 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RITnet: Real-time Semantic Segmentation of the Eye for Gaze Tracking
Oct 01, 2019
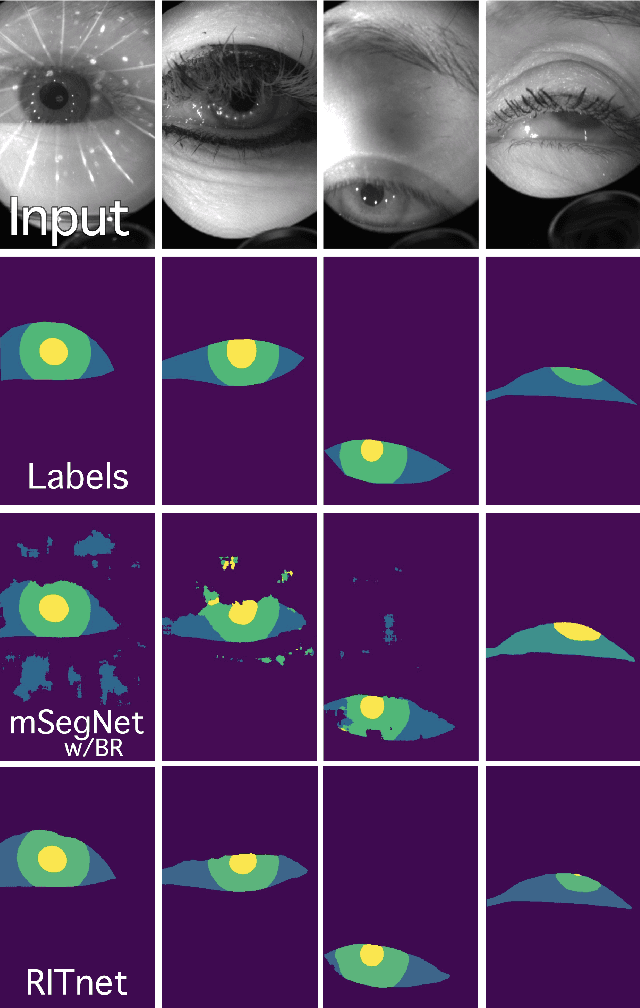
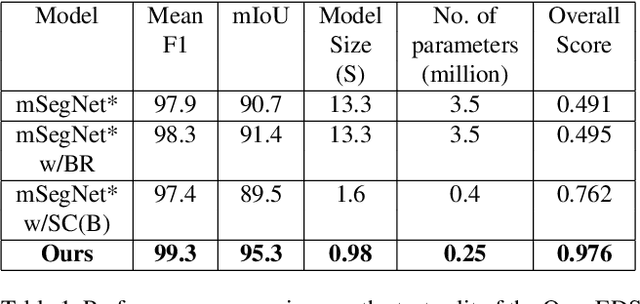
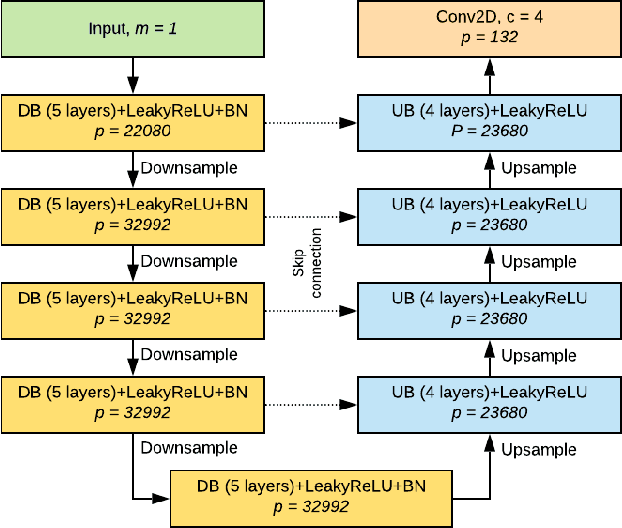
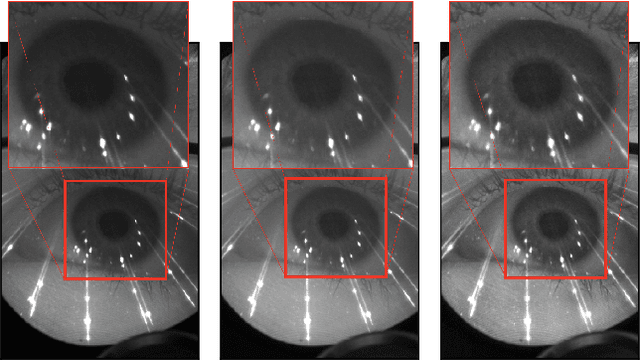
Accurate eye segmentation can improve eye-gaze estimation and support interactive computing based on visual attention; however, existing eye segmentation methods suffer from issues such as person-dependent accuracy, lack of robustness, and an inability to be run in real-time. Here, we present the RITnet model, which is a deep neural network that combines U-Net and DenseNet. RITnet is under 1 MB and achieves 95.3\% accuracy on the 2019 OpenEDS Semantic Segmentation challenge. Using a GeForce GTX 1080 Ti, RITnet tracks at $>$ 300Hz, enabling real-time gaze tracking applications. Pre-trained models and source code are available https://bitbucket.org/eye-ush/ritnet/.
RMSMP: A Novel Deep Neural Network Quantization Framework with Row-wise Mixed Schemes and Multiple Precisions
Oct 30, 2021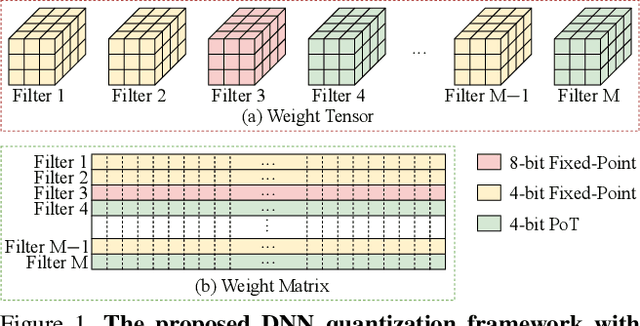
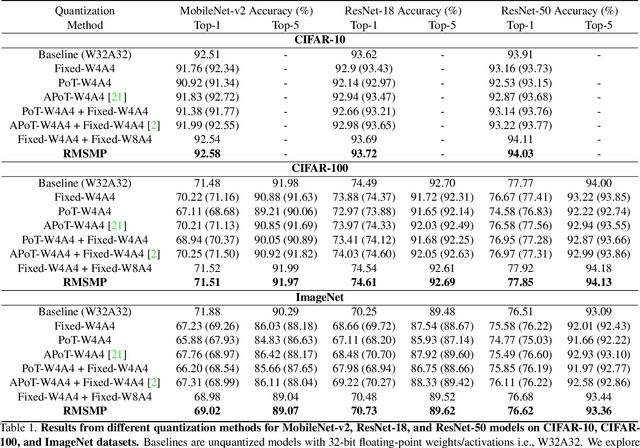
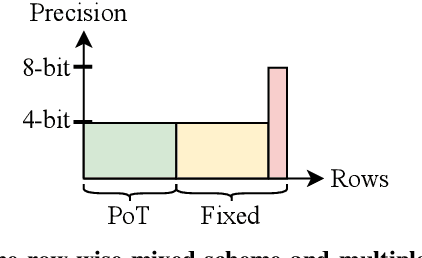
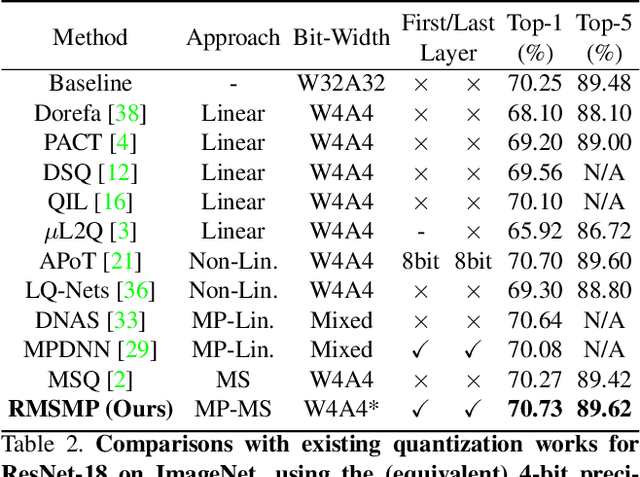
This work proposes a novel Deep Neural Network (DNN) quantization framework, namely RMSMP, with a Row-wise Mixed-Scheme and Multi-Precision approach. Specifically, this is the first effort to assign mixed quantization schemes and multiple precisions within layers -- among rows of the DNN weight matrix, for simplified operations in hardware inference, while preserving accuracy. Furthermore, this paper makes a different observation from the prior work that the quantization error does not necessarily exhibit the layer-wise sensitivity, and actually can be mitigated as long as a certain portion of the weights in every layer are in higher precisions. This observation enables layer-wise uniformality in the hardware implementation towards guaranteed inference acceleration, while still enjoying row-wise flexibility of mixed schemes and multiple precisions to boost accuracy. The candidates of schemes and precisions are derived practically and effectively with a highly hardware-informative strategy to reduce the problem search space. With the offline determined ratio of different quantization schemes and precisions for all the layers, the RMSMP quantization algorithm uses the Hessian and variance-based method to effectively assign schemes and precisions for each row. The proposed RMSMP is tested for the image classification and natural language processing (BERT) applications and achieves the best accuracy performance among state-of-the-arts under the same equivalent precisions. The RMSMP is implemented on FPGA devices, achieving 3.65x speedup in the end-to-end inference time for ResNet-18 on ImageNet, compared with the 4-bit Fixed-point baseline.
Learning to Describe Solutions for Bug Reports Based on Developer Discussions
Oct 08, 2021
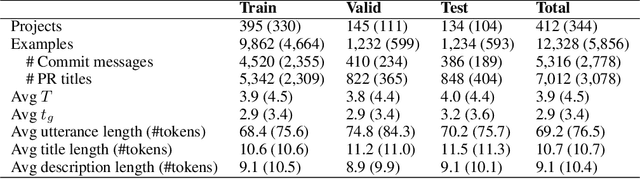

When a software bug is reported, developers engage in a discussion to collaboratively resolve it. While the solution is likely formulated within the discussion, it is often buried in a large amount of text, making it difficult to comprehend, which delays its implementation. To expedite bug resolution, we propose generating a concise natural language description of the solution by synthesizing relevant content within the discussion, which encompasses both natural language and source code. Furthermore, to support generating an informative description during an ongoing discussion, we propose a secondary task of determining when sufficient context about the solution emerges in real-time. We construct a dataset for these tasks with a novel technique for obtaining noisy supervision from repository changes linked to bug reports. We establish baselines for generating solution descriptions, and develop a classifier which makes a prediction following each new utterance on whether or not the necessary context for performing generation is available. Through automated and human evaluation, we find these tasks to form an ideal testbed for complex reasoning in long, bimodal dialogue context.
Dynamic Portfolio Cuts: A Spectral Approach to Graph-Theoretic Diversification
Jun 07, 2021

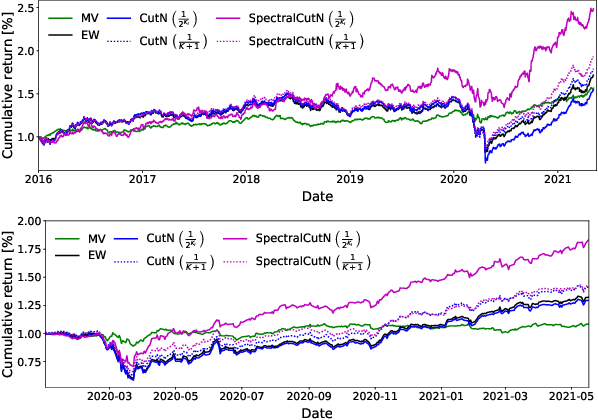
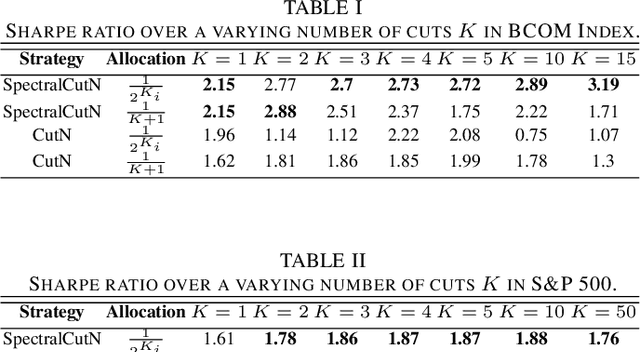
Stock market returns are typically analyzed using standard regression, yet they reside on irregular domains which is a natural scenario for graph signal processing. To this end, we consider a market graph as an intuitive way to represent the relationships between financial assets. Traditional methods for estimating asset-return covariance operate under the assumption of statistical time-invariance, and are thus unable to appropriately infer the underlying true structure of the market graph. This work introduces a class of graph spectral estimators which cater for the nonstationarity inherent to asset price movements, and serve as a basis to represent the time-varying interactions between assets through a dynamic spectral market graph. Such an account of the time-varying nature of the asset-return covariance allows us to introduce the notion of dynamic spectral portfolio cuts, whereby the graph is partitioned into time-evolving clusters, allowing for online and robust asset allocation. The advantages of the proposed framework over traditional methods are demonstrated through numerical case studies using real-world price data.
Idle Time Optimization for Target Assignment and Path Finding in Sortation Centers
Nov 30, 2019
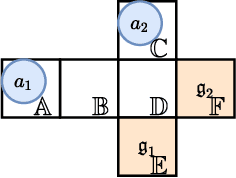
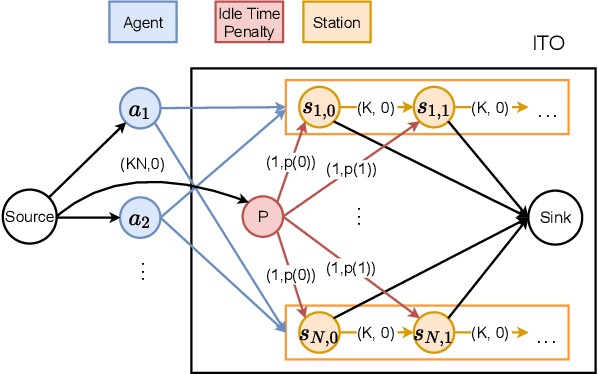
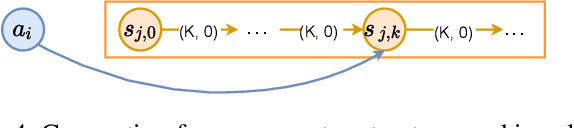
In this paper, we study the one-shot and lifelong versions of the Target Assignment and Path Finding problem in automated sortation centers, where each agent needs to constantly assign itself a sorting station, move to its assigned station without colliding with obstacles or other agents, wait in the queue of that station to obtain a parcel for delivery, and then deliver the parcel to a sorting bin. The throughput of such centers is largely determined by the total idle time of all stations since their queues can frequently become empty. To address this problem, we first formalize and study the one-shot version that assigns stations to a set of agents and finds collision-free paths for the agents to their assigned stations. We present efficient algorithms for this task based on a novel min-cost max-flow formulation that minimizes the total idle time of all stations in a fixed time window. We then demonstrate how our algorithms for solving the one-shot problem can be applied to solving the lifelong problem as well. Experimentally, we believe to be the first researchers to consider real-world automated sortation centers using an industrial simulator with realistic data and a kinodynamic model of real robots. On this simulator, we showcase the benefits of our algorithms by demonstrating their efficiency and effectiveness for up to 350 agents.
Integration of Data and Theory for Accelerated Derivable Symbolic Discovery
Sep 03, 2021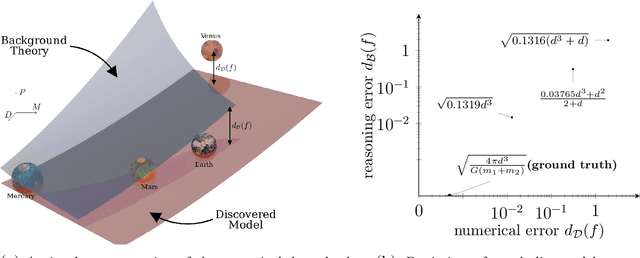
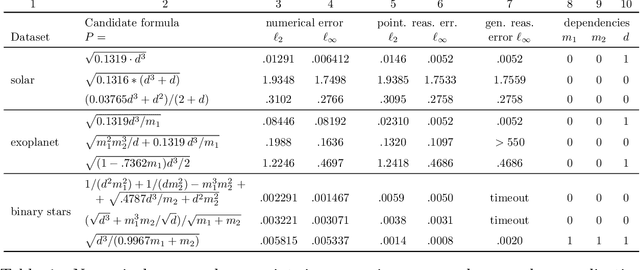
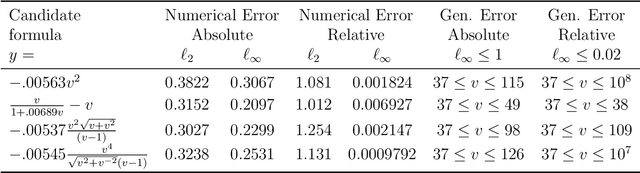
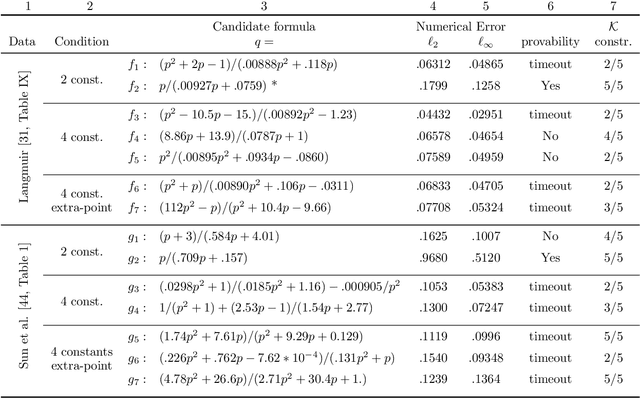
Scientists have long aimed to discover meaningful equations which accurately describe data. Machine learning algorithms automate construction of accurate data-driven models, but ensuring that these are consistent with existing knowledge is a challenge. We developed a methodology combining automated theorem proving with symbolic regression, enabling principled derivations of laws of nature. We demonstrate this for Kepler's third law, Einstein's relativistic time dilation, and Langmuir's theory of adsorption, in each case, automatically connecting experimental data with background theory. The combination of logical reasoning with machine learning provides generalizable insights into key aspects of the natural phenomena.
Auto-DSP: Learning to Optimize Acoustic Echo Cancellers
Oct 08, 2021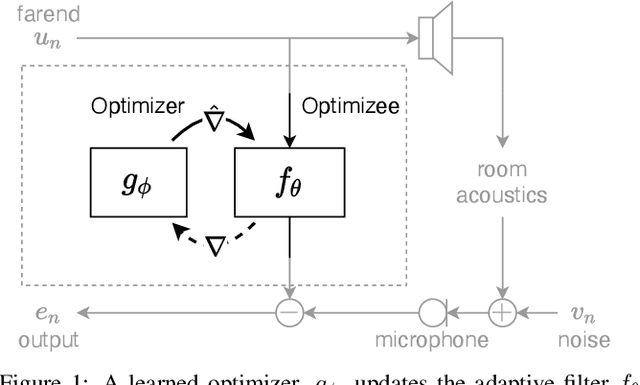
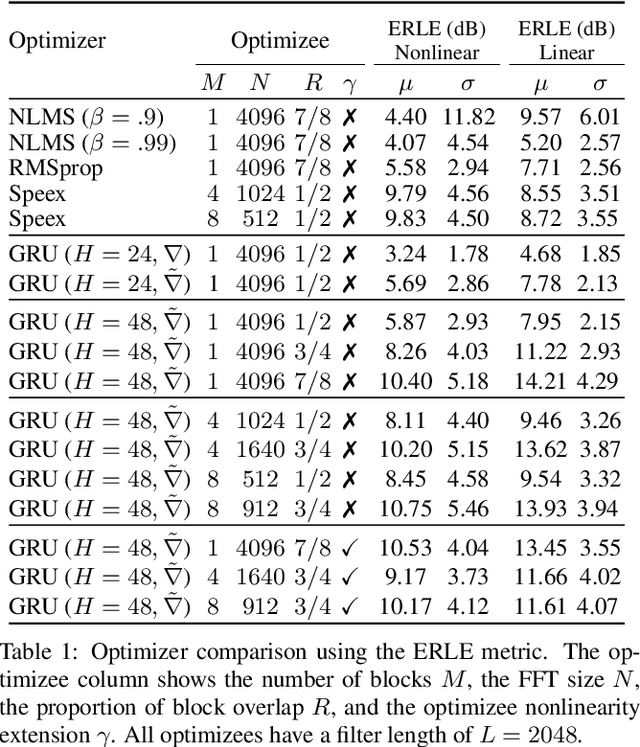
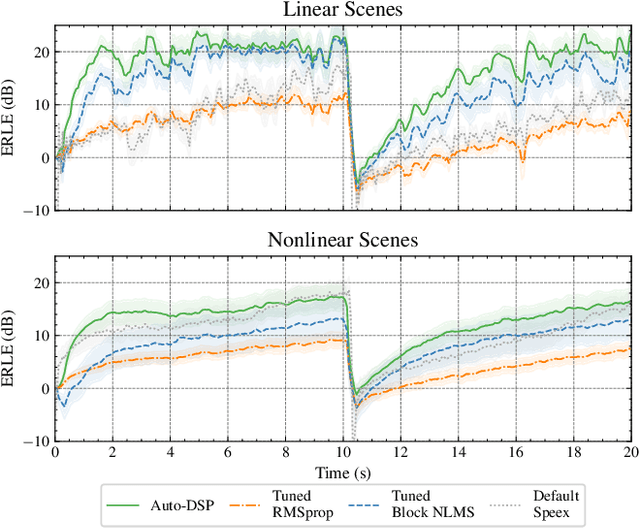
Adaptive filtering algorithms are commonplace in signal processing and have wide-ranging applications from single-channel denoising to multi-channel acoustic echo cancellation and adaptive beamforming. Such algorithms typically operate via specialized online, iterative optimization methods and have achieved tremendous success, but require expert knowledge, are slow to develop, and are difficult to customize. In our work, we present a new method to automatically learn adaptive filtering update rules directly from data. To do so, we frame adaptive filtering as a differentiable operator and train a learned optimizer to output a gradient descent-based update rule from data via backpropagation through time. We demonstrate our general approach on an acoustic echo cancellation task (single-talk with noise) and show that we can learn high-performing adaptive filters for a variety of common linear and non-linear multidelayed block frequency domain filter architectures. We also find that our learned update rules exhibit fast convergence, can optimize in the presence of nonlinearities, and are robust to acoustic scene changes despite never encountering any during training.
An Explanation of In-context Learning as Implicit Bayesian Inference
Nov 03, 2021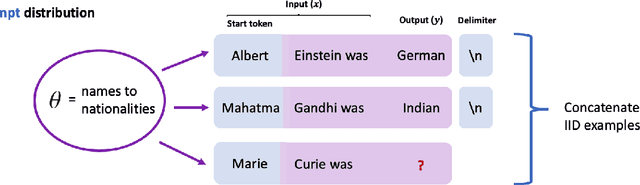
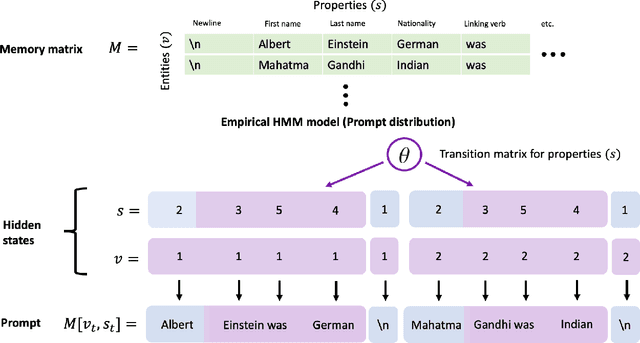
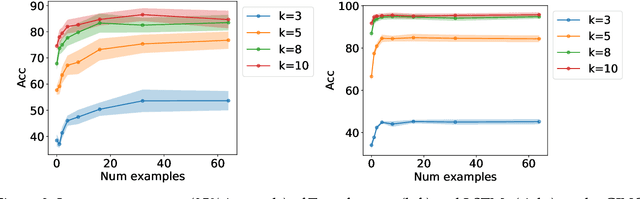

Large pretrained language models such as GPT-3 have the surprising ability to do in-context learning, where the model learns to do a downstream task simply by conditioning on a prompt consisting of input-output examples. Without being explicitly pretrained to do so, the language model learns from these examples during its forward pass without parameter updates on "out-of-distribution" prompts. Thus, it is unclear what mechanism enables in-context learning. In this paper, we study the role of the pretraining distribution on the emergence of in-context learning under a mathematical setting where the pretraining texts have long-range coherence. Here, language model pretraining requires inferring a latent document-level concept from the conditioning text to generate coherent next tokens. At test time, this mechanism enables in-context learning by inferring the shared latent concept between prompt examples and applying it to make a prediction on the test example. Concretely, we prove that in-context learning occurs implicitly via Bayesian inference of the latent concept when the pretraining distribution is a mixture of HMMs. This can occur despite the distribution mismatch between prompts and pretraining data. In contrast to messy large-scale pretraining datasets for in-context learning in natural language, we generate a family of small-scale synthetic datasets (GINC) where Transformer and LSTM language models both exhibit in-context learning. Beyond the theory which focuses on the effect of the pretraining distribution, we empirically find that scaling model size improves in-context accuracy even when the pretraining loss is the same.
Real-time Fusion Network for RGB-D Semantic Segmentation Incorporating Unexpected Obstacle Detection for Road-driving Images
Feb 24, 2020
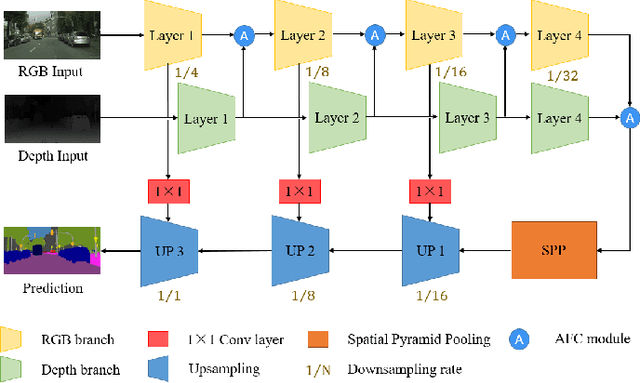
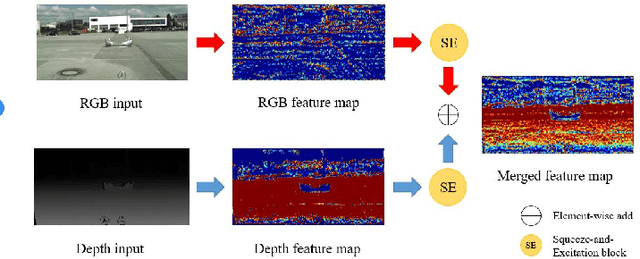

Semantic segmentation has made striking progress due to the success of deep convolutional neural networks. Considering the demand of autonomous driving, real-time semantic segmentation has become a research hotspot these years. However, few real-time RGB-D fusion semantic segmentation studies are carried out despite readily accessible depth information nowadays. In this paper, we propose a real-time fusion semantic segmentation network termed RFNet that efficiently exploits complementary features from depth information to enhance the performance in an attention-augmented way, while running swiftly that is a necessity for autonomous vehicles applications. Multi-dataset training is leveraged to incorporate unexpected small obstacle detection, enriching the recognizable classes required to face unforeseen hazards in the real world. A comprehensive set of experiments demonstrates the effectiveness of our framework. On \textit{Cityscapes}, Our method outperforms previous state-of-the-art semantic segmenters, with excellent accuracy and 22Hz inference speed at the full 2048$\times$1024 resolution, outperforming most existing RGB-D networks.
Diffusion-Based Voice Conversion with Fast Maximum Likelihood Sampling Scheme
Sep 28, 2021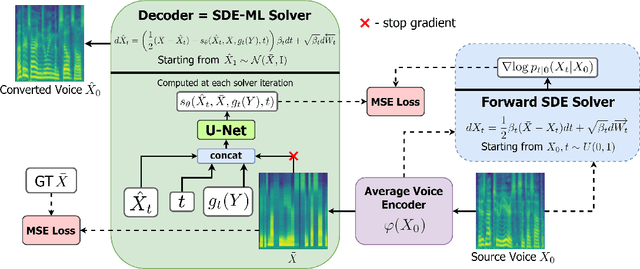

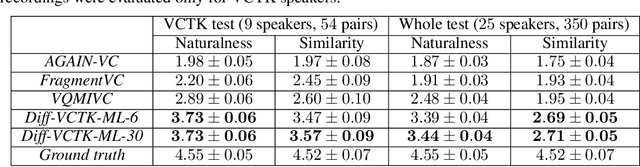

Voice conversion is a common speech synthesis task which can be solved in different ways depending on a particular real-world scenario. The most challenging one often referred to as one-shot many-to-many voice conversion consists in copying the target voice from only one reference utterance in the most general case when both source and target speakers do not belong to the training dataset. We present a scalable high-quality solution based on diffusion probabilistic modeling and demonstrate its superior quality compared to state-of-the-art one-shot voice conversion approaches. Moreover, focusing on real-time applications, we investigate general principles which can make diffusion models faster while keeping synthesis quality at a high level. As a result, we develop a novel Stochastic Differential Equations solver suitable for various diffusion model types and generative tasks as shown through empirical studies and justify it by theoretical analysis.