 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Maximum Linear Arrangement Problem for trees under projectivity and planarity
Jun 16, 2022
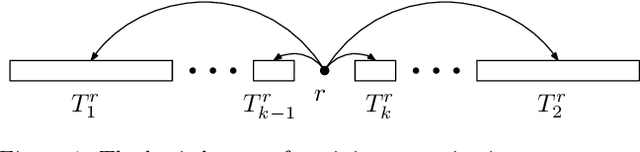
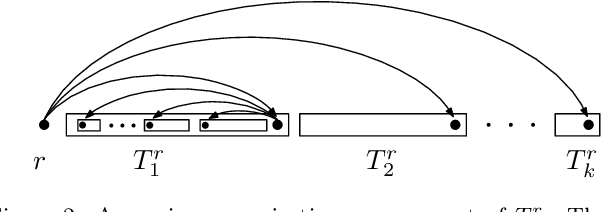
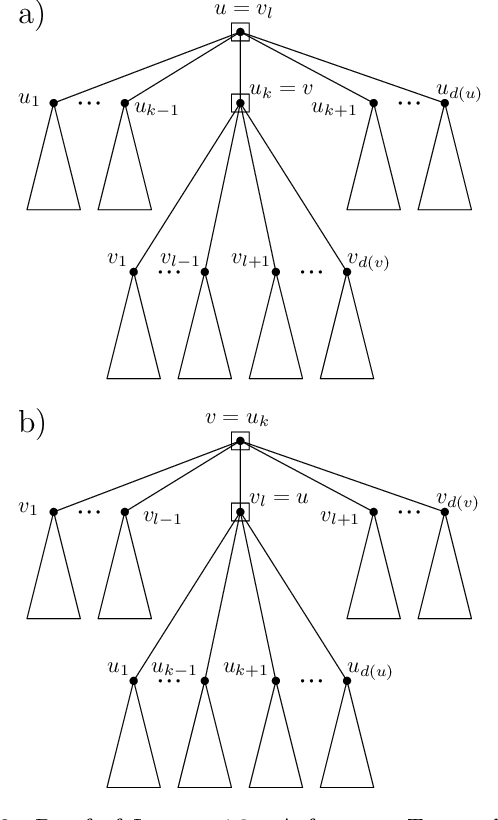
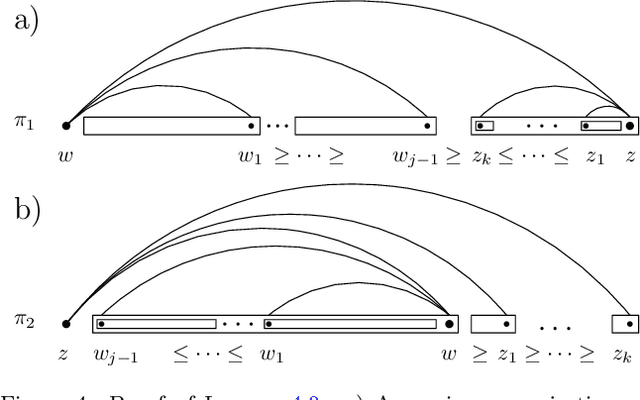
The Maximum Linear Arrangement problem (MaxLA) consists of finding a mapping $\pi$ from the $n$ vertices of a graph $G$ to distinct consecutive integers that maximizes $D_{\pi}(G)=\sum_{uv\in E(G)}|\pi(u) - \pi(v)|$. In this setting, vertices are considered to lie on a horizontal line and edges are drawn as semicircles above the line. There exist variants of MaxLA in which the arrangements are constrained. In the planar variant edge crossings are forbidden. In the projective variant for rooted trees arrangements are planar and the root cannot be covered by any edge. Here we present $O(n)$-time and $O(n)$-space algorithms that solve Planar and Projective MaxLA for trees. We also prove several properties of maximum projective and planar arrangements.
CoBEVT: Cooperative Bird's Eye View Semantic Segmentation with Sparse Transformers
Jul 05, 2022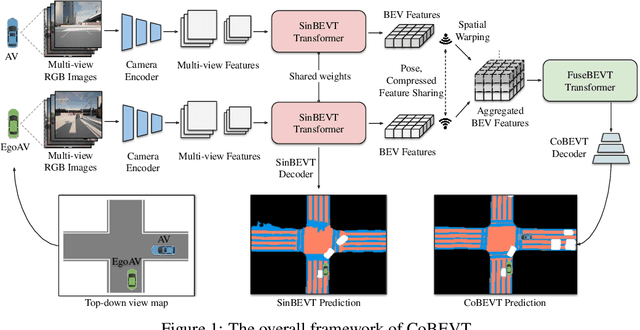

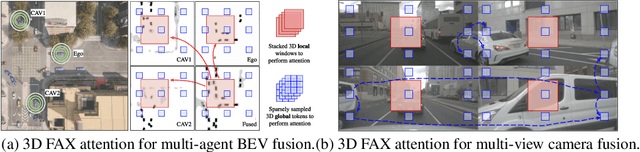
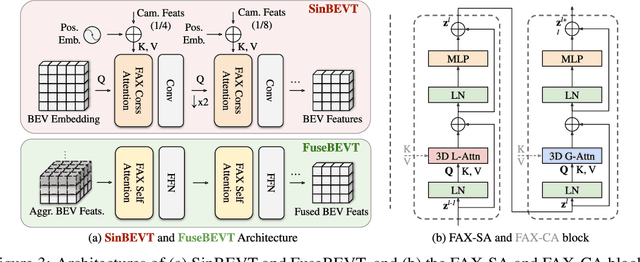
Bird's eye view (BEV) semantic segmentation plays a crucial role in spatial sensing for autonomous driving. Although recent literature has made significant progress on BEV map understanding, they are all based on single-agent camera-based systems which are difficult to handle occlusions and detect distant objects in complex traffic scenes. Vehicle-to-Vehicle (V2V) communication technologies have enabled autonomous vehicles to share sensing information, which can dramatically improve the perception performance and range as compared to single-agent systems. In this paper, we propose CoBEVT, the first generic multi-agent multi-camera perception framework that can cooperatively generate BEV map predictions. To efficiently fuse camera features from multi-view and multi-agent data in an underlying Transformer architecture, we design a fused axial attention or FAX module, which can capture sparsely local and global spatial interactions across views and agents. The extensive experiments on the V2V perception dataset, OPV2V, demonstrate that CoBEVT achieves state-of-the-art performance for cooperative BEV semantic segmentation. Moreover, CoBEVT is shown to be generalizable to other tasks, including 1) BEV segmentation with single-agent multi-camera and 2) 3D object detection with multi-agent LiDAR systems, and achieves state-of-the-art performance with real-time inference speed.
Real-time Scene Text Detection Based on Global Level and Word Level Features
Mar 10, 2022
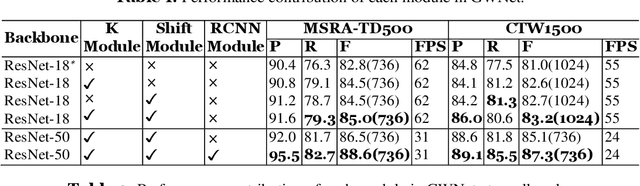

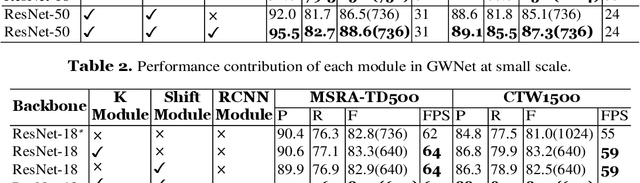
It is an extremely challenging task to detect arbitrary shape text in natural scenes on high accuracy and efficiency. In this paper, we propose a scene text detection framework, namely GWNet, which mainly includes two modules: Global module and RCNN module. Specifically, Global module improves the adaptive performance of the DB (Differentiable Binarization) module by adding k submodule and shift submodule. Two submodules enhance the adaptability of amplifying factor k, accelerate the convergence of models and help to produce more accurate detection results. RCNN module fuses global-level and word-level features. The word-level label is generated by obtaining the minimum axis-aligned rectangle boxes of the shrunk polygon. In the inference period, GWNet only uses global-level features to output simple polygon detections. Experiments on four benchmark datasets, including the MSRA-TD500, Total-Text, ICDAR2015 and CTW-1500, demonstrate that our GWNet outperforms the state-of-the-art detectors. Specifically, with a backbone of ResNet-50, we achieve an F-measure of 88.6% on MSRA- TD500, 87.9% on Total-Text, 89.2% on ICDAR2015 and 87.5% on CTW-1500.
Visual Time Series Forecasting: An Image-driven Approach
Jul 02, 2021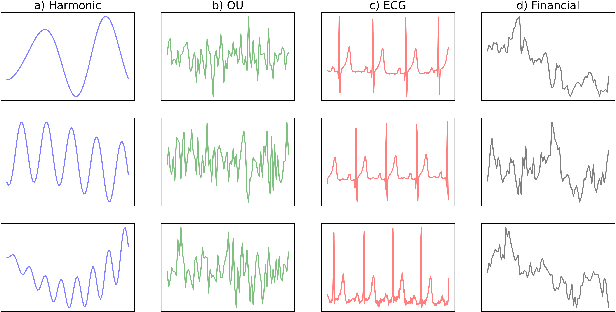
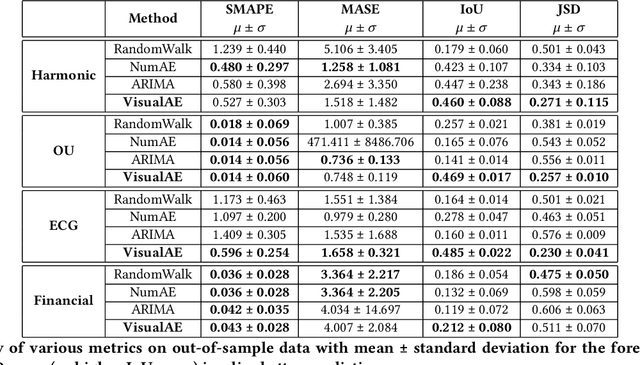
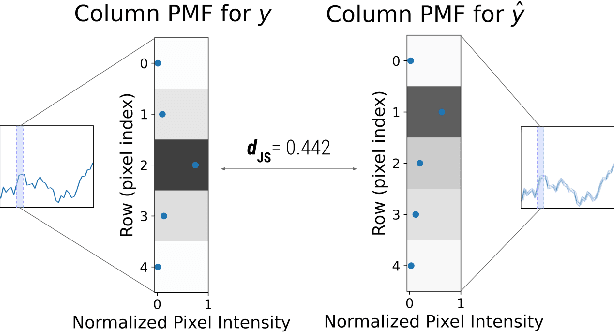
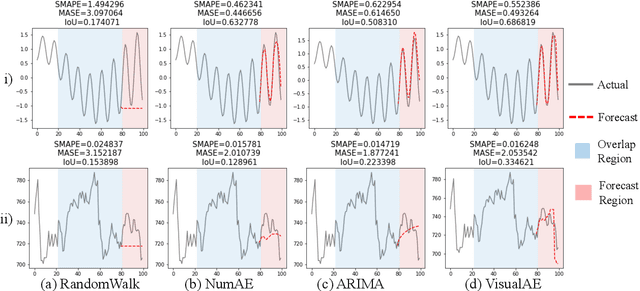
In this work, we address time-series forecasting as a computer vision task. We capture input data as an image and train a model to produce the subsequent image. This approach results in predicting distributions as opposed to pointwise values. To assess the robustness and quality of our approach, we examine various datasets and multiple evaluation metrics. Our experiments show that our forecasting tool is effective for cyclic data but somewhat less for irregular data such as stock prices. Importantly, when using image-based evaluation metrics, we find our method to outperform various baselines, including ARIMA, and a numerical variation of our deep learning approach.
Adapting to Online Label Shift with Provable Guarantees
Jul 05, 2022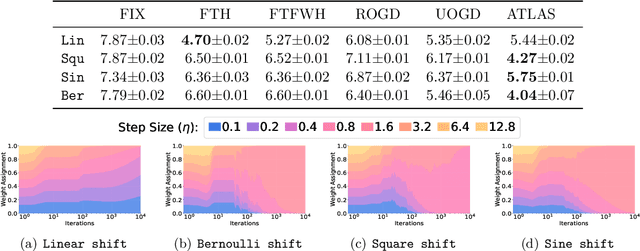
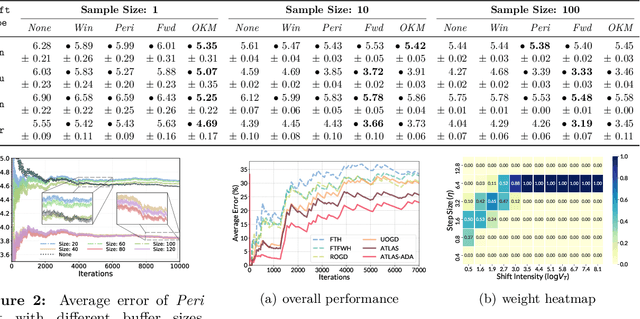
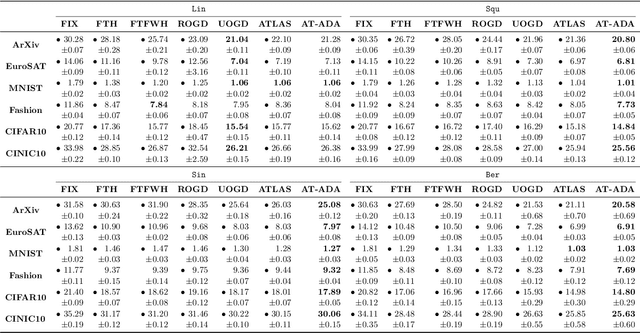
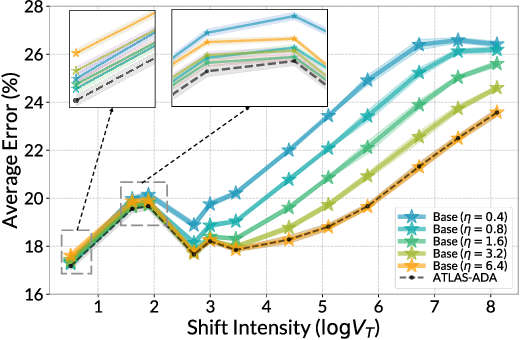
The standard supervised learning paradigm works effectively when training data shares the same distribution as the upcoming testing samples. However, this assumption is often violated in real-world applications, especially when testing data appear in an online fashion. In this paper, we formulate and investigate the problem of online label shift (OLaS): the learner trains an initial model from the labeled offline data and then deploys it to an unlabeled online environment where the underlying label distribution changes over time but the label-conditional density does not. The non-stationarity nature and the lack of supervision make the problem challenging to be tackled. To address the difficulty, we construct a new unbiased risk estimator that utilizes the unlabeled data, which exhibits many benign properties albeit with potential non-convexity. Building upon that, we propose novel online ensemble algorithms to deal with the non-stationarity of the environments. Our approach enjoys optimal dynamic regret, indicating that the performance is competitive with a clairvoyant who knows the online environments in hindsight and then chooses the best decision for each round. The obtained dynamic regret bound scales with the intensity and pattern of label distribution shift, hence exhibiting the adaptivity in the OLaS problem. Extensive experiments are conducted to validate the effectiveness and support our theoretical findings.
Long-Tail Prediction Uncertainty Aware Trajectory Planning for Self-driving Vehicles
Jul 02, 2022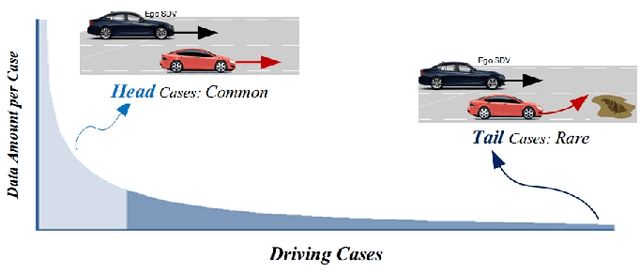
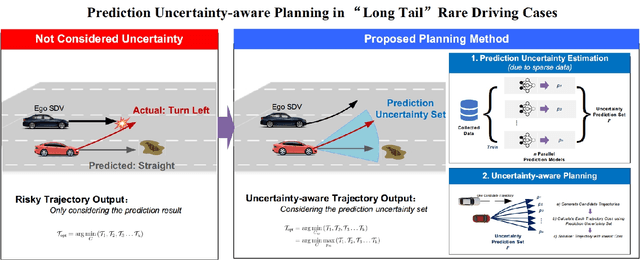
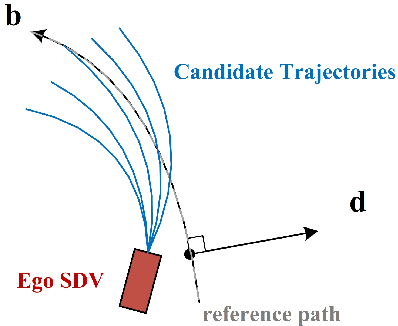
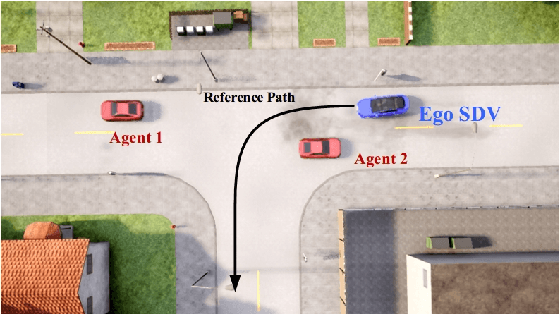
A typical trajectory planner of autonomous driving usually relies on predicting the future behavior of surrounding obstacles. In recent years, prediction models based on deep learning have been widely used due to their impressive performance. However, recent studies have shown that deep learning models trained on a dataset following a long-tailed driving scenario distribution will suffer from large prediction errors in the "tails," which might lead to failures of the planner. To this end, this work defines a notion of prediction model uncertainty to quantify high errors due to sparse data. Moreover, this work proposes a trajectory planner to consider such prediction uncertainty for safer performance. Firstly, the prediction model's uncertainty due to insufficient training data is estimated by an ensemble network structure. Then a trajectory planner is designed to consider the worst-case arising from prediction uncertainty. The results show that the proposed method can improve the safety of trajectory planning under the prediction uncertainty caused by insufficient data. At the same time, with sufficient data, the framework will not lead to overly conservative results. This technology helps to improve the safety and reliability of autonomous vehicles under the long-tail data distribution of the real world.
CASHformer: Cognition Aware SHape Transformer for Longitudinal Analysis
Jul 05, 2022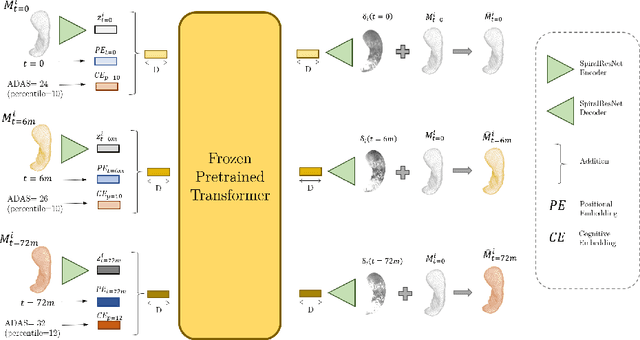
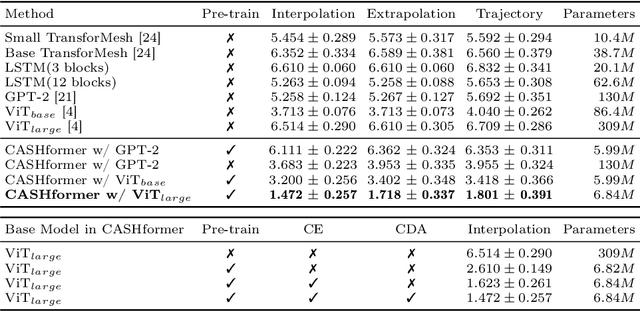
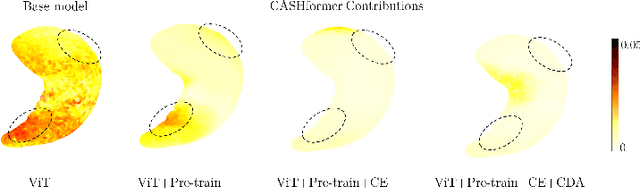
Modeling temporal changes in subcortical structures is crucial for a better understanding of the progression of Alzheimer's disease (AD). Given their flexibility to adapt to heterogeneous sequence lengths, mesh-based transformer architectures have been proposed in the past for predicting hippocampus deformations across time. However, one of the main limitations of transformers is the large amount of trainable parameters, which makes the application on small datasets very challenging. In addition, current methods do not include relevant non-image information that can help to identify AD-related patterns in the progression. To this end, we introduce CASHformer, a transformer-based framework to model longitudinal shape trajectories in AD. CASHformer incorporates the idea of pre-trained transformers as universal compute engines that generalize across a wide range of tasks by freezing most layers during fine-tuning. This reduces the number of parameters by over 90% with respect to the original model and therefore enables the application of large models on small datasets without overfitting. In addition, CASHformer models cognitive decline to reveal AD atrophy patterns in the temporal sequence. Our results show that CASHformer reduces the reconstruction error by 73% compared to previously proposed methods. Moreover, the accuracy of detecting patients progressing to AD increases by 3% with imputing missing longitudinal shape data.
Learning in games from a stochastic approximation viewpoint
Jun 08, 2022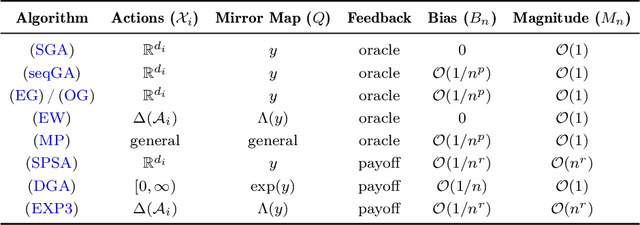
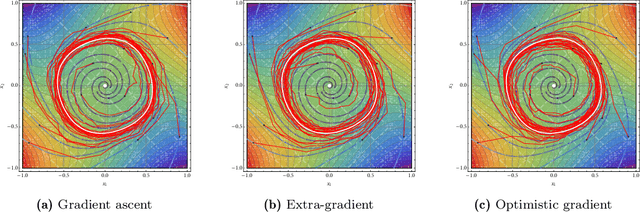
We develop a unified stochastic approximation framework for analyzing the long-run behavior of multi-agent online learning in games. Our framework is based on a "primal-dual", mirrored Robbins-Monro (MRM) template which encompasses a wide array of popular game-theoretic learning algorithms (gradient methods, their optimistic variants, the EXP3 algorithm for learning with payoff-based feedback in finite games, etc.). In addition to providing an integrated view of these algorithms, the proposed MRM blueprint allows us to obtain a broad range of new convergence results, both asymptotic and in finite time, in both continuous and finite games.
Disentangling private classes through regularization
Jul 05, 2022
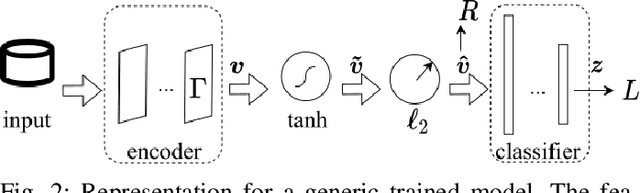
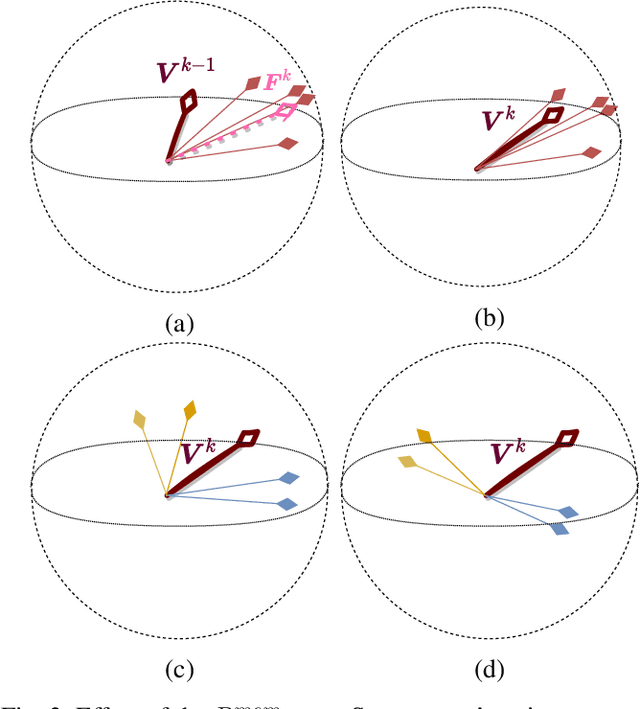
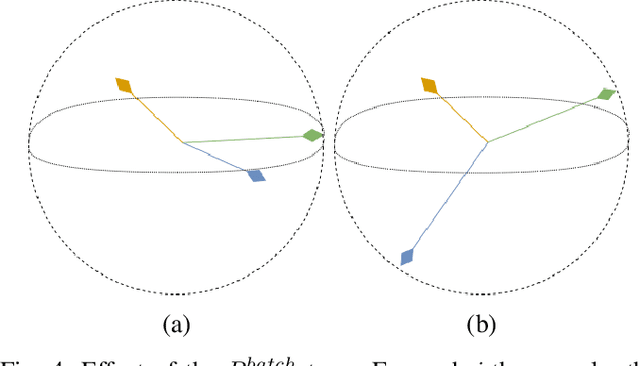
Deep learning models are nowadays broadly deployed to solve an incredibly large variety of tasks. However, little attention has been devoted to connected legal aspects. In 2016, the European Union approved the General Data Protection Regulation which entered into force in 2018. Its main rationale was to protect the privacy and data protection of its citizens by the way of operating of the so-called "Data Economy". As data is the fuel of modern Artificial Intelligence, it is argued that the GDPR can be partly applicable to a series of algorithmic decision making tasks before a more structured AI Regulation enters into force. In the meantime, AI should not allow undesired information leakage deviating from the purpose for which is created. In this work we propose DisP, an approach for deep learning models disentangling the information related to some classes we desire to keep private, from the data processed by AI. In particular, DisP is a regularization strategy de-correlating the features belonging to the same private class at training time, hiding the information of private classes membership. Our experiments on state-of-the-art deep learning models show the effectiveness of DisP, minimizing the risk of extraction for the classes we desire to keep private.
OPerA: Object-Centric Performance Analysis
Apr 22, 2022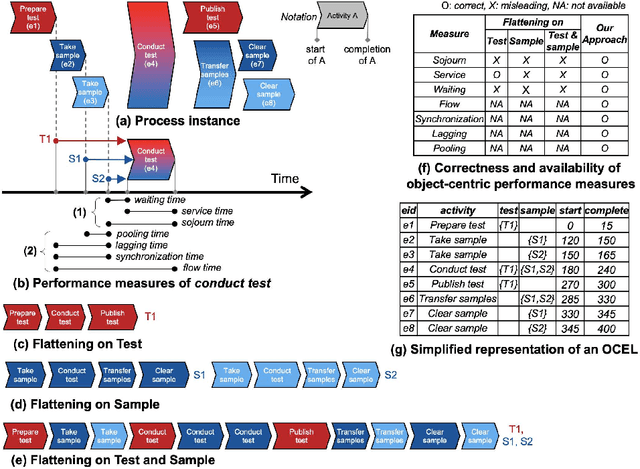
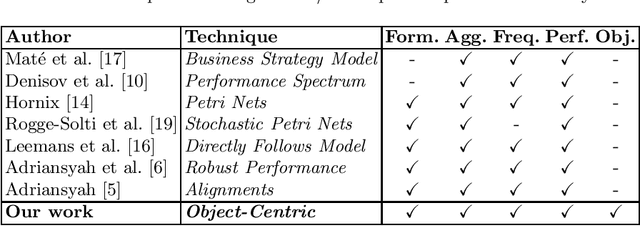
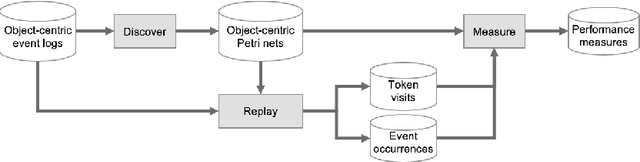
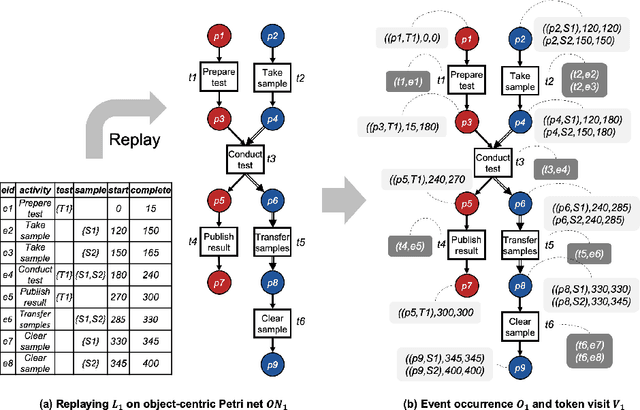
Performance analysis in process mining aims to provide insights on the performance of a business process by using a process model as a formal representation of the process. Such insights are reliably interpreted by process analysts in the context of a model with formal semantics. Existing techniques for performance analysis assume that a single case notion exists in a business process (e.g., a patient in healthcare process). However, in reality, different objects might interact (e.g., order, item, delivery, and invoice in an O2C process). In such a setting, traditional techniques may yield misleading or even incorrect insights on performance metrics such as waiting time. More importantly, by considering the interaction between objects, we can define object-centric performance metrics such as synchronization time, pooling time, and lagging time. In this work, we propose a novel approach to performance analysis considering multiple case notions by using object-centric Petri nets as formal representations of business processes. The proposed approach correctly computes existing performance metrics, while supporting the derivation of newly-introduced object-centric performance metrics. We have implemented the approach as a web application and conducted a case study based on a real-life loan application process.