 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFruitNeRF++: A Generalized Multi-Fruit Counting Method Utilizing Contrastive Learning and Neural Radiance Fields
May 26, 2025



We introduce FruitNeRF++, a novel fruit-counting approach that combines contrastive learning with neural radiance fields to count fruits from unstructured input photographs of orchards. Our work is based on FruitNeRF, which employs a neural semantic field combined with a fruit-specific clustering approach. The requirement for adaptation for each fruit type limits the applicability of the method, and makes it difficult to use in practice. To lift this limitation, we design a shape-agnostic multi-fruit counting framework, that complements the RGB and semantic data with instance masks predicted by a vision foundation model. The masks are used to encode the identity of each fruit as instance embeddings into a neural instance field. By volumetrically sampling the neural fields, we extract a point cloud embedded with the instance features, which can be clustered in a fruit-agnostic manner to obtain the fruit count. We evaluate our approach using a synthetic dataset containing apples, plums, lemons, pears, peaches, and mangoes, as well as a real-world benchmark apple dataset. Our results demonstrate that FruitNeRF++ is easier to control and compares favorably to other state-of-the-art methods.
Blind Localization and Clustering of Anomalies in Textures
Apr 18, 2024



Anomaly detection and localization in images is a growing field in computer vision. In this area, a seemingly understudied problem is anomaly clustering, i.e., identifying and grouping different types of anomalies in a fully unsupervised manner. In this work, we propose a novel method for clustering anomalies in largely stationary images (textures) in a blind setting. That is, the input consists of normal and anomalous images without distinction and without labels. What contributes to the difficulty of the task is that anomalous regions are often small and may present only subtle changes in appearance, which can be easily overshadowed by the genuine variance in the texture. Moreover, each anomaly type may have a complex appearance distribution. We introduce a novel scheme for solving this task using a combination of blind anomaly localization and contrastive learning. By identifying the anomalous regions with high fidelity, we can restrict our focus to those regions of interest; then, contrastive learning is employed to increase the separability of different anomaly types and reduce the intra-class variation. Our experiments show that the proposed solution yields significantly better results compared to prior work, setting a new state of the art. Project page: https://reality.tf.fau.de/pub/ardelean2024blind.html.
High-Fidelity Zero-Shot Texture Anomaly Localization Using Feature Correspondence Analysis
Apr 13, 2023



We propose a novel method for Zero-Shot Anomaly Localization that leverages a bidirectional mapping derived from the 1-dimensional Wasserstein Distance. The proposed approach allows pinpointing the anomalous regions in a texture with increased precision by aggregating the contribution of a pixel to the errors of all nearby patches. We validate our solution on several datasets and obtain more than a 40% reduction in error over the previous state of the art on the MVTec AD dataset in a zero-shot setting.
NPBG++: Accelerating Neural Point-Based Graphics
Mar 24, 2022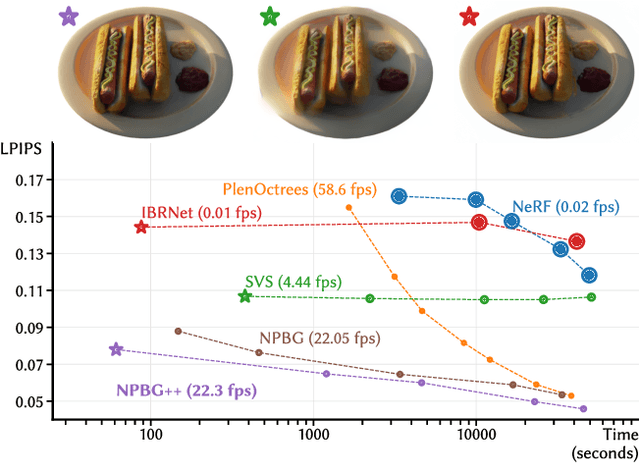
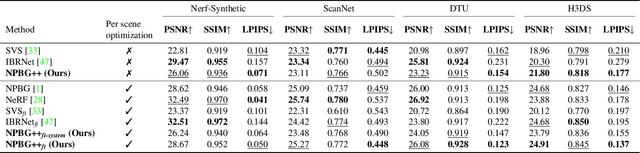
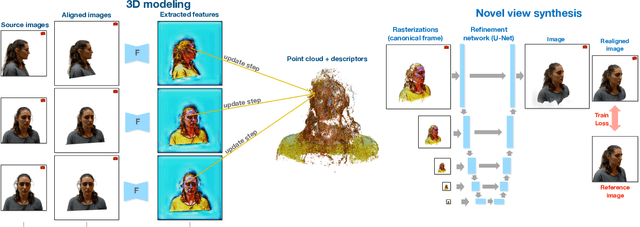
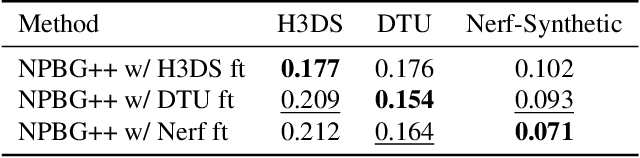
We present a new system (NPBG++) for the novel view synthesis (NVS) task that achieves high rendering realism with low scene fitting time. Our method efficiently leverages the multiview observations and the point cloud of a static scene to predict a neural descriptor for each point, improving upon the pipeline of Neural Point-Based Graphics in several important ways. By predicting the descriptors with a single pass through the source images, we lift the requirement of per-scene optimization while also making the neural descriptors view-dependent and more suitable for scenes with strong non-Lambertian effects. In our comparisons, the proposed system outperforms previous NVS approaches in terms of fitting and rendering runtimes while producing images of similar quality.
Multi-sensor large-scale dataset for multi-view 3D reconstruction
Mar 11, 2022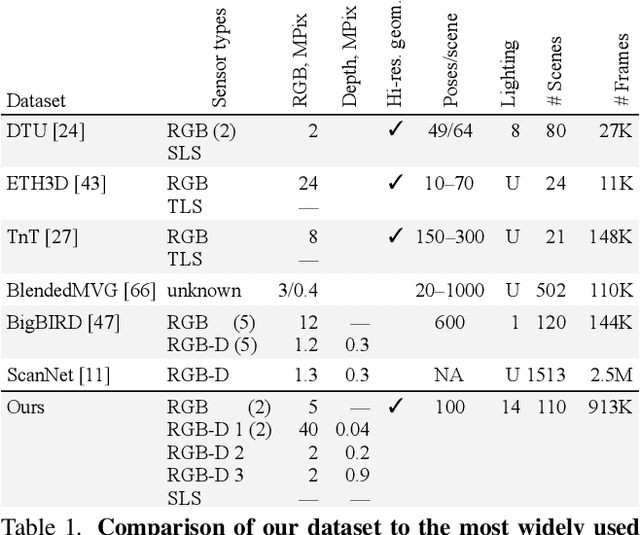
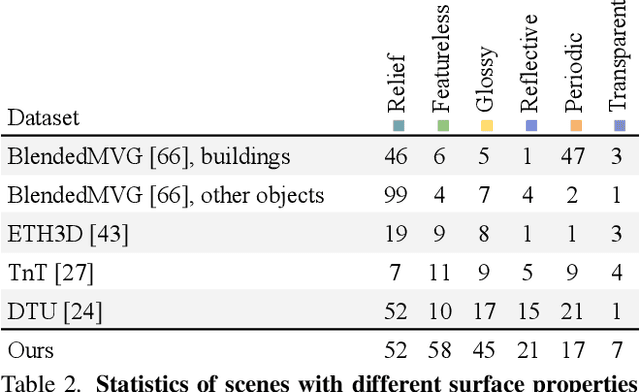

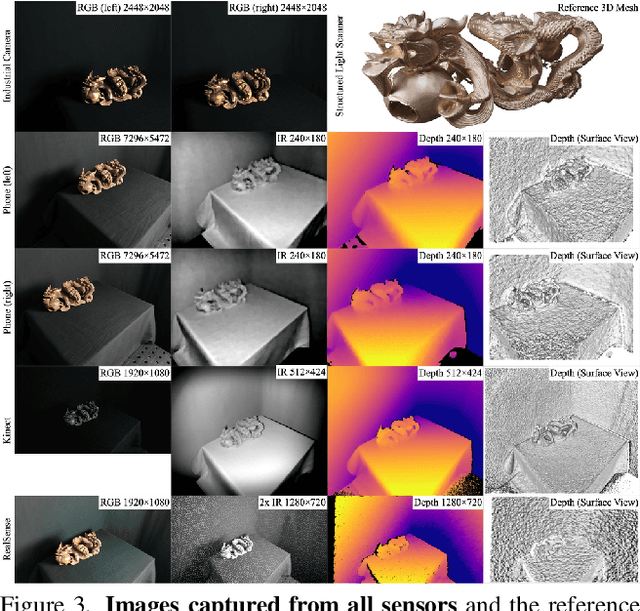
We present a new multi-sensor dataset for 3D surface reconstruction. It includes registered RGB and depth data from sensors of different resolutions and modalities: smartphones, Intel RealSense, Microsoft Kinect, industrial cameras, and structured-light scanner. The data for each scene is obtained under a large number of lighting conditions, and the scenes are selected to emphasize a diverse set of material properties challenging for existing algorithms. In the acquisition process, we aimed to maximize high-resolution depth data quality for challenging cases, to provide reliable ground truth for learning algorithms. Overall, we provide over 1.4 million images of 110 different scenes acquired at 14 lighting conditions from 100 viewing directions. We expect our dataset will be useful for evaluation and training of 3D reconstruction algorithms of different types and for other related tasks. Our dataset and accompanying software will be available online.
Pose Manipulation with Identity Preservation
Apr 20, 2020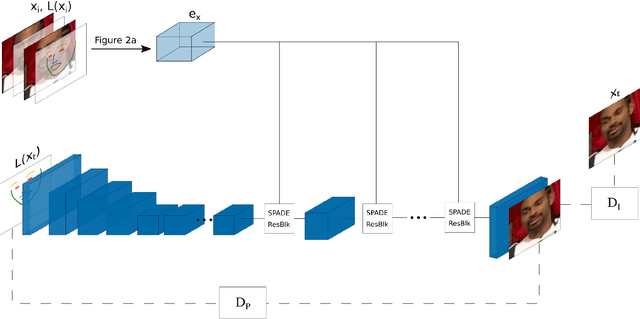
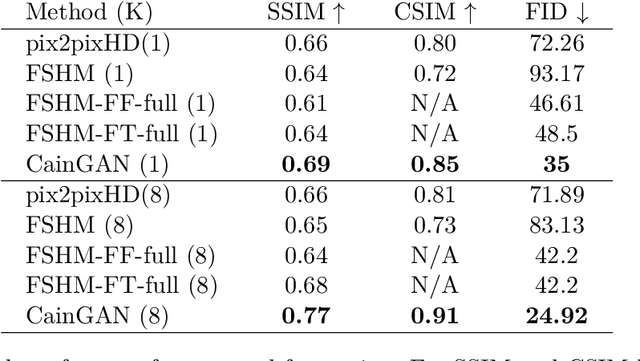
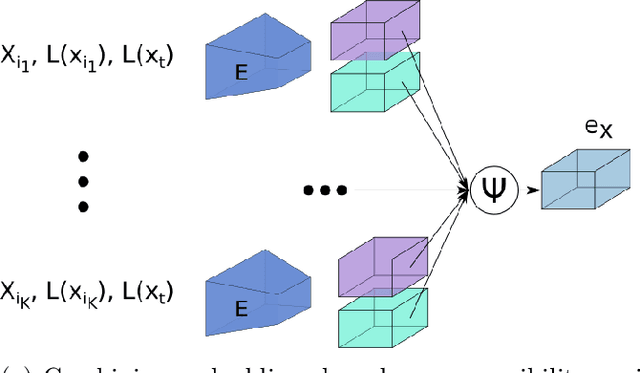
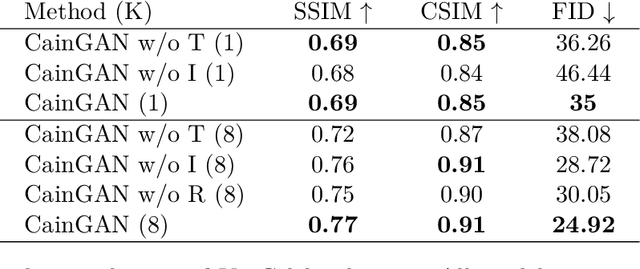
This paper describes a new model which generates images in novel poses e.g. by altering face expression and orientation, from just a few instances of a human subject. Unlike previous approaches which require large datasets of a specific person for training, our approach may start from a scarce set of images, even from a single image. To this end, we introduce Character Adaptive Identity Normalization GAN (CainGAN) which uses spatial characteristic features extracted by an embedder and combined across source images. The identity information is propagated throughout the network by applying conditional normalization. After extensive adversarial training, CainGAN receives figures of faces from a certain individual and produces new ones while preserving the person's identity. Experimental results show that the quality of generated images scales with the size of the input set used during inference. Furthermore, quantitative measurements indicate that CainGAN performs better compared to other methods when training data is limited.
* 9 pages, journal article