 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPTIAGENT: A Physics-Driven Agentic Framework for Automated Optical Design
Feb 27, 2026Optical design is the process of configuring optical elements to precisely manipulate light for high-fidelity imaging. It is inherently a highly non-convex optimization problem that relies heavily on human heuristic expertise and domain-specific knowledge. While Large Language Models (LLMs) possess extensive optical knowledge, their capabilities in leveraging the knowledge in designing lens system remain significantly constrained. This work represents the first attempt to employ LLMs in the field of optical design. We bridge the expertise gap by enabling users without formal optical training to successfully develop functional lens systems. Concretely, we curate a comprehensive dataset, named OptiDesignQA, which encompasses both classical lens systems sourced from standard optical textbooks and novel configurations generated by automated design algorithms for training and evaluation. Furthermore, we inject domain-specific optical expertise into the LLM through a hybrid objective of full-system synthesis and lens completion. To align the model with optical principles, we employ Group Relative Policy Optimization Done Right (DrGRPO) guided by Optical Lexicographic Reward for physics-driven policy alignment. This reward system incorporates structural format rewards, physical feasibility rewards, light-manipulation accuracy, and LLM-based heuristics. Finally, our model integrates with specialized optical optimization routines for end-to-end fine-tuning and precision refinement. We benchmark our proposed method against both traditional optimization-based automated design algorithms and LLM counterparts, and experimental results show the superiority of our method.
Towards Real-world Lens Active Alignment with Unlabeled Data via Domain Adaptation
Jan 08, 2026Active Alignment (AA) is a key technology for the large-scale automated assembly of high-precision optical systems. Compared with labor-intensive per-model on-device calibration, a digital-twin pipeline built on optical simulation offers a substantial advantage in generating large-scale labeled data. However, complex imaging conditions induce a domain gap between simulation and real-world images, limiting the generalization of simulation-trained models. To address this, we propose augmenting a simulation baseline with minimal unlabeled real-world images captured at random misalignment positions, mitigating the gap from a domain adaptation perspective. We introduce Domain Adaptive Active Alignment (DA3), which utilizes an autoregressive domain transformation generator and an adversarial-based feature alignment strategy to distill real-world domain information via self-supervised learning. This enables the extraction of domain-invariant image degradation features to facilitate robust misalignment prediction. Experiments on two lens types reveal that DA3 improves accuracy by 46% over a purely simulation pipeline. Notably, it approaches the performance achieved with precisely labeled real-world data collected on 3 lens samples, while reducing on-device data collection time by 98.7%. The results demonstrate that domain adaptation effectively endows simulation-trained models with robust real-world performance, validating the digital-twin pipeline as a practical solution to significantly enhance the efficiency of large-scale optical assembly.
Fine-gained air quality inference based on low-quality sensing data using self-supervised learning
Aug 18, 2024



Fine-grained air quality (AQ) mapping is made possible by the proliferation of cheap AQ micro-stations (MSs). However, their measurements are often inaccurate and sensitive to local disturbances, in contrast to standardized stations (SSs) that provide accurate readings but fall short in number. To simultaneously address the issues of low data quality (MSs) and high label sparsity (SSs), a multi-task spatio-temporal network (MTSTN) is proposed, which employs self-supervised learning to utilize massive unlabeled data, aided by seasonal and trend decomposition of MS data offering reliable information as features. The MTSTN is applied to infer NO$_2$, O$_3$ and PM$_{2.5}$ concentrations in a 250 km$^2$ area in Chengdu, China, at a resolution of 500m$\times$500m$\times$1hr. Data from 55 SSs and 323 MSs were used, along with meteorological, traffic, geographic and timestamp data as features. The MTSTN excels in accuracy compared to several benchmarks, and its performance is greatly enhanced by utilizing low-quality MS data. A series of ablation and pressure tests demonstrate the results' robustness and interpretability, showcasing the MTSTN's practical value for accurate and affordable AQ inference.
Panoramic annular SLAM with loop closure and global optimization
Feb 26, 2021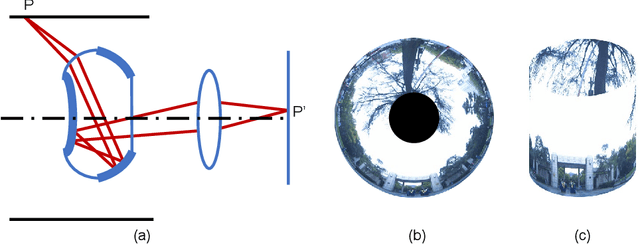
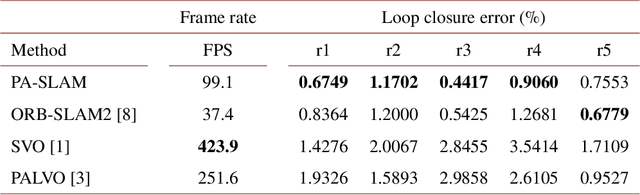
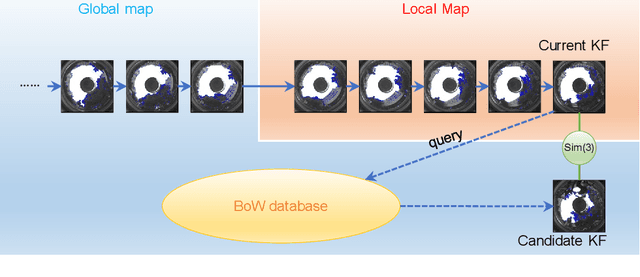

In this paper, we propose PA-SLAM, a monocular panoramic annular visual SLAM system with loop closure and global optimization. A hybrid point selection strategy is put forward in the tracking front-end, which ensures repeatability of keypoints and enables loop closure detection based on the bag-of-words approach. Every detected loop candidate is verified geometrically and the $Sim(3)$ relative pose constraint is estimated to perform pose graph optimization and global bundle adjustment in the back-end. A comprehensive set of experiments on real-world datasets demonstrates that the hybrid point selection strategy allows reliable loop closure detection, and the accumulated error and scale drift have been significantly reduced via global optimization, enabling PA-SLAM to reach state-of-the-art accuracy while maintaining high robustness and efficiency.
Real-time Fusion Network for RGB-D Semantic Segmentation Incorporating Unexpected Obstacle Detection for Road-driving Images
Feb 24, 2020
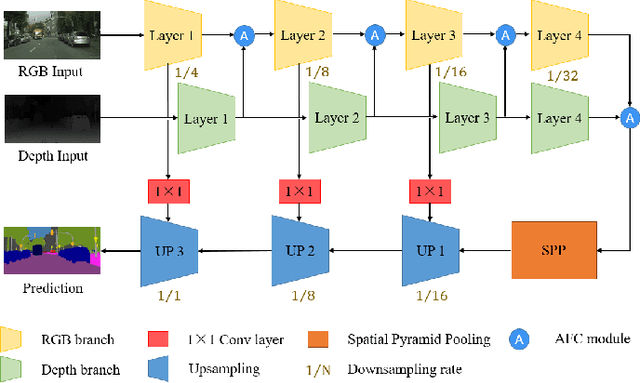
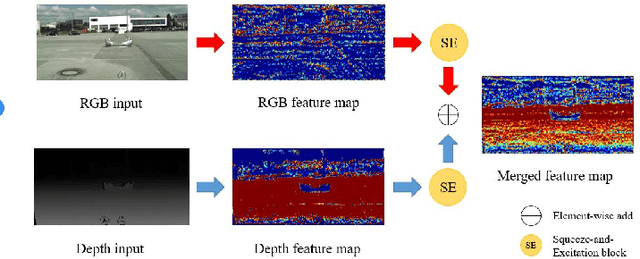

Semantic segmentation has made striking progress due to the success of deep convolutional neural networks. Considering the demand of autonomous driving, real-time semantic segmentation has become a research hotspot these years. However, few real-time RGB-D fusion semantic segmentation studies are carried out despite readily accessible depth information nowadays. In this paper, we propose a real-time fusion semantic segmentation network termed RFNet that efficiently exploits complementary features from depth information to enhance the performance in an attention-augmented way, while running swiftly that is a necessity for autonomous vehicles applications. Multi-dataset training is leveraged to incorporate unexpected small obstacle detection, enriching the recognizable classes required to face unforeseen hazards in the real world. A comprehensive set of experiments demonstrates the effectiveness of our framework. On \textit{Cityscapes}, Our method outperforms previous state-of-the-art semantic segmenters, with excellent accuracy and 22Hz inference speed at the full 2048$\times$1024 resolution, outperforming most existing RGB-D networks.
Panoramic Annular Localizer: Tackling the Variation Challenges of Outdoor Localization Using Panoramic Annular Images and Active Deep Descriptors
May 14, 2019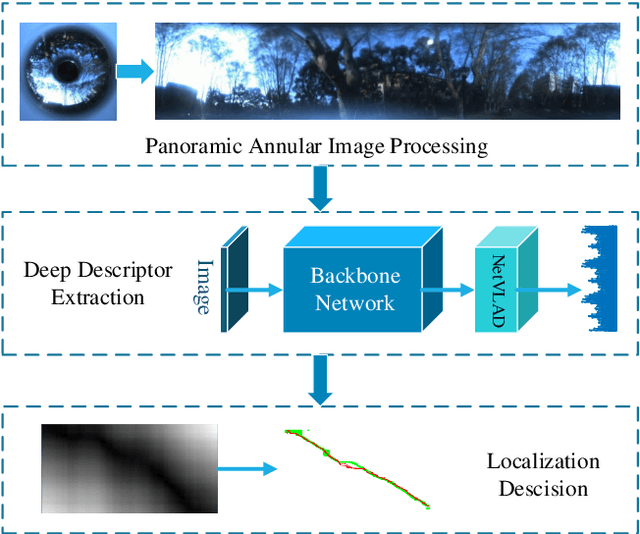
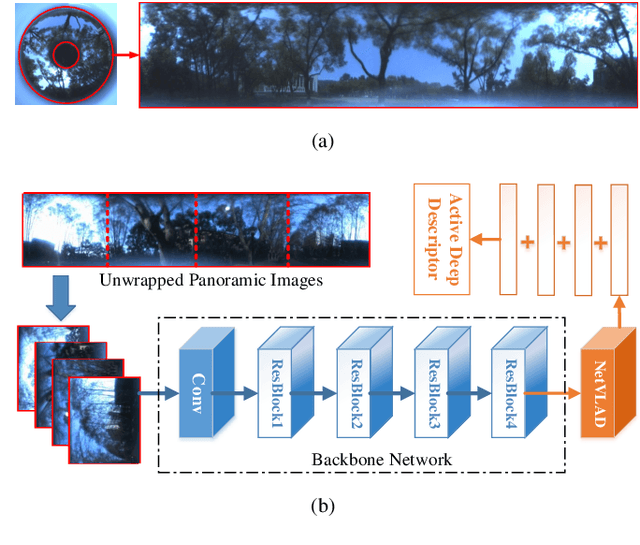
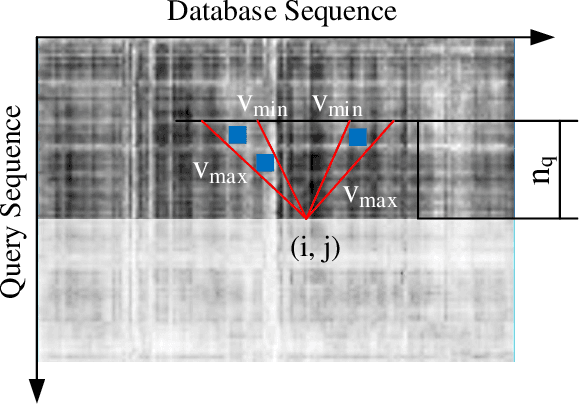
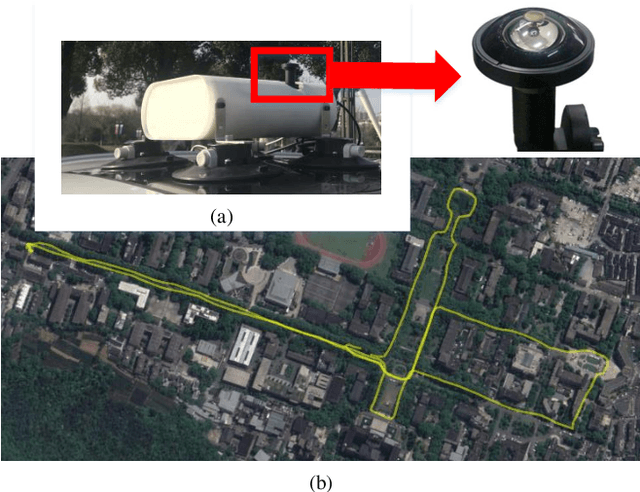
Visual localization is an attractive problem that estimates the camera localization from database images based on the query image. It is a crucial task for various applications, such as autonomous vehicles, assistive navigation and augmented reality. The challenging issues of the task lie in various appearance variations between query and database images, including illumination variations, season variations, dynamic object variations and viewpoint variations. In order to tackle those challenges, Panoramic Annular Localizer into which panoramic annular lens and robust deep image descriptors are incorporated is proposed in this paper. The panoramic annular images captured by the single camera are processed and fed into the NetVLAD network to form the active deep descriptor, and sequential matching is utilized to generate the localization result. The experiments carried on the public datasets and in the field illustrate the validation of the proposed system.