 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Leveraging Structure for Improved Classification of Grouped Biased Data
Dec 07, 2022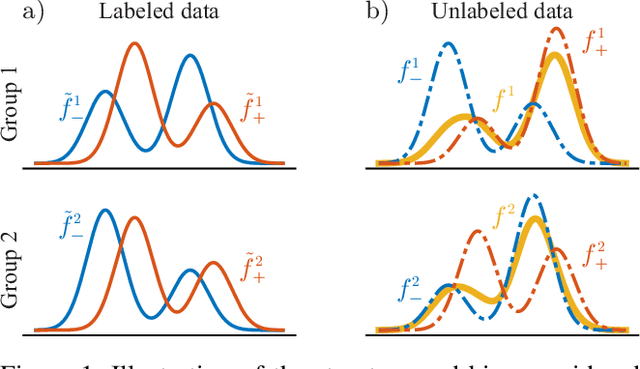


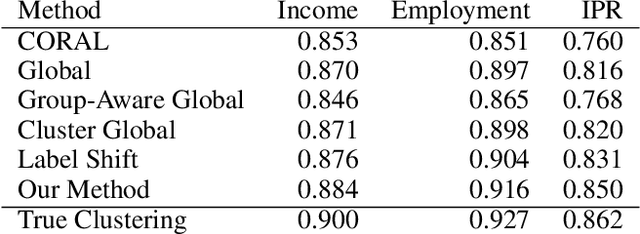
We consider semi-supervised binary classification for applications in which data points are naturally grouped (e.g., survey responses grouped by state) and the labeled data is biased (e.g., survey respondents are not representative of the population). The groups overlap in the feature space and consequently the input-output patterns are related across the groups. To model the inherent structure in such data, we assume the partition-projected class-conditional invariance across groups, defined in terms of the group-agnostic feature space. We demonstrate that under this assumption, the group carries additional information about the class, over the group-agnostic features, with provably improved area under the ROC curve. Further assuming invariance of partition-projected class-conditional distributions across both labeled and unlabeled data, we derive a semi-supervised algorithm that explicitly leverages the structure to learn an optimal, group-aware, probability-calibrated classifier, despite the bias in the labeled data. Experiments on synthetic and real data demonstrate the efficacy of our algorithm over suitable baselines and ablative models, spanning standard supervised and semi-supervised learning approaches, with and without incorporating the group directly as a feature.
WebGPT: Browser-assisted question-answering with human feedback
Dec 17, 2021


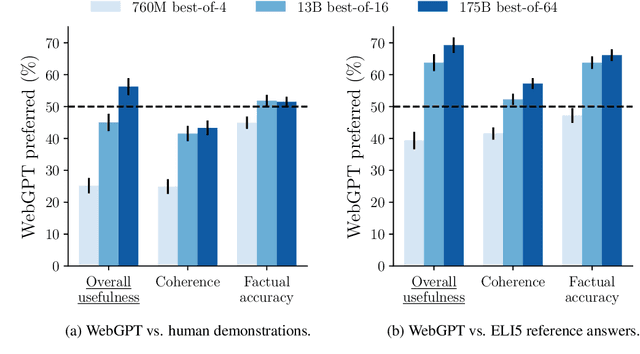
We fine-tune GPT-3 to answer long-form questions using a text-based web-browsing environment, which allows the model to search and navigate the web. By setting up the task so that it can be performed by humans, we are able to train models on the task using imitation learning, and then optimize answer quality with human feedback. To make human evaluation of factual accuracy easier, models must collect references while browsing in support of their answers. We train and evaluate our models on ELI5, a dataset of questions asked by Reddit users. Our best model is obtained by fine-tuning GPT-3 using behavior cloning, and then performing rejection sampling against a reward model trained to predict human preferences. This model's answers are preferred by humans 56% of the time to those of our human demonstrators, and 69% of the time to the highest-voted answer from Reddit.
Evaluating Large Language Models Trained on Code
Jul 14, 2021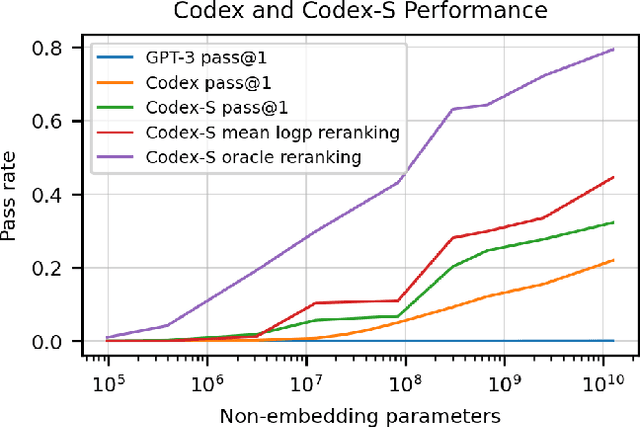
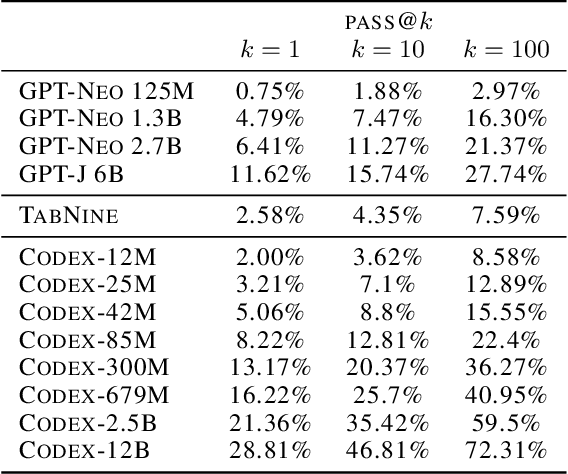
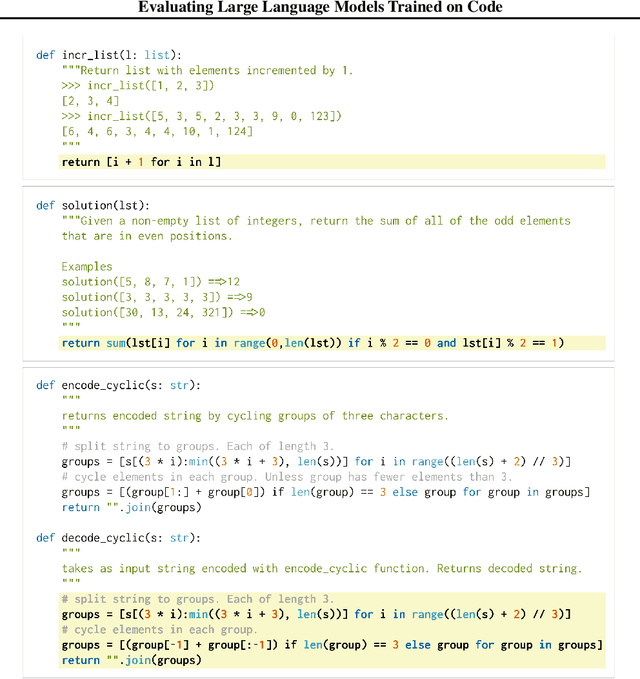
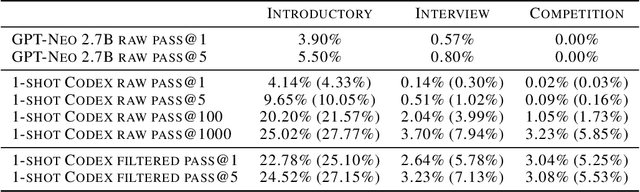
We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
Recovering True Classifier Performance in Positive-Unlabeled Learning
Feb 02, 2017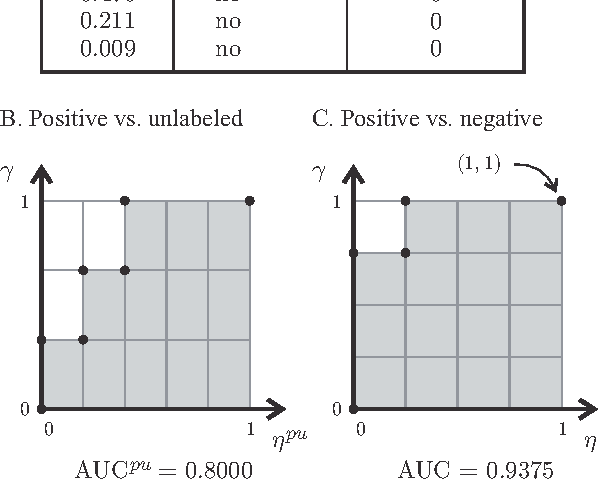

A common approach in positive-unlabeled learning is to train a classification model between labeled and unlabeled data. This strategy is in fact known to give an optimal classifier under mild conditions; however, it results in biased empirical estimates of the classifier performance. In this work, we show that the typically used performance measures such as the receiver operating characteristic curve, or the precision-recall curve obtained on such data can be corrected with the knowledge of class priors; i.e., the proportions of the positive and negative examples in the unlabeled data. We extend the results to a noisy setting where some of the examples labeled positive are in fact negative and show that the correction also requires the knowledge of the proportion of noisy examples in the labeled positives. Using state-of-the-art algorithms to estimate the positive class prior and the proportion of noise, we experimentally evaluate two correction approaches and demonstrate their efficacy on real-life data.
Estimating the class prior and posterior from noisy positives and unlabeled data
Jan 31, 2017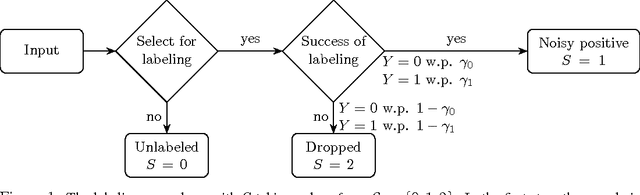
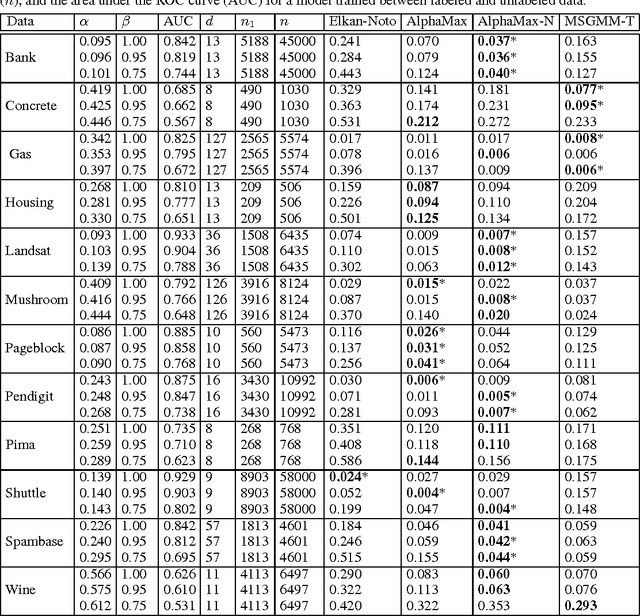
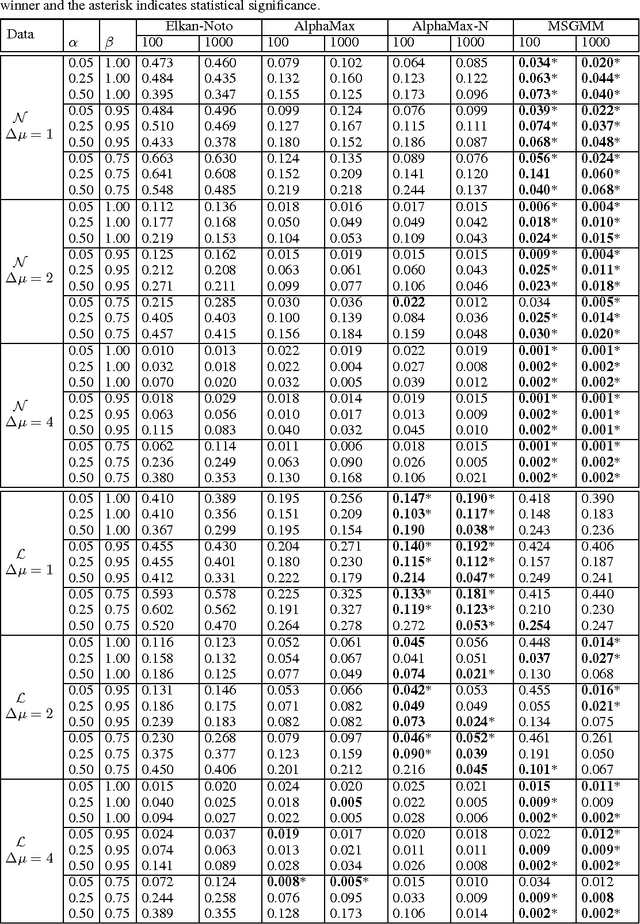
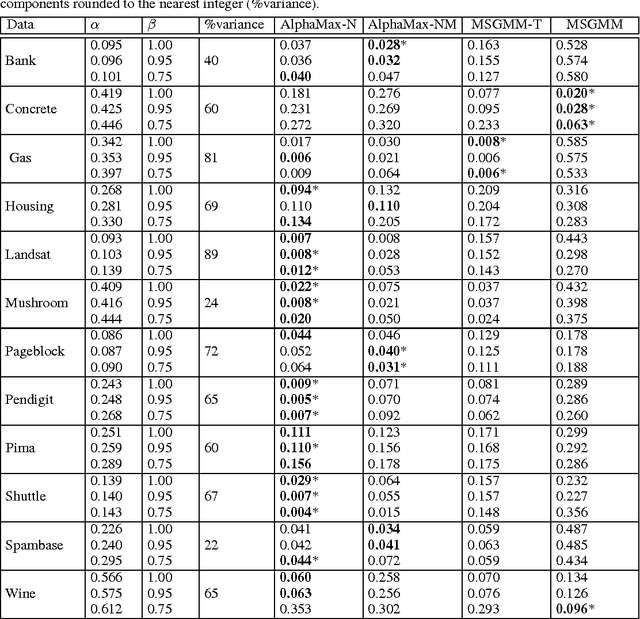
We develop a classification algorithm for estimating posterior distributions from positive-unlabeled data, that is robust to noise in the positive labels and effective for high-dimensional data. In recent years, several algorithms have been proposed to learn from positive-unlabeled data; however, many of these contributions remain theoretical, performing poorly on real high-dimensional data that is typically contaminated with noise. We build on this previous work to develop two practical classification algorithms that explicitly model the noise in the positive labels and utilize univariate transforms built on discriminative classifiers. We prove that these univariate transforms preserve the class prior, enabling estimation in the univariate space and avoiding kernel density estimation for high-dimensional data. The theoretical development and both parametric and nonparametric algorithms proposed here constitutes an important step towards wide-spread use of robust classification algorithms for positive-unlabeled data.
Nonparametric semi-supervised learning of class proportions
Jan 08, 2016
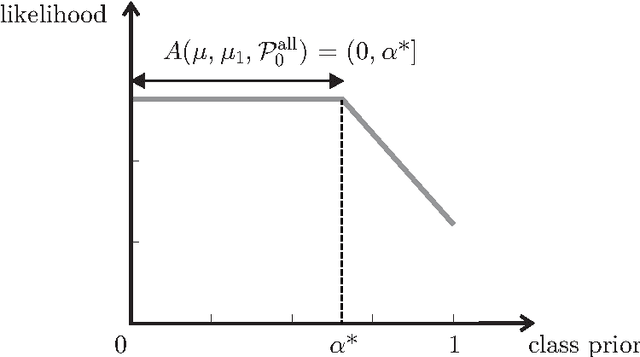
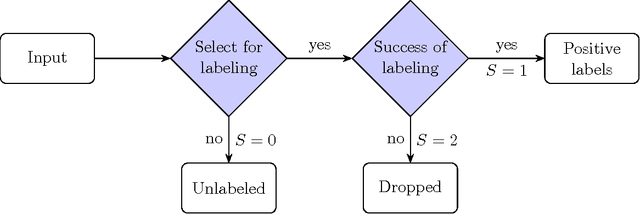
The problem of developing binary classifiers from positive and unlabeled data is often encountered in machine learning. A common requirement in this setting is to approximate posterior probabilities of positive and negative classes for a previously unseen data point. This problem can be decomposed into two steps: (i) the development of accurate predictors that discriminate between positive and unlabeled data, and (ii) the accurate estimation of the prior probabilities of positive and negative examples. In this work we primarily focus on the latter subproblem. We study nonparametric class prior estimation and formulate this problem as an estimation of mixing proportions in two-component mixture models, given a sample from one of the components and another sample from the mixture itself. We show that estimation of mixing proportions is generally ill-defined and propose a canonical form to obtain identifiability while maintaining the flexibility to model any distribution. We use insights from this theory to elucidate the optimization surface of the class priors and propose an algorithm for estimating them. To address the problems of high-dimensional density estimation, we provide practical transformations to low-dimensional spaces that preserve class priors. Finally, we demonstrate the efficacy of our method on univariate and multivariate data.