 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Benchmarking and Interpreting End-to-end Learning of MIMO and Multi-User Communication
Mar 15, 2022
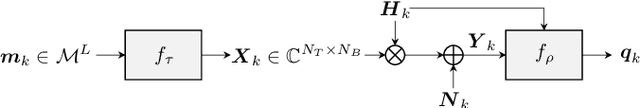
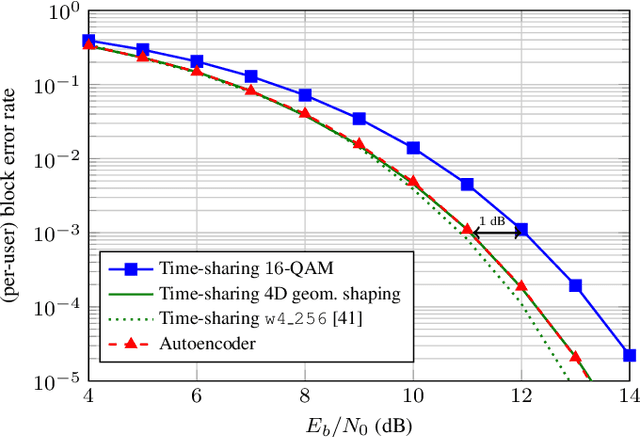
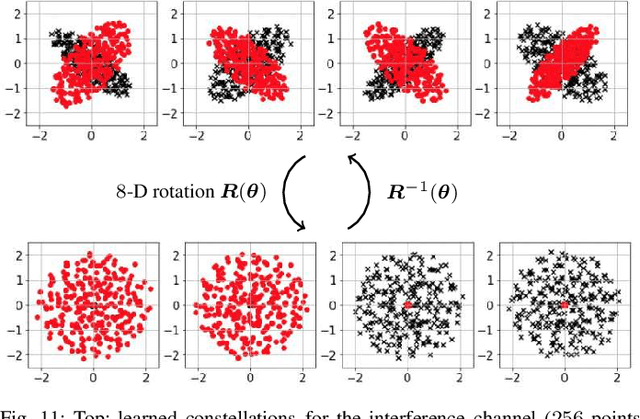
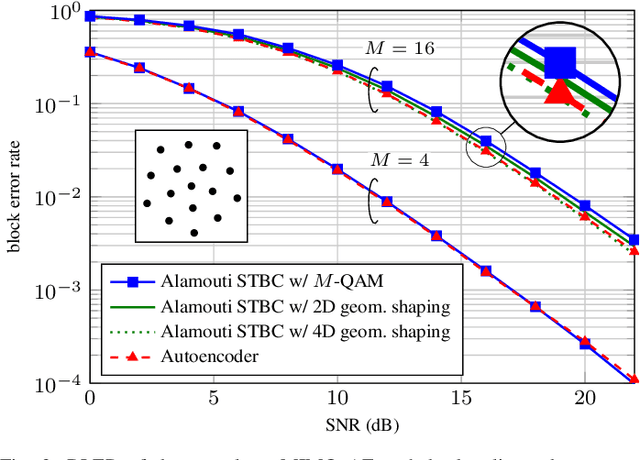
End-to-end autoencoder (AE) learning has the potential of exceeding the performance of human-engineered transceivers and encoding schemes, without a priori knowledge of communication-theoretic principles. In this work, we aim to understand to what extent and for which scenarios this claim holds true when comparing with fair benchmarks. Our particular focus is on memoryless multiple-input multiple-output (MIMO) and multi-user (MU) systems. Four case studies are considered: two point-to-point (closed-loop and open-loop MIMO) and two MU scenarios (MIMO broadcast and interference channels). For the point-to-point scenarios, we explain some of the performance gains observed in prior work through the selection of improved baseline schemes that include geometric shaping as well as bit and power allocation. For the MIMO broadcast channel, we demonstrate the feasibility of a novel AE method with centralized learning and decentralized execution. Interestingly, the learned scheme performs close to nonlinear vector-perturbation precoding and significantly outperforms conventional zero-forcing. Lastly, we highlight potential pitfalls when interpreting learned communication schemes. In particular, we show that the AE for the considered interference channel learns to avoid interference, albeit in a rotated reference frame. After de-rotating the learned signal constellation of each user, the resulting scheme corresponds to conventional time sharing with geometric shaping.
Reinforcement Learning with Time-dependent Goals for Robotic Musicians
Nov 11, 2020

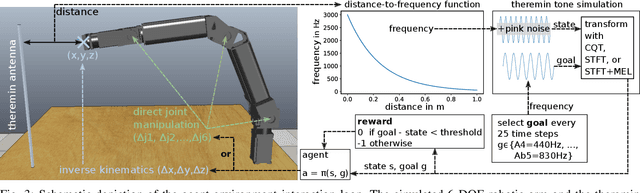

Reinforcement learning is a promising method to accomplish robotic control tasks. The task of playing musical instruments is, however, largely unexplored because it involves the challenge of achieving sequential goals - melodies - that have a temporal dimension. In this paper, we address robotic musicianship by introducing a temporal extension to goal-conditioned reinforcement learning: Time-dependent goals. We demonstrate that these can be used to train a robotic musician to play the theremin instrument. We train the robotic agent in simulation and transfer the acquired policy to a real-world robotic thereminist. Supplemental video: https://youtu.be/jvC9mPzdQN4
Risk Bounds of Multi-Pass SGD for Least Squares in the Interpolation Regime
Mar 07, 2022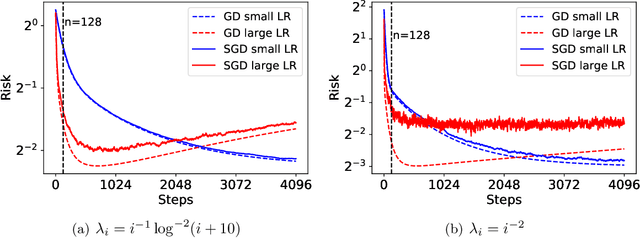
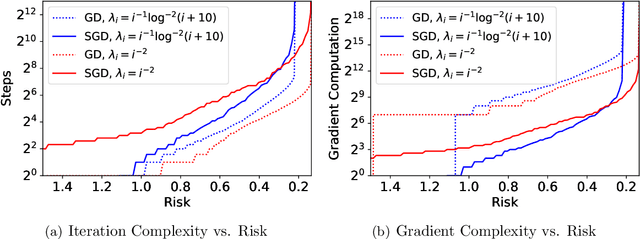
Stochastic gradient descent (SGD) has achieved great success due to its superior performance in both optimization and generalization. Most of existing generalization analyses are made for single-pass SGD, which is a less practical variant compared to the commonly-used multi-pass SGD. Besides, theoretical analyses for multi-pass SGD often concern a worst-case instance in a class of problems, which may be pessimistic to explain the superior generalization ability for some particular problem instance. The goal of this paper is to sharply characterize the generalization of multi-pass SGD, by developing an instance-dependent excess risk bound for least squares in the interpolation regime, which is expressed as a function of the iteration number, stepsize, and data covariance. We show that the excess risk of SGD can be exactly decomposed into the excess risk of GD and a positive fluctuation error, suggesting that SGD always performs worse, instance-wisely, than GD, in generalization. On the other hand, we show that although SGD needs more iterations than GD to achieve the same level of excess risk, it saves the number of stochastic gradient evaluations, and therefore is preferable in terms of computational time.
Deep Graph Convolutional Network and LSTM based approach for predicting drug-target binding affinity
Jan 18, 2022Development of new drugs is an expensive and time-consuming process. Due to the world-wide SARS-CoV-2 outbreak, it is essential that new drugs for SARS-CoV-2 are developed as soon as possible. Drug repurposing techniques can reduce the time span needed to develop new drugs by probing the list of existing FDA-approved drugs and their properties to reuse them for combating the new disease. We propose a novel architecture DeepGLSTM, which is a Graph Convolutional network and LSTM based method that predicts binding affinity values between the FDA-approved drugs and the viral proteins of SARS-CoV-2. Our proposed model has been trained on Davis, KIBA (Kinase Inhibitor Bioactivity), DTC (Drug Target Commons), Metz, ToxCast and STITCH datasets. We use our novel architecture to predict a Combined Score (calculated using Davis and KIBA score) of 2,304 FDA-approved drugs against 5 viral proteins. On the basis of the Combined Score, we prepare a list of the top-18 drugs with the highest binding affinity for 5 viral proteins present in SARS-CoV-2. Subsequently, this list may be used for the creation of new useful drugs.
AutoFR: Automated Filter Rule Generation for Adblocking
Feb 25, 2022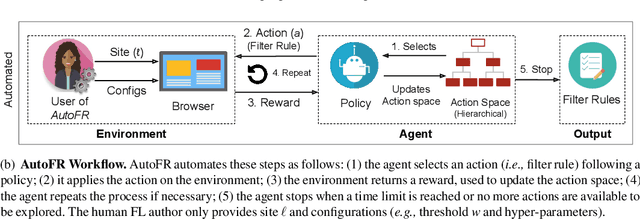

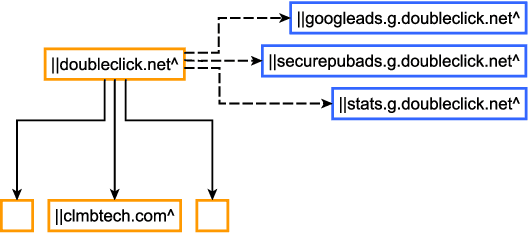

Adblocking relies on filter lists, which are manually curated and maintained by a small community of filter list authors. This manual process is laborious and does not scale well to a large number of sites and over time. We introduce AutoFR, a reinforcement learning framework to fully automate the process of filter rule creation and evaluation. We design an algorithm based on multi-arm bandits to generate filter rules while controlling the trade-off between blocking ads and avoiding breakage. We test our implementation of AutoFR on thousands of sites in terms of efficiency and effectiveness. AutoFR is efficient: it takes only a few minutes to generate filter rules for a site. AutoFR is also effective: it generates filter rules that can block 86% of the ads, as compared to 87% by EasyList while achieving comparable visual breakage. The filter rules generated by AutoFR generalize well to new and unseen sites. We envision AutoFR to assist the adblocking community in automated filter rule generation at scale.
Modelling Underwater Acoustic Propagation using One-way Wave Equations
Feb 14, 2022The primary contribution of this paper is to characterize the propagation of acoustic signal carrying information through any medium and the interaction of the travelling acoustic signal with the surrounding medium. We will use the concept of damped harmonic oscillator to model the medium and Milne's oscillator technique to map the interaction of the acoustic signal with the medium. The acoustic signal itself will be modelled using the one-way wave equation formulated in terms of acoustic pressure and velocity of acoustic waves through the medium. Using the above-mentioned concepts, we calculated the effective signal strength, phase shift and time period of the communicated signal. Numerical results are generated to present the evolution of signal strength and received signal envelope in underwater environment.
RheFrameDetect: A Text Classification System for Automatic Detection of Rhetorical Frames in AI from Open Sources
Dec 30, 2021
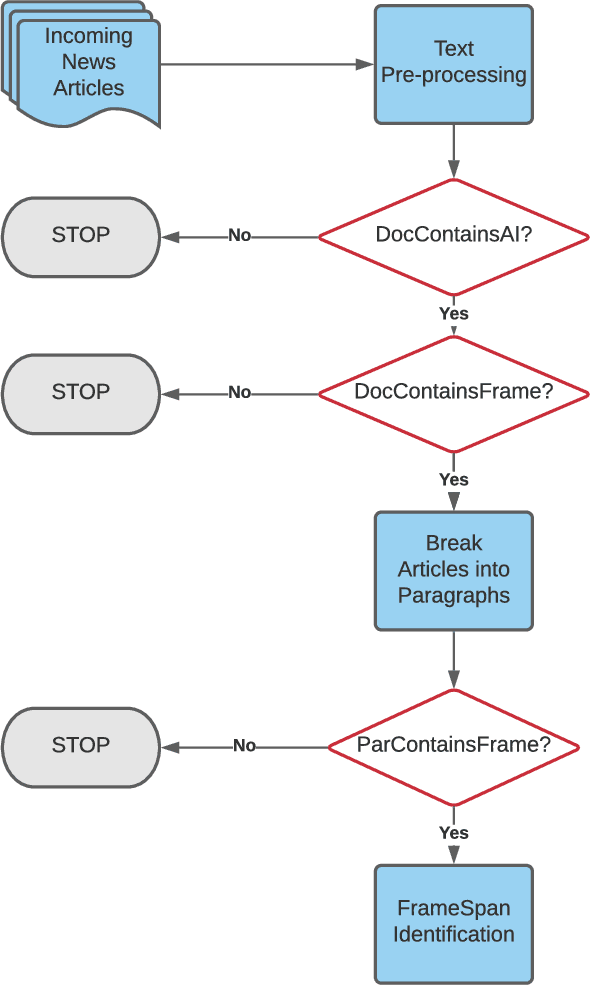
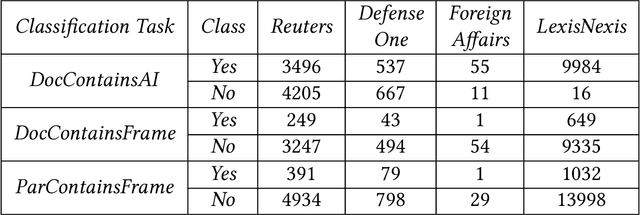
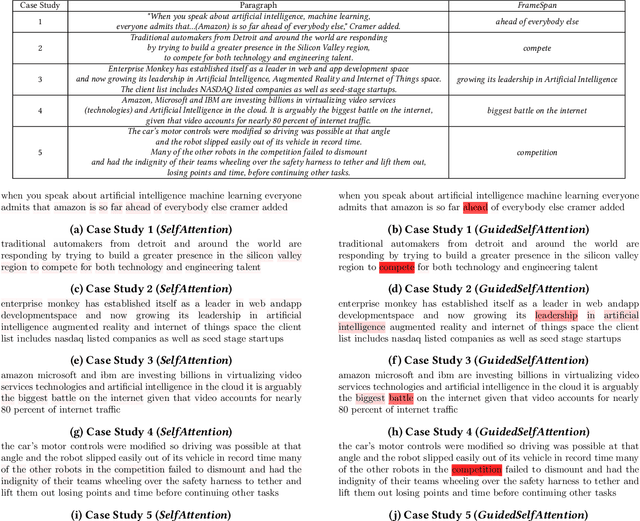
Rhetorical Frames in AI can be thought of as expressions that describe AI development as a competition between two or more actors, such as governments or companies. Examples of such Frames include robotic arms race, AI rivalry, technological supremacy, cyberwarfare dominance and 5G race. Detection of Rhetorical Frames from open sources can help us track the attitudes of governments or companies towards AI, specifically whether attitudes are becoming more cooperative or competitive over time. Given the rapidly increasing volumes of open sources (online news media, twitter, blogs), it is difficult for subject matter experts to identify Rhetorical Frames in (near) real-time. Moreover, these sources are in general unstructured (noisy) and therefore, detecting Frames from these sources will require state-of-the-art text classification techniques. In this paper, we develop RheFrameDetect, a text classification system for (near) real-time capture of Rhetorical Frames from open sources. Given an input document, RheFrameDetect employs text classification techniques at multiple levels (document level and paragraph level) to identify all occurrences of Frames used in the discussion of AI. We performed extensive evaluation of the text classification techniques used in RheFrameDetect against human annotated Frames from multiple news sources. To further demonstrate the effectiveness of RheFrameDetect, we show multiple case studies depicting the Frames identified by RheFrameDetect compared against human annotated Frames.
NetRCA: An Effective Network Fault Cause Localization Algorithm
Feb 23, 2022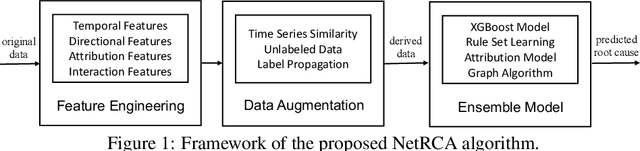
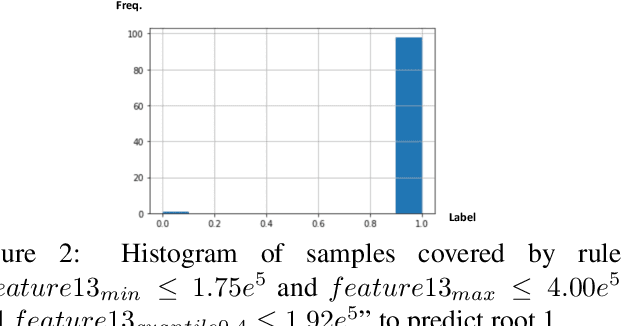
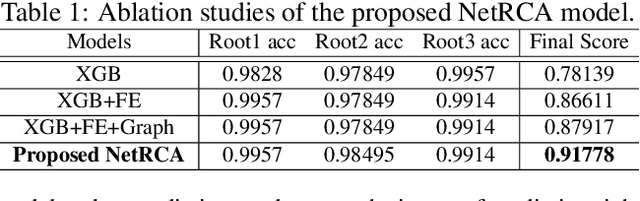
Localizing the root cause of network faults is crucial to network operation and maintenance. However, due to the complicated network architectures and wireless environments, as well as limited labeled data, accurately localizing the true root cause is challenging. In this paper, we propose a novel algorithm named NetRCA to deal with this problem. Firstly, we extract effective derived features from the original raw data by considering temporal, directional, attribution, and interaction characteristics. Secondly, we adopt multivariate time series similarity and label propagation to generate new training data from both labeled and unlabeled data to overcome the lack of labeled samples. Thirdly, we design an ensemble model which combines XGBoost, rule set learning, attribution model, and graph algorithm, to fully utilize all data information and enhance performance. Finally, experiments and analysis are conducted on the real-world dataset from ICASSP 2022 AIOps Challenge to demonstrate the superiority and effectiveness of our approach.
Near-optimal Offline Reinforcement Learning with Linear Representation: Leveraging Variance Information with Pessimism
Mar 11, 2022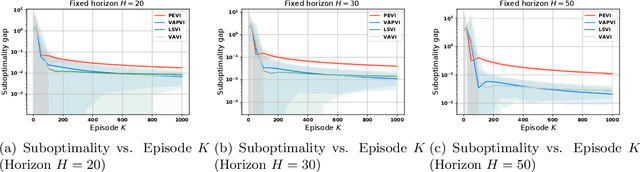
Offline reinforcement learning, which seeks to utilize offline/historical data to optimize sequential decision-making strategies, has gained surging prominence in recent studies. Due to the advantage that appropriate function approximators can help mitigate the sample complexity burden in modern reinforcement learning problems, existing endeavors usually enforce powerful function representation models (e.g. neural networks) to learn the optimal policies. However, a precise understanding of the statistical limits with function representations, remains elusive, even when such a representation is linear. Towards this goal, we study the statistical limits of offline reinforcement learning with linear model representations. To derive the tight offline learning bound, we design the variance-aware pessimistic value iteration (VAPVI), which adopts the conditional variance information of the value function for time-inhomogeneous episodic linear Markov decision processes (MDPs). VAPVI leverages estimated variances of the value functions to reweight the Bellman residuals in the least-square pessimistic value iteration and provides improved offline learning bounds over the best-known existing results (whereas the Bellman residuals are equally weighted by design). More importantly, our learning bounds are expressed in terms of system quantities, which provide natural instance-dependent characterizations that previous results are short of. We hope our results draw a clearer picture of what offline learning should look like when linear representations are provided.
InsertionNet 2.0: Minimal Contact Multi-Step Insertion Using Multimodal Multiview Sensory Input
Mar 02, 2022
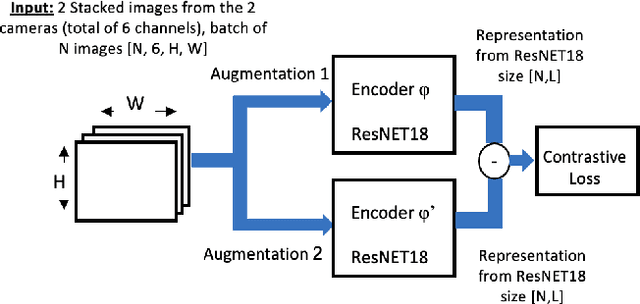
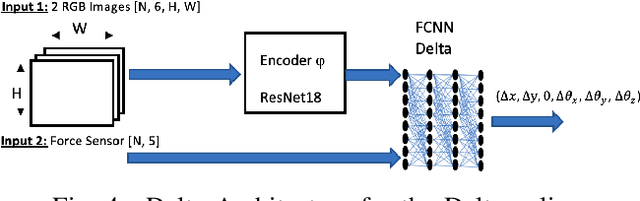
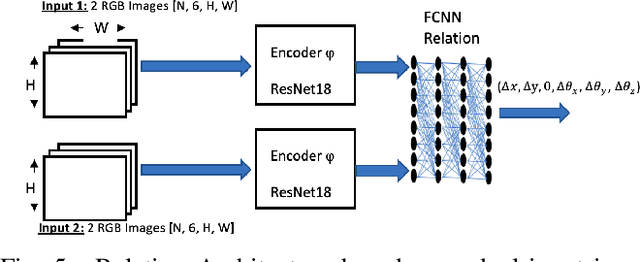
We address the problem of devising the means for a robot to rapidly and safely learn insertion skills with just a few human interventions and without hand-crafted rewards or demonstrations. Our InsertionNet version 2.0 provides an improved technique to robustly cope with a wide range of use-cases featuring different shapes, colors, initial poses, etc. In particular, we present a regression-based method based on multimodal input from stereo perception and force, augmented with contrastive learning for the efficient learning of valuable features. In addition, we introduce a one-shot learning technique for insertion, which relies on a relation network scheme to better exploit the collected data and to support multi-step insertion tasks. Our method improves on the results obtained with the original InsertionNet, achieving an almost perfect score (above 97.5$\%$ on 200 trials) in 16 real-life insertion tasks while minimizing the execution time and contact during insertion. We further demonstrate our method's ability to tackle a real-life 3-step insertion task and perfectly solve an unseen insertion task without learning.