 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Segmentation for Autonomous Clip Positioning in Laparoscopic Cholecystectomy on a Phantom
Jun 10, 2026High-risk applications in robotics, such as robot-assisted surgery, present unique challenges. These systems must be both highly precise and interpretable in order to be deployed in environments with very low tolerance for error or unsafe exploration. We present the first robotic system to demonstrate autonomous clip positioning on a physical phantom in laparoscopic surgery, one of the most common interventions in general surgery. After segmentation of a colorless point cloud from a single camera, target positions for the clips are extracted using spline interpolation, and can then be adjusted by the human operator. The segmentation model is trained on only 60 hand-labeled real point clouds, reflecting data scarcity in the surgical domain. We overcome this with a combination of pre-training on 128,000 synthetic point clouds and two novel data augmentation techniques. The motion of the end-effector to each target is visualized for the operator, satisfying the unique motion constraints of minimally-invasive surgery while ensuring that the robot's actions are verifiable and interpretable. In real robot experiments, our system localizes targets with the required precision of 0.75mm at a 95% success rate and executes autonomous clip positioning with a 100% success rate. We provide insights that are applicable to many other surgical and non-surgical tasks that require identifying and navigating to a precise target. Source code and project page: https://github.com/balazsgyenes/kirurc
* 8 pages, 5 figures, accepted to IEEE Robotics and Automation Letters (RAL)
Open-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
LAR-MoE: Latent-Aligned Routing for Mixture of Experts in Robotic Imitation Learning
Mar 09, 2026Imitation learning enables robots to acquire manipulation skills from demonstrations, yet deploying a policy across tasks with heterogeneous dynamics remains challenging, as models tend to average over distinct behavioral modes present in the demonstrations. Mixture-of-Experts (MoE) architectures address this by activating specialized subnetworks, but requires meaningful skill decompositions for expert routing. We introduce Latent-Aligned Routing for Mixture of Experts (LAR-MoE), a two-stage framework that decouples unsupervised skill discovery from policy learning. In pre-training, we learn a joint latent representation between observations and future actions through student-teacher co-training. In a post-training stage, the expert routing is regularized to follow the structure of the learned latent space, preventing expert collapse while maintaining parameter efficiency. We evaluate LAR-MoE in simulation and on hardware. On the LIBERO benchmark, our method achieves a 95.2% average success rate with 150M parameters. On a surgical bowel grasping and retraction task, LAR-MoE matches a supervised MoE baseline without requiring any phase annotations, and transfers zero-shot to ex vivo porcine tissue. Our findings suggest that latent-aligned routing provides a principled alternative to supervised skill decomposition, enabling structured expert specialization from unlabeled demonstrations.
An Open-Source Robotics Research Platform for Autonomous Laparoscopic Surgery
Mar 09, 2026Autonomous robot-assisted surgery demands reliable, high-precision platforms that strictly adhere to the safety and kinematic constraints of minimally invasive procedures. Existing research platforms, primarily based on the da Vinci Research Kit, suffer from cable-driven mechanical limitations that degrade state-space consistency and hinder the downstream training of reliable autonomous policies. We present an open-source, robot-agnostic Remote Center of Motion (RCM) controller based on a closed-form analytical velocity solver that enforces the trocar constraint deterministically without iterative optimization. The controller operates in Cartesian space, enabling any industrial manipulator to function as a surgical robot. We provide implementations for the UR5e and Franka Emika Panda manipulators, and integrate stereoscopic 3D perception. We integrate the robot control into a full-stack ROS-based surgical robotics platform supporting teleoperation, demonstration recording, and deployment of learned policies via a decoupled server-client architecture. We validate the system on a bowel grasping and retraction task across phantom, ex vivo, and in vivo porcine laparoscopic procedures. RCM deviations remain sub-millimeter across all conditions, and trajectory smoothness metrics (SPARC, LDLJ) are comparable to expert demonstrations from the JIGSAWS benchmark recorded on the da Vinci system. These results demonstrate that the platform provides the precision and robustness required for teleoperation, data collection and autonomous policy deployment in realistic surgical scenarios.
The Dresden Dataset for 4D Reconstruction of Non-Rigid Abdominal Surgical Scenes
Mar 03, 2026The D4D Dataset provides paired endoscopic video and high-quality structured-light geometry for evaluating 3D reconstruction of deforming abdominal soft tissue in realistic surgical conditions. Data were acquired from six porcine cadaver sessions using a da Vinci Xi stereo endoscope and a Zivid structured-light camera, registered via optical tracking and manually curated iterative alignment methods. Three sequence types - whole deformations, incremental deformations, and moved-camera clips - probe algorithm robustness to non-rigid motion, deformation magnitude, and out-of-view updates. Each clip provides rectified stereo images, per-frame instrument masks, stereo depth, start/end structured-light point clouds, curated camera poses and camera intrinsics. In postprocessing, ICP and semi-automatic registration techniques are used to register data, and instrument masks are created. The dataset enables quantitative geometric evaluation in both visible and occluded regions, alongside photometric view-synthesis baselines. Comprising over 300,000 frames and 369 point clouds across 98 curated recordings, this resource can serve as a comprehensive benchmark for developing and evaluating non-rigid SLAM, 4D reconstruction, and depth estimation methods.
MoE-ACT: Improving Surgical Imitation Learning Policies through Supervised Mixture-of-Experts
Jan 29, 2026Imitation learning has achieved remarkable success in robotic manipulation, yet its application to surgical robotics remains challenging due to data scarcity, constrained workspaces, and the need for an exceptional level of safety and predictability. We present a supervised Mixture-of-Experts (MoE) architecture designed for phase-structured surgical manipulation tasks, which can be added on top of any autonomous policy. Unlike prior surgical robot learning approaches that rely on multi-camera setups or thousands of demonstrations, we show that a lightweight action decoder policy like Action Chunking Transformer (ACT) can learn complex, long-horizon manipulation from less than 150 demonstrations using solely stereo endoscopic images, when equipped with our architecture. We evaluate our approach on the collaborative surgical task of bowel grasping and retraction, where a robot assistant interprets visual cues from a human surgeon, executes targeted grasping on deformable tissue, and performs sustained retraction. We benchmark our method against state-of-the-art Vision-Language-Action (VLA) models and the standard ACT baseline. Our results show that generalist VLAs fail to acquire the task entirely, even under standard in-distribution conditions. Furthermore, while standard ACT achieves moderate success in-distribution, adopting a supervised MoE architecture significantly boosts its performance, yielding higher success rates in-distribution and demonstrating superior robustness in out-of-distribution scenarios, including novel grasp locations, reduced illumination, and partial occlusions. Notably, it generalizes to unseen testing viewpoints and also transfers zero-shot to ex vivo porcine tissue without additional training, offering a promising pathway toward in vivo deployment. To support this, we present qualitative preliminary results of policy roll-outs during in vivo porcine surgery.
Interactive Surgical Liver Phantom for Cholecystectomy Training
Sep 05, 2024



Training and prototype development in robot-assisted surgery requires appropriate and safe environments for the execution of surgical procedures. Current dry lab laparoscopy phantoms often lack the ability to mimic complex, interactive surgical tasks. This work presents an interactive surgical phantom for the cholecystectomy. The phantom enables the removal of the gallbladder during cholecystectomy by allowing manipulations and cutting interactions with the synthetic tissue. The force-displacement behavior of the gallbladder is modelled based on retraction demonstrations. The force model is compared to the force model of ex-vivo porcine gallbladders and evaluated on its ability to estimate retraction forces.
LapGym -- An Open Source Framework for Reinforcement Learning in Robot-Assisted Laparoscopic Surgery
Feb 19, 2023



Recent advances in reinforcement learning (RL) have increased the promise of introducing cognitive assistance and automation to robot-assisted laparoscopic surgery (RALS). However, progress in algorithms and methods depends on the availability of standardized learning environments that represent skills relevant to RALS. We present LapGym, a framework for building RL environments for RALS that models the challenges posed by surgical tasks, and sofa_env, a diverse suite of 12 environments. Motivated by surgical training, these environments are organized into 4 tracks: Spatial Reasoning, Deformable Object Manipulation & Grasping, Dissection, and Thread Manipulation. Each environment is highly parametrizable for increasing difficulty, resulting in a high performance ceiling for new algorithms. We use Proximal Policy Optimization (PPO) to establish a baseline for model-free RL algorithms, investigating the effect of several environment parameters on task difficulty. Finally, we show that many environments and parameter configurations reflect well-known, open problems in RL research, allowing researchers to continue exploring these fundamental problems in a surgical context. We aim to provide a challenging, standard environment suite for further development of RL for RALS, ultimately helping to realize the full potential of cognitive surgical robotics. LapGym is publicly accessible through GitHub (https://github.com/ScheiklP/lap_gym).
LapSeg3D: Weakly Supervised Semantic Segmentation of Point Clouds Representing Laparoscopic Scenes
Jul 15, 2022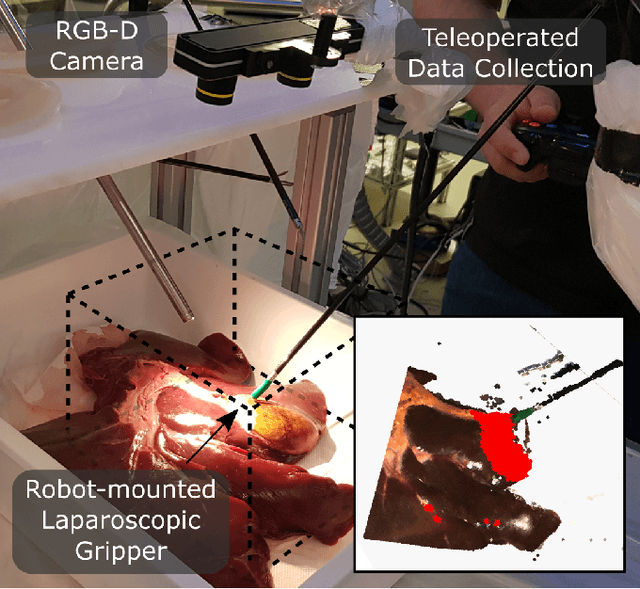
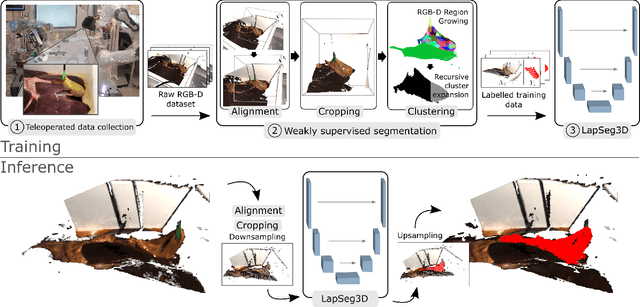
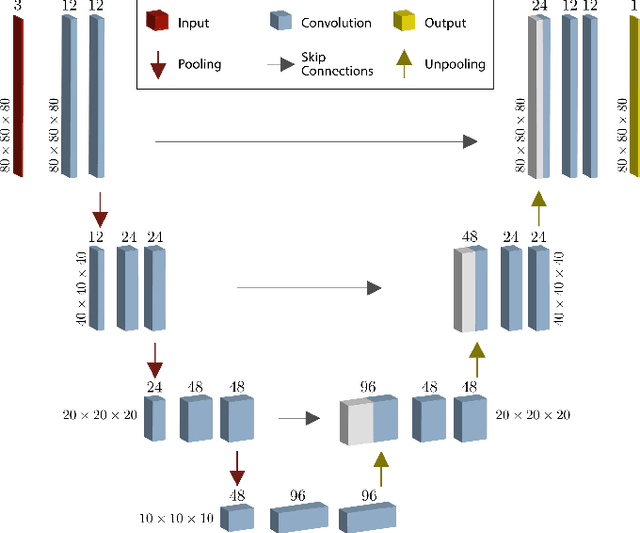

The semantic segmentation of surgical scenes is a prerequisite for task automation in robot assisted interventions. We propose LapSeg3D, a novel DNN-based approach for the voxel-wise annotation of point clouds representing surgical scenes. As the manual annotation of training data is highly time consuming, we introduce a semi-autonomous clustering-based pipeline for the annotation of the gallbladder, which is used to generate segmented labels for the DNN. When evaluated against manually annotated data, LapSeg3D achieves an F1 score of 0.94 for gallbladder segmentation on various datasets of ex-vivo porcine livers. We show LapSeg3D to generalize accurately across different gallbladders and datasets recorded with different RGB-D camera systems.
Cooperative Assistance in Robotic Surgery through Multi-Agent Reinforcement Learning
Oct 10, 2021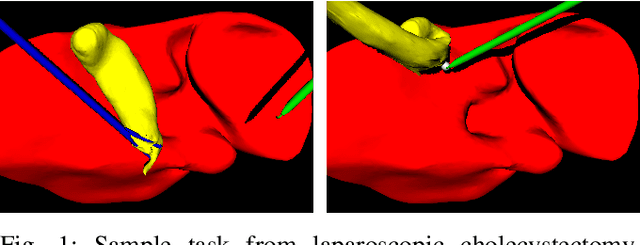

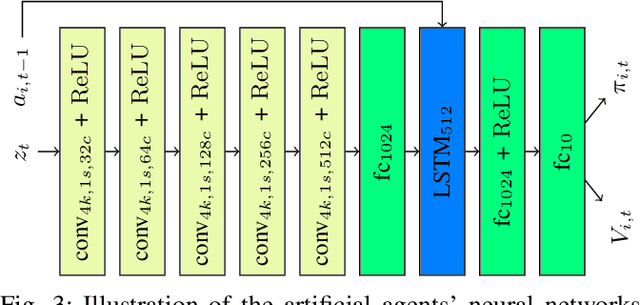
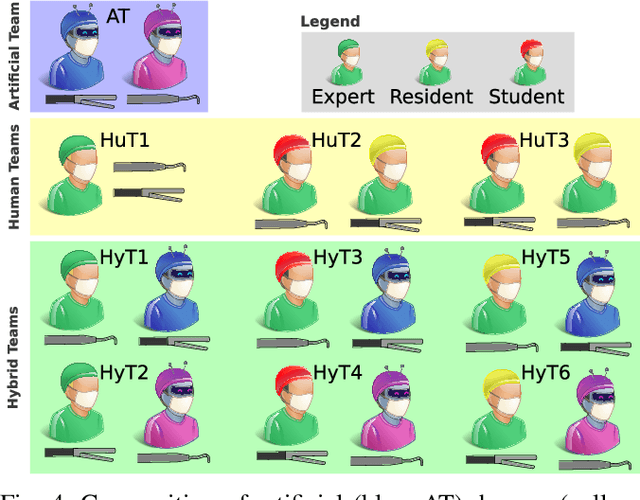
Cognitive cooperative assistance in robot-assisted surgery holds the potential to increase quality of care in minimally invasive interventions. Automation of surgical tasks promises to reduce the mental exertion and fatigue of surgeons. In this work, multi-agent reinforcement learning is demonstrated to be robust to the distribution shift introduced by pairing a learned policy with a human team member. Multi-agent policies are trained directly from images in simulation to control multiple instruments in a sub task of the minimally invasive removal of the gallbladder. These agents are evaluated individually and in cooperation with humans to demonstrate their suitability as autonomous assistants. Compared to human teams, the hybrid teams with artificial agents perform better considering completion time (44.4% to 71.2% shorter) as well as number of collisions (44.7% to 98.0% fewer). Path lengths, however, increase under control of an artificial agent (11.4% to 33.5% longer). A multi-agent formulation of the learning problem was favored over a single-agent formulation on this surgical sub task, due to the sequential learning of the two instruments. This approach may be extended to other tasks that are difficult to formulate within the standard reinforcement learning framework. Multi-agent reinforcement learning may shift the paradigm of cognitive robotic surgery towards seamless cooperation between surgeons and assistive technologies.