 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Conditional Approximate Normalizing Flows for Joint Multi-Step Probabilistic Forecasting with Application to Electricity Demand
Jan 14, 2022
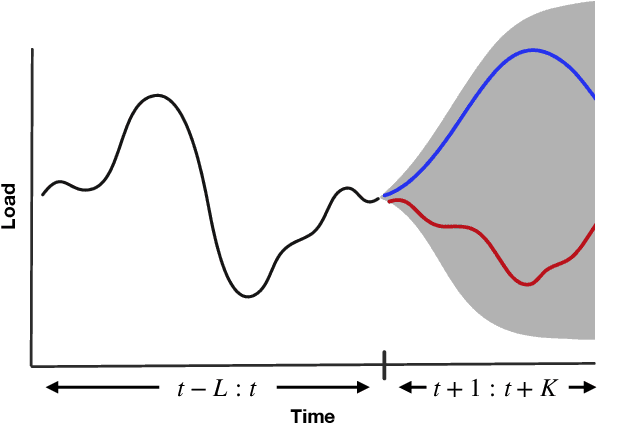
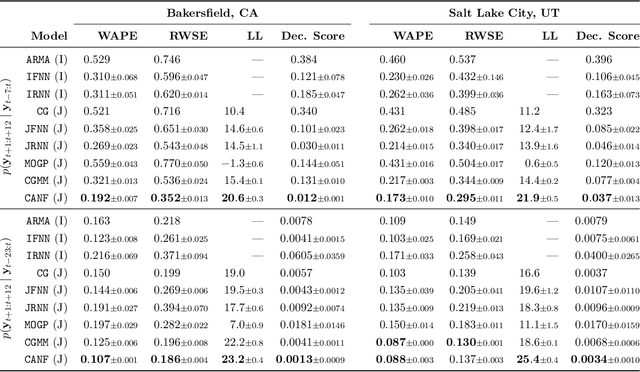
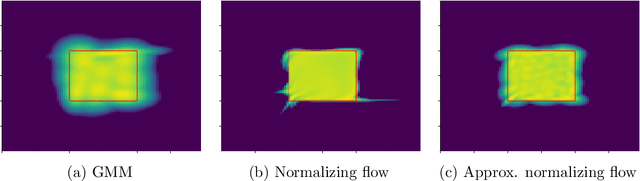
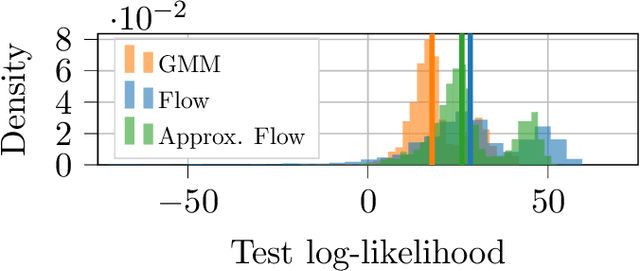
Some real-world decision-making problems require making probabilistic forecasts over multiple steps at once. However, methods for probabilistic forecasting may fail to capture correlations in the underlying time-series that exist over long time horizons as errors accumulate. One such application is with resource scheduling under uncertainty in a grid environment, which requires forecasting electricity demand that is inherently noisy, but often cyclic. In this paper, we introduce the conditional approximate normalizing flow (CANF) to make probabilistic multi-step time-series forecasts when correlations are present over long time horizons. We first demonstrate our method's efficacy on estimating the density of a toy distribution, finding that CANF improves the KL divergence by one-third compared to that of a Gaussian mixture model while still being amenable to explicit conditioning. We then use a publicly available household electricity consumption dataset to showcase the effectiveness of CANF on joint probabilistic multi-step forecasting. Empirical results show that conditional approximate normalizing flows outperform other methods in terms of multi-step forecast accuracy and lead to up to 10x better scheduling decisions. Our implementation is available at https://github.com/sisl/JointDemandForecasting.
A simple and robust method for noise variance estimation for time-varying signals
Apr 07, 2021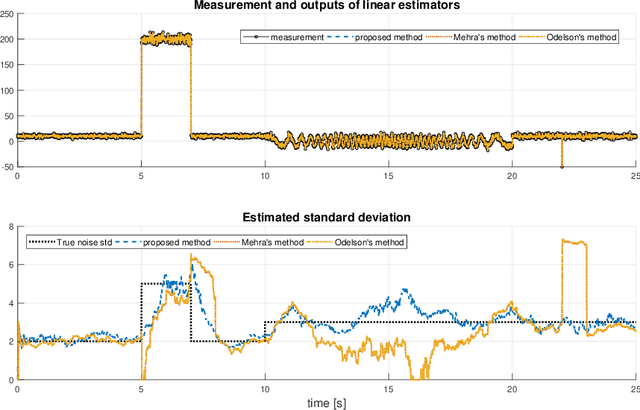
In this brief paper, we present a simple approach to estimate the variance of measurement noise with time-varying 1-D signals. The proposed approach exploits the relationship between the noise variance and the variance of the prediction errors (or innovation sequence) of a linear estimator, the idea that was pioneered by [9] and [2]. Compared with the classic and more recent methods in the same category, the proposed method can render more robust estimates with the presence of unmodelled dynamics and outliers in the measurement.
Bringing Rolling Shutter Images Alive with Dual Reversed Distortion
Mar 12, 2022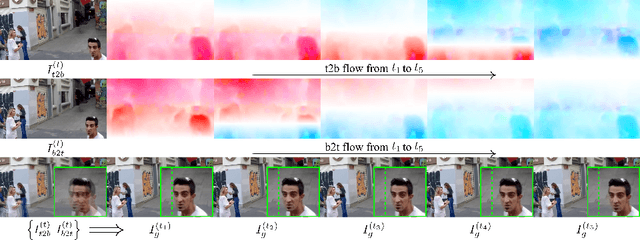

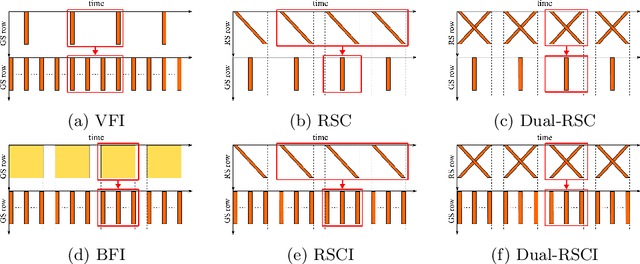
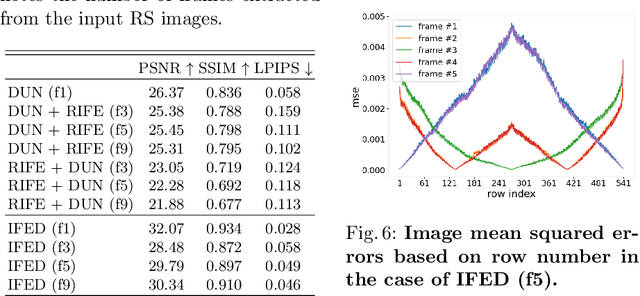
Rolling shutter (RS) distortion can be interpreted as the result of picking a row of pixels from instant global shutter (GS) frames over time during the exposure of the RS camera. This means that the information of each instant GS frame is partially, yet sequentially, embedded into the row-dependent distortion. Inspired by this fact, we address the challenging task of reversing this process, i.e., extracting undistorted GS frames from images suffering from RS distortion. However, since RS distortion is coupled with other factors such as readout settings and the relative velocity of scene elements to the camera, models that only exploit the geometric correlation between temporally adjacent images suffer from poor generality in processing data with different readout settings and dynamic scenes with both camera motion and object motion. In this paper, instead of two consecutive frames, we propose to exploit a pair of images captured by dual RS cameras with reversed RS directions for this highly challenging task. Grounded on the symmetric and complementary nature of dual reversed distortion, we develop a novel end-to-end model, IFED, to generate dual optical flow sequence through iterative learning of the velocity field during the RS time. Extensive experimental results demonstrate that IFED is superior to naive cascade schemes, as well as the state-of-the-art which utilizes adjacent RS images. Most importantly, although it is trained on a synthetic dataset, IFED is shown to be effective at retrieving GS frame sequences from real-world RS distorted images of dynamic scenes.
Efficient Argument Structure Extraction with Transfer Learning and Active Learning
Apr 01, 2022
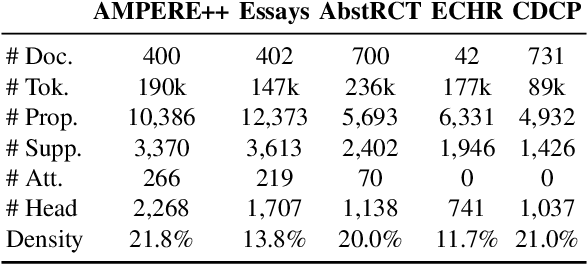
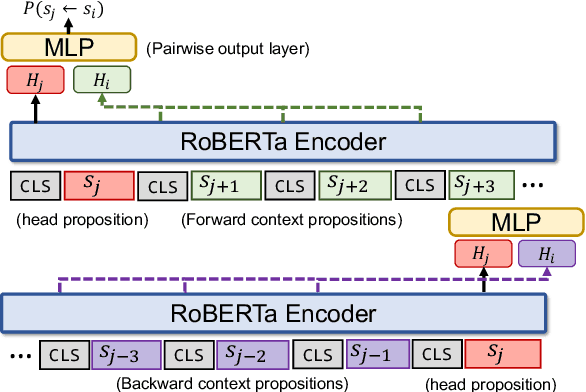
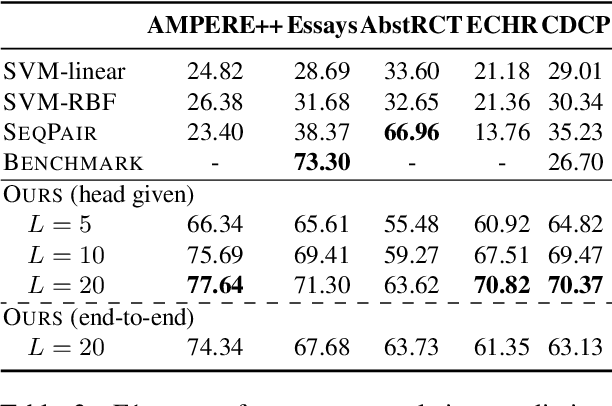
The automation of extracting argument structures faces a pair of challenges on (1) encoding long-term contexts to facilitate comprehensive understanding, and (2) improving data efficiency since constructing high-quality argument structures is time-consuming. In this work, we propose a novel context-aware Transformer-based argument structure prediction model which, on five different domains, significantly outperforms models that rely on features or only encode limited contexts. To tackle the difficulty of data annotation, we examine two complementary methods: (i) transfer learning to leverage existing annotated data to boost model performance in a new target domain, and (ii) active learning to strategically identify a small amount of samples for annotation. We further propose model-independent sample acquisition strategies, which can be generalized to diverse domains. With extensive experiments, we show that our simple-yet-effective acquisition strategies yield competitive results against three strong comparisons. Combined with transfer learning, substantial F1 score boost (5-25) can be further achieved during the early iterations of active learning across domains.
Boosting the Learning for Ranking Patterns
Mar 05, 2022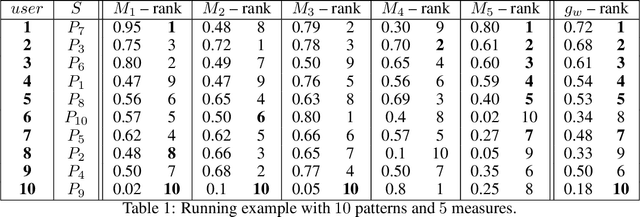
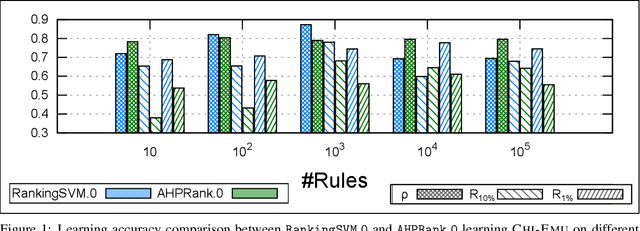

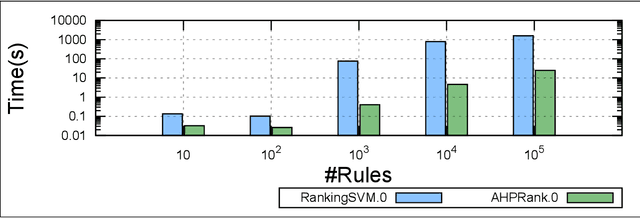
Discovering relevant patterns for a particular user remains a challenging tasks in data mining. Several approaches have been proposed to learn user-specific pattern ranking functions. These approaches generalize well, but at the expense of the running time. On the other hand, several measures are often used to evaluate the interestingness of patterns, with the hope to reveal a ranking that is as close as possible to the user-specific ranking. In this paper, we formulate the problem of learning pattern ranking functions as a multicriteria decision making problem. Our approach aggregates different interestingness measures into a single weighted linear ranking function, using an interactive learning procedure that operates in either passive or active modes. A fast learning step is used for eliciting the weights of all the measures by mean of pairwise comparisons. This approach is based on Analytic Hierarchy Process (AHP), and a set of user-ranked patterns to build a preference matrix, which compares the importance of measures according to the user-specific interestingness. A sensitivity based heuristic is proposed for the active learning mode, in order to insure high quality results with few user ranking queries. Experiments conducted on well-known datasets show that our approach significantly reduces the running time and returns precise pattern ranking, while being robust to user-error compared with state-of-the-art approaches.
APAN: Asynchronous Propagate Attention Network for Real-time Temporal Graph Embedding
Nov 23, 2020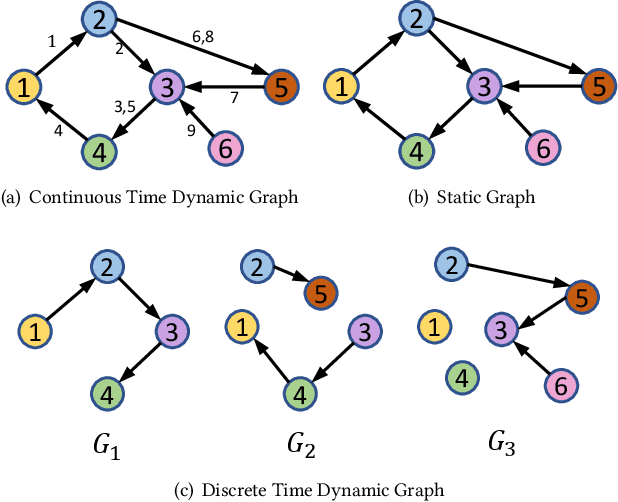
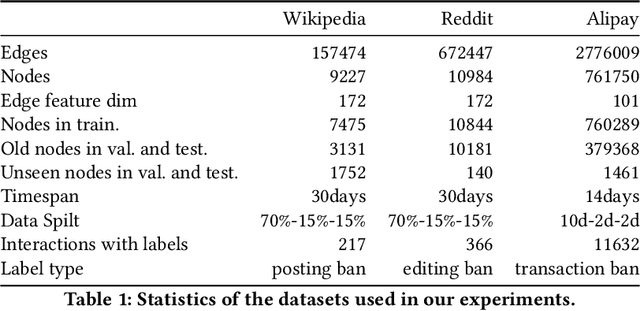
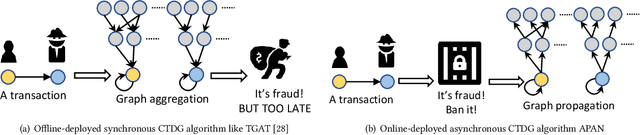
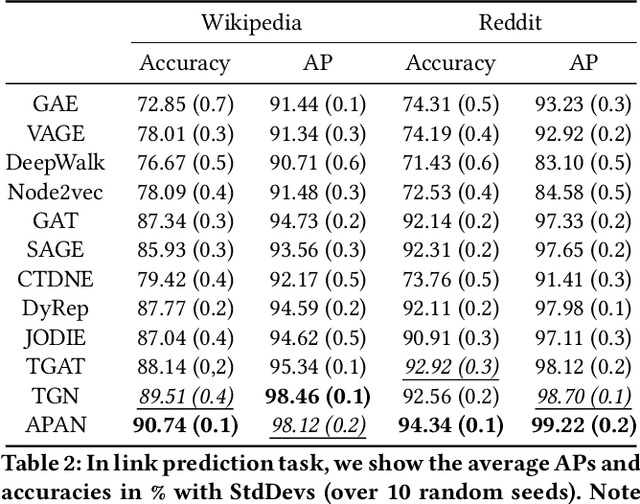
Limited by the time complexity of querying k-hop neighbors in a graph database, most graph algorithms cannot be deployed online and execute millisecond-level inference. This problem dramatically limits the potential of applying graph algorithms in certain areas, such as financial fraud detection. Therefore, we propose Asynchronous Propagate Attention Network, an asynchronous continuous time dynamic graph algorithm for real-time temporal graph embedding. Traditional graph models usually execute two serial operations: first graph computation and then model inference. We decouple model inference and graph computation step so that the heavy graph query operations will not damage the speed of model inference. Extensive experiments demonstrate that the proposed method can achieve competitive performance and 8.7 times inference speed improvement in the meantime. The source code is published at a Github repository.
Visual Mechanisms Inspired Efficient Transformers for Image and Video Quality Assessment
Apr 06, 2022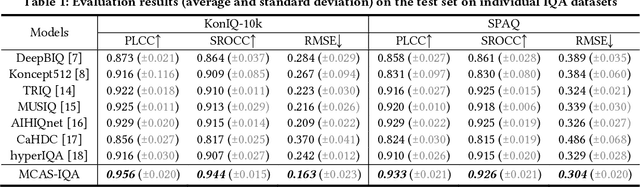

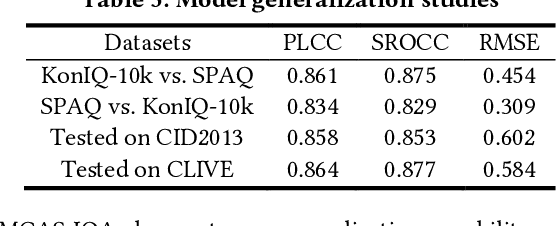
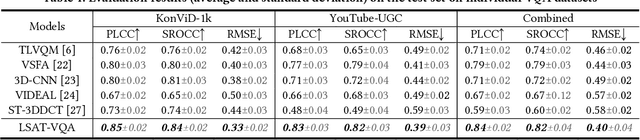
Visual (image, video) quality assessments can be modelled by visual features in different domains, e.g., spatial, frequency, and temporal domains. Perceptual mechanisms in the human visual system (HVS) play a crucial role in generation of quality perception. This paper proposes a general framework for no-reference visual quality assessment using efficient windowed transformer architectures. A lightweight module for multi-stage channel attention is integrated into Swin (shifted window) Transformer. Such module can represent appropriate perceptual mechanisms in image quality assessment (IQA) to build an accurate IQA model. Meanwhile, representative features for image quality perception in the spatial and frequency domains can also be derived from the IQA model, which are then fed into another windowed transformer architecture for video quality assessment (VQA). The VQA model efficiently reuses attention information across local windows to tackle the issue of expensive time and memory complexities of original transformer. Experimental results on both large-scale IQA and VQA databases demonstrate that the proposed quality assessment models outperform other state-of-the-art models by large margins. The complete source code will be published on Github.
Microstructure Surface Reconstruction from SEM Images: An Alternative to Digital Image Correlation (DIC)
Mar 25, 2022
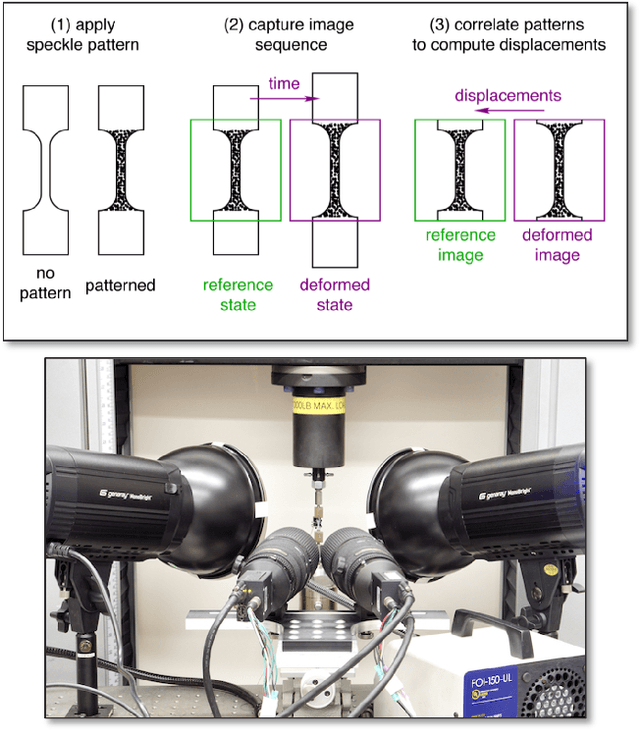


We reconstruct a 3D model of the surface of a material undergoing fatigue testing and experiencing cracking. Specifically we reconstruct the surface depth (out of plane intrusions and extrusions) and lateral (in-plane) motion from multiple views of the sample at the end of the experiment, combined with a reverse optical flow propagation backwards in time that utilizes interim single view images. These measurements can be mapped to a material strain tensor which helps to understand material life and predict failure. This approach offers an alternative to the commonly used Digital Image Correlation (DIC) technique which relies on tracking a speckle pattern applied to the material surface. DIC only produces in-plane (2D) measurements whereas our approach is 3D and non-invasive (requires no pattern being applied to the material).
iELAS: An ELAS-Based Energy-Efficient Accelerator for Real-Time Stereo Matching on FPGA Platform
Apr 11, 2021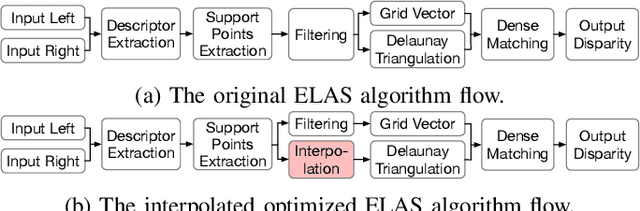
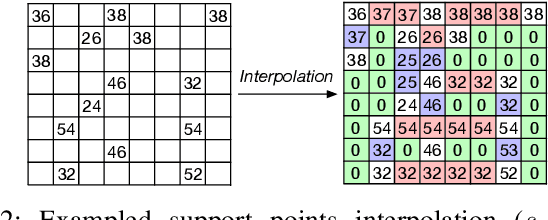

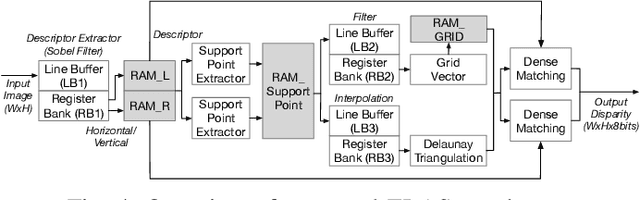
Stereo matching is a critical task for robot navigation and autonomous vehicles, providing the depth estimation of surroundings. Among all stereo matching algorithms, Efficient Large-scale Stereo (ELAS) offers one of the best tradeoffs between efficiency and accuracy. However, due to the inherent iterative process and unpredictable memory access pattern, ELAS can only run at 1.5-3 fps on high-end CPUs and difficult to achieve real-time performance on low-power platforms. In this paper, we propose an energy-efficient architecture for real-time ELAS-based stereo matching on FPGA platform. Moreover, the original computational-intensive and irregular triangulation module is reformed in a regular manner with points interpolation, which is much more hardware-friendly. Optimizations, including memory management, parallelism, and pipelining, are further utilized to reduce memory footprint and improve throughput. Compared with Intel i7 CPU and the state-of-the-art CPU+FPGA implementation, our FPGA realization achieves up to 38.4x and 3.32x frame rate improvement, and up to 27.1x and 1.13x energy efficiency improvement, respectively.
Approximating a deep reinforcement learning docking agent using linear model trees
Mar 01, 2022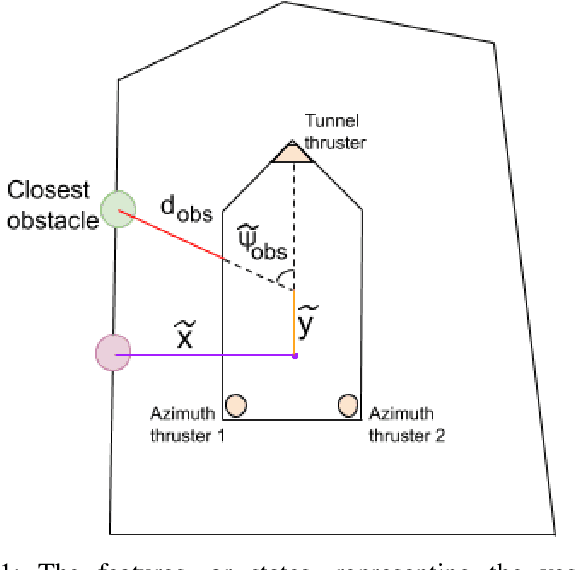
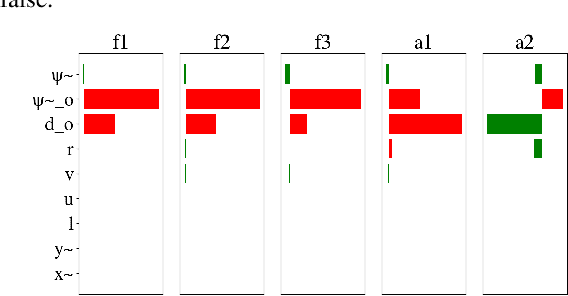
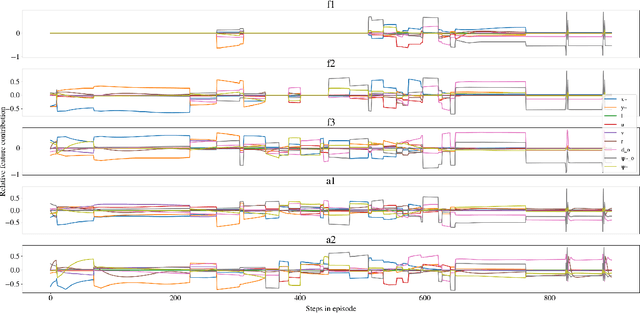
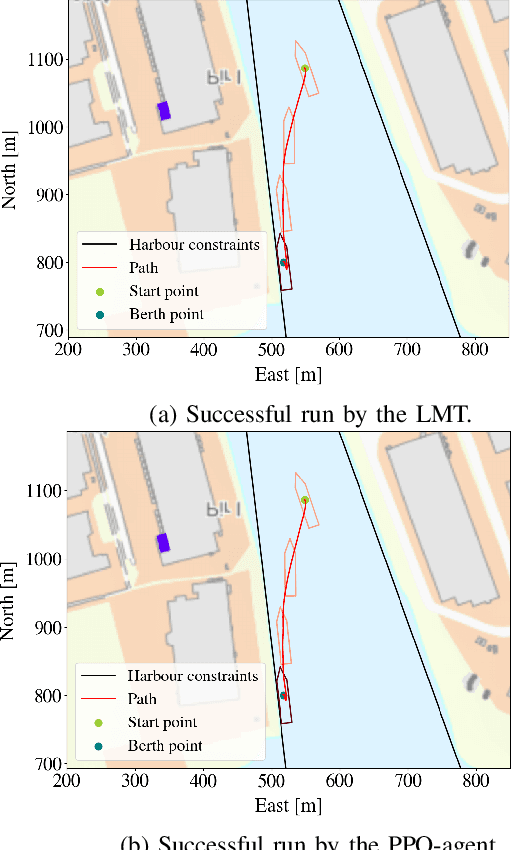
Deep reinforcement learning has led to numerous notable results in robotics. However, deep neural networks (DNNs) are unintuitive, which makes it difficult to understand their predictions and strongly limits their potential for real-world applications due to economic, safety, and assurance reasons. To remedy this problem, a number of explainable AI methods have been presented, such as SHAP and LIME, but these can be either be too costly to be used in real-time robotic applications or provide only local explanations. In this paper, the main contribution is the use of a linear model tree (LMT) to approximate a DNN policy, originally trained via proximal policy optimization(PPO), for an autonomous surface vehicle with five control inputs performing a docking operation. The two main benefits of the proposed approach are: a) LMTs are transparent which makes it possible to associate directly the outputs (control actions, in our case) with specific values of the input features, b) LMTs are computationally efficient and can provide information in real-time. In our simulations, the opaque DNN policy controls the vehicle and the LMT runs in parallel to provide explanations in the form of feature attributions. Our results indicate that LMTs can be a useful component within digital assurance frameworks for autonomous ships.