 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
WebGPT: Browser-assisted question-answering with human feedback
Dec 17, 2021



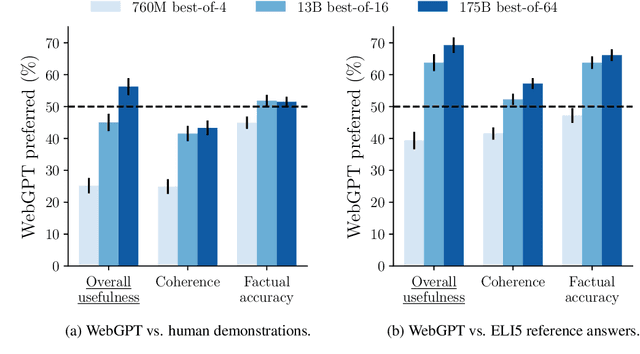
We fine-tune GPT-3 to answer long-form questions using a text-based web-browsing environment, which allows the model to search and navigate the web. By setting up the task so that it can be performed by humans, we are able to train models on the task using imitation learning, and then optimize answer quality with human feedback. To make human evaluation of factual accuracy easier, models must collect references while browsing in support of their answers. We train and evaluate our models on ELI5, a dataset of questions asked by Reddit users. Our best model is obtained by fine-tuning GPT-3 using behavior cloning, and then performing rejection sampling against a reward model trained to predict human preferences. This model's answers are preferred by humans 56% of the time to those of our human demonstrators, and 69% of the time to the highest-voted answer from Reddit.
Part-Aware Self-Supervised Pre-Training for Person Re-Identification
Mar 08, 2022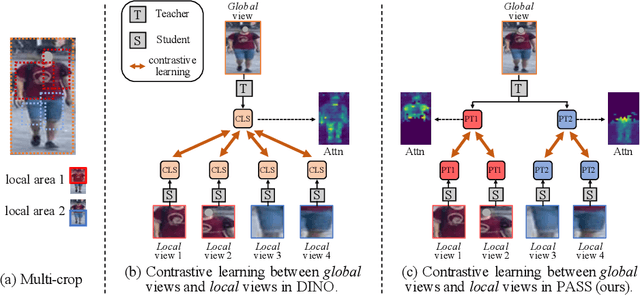
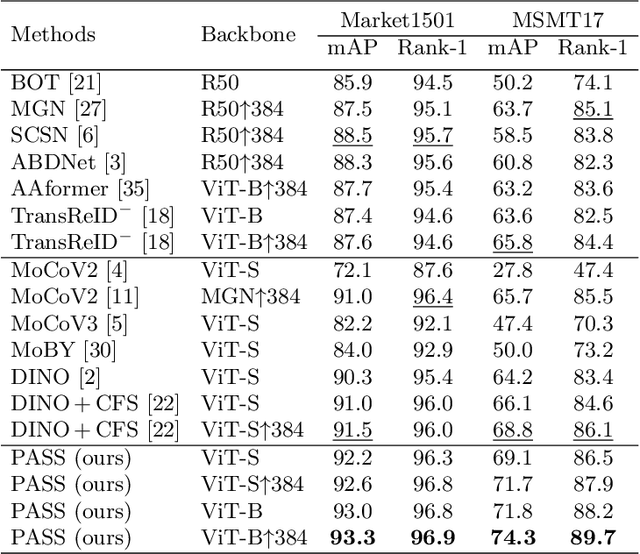
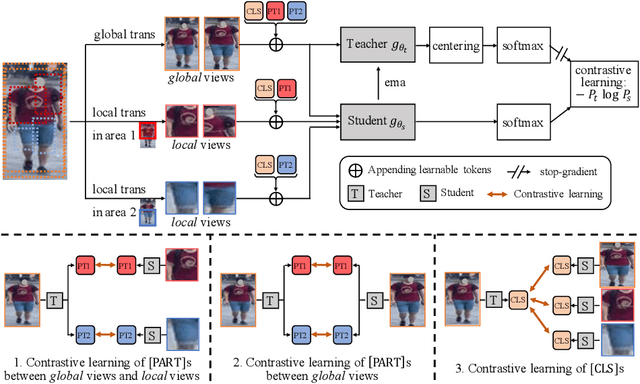
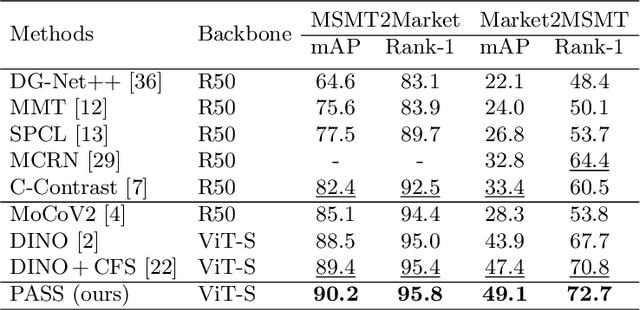
In person re-identification (ReID), very recent researches have validated pre-training the models on unlabelled person images is much better than on ImageNet. However, these researches directly apply the existing self-supervised learning (SSL) methods designed for image classification to ReID without any adaption in the framework. These SSL methods match the outputs of local views (e.g., red T-shirt, blue shorts) to those of the global views at the same time, losing lots of details. In this paper, we propose a ReID-specific pre-training method, Part-Aware Self-Supervised pre-training (PASS), which can generate part-level features to offer fine-grained information and is more suitable for ReID. PASS divides the images into several local areas, and the local views randomly cropped from each area are assigned with a specific learnable [PART] token. On the other hand, the [PART]s of all local areas are also appended to the global views. PASS learns to match the output of the local views and global views on the same [PART]. That is, the learned [PART] of the local views from a local area is only matched with the corresponding [PART] learned from the global views. As a result, each [PART] can focus on a specific local area of the image and extracts fine-grained information of this area. Experiments show PASS sets the new state-of-the-art performances on Market1501 and MSMT17 on various ReID tasks, e.g., vanilla ViT-S/16 pre-trained by PASS achieves 92.2\%/90.2\%/88.5\% mAP accuracy on Market1501 for supervised/UDA/USL ReID. Our codes are available at https://github.com/CASIA-IVA-Lab/PASS-reID.
Comparative Analysis of Radar Cross Section Based UAV Classification Techniques
Dec 17, 2021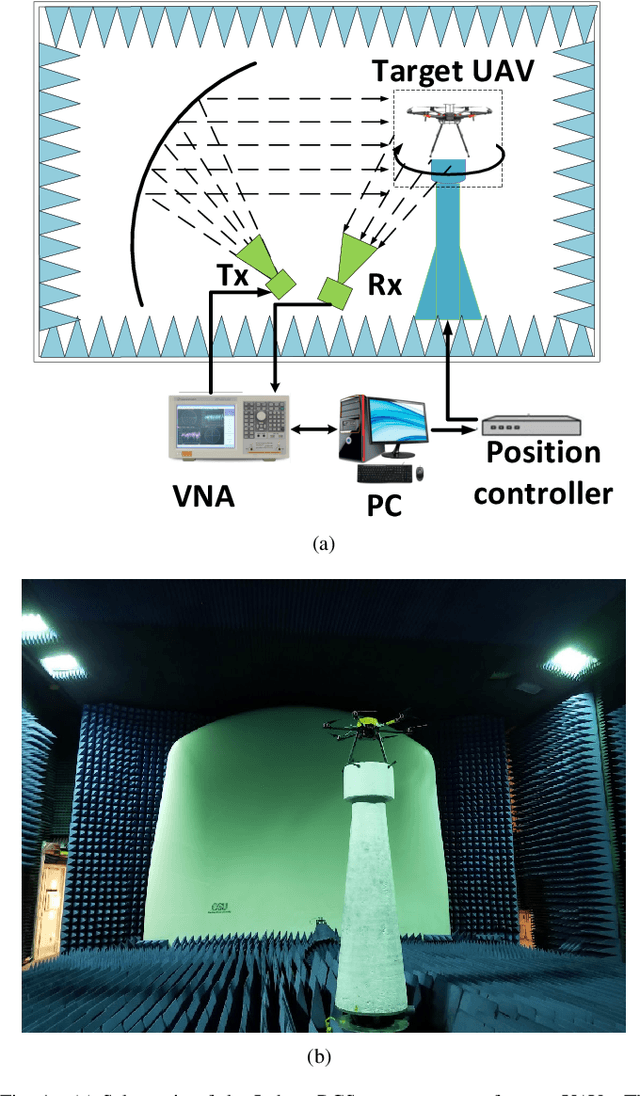
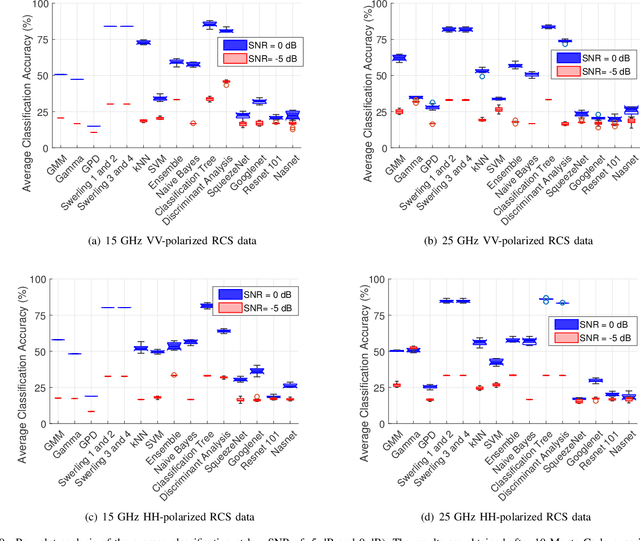
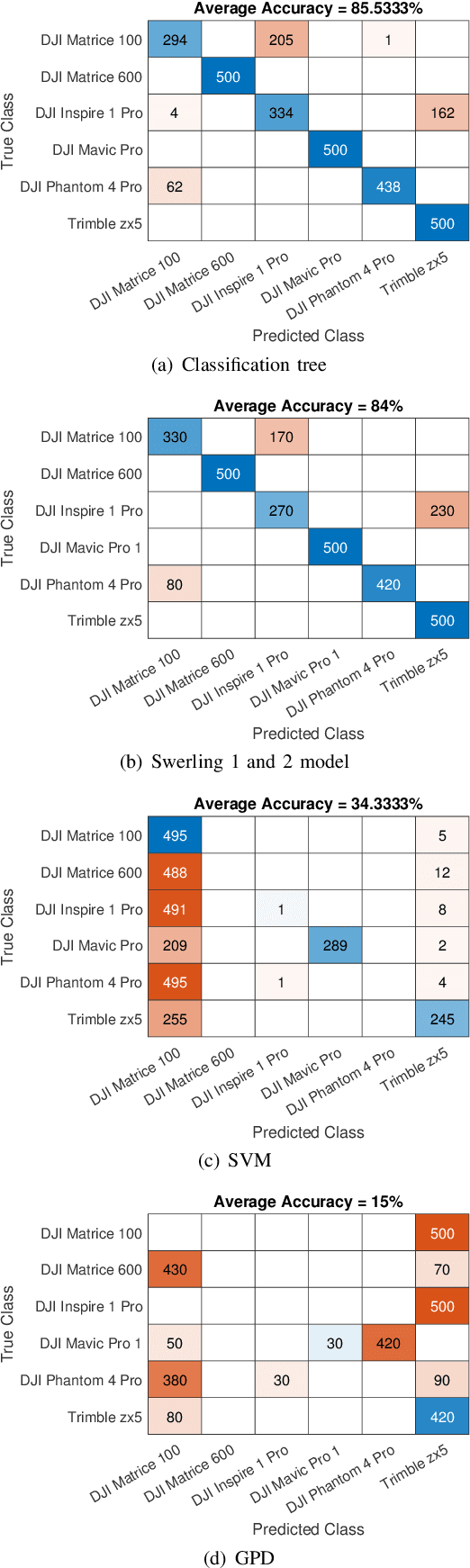
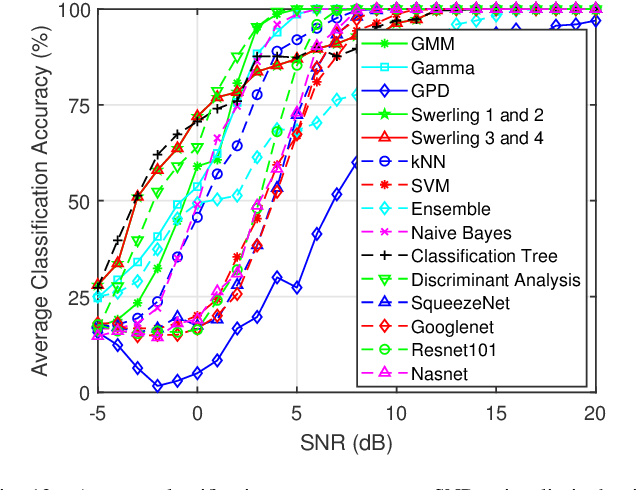
This work investigates the problem of unmanned aerial vehicles (UAVs) identification using their radar crosssection (RCS) signature. The RCS of six commercial UAVs are measured at 15 GHz and 25 GHz in an anechoic chamber, for both vertical-vertical and horizontal-horizontal polarization. The RCS signatures are used to train 15 different classification algorithms, each belonging to one of three different categories: statistical learning (SL), machine learning (ML), and deep learning (DL). The study shows that while the classification accuracy of all the algorithms increases with the signal-to-noise ratio (SNR), the ML algorithm achieved better accuracy than the SL and DL algorithms. For example, the classification tree ML achieves an accuracy of 98.66% at 3 dB SNR using the 15 GHz VV-polarized RCS test data from the UAVs. We investigate the classification accuracy using Monte Carlo analysis with the aid of boxplots, confusion matrices, and classification plots. On average, the accuracy of the classification tree ML model performed better than the other algorithms, followed by the Peter Swerling statistical models and the discriminant analysis ML model. In general, the classification accuracy of the ML and SL algorithms outperformed the DL algorithms (Squeezenet, Googlenet, Nasnet, and Resnet 101) considered in the study. Furthermore, the computational time of each algorithm is analyzed. The study concludes that while the SL algorithms achieved good classification accuracy, the computational time was relatively long when compared to the ML and DL algorithms. Also, the study shows that the classification tree achieved the fastest average classification time of about 0.46 ms.
Distributional Offline Continuous-Time Reinforcement Learning with Neural Physics-Informed PDEs (SciPhy RL for DOCTR-L)
Apr 02, 2021
This paper addresses distributional offline continuous-time reinforcement learning (DOCTR-L) with stochastic policies for high-dimensional optimal control. A soft distributional version of the classical Hamilton-Jacobi-Bellman (HJB) equation is given by a semilinear partial differential equation (PDE). This `soft HJB equation' can be learned from offline data without assuming that the latter correspond to a previous optimal or near-optimal policy. A data-driven solution of the soft HJB equation uses methods of Neural PDEs and Physics-Informed Neural Networks developed in the field of Scientific Machine Learning (SciML). The suggested approach, dubbed `SciPhy RL', thus reduces DOCTR-L to solving neural PDEs from data. Our algorithm called Deep DOCTR-L converts offline high-dimensional data into an optimal policy in one step by reducing it to supervised learning, instead of relying on value iteration or policy iteration methods. The method enables a computable approach to the quality control of obtained policies in terms of both their expected returns and uncertainties about their values.
Generating Videos with Dynamics-aware Implicit Generative Adversarial Networks
Feb 21, 2022
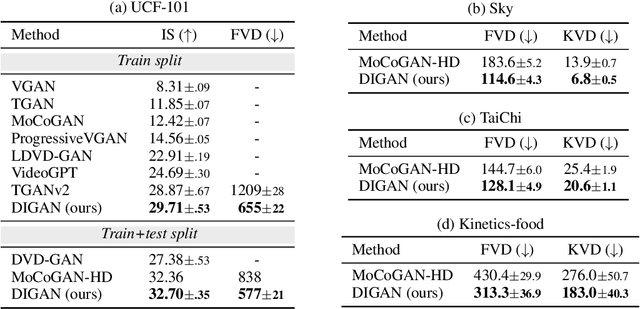
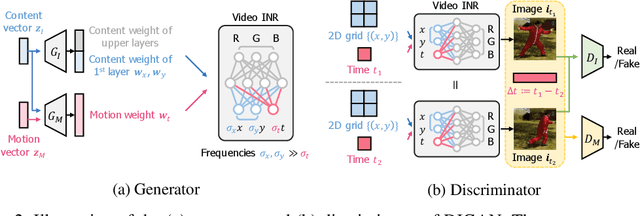
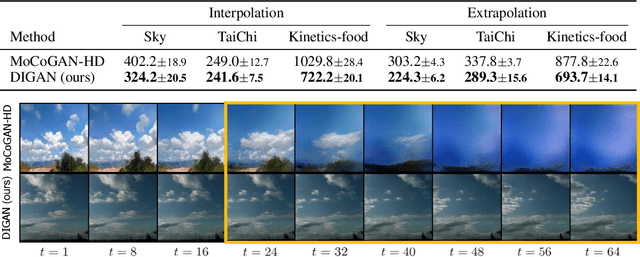
In the deep learning era, long video generation of high-quality still remains challenging due to the spatio-temporal complexity and continuity of videos. Existing prior works have attempted to model video distribution by representing videos as 3D grids of RGB values, which impedes the scale of generated videos and neglects continuous dynamics. In this paper, we found that the recent emerging paradigm of implicit neural representations (INRs) that encodes a continuous signal into a parameterized neural network effectively mitigates the issue. By utilizing INRs of video, we propose dynamics-aware implicit generative adversarial network (DIGAN), a novel generative adversarial network for video generation. Specifically, we introduce (a) an INR-based video generator that improves the motion dynamics by manipulating the space and time coordinates differently and (b) a motion discriminator that efficiently identifies the unnatural motions without observing the entire long frame sequences. We demonstrate the superiority of DIGAN under various datasets, along with multiple intriguing properties, e.g., long video synthesis, video extrapolation, and non-autoregressive video generation. For example, DIGAN improves the previous state-of-the-art FVD score on UCF-101 by 30.7% and can be trained on 128 frame videos of 128x128 resolution, 80 frames longer than the 48 frames of the previous state-of-the-art method.
Learning stochastic dynamics and predicting emergent behavior using transformers
Feb 17, 2022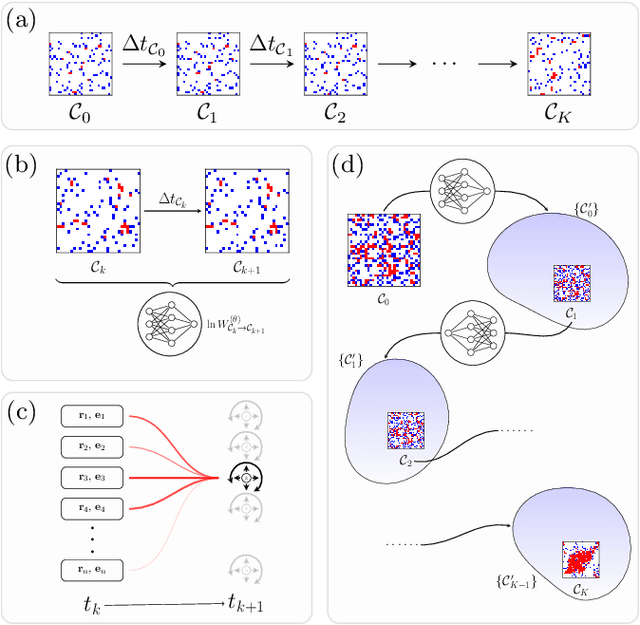
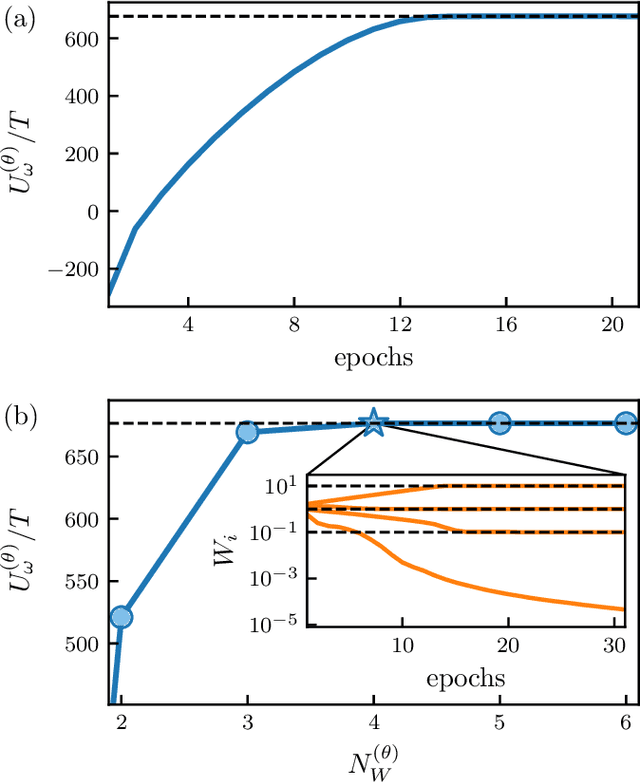
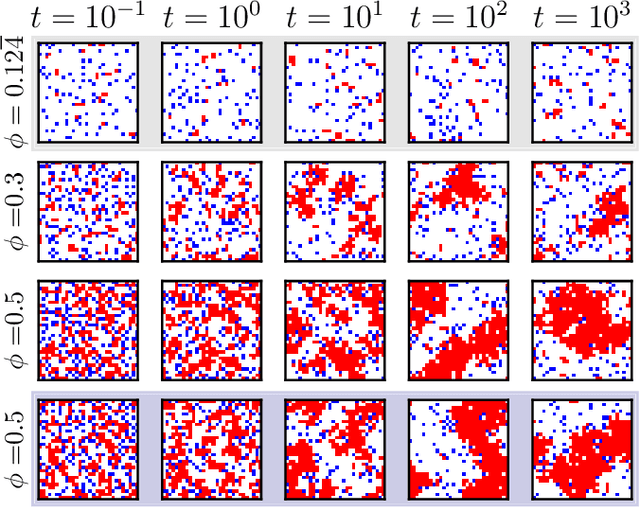
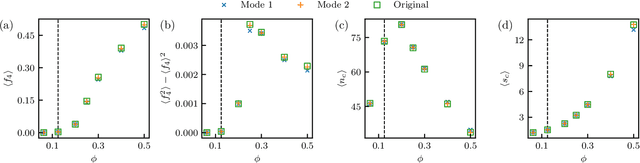
We show that a neural network originally designed for language processing can learn the dynamical rules of a stochastic system by observation of a single dynamical trajectory of the system, and can accurately predict its emergent behavior under conditions not observed during training. We consider a lattice model of active matter undergoing continuous-time Monte Carlo dynamics, simulated at a density at which its steady state comprises small, dispersed clusters. We train a neural network called a transformer on a single trajectory of the model. The transformer, which we show has the capacity to represent dynamical rules that are numerous and nonlocal, learns that the dynamics of this model consists of a small number of processes. Forward-propagated trajectories of the trained transformer, at densities not encountered during training, exhibit motility-induced phase separation and so predict the existence of a nonequilibrium phase transition. Transformers have the flexibility to learn dynamical rules from observation without explicit enumeration of rates or coarse-graining of configuration space, and so the procedure used here can be applied to a wide range of physical systems, including those with large and complex dynamical generators.
Optimal quantum dataset for learning a unitary transformation
Mar 01, 2022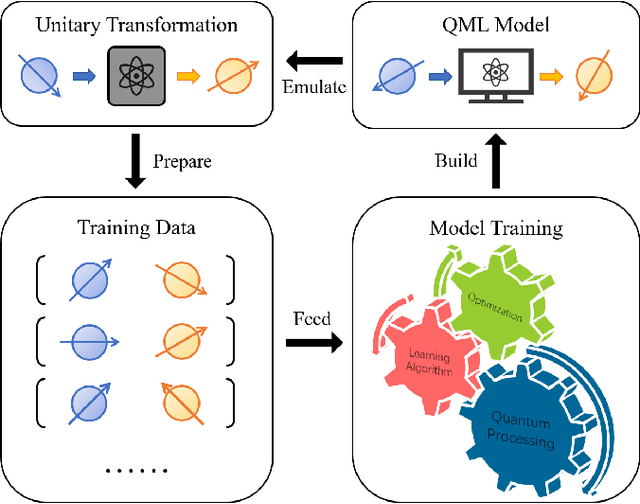
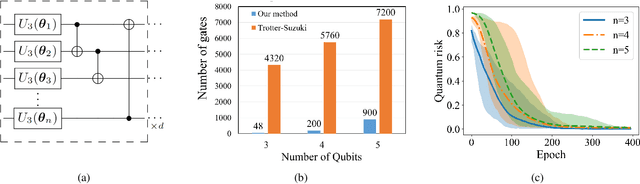
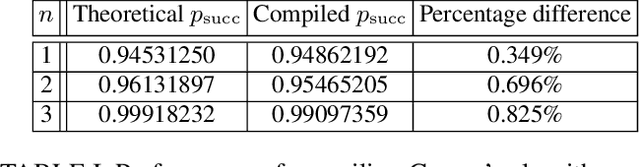
Unitary transformations formulate the time evolution of quantum states. How to learn a unitary transformation efficiently is a fundamental problem in quantum machine learning. The most natural and leading strategy is to train a quantum machine learning model based on a quantum dataset. Although presence of more training data results in better models, using too much data reduces the efficiency of training. In this work, we solve the problem on the minimum size of sufficient quantum datasets for learning a unitary transformation exactly, which reveals the power and limitation of quantum data. First, we prove that the minimum size of dataset with pure states is $2^n$ for learning an $n$-qubit unitary transformation. To fully explore the capability of quantum data, we introduce a quantum dataset consisting of $n+1$ mixed states that are sufficient for exact training. The main idea is to simplify the structure utilizing decoupling, which leads to an exponential improvement on the size over the datasets with pure states. Furthermore, we show that the size of quantum dataset with mixed states can be reduced to a constant, which yields an optimal quantum dataset for learning a unitary. We showcase the applications of our results in oracle compiling and Hamiltonian simulation. Notably, to accurately simulate a 3-qubit one-dimensional nearest-neighbor Heisenberg model, our circuit only uses $48$ elementary quantum gates, which is significantly less than $4320$ gates in the circuit constructed by the Trotter-Suzuki product formula.
Neural Datalog Through Time: Informed Temporal Modeling via Logical Specification
Jun 30, 2020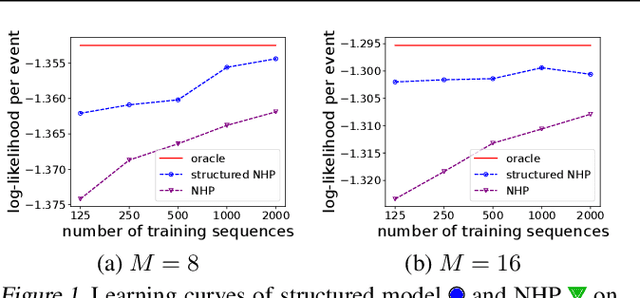
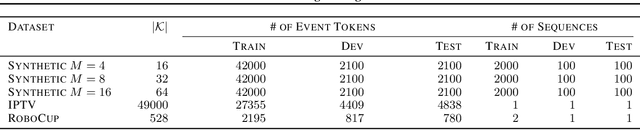
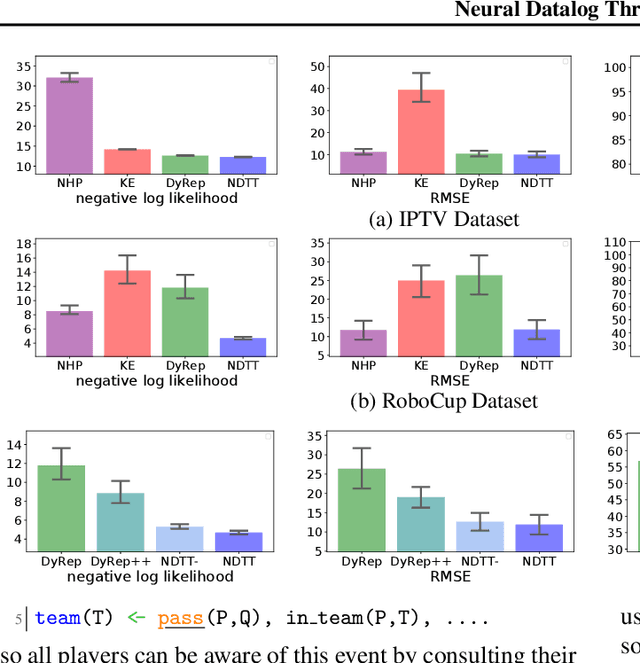
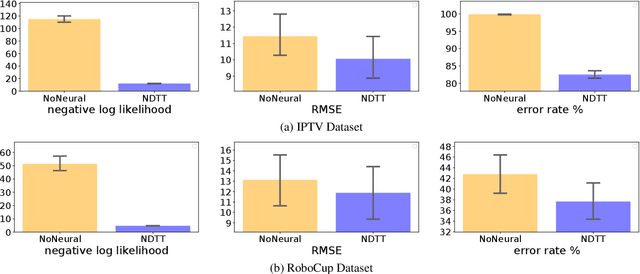
Learning how to predict future events from patterns of past events is difficult when the set of possible event types is large. Training an unrestricted neural model might overfit to spurious patterns. To exploit domain-specific knowledge of how past events might affect an event's present probability, we propose using a temporal deductive database to track structured facts over time. Rules serve to prove facts from other facts and from past events. Each fact has a time-varying state---a vector computed by a neural net whose topology is determined by the fact's provenance, including its experience of past events. The possible event types at any time are given by special facts, whose probabilities are neurally modeled alongside their states. In both synthetic and real-world domains, we show that neural probabilistic models derived from concise Datalog programs improve prediction by encoding appropriate domain knowledge in their architecture.
Inverse Contextual Bandits: Learning How Behavior Evolves over Time
Jul 13, 2021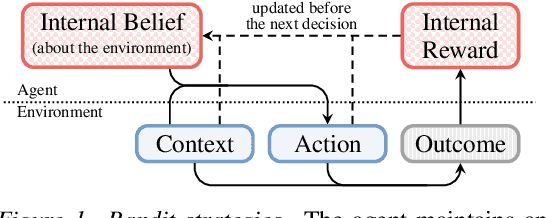
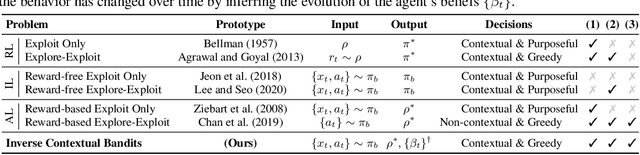
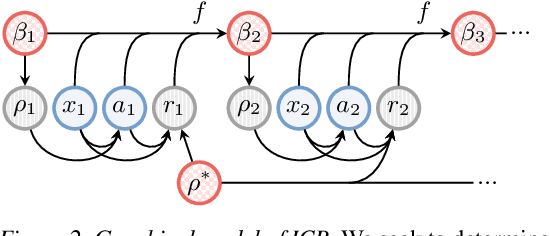
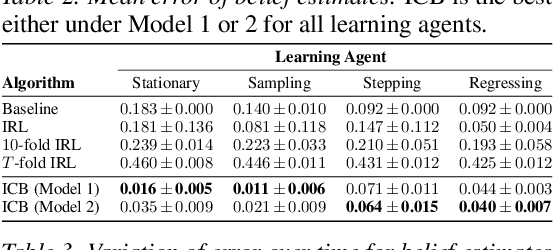
Understanding an agent's priorities by observing their behavior is critical for transparency and accountability in decision processes, such as in healthcare. While conventional approaches to policy learning almost invariably assume stationarity in behavior, this is hardly true in practice: Medical practice is constantly evolving, and clinical professionals are constantly fine-tuning their priorities. We desire an approach to policy learning that provides (1) interpretable representations of decision-making, accounts for (2) non-stationarity in behavior, as well as operating in an (3) offline manner. First, we model the behavior of learning agents in terms of contextual bandits, and formalize the problem of inverse contextual bandits (ICB). Second, we propose two algorithms to tackle ICB, each making varying degrees of assumptions regarding the agent's learning strategy. Finally, through both real and simulated data for liver transplantations, we illustrate the applicability and explainability of our method, as well as validating its accuracy.
Hybrid Learning for Orchestrating Deep Learning Inference in Multi-user Edge-cloud Networks
Feb 21, 2022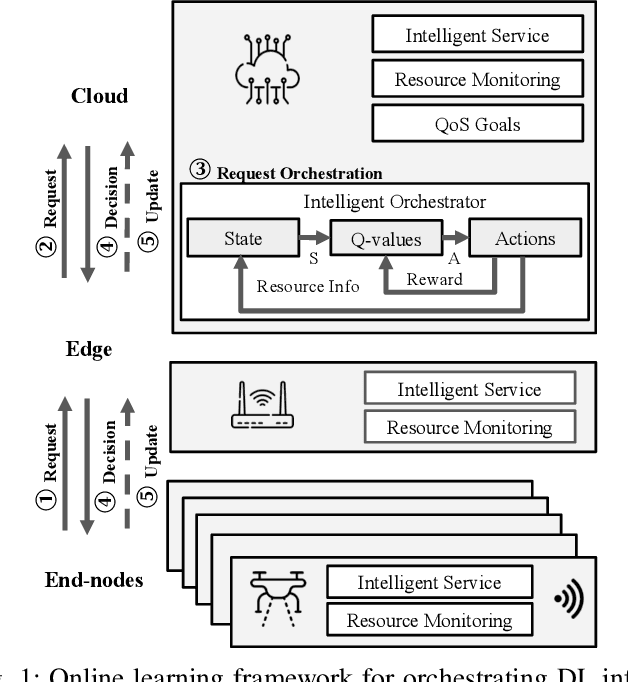
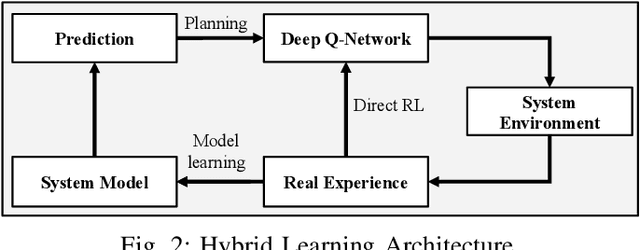
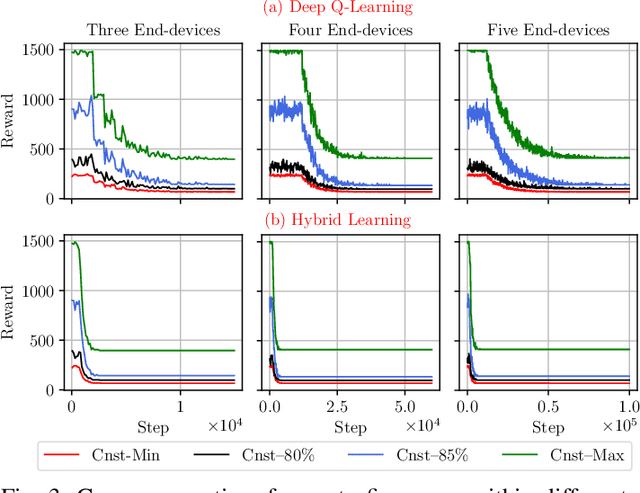
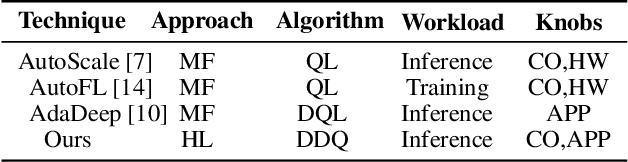
Deep-learning-based intelligent services have become prevalent in cyber-physical applications including smart cities and health-care. Collaborative end-edge-cloud computing for deep learning provides a range of performance and efficiency that can address application requirements through computation offloading. The decision to offload computation is a communication-computation co-optimization problem that varies with both system parameters (e.g., network condition) and workload characteristics (e.g., inputs). Identifying optimal orchestration considering the cross-layer opportunities and requirements in the face of varying system dynamics is a challenging multi-dimensional problem. While Reinforcement Learning (RL) approaches have been proposed earlier, they suffer from a large number of trial-and-errors during the learning process resulting in excessive time and resource consumption. We present a Hybrid Learning orchestration framework that reduces the number of interactions with the system environment by combining model-based and model-free reinforcement learning. Our Deep Learning inference orchestration strategy employs reinforcement learning to find the optimal orchestration policy. Furthermore, we deploy Hybrid Learning (HL) to accelerate the RL learning process and reduce the number of direct samplings. We demonstrate efficacy of our HL strategy through experimental comparison with state-of-the-art RL-based inference orchestration, demonstrating that our HL strategy accelerates the learning process by up to 166.6x.