim P$ and Bob a sample $b \sim Q$ such that $a = b$ with has as high of probability as possible. It is well-known that, by sampling from an optimal coupling between the distributions, Alice and Bob can achieve $Pr[a = b] = 1 - D_{TV}(P,Q)$, where $D_{TV}(P,Q)$ is the total variation distance. What if Alice and Bob must solve this same problem without communicating at all? Perhaps surprisingly, with access to public randomness, they can still achieve $Pr[a = b] \geq \frac{1 - D_{TV}(P,Q)}{1 + D_{TV}(P,Q)} \geq 1-2D_{TV}(P,Q)$. In fact, this bound can be obtained using a simple protocol based on the Weighted MinHash algorithm. In this work, we explore the communication-free coupling in greater depth. First, we show that an equally simple protocol based on Gumbel sampling matches the worst-case guarantees of the Weighted MinHash approach, but tends to perform better in practice. Conversely, we prove that both approaches are actually sharp: no communication-free protocol can achieve $Pr[a=b]>\frac{1 - D_{TV}(P,Q)}{1 + D_{TV}(P,Q)}$ in the worst-case. Finally, we prove that, for distributions over $n$ items, there exists a scheme that uses just $O(\log(n/\epsilon))$ bits of communication to achieve $Pr[a = b] = 1 - D_{TV}(P,Q) - \epsilon$, i.e. to essentially match optimal coupling. Beyond our theoretical results, we demonstrate an application of communication-free coupling to speculative decoding, a recent method for accelerating autoregressive large language models [Leviathan, Kalman, Matias, ICML 2023]. We show that communication-free protocols yield a variant of speculative decoding that we call Drafter-Invariant Speculative Decoding, which has the desirable property that the output of the method is fixed given a fixed random seed, regardless of what drafter is used for speculation.