 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk, Clarify, Optimize: Human-LLM Agent Collaboration for Smarter Inventory Control
Dec 31, 2025Inventory management remains a challenge for many small and medium-sized businesses that lack the expertise to deploy advanced optimization methods. This paper investigates whether Large Language Models (LLMs) can help bridge this gap. We show that employing LLMs as direct, end-to-end solvers incurs a significant "hallucination tax": a performance gap arising from the model's inability to perform grounded stochastic reasoning. To address this, we propose a hybrid agentic framework that strictly decouples semantic reasoning from mathematical calculation. In this architecture, the LLM functions as an intelligent interface, eliciting parameters from natural language and interpreting results while automatically calling rigorous algorithms to build the optimization engine. To evaluate this interactive system against the ambiguity and inconsistency of real-world managerial dialogue, we introduce the Human Imitator, a fine-tuned "digital twin" of a boundedly rational manager that enables scalable, reproducible stress-testing. Our empirical analysis reveals that the hybrid agentic framework reduces total inventory costs by 32.1% relative to an interactive baseline using GPT-4o as an end-to-end solver. Moreover, we find that providing perfect ground-truth information alone is insufficient to improve GPT-4o's performance, confirming that the bottleneck is fundamentally computational rather than informational. Our results position LLMs not as replacements for operations research, but as natural-language interfaces that make rigorous, solver-based policies accessible to non-experts.
PILAF: Optimal Human Preference Sampling for Reward Modeling
Feb 06, 2025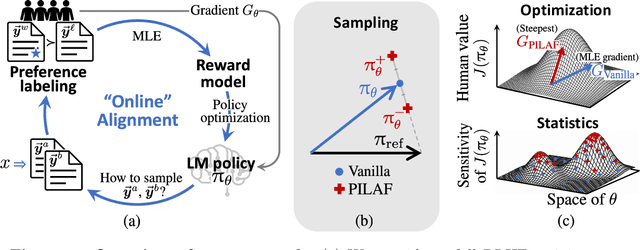

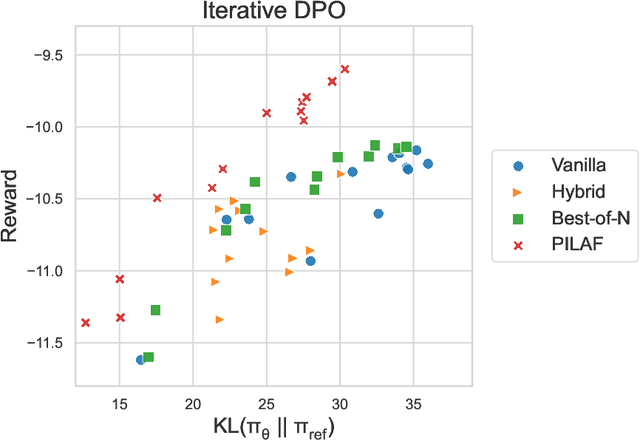
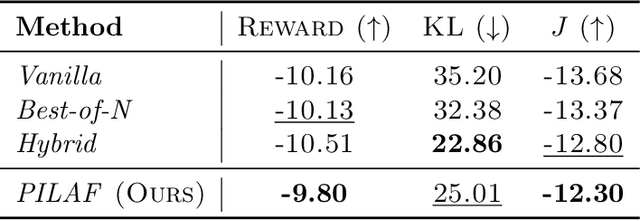
As large language models increasingly drive real-world applications, aligning them with human values becomes paramount. Reinforcement Learning from Human Feedback (RLHF) has emerged as a key technique, translating preference data into reward models when oracle human values remain inaccessible. In practice, RLHF mostly relies on approximate reward models, which may not consistently guide the policy toward maximizing the underlying human values. We propose Policy-Interpolated Learning for Aligned Feedback (PILAF), a novel response sampling strategy for preference labeling that explicitly aligns preference learning with maximizing the underlying oracle reward. PILAF is theoretically grounded, demonstrating optimality from both an optimization and a statistical perspective. The method is straightforward to implement and demonstrates strong performance in iterative and online RLHF settings where feedback curation is critical.
Localized exploration in contextual dynamic pricing achieves dimension-free regret
Dec 26, 2024We study the problem of contextual dynamic pricing with a linear demand model. We propose a novel localized exploration-then-commit (LetC) algorithm which starts with a pure exploration stage, followed by a refinement stage that explores near the learned optimal pricing policy, and finally enters a pure exploitation stage. The algorithm is shown to achieve a minimax optimal, dimension-free regret bound when the time horizon exceeds a polynomial of the covariate dimension. Furthermore, we provide a general theoretical framework that encompasses the entire time spectrum, demonstrating how to balance exploration and exploitation when the horizon is limited. The analysis is powered by a novel critical inequality that depicts the exploration-exploitation trade-off in dynamic pricing, mirroring its existing counterpart for the bias-variance trade-off in regularized regression. Our theoretical results are validated by extensive experiments on synthetic and real-world data.
Taming "data-hungry" reinforcement learning? Stability in continuous state-action spaces
Jan 10, 2024We introduce a novel framework for analyzing reinforcement learning (RL) in continuous state-action spaces, and use it to prove fast rates of convergence in both off-line and on-line settings. Our analysis highlights two key stability properties, relating to how changes in value functions and/or policies affect the Bellman operator and occupation measures. We argue that these properties are satisfied in many continuous state-action Markov decision processes, and demonstrate how they arise naturally when using linear function approximation methods. Our analysis offers fresh perspectives on the roles of pessimism and optimism in off-line and on-line RL, and highlights the connection between off-line RL and transfer learning.
Policy evaluation from a single path: Multi-step methods, mixing and mis-specification
Nov 07, 2022


We study non-parametric estimation of the value function of an infinite-horizon $\gamma$-discounted Markov reward process (MRP) using observations from a single trajectory. We provide non-asymptotic guarantees for a general family of kernel-based multi-step temporal difference (TD) estimates, including canonical $K$-step look-ahead TD for $K = 1, 2, \ldots$ and the TD$(\lambda)$ family for $\lambda \in [0,1)$ as special cases. Our bounds capture its dependence on Bellman fluctuations, mixing time of the Markov chain, any mis-specification in the model, as well as the choice of weight function defining the estimator itself, and reveal some delicate interactions between mixing time and model mis-specification. For a given TD method applied to a well-specified model, its statistical error under trajectory data is similar to that of i.i.d. sample transition pairs, whereas under mis-specification, temporal dependence in data inflates the statistical error. However, any such deterioration can be mitigated by increased look-ahead. We complement our upper bounds by proving minimax lower bounds that establish optimality of TD-based methods with appropriately chosen look-ahead and weighting, and reveal some fundamental differences between value function estimation and ordinary non-parametric regression.
Near-optimal Offline Reinforcement Learning with Linear Representation: Leveraging Variance Information with Pessimism
Mar 11, 2022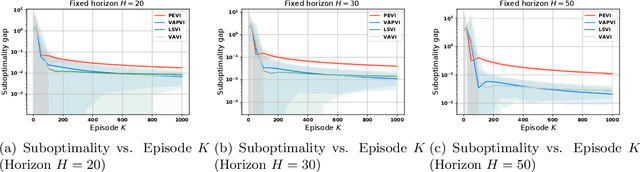
Offline reinforcement learning, which seeks to utilize offline/historical data to optimize sequential decision-making strategies, has gained surging prominence in recent studies. Due to the advantage that appropriate function approximators can help mitigate the sample complexity burden in modern reinforcement learning problems, existing endeavors usually enforce powerful function representation models (e.g. neural networks) to learn the optimal policies. However, a precise understanding of the statistical limits with function representations, remains elusive, even when such a representation is linear. Towards this goal, we study the statistical limits of offline reinforcement learning with linear model representations. To derive the tight offline learning bound, we design the variance-aware pessimistic value iteration (VAPVI), which adopts the conditional variance information of the value function for time-inhomogeneous episodic linear Markov decision processes (MDPs). VAPVI leverages estimated variances of the value functions to reweight the Bellman residuals in the least-square pessimistic value iteration and provides improved offline learning bounds over the best-known existing results (whereas the Bellman residuals are equally weighted by design). More importantly, our learning bounds are expressed in terms of system quantities, which provide natural instance-dependent characterizations that previous results are short of. We hope our results draw a clearer picture of what offline learning should look like when linear representations are provided.
Adaptive and Robust Multi-task Learning
Feb 10, 2022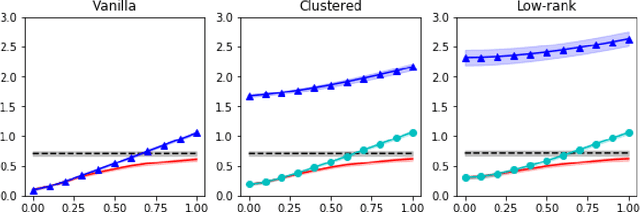

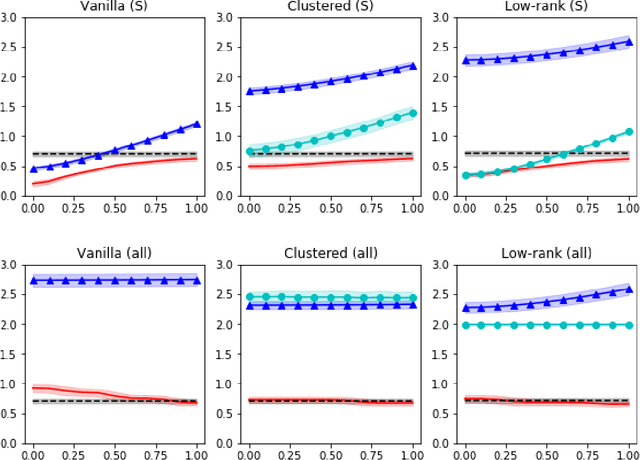
We study the multi-task learning problem that aims to simultaneously analyze multiple datasets collected from different sources and learn one model for each of them. We propose a family of adaptive methods that automatically utilize possible similarities among those tasks while carefully handling their differences. We derive sharp statistical guarantees for the methods and prove their robustness against outlier tasks. Numerical experiments on synthetic and real datasets demonstrate the efficacy of our new methods.
Optimal policy evaluation using kernel-based temporal difference methods
Sep 24, 2021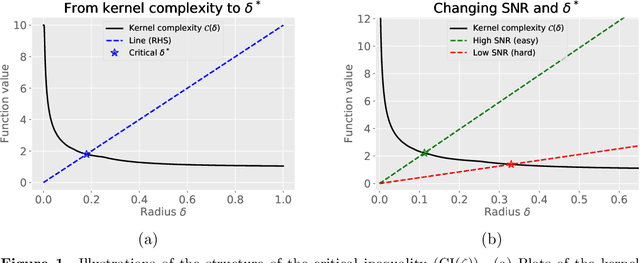
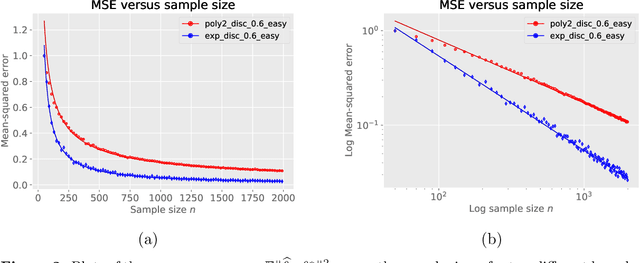
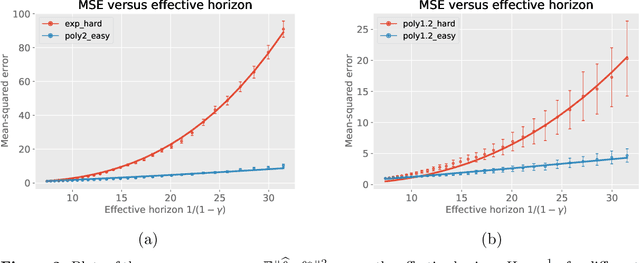
We study methods based on reproducing kernel Hilbert spaces for estimating the value function of an infinite-horizon discounted Markov reward process (MRP). We study a regularized form of the kernel least-squares temporal difference (LSTD) estimate; in the population limit of infinite data, it corresponds to the fixed point of a projected Bellman operator defined by the associated reproducing kernel Hilbert space. The estimator itself is obtained by computing the projected fixed point induced by a regularized version of the empirical operator; due to the underlying kernel structure, this reduces to solving a linear system involving kernel matrices. We analyze the error of this estimate in the $L^2(\mu)$-norm, where $\mu$ denotes the stationary distribution of the underlying Markov chain. Our analysis imposes no assumptions on the transition operator of the Markov chain, but rather only conditions on the reward function and population-level kernel LSTD solutions. We use empirical process theory techniques to derive a non-asymptotic upper bound on the error with explicit dependence on the eigenvalues of the associated kernel operator, as well as the instance-dependent variance of the Bellman residual error. In addition, we prove minimax lower bounds over sub-classes of MRPs, which shows that our rate is optimal in terms of the sample size $n$ and the effective horizon $H = (1 - \gamma)^{-1}$. Whereas existing worst-case theory predicts cubic scaling ($H^3$) in the effective horizon, our theory reveals that there is in fact a much wider range of scalings, depending on the kernel, the stationary distribution, and the variance of the Bellman residual error. Notably, it is only parametric and near-parametric problems that can ever achieve the worst-case cubic scaling.
PU-Flow: a Point Cloud Upsampling Networkwith Normalizing Flows
Jul 13, 2021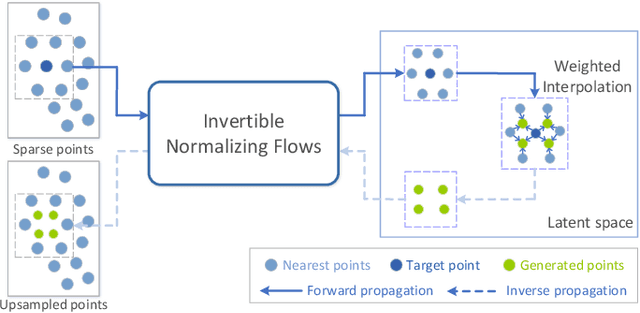
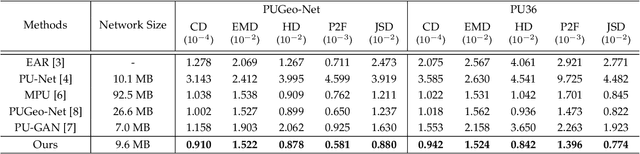
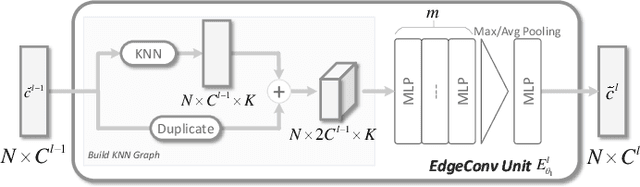
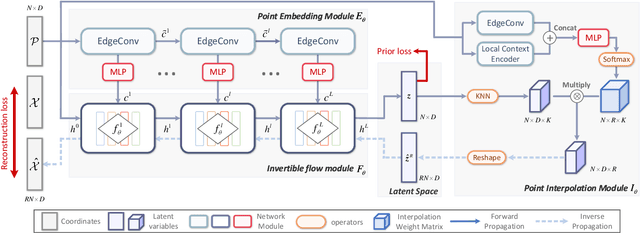
Point cloud upsampling aims to generate dense point clouds from given sparse ones, which is a challenging task due to the irregular and unordered nature of point sets. To address this issue, we present a novel deep learning-based model, called PU-Flow,which incorporates normalizing flows and feature interpolation techniques to produce dense points uniformly distributed on the underlying surface. Specifically, we formulate the upsampling process as point interpolation in a latent space, where the interpolation weights are adaptively learned from local geometric context, and exploit the invertible characteristics of normalizing flows to transform points between Euclidean and latent spaces. We evaluate PU-Flow on a wide range of 3D models with sharp features and high-frequency details. Qualitative and quantitative results show that our method outperforms state-of-the-art deep learning-based approaches in terms of reconstruction quality, proximity-to-surface accuracy, and computation efficiency.
Learning Good State and Action Representations via Tensor Decomposition
May 03, 2021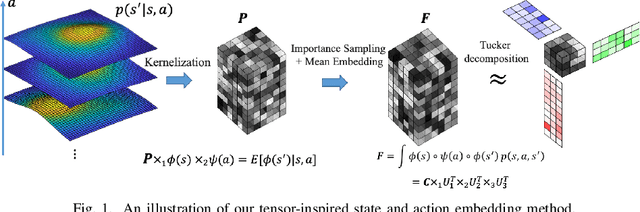
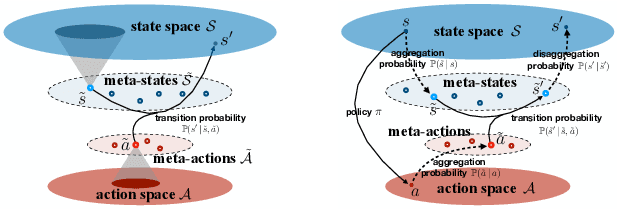
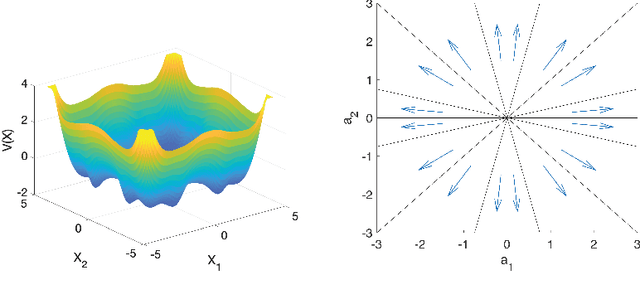
The transition kernel of a continuous-state-action Markov decision process (MDP) admits a natural tensor structure. This paper proposes a tensor-inspired unsupervised learning method to identify meaningful low-dimensional state and action representations from empirical trajectories. The method exploits the MDP's tensor structure by kernelization, importance sampling and low-Tucker-rank approximation. This method can be further used to cluster states and actions respectively and find the best discrete MDP abstraction. We provide sharp statistical error bounds for tensor concentration and the preservation of diffusion distance after embedding.