 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SOLIS: Autonomous Solubility Screening using Deep Neural Networks
Mar 18, 2022




Accelerating material discovery has tremendous societal and industrial impact, particularly for pharmaceuticals and clean energy production. Many experimental instruments have some degree of automation, facilitating continuous running and higher throughput. However, it is common that sample preparation is still carried out manually. This can result in researchers spending a significant amount of their time on repetitive tasks, which introduces errors and can prohibit production of statistically relevant data. Crystallisation experiments are common in many chemical fields, both for purification and in polymorph screening experiments. The initial step often involves a solubility screen of the molecule; that is, understanding whether molecular compounds have dissolved in a particular solvent. This usually can be time consuming and work intensive. Moreover, accurate knowledge of the precise solubility limit of the molecule is often not required, and simply measuring a threshold of solubility in each solvent would be sufficient. To address this, we propose a novel cascaded deep model that is inspired by how a human chemist would visually assess a sample to determine whether the solid has completely dissolved in the solution. In this paper, we design, develop, and evaluate the first fully autonomous solubility screening framework, which leverages state-of-the-art methods for image segmentation and convolutional neural networks for image classification. To realise that, we first create a dataset comprising different molecules and solvents, which is collected in a real-world chemistry laboratory. We then evaluated our method on the data recorded through an eye-in-hand camera mounted on a seven degree-of-freedom robotic manipulator, and show that our model can achieve 99.13% test accuracy across various setups.
NPBG++: Accelerating Neural Point-Based Graphics
Mar 24, 2022
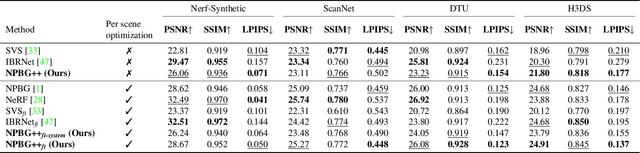
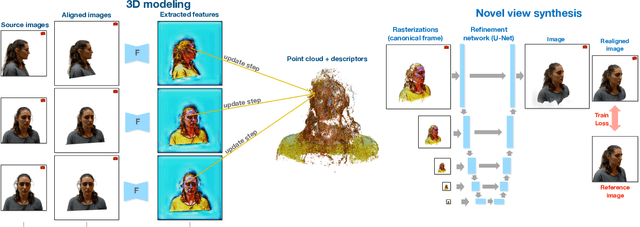
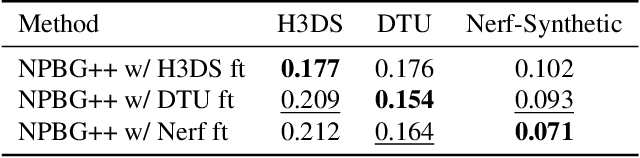
We present a new system (NPBG++) for the novel view synthesis (NVS) task that achieves high rendering realism with low scene fitting time. Our method efficiently leverages the multiview observations and the point cloud of a static scene to predict a neural descriptor for each point, improving upon the pipeline of Neural Point-Based Graphics in several important ways. By predicting the descriptors with a single pass through the source images, we lift the requirement of per-scene optimization while also making the neural descriptors view-dependent and more suitable for scenes with strong non-Lambertian effects. In our comparisons, the proposed system outperforms previous NVS approaches in terms of fitting and rendering runtimes while producing images of similar quality.
OSOP: A Multi-Stage One Shot Object Pose Estimation Framework
Mar 30, 2022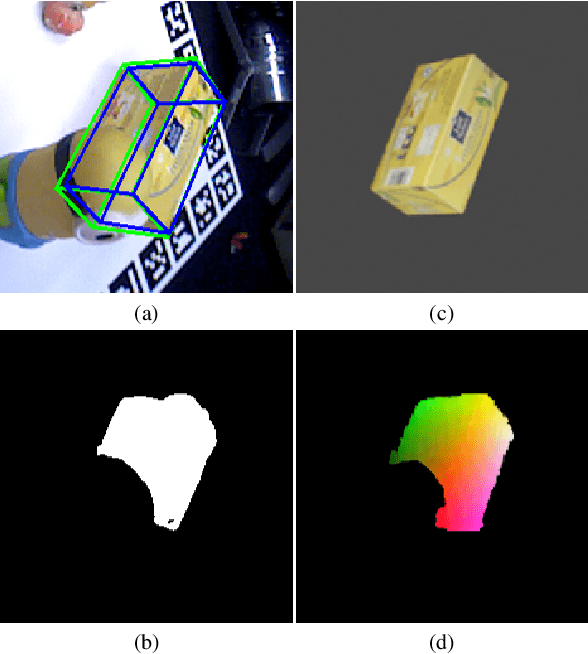
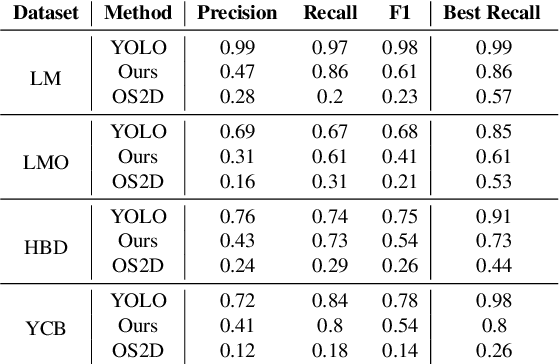
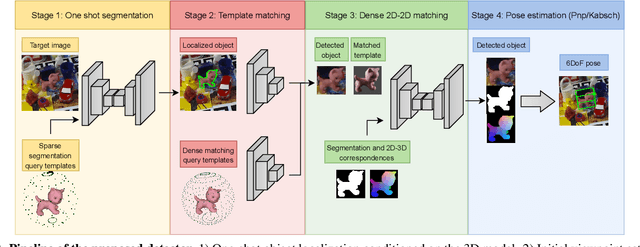
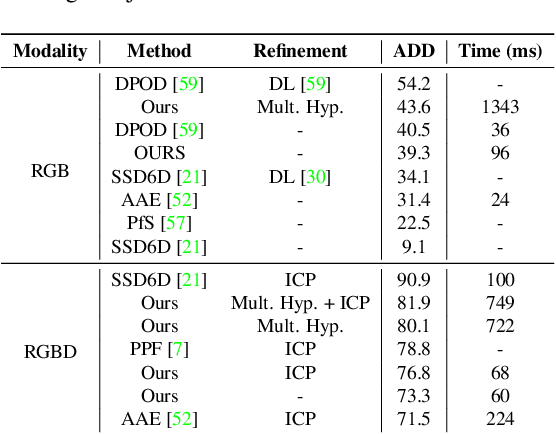
We present a novel one-shot method for object detection and 6 DoF pose estimation, that does not require training on target objects. At test time, it takes as input a target image and a textured 3D query model. The core idea is to represent a 3D model with a number of 2D templates rendered from different viewpoints. This enables CNN-based direct dense feature extraction and matching. The object is first localized in 2D, then its approximate viewpoint is estimated, followed by dense 2D-3D correspondence prediction. The final pose is computed with PnP. We evaluate the method on LineMOD, Occlusion, Homebrewed, YCB-V and TLESS datasets and report very competitive performance in comparison to the state-of-the-art methods trained on synthetic data, even though our method is not trained on the object models used for testing.
FedSpace: An Efficient Federated Learning Framework at Satellites and Ground Stations
Feb 02, 2022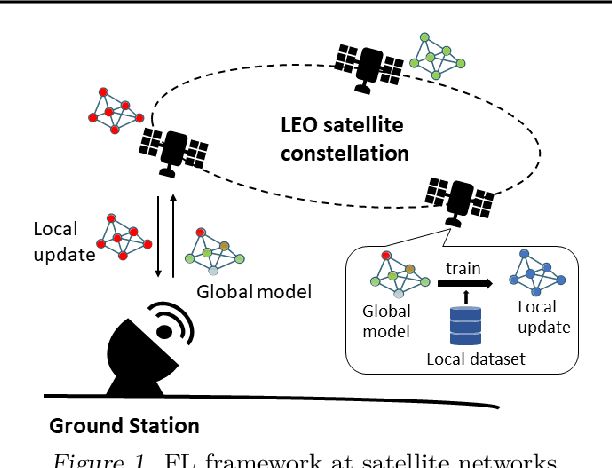
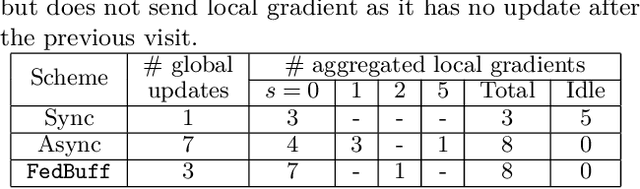
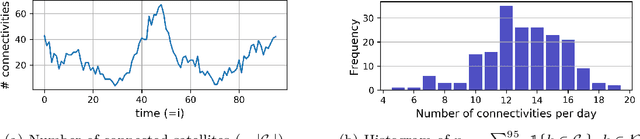
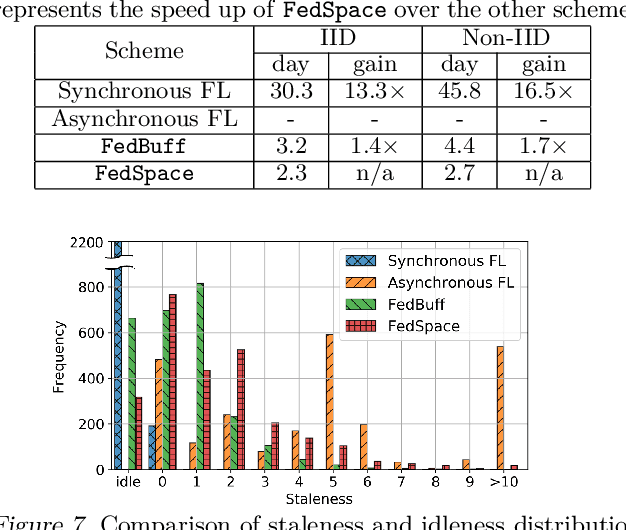
Large-scale deployments of low Earth orbit (LEO) satellites collect massive amount of Earth imageries and sensor data, which can empower machine learning (ML) to address global challenges such as real-time disaster navigation and mitigation. However, it is often infeasible to download all the high-resolution images and train these ML models on the ground because of limited downlink bandwidth, sparse connectivity, and regularization constraints on the imagery resolution. To address these challenges, we leverage Federated Learning (FL), where ground stations and satellites collaboratively train a global ML model without sharing the captured images on the satellites. We show fundamental challenges in applying existing FL algorithms among satellites and ground stations, and we formulate an optimization problem which captures a unique trade-off between staleness and idleness. We propose a novel FL framework, named FedSpace, which dynamically schedules model aggregation based on the deterministic and time-varying connectivity according to satellite orbits. Extensive numerical evaluations based on real-world satellite images and satellite networks show that FedSpace reduces the training time by 1.7 days (38.6%) over the state-of-the-art FL algorithms.
A Novel Fully Annotated Thermal Infrared Face Dataset: Recorded in Various Environment Conditions and Distances From The Camera
Apr 29, 2022
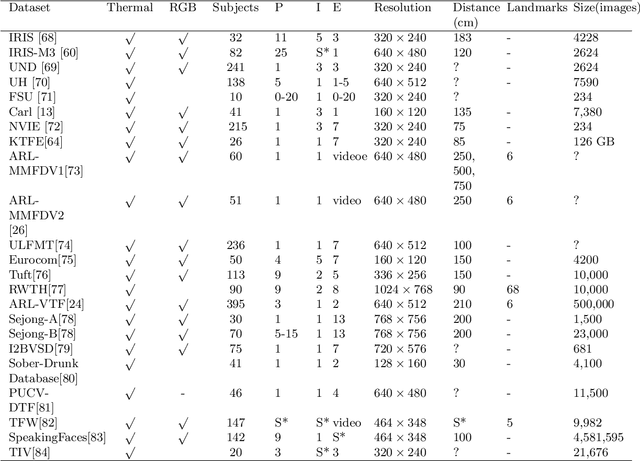
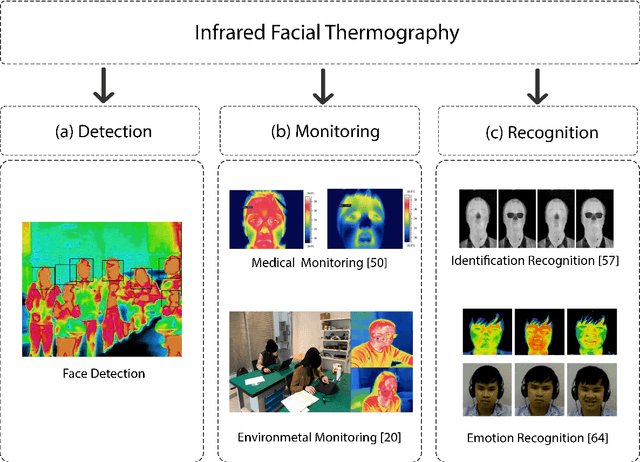
Facial thermography is one of the most popular research areas in infrared thermal imaging, with diverse applications in medical, surveillance, and environmental monitoring. However, in contrast to facial imagery in the visual spectrum, the lack of public datasets on facial thermal images is an obstacle to research improvement in this area. Thermal face imagery is still a relatively new research area to be evaluated and studied in different domains.The current thermal face datasets are limited in regards to the subjects' distance from the camera, the ambient temperature variation, and facial landmarks' localization. We address these gaps by presenting a new facial thermography dataset. This article makes two main contributions to the body of knowledge. First, it presents a comprehensive review and comparison of current public datasets in facial thermography. Second, it introduces and studies a novel public dataset on facial thermography, which we call it Charlotte-ThermalFace. Charlotte-ThermalFace contains more than10000 infrared thermal images in varying thermal conditions, several distances from the camera, and different head positions. The data is fully annotated with the facial landmarks, ambient temperature, relative humidity, the air speed of the room, distance to the camera, and subject thermal sensation at the time of capturing each image. Our dataset is the first publicly available thermal dataset annotated with the thermal sensation of each subject in different thermal conditions and one of the few datasets in raw 16-bit format. Finally, we present a preliminary analysis of the dataset to show the applicability and importance of the thermal conditions in facial thermography. The full dataset, including annotations, are freely available for research purpose at https://github.com/TeCSAR-UNCC/UNCC-ThermalFace
Time regularization as a solution to mitigate quantization induced performance degradation
Oct 30, 2020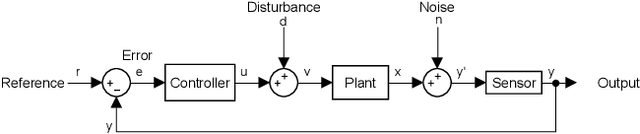
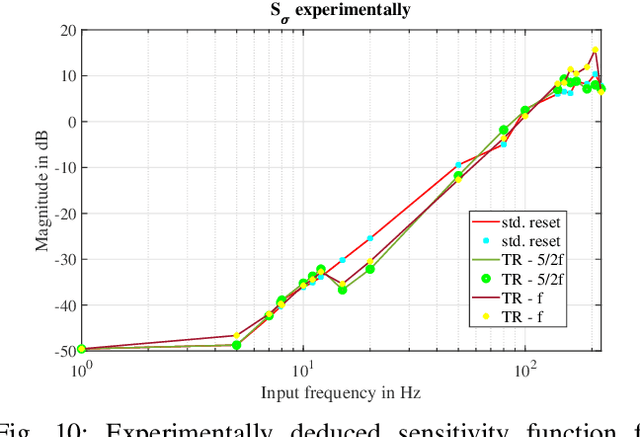
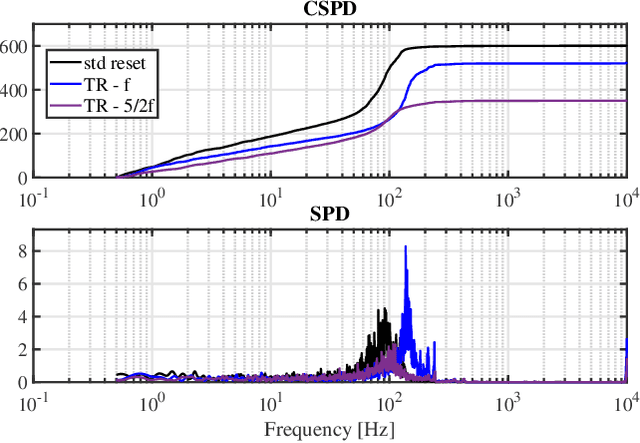
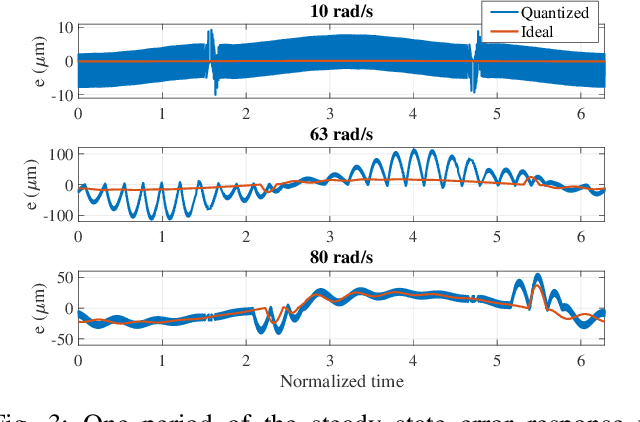
Reset control is known to be able to outperform PID and the like linear controllers. However, in motion control systems, quantization can cause severe performance degradation. This paper shows the application of time regularization to mitigate this practical issue in reset control systems. Numerical simulations have been conducted in order to analyze the cause of the quantization induced performance degradation and the effectiveness of time regularization to mitigate this degradation; with tuning guidelines for the time regularization parameter also provided. Moreover, a robustness analysis is performed. The solution is also tested experimentally on a high precision motion system for validation. It is estimated by numerical simulations that time regularization can reduce quantization induced performance degradation by almost 10 dB. Experiments have similarly shown a reduction of several dB for the high precision motion stage.
Human-Robot Shared Control for Surgical Robot Based on Context-Aware Sim-to-Real Adaptation
Apr 23, 2022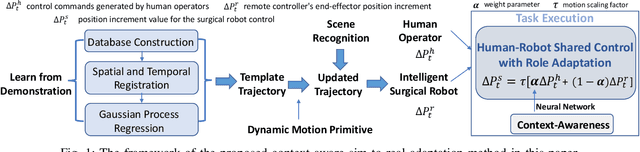
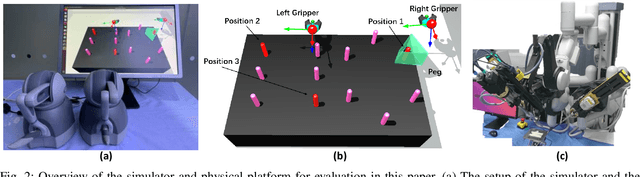
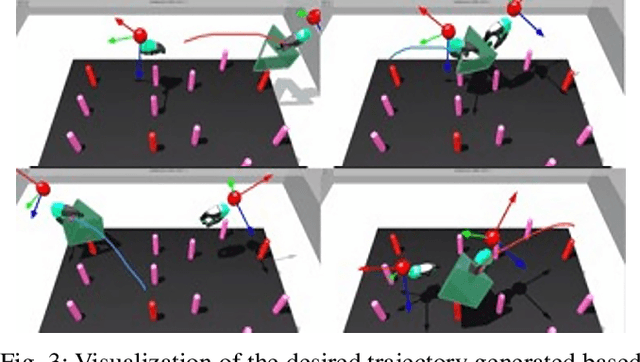
Human-robot shared control, which integrates the advantages of both humans and robots, is an effective approach to facilitate efficient surgical operation. Learning from demonstration (LfD) techniques can be used to automate some of the surgical subtasks for the construction of the shared control mechanism. However, a sufficient amount of data is required for the robot to learn the manoeuvres. Using a surgical simulator to collect data is a less resource-demanding approach. With sim-to-real adaptation, the manoeuvres learned from a simulator can be transferred to a physical robot. To this end, we propose a sim-to-real adaptation method to construct a human-robot shared control framework for robotic surgery. In this paper, a desired trajectory is generated from a simulator using LfD method, while dynamic motion primitives (DMP) is used to transfer the desired trajectory from the simulator to the physical robotic platform. Moreover, a role adaptation mechanism is developed such that the robot can adjust its role according to the surgical operation contexts predicted by a neural network model. The effectiveness of the proposed framework is validated on the da Vinci Research Kit (dVRK). Results of the user studies indicated that with the adaptive human-robot shared control framework, the path length of the remote controller, the total clutching number and the task completion time can be reduced significantly. The proposed method outperformed the traditional manual control via teleoperation.
Precipitaion Nowcasting using Deep Neural Network
Mar 24, 2022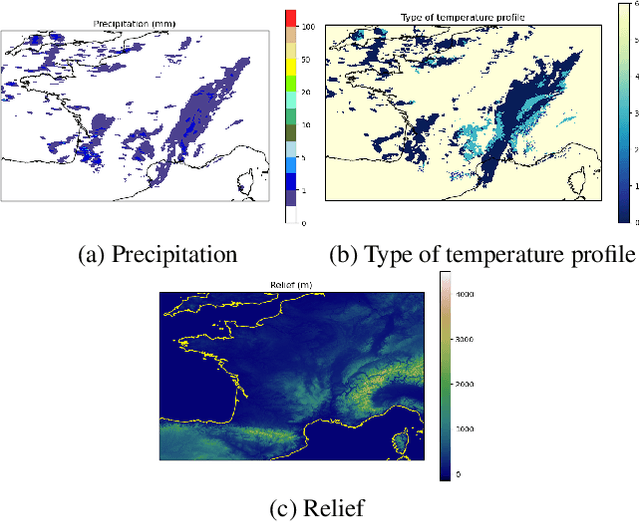
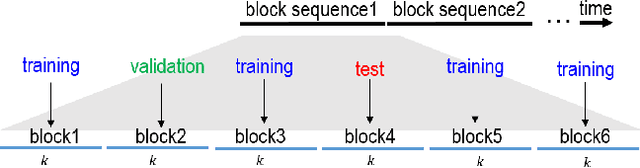
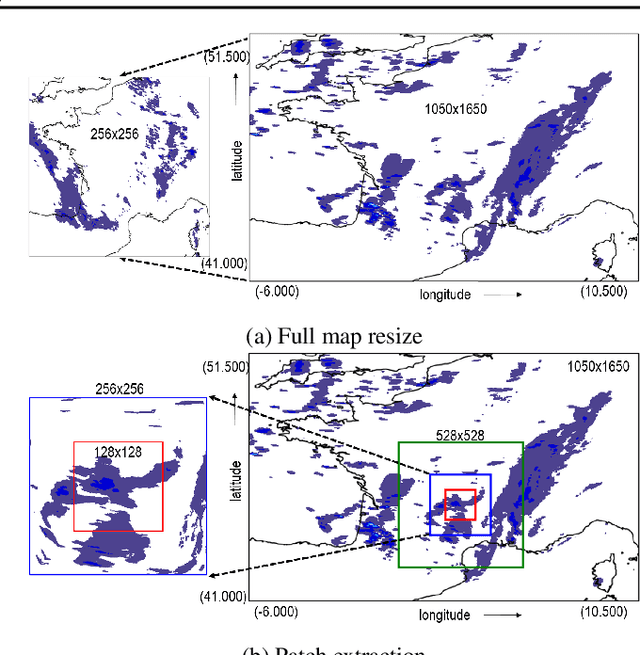
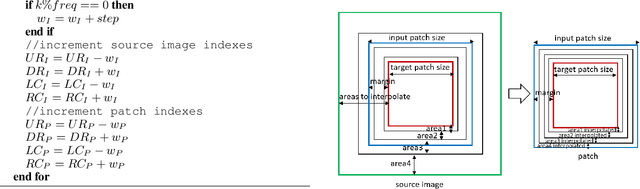
Precipitation nowcasting is of great importance for weather forecast users, for activities ranging from outdoor activities and sports competitions to airport traffic management. In contrast to long-term precipitation forecasts which are traditionally obtained from numerical models, precipitation nowcasting needs to be very fast. It is therefore more challenging to obtain because of this time constraint. Recently, many machine learning based methods had been proposed. We propose the use three popular deep learning models (U-net, ConvLSTM and SVG-LP) trained on two-dimensional precipitation maps for precipitation nowcasting. We proposed an algorithm for patch extraction to obtain high resolution precipitation maps. We proposed a loss function to solve the blurry image issue and to reduce the influence of zero value pixels in precipitation maps.
Decision-Dependent Risk Minimization in Geometrically Decaying Dynamic Environments
Apr 08, 2022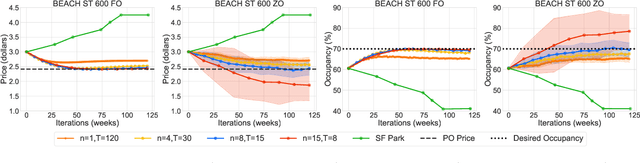

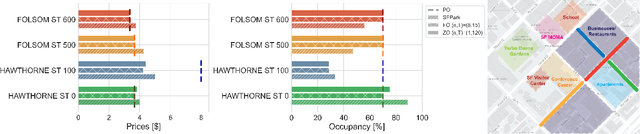
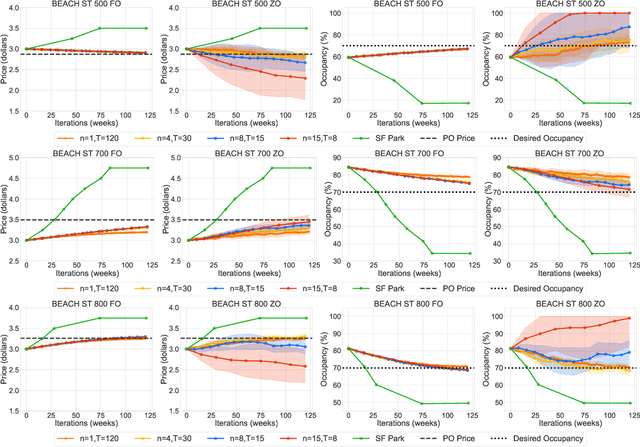
This paper studies the problem of expected loss minimization given a data distribution that is dependent on the decision-maker's action and evolves dynamically in time according to a geometric decay process. Novel algorithms for both the information setting in which the decision-maker has a first order gradient oracle and the setting in which they have simply a loss function oracle are introduced. The algorithms operate on the same underlying principle: the decision-maker repeatedly deploys a fixed decision over the length of an epoch, thereby allowing the dynamically changing environment to sufficiently mix before updating the decision. The iteration complexity in each of the settings is shown to match existing rates for first and zero order stochastic gradient methods up to logarithmic factors. The algorithms are evaluated on a "semi-synthetic" example using real world data from the SFpark dynamic pricing pilot study; it is shown that the announced prices result in an improvement for the institution's objective (target occupancy), while achieving an overall reduction in parking rates.
Learning Efficiently Function Approximation for Contextual MDP
Mar 02, 2022
We study learning contextual MDPs using a function approximation for both the rewards and the dynamics. We consider both the case where the dynamics is known and unknown, and the case that the dynamics dependent or independent of the context. For all four models we derive polynomial sample and time complexity (assuming an efficient ERM oracle). Our methodology gives a general reduction from learning contextual MDP to supervised learning.