 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multinomial Logistic Bandit via Frequent Directions
Jun 10, 2026This paper studies efficient online algorithms for multinomial logistic bandits (MLogB), where the feedback distribution over $K+1$ outcomes follows a multinomial logistic model of $d$-dimensional action vectors. A representative UCB-type algorithm, OFUL-MLogB, achieves a regret bound of $\tilde{\mathcal{O}}(Kd\sqrt{T})$, but still requires $\mathcal{O}(K^3d^3)$ time and $\mathcal{O}(K^2d^2)$ space per round due to parameter estimation and optimistic reward construction, which is prohibitive in high-dimensional settings. To address this limitation, we propose EOFD-MLogB, which integrates frequent directions matrix sketching into OFUL-MLogB. By maintaining a low-rank SVD sketch of the accumulated Hessian, constrained online Newton updates in parameter estimation and $Kd \times K$ spectral-norm computations in the reward bonus are reduced to one-dimensional root-finding tasks and $K \times K$ eigenvalue computations, respectively. This yields dominant per-round time complexity $\mathcal{O}(Kd(m+K)^2)$ and space complexity $\mathcal{O}(Kd(m+K))$, where $m \ll d$ is the sketch size. We further prove a regret bound of $\tilde{\mathcal{O}}(Δ_T(Kd\lnΔ_T+m)\sqrt{T})$, where the sketching error factor $Δ_T$ is controlled by the $m$-truncated spectral tail of the Hessian. Thus, when the Hessian is approximately low-rank, the regret is close to that of OFUL-MLogB. Experiments validate the computational efficiency and competitive performance.
Near-Optimal Regret in Adversarial Kernel Bandits
May 26, 2026We study the adversarial kernel bandit problem, in which the loss at each round is induced by an arbitrary bounded element of a reproducing kernel Hilbert space (RKHS). We propose an exponential-weights algorithm built on a regularized importance-weighted loss estimator, together with an explicit correction term that cancels the bias introduced by the regularization. Our main result bounds the regret by $\widetilde{O}\big(\sqrt{T\, d_*(λ)\,\log|{X}|}\big)$, where $d_*(λ)$ is a widely-adopted notion of effective dimension that captures the complexity of the kernel. Up to logarithmic factors, this matches the known rate achieved in the related stochastic kernel bandit problem. A notable application is the Matérn$(ν,d)$ kernel with smoothness parameter $ν$ on $\mathbb{R}^d$, for which our bound specializes to $\widetilde{O}\big(T^{(ν+d)/(2ν+d)}\big)$, improving over the best-known prior rate of Chatterji et al. [2019] while simultaneously removing the rank-one adversary assumption required by their analysis. Moreover, this rate is the same as the known optimal rate for stochastic kernel bandits, and also matches a lower bound from concurrent work up to a $\log T$ factor.
Dynamic Regret via Discounted-to-Dynamic Reduction with Applications to Curved Losses and Adam Optimizer
Feb 09, 2026We study dynamic regret minimization in non-stationary online learning, with a primary focus on follow-the-regularized-leader (FTRL) methods. FTRL is important for curved losses and for understanding adaptive optimizers such as Adam, yet existing dynamic regret analyses are less explored for FTRL. To address this, we build on the discounted-to-dynamic reduction and present a modular way to obtain dynamic regret bounds of FTRL-related problems. Specifically, we focus on two representative curved losses: linear regression and logistic regression. Our method not only simplifies existing proofs for the optimal dynamic regret of online linear regression, but also yields new dynamic regret guarantees for online logistic regression. Beyond online convex optimization, we apply the reduction to analyze the Adam optimizers, obtaining optimal convergence rates in stochastic, non-convex, and non-smooth settings. The reduction also enables a more detailed treatment of Adam with two discount parameters $(β_1,β_2)$, leading to new results for both clipped and clip-free variants of Adam optimizers.
Generalized Linear Bandits: Almost Optimal Regret with One-Pass Update
Jul 16, 2025We study the generalized linear bandit (GLB) problem, a contextual multi-armed bandit framework that extends the classical linear model by incorporating a non-linear link function, thereby modeling a broad class of reward distributions such as Bernoulli and Poisson. While GLBs are widely applicable to real-world scenarios, their non-linear nature introduces significant challenges in achieving both computational and statistical efficiency. Existing methods typically trade off between two objectives, either incurring high per-round costs for optimal regret guarantees or compromising statistical efficiency to enable constant-time updates. In this paper, we propose a jointly efficient algorithm that attains a nearly optimal regret bound with $\mathcal{O}(1)$ time and space complexities per round. The core of our method is a tight confidence set for the online mirror descent (OMD) estimator, which is derived through a novel analysis that leverages the notion of mix loss from online prediction. The analysis shows that our OMD estimator, even with its one-pass updates, achieves statistical efficiency comparable to maximum likelihood estimation, thereby leading to a jointly efficient optimistic method.
Non-stationary Online Learning for Curved Losses: Improved Dynamic Regret via Mixability
Jun 12, 2025Non-stationary online learning has drawn much attention in recent years. Despite considerable progress, dynamic regret minimization has primarily focused on convex functions, leaving the functions with stronger curvature (e.g., squared or logistic loss) underexplored. In this work, we address this gap by showing that the regret can be substantially improved by leveraging the concept of mixability, a property that generalizes exp-concavity to effectively capture loss curvature. Let $d$ denote the dimensionality and $P_T$ the path length of comparators that reflects the environmental non-stationarity. We demonstrate that an exponential-weight method with fixed-share updates achieves an $\mathcal{O}(d T^{1/3} P_T^{2/3} \log T)$ dynamic regret for mixable losses, improving upon the best-known $\mathcal{O}(d^{10/3} T^{1/3} P_T^{2/3} \log T)$ result (Baby and Wang, 2021) in $d$. More importantly, this improvement arises from a simple yet powerful analytical framework that exploits the mixability, which avoids the Karush-Kuhn-Tucker-based analysis required by existing work.
On Symmetric Losses for Robust Policy Optimization with Noisy Preferences
May 30, 2025Optimizing policies based on human preferences is key to aligning language models with human intent. This work focuses on reward modeling, a core component in reinforcement learning from human feedback (RLHF), and offline preference optimization, such as direct preference optimization. Conventional approaches typically assume accurate annotations. However, real-world preference data often contains noise due to human errors or biases. We propose a principled framework for robust policy optimization under noisy preferences, viewing reward modeling as a classification problem. This allows us to leverage symmetric losses, known for their robustness to label noise in classification, leading to our Symmetric Preference Optimization (SymPO) method. We prove that symmetric losses enable successful policy optimization even under noisy labels, as the resulting reward remains rank-preserving -- a property sufficient for policy improvement. Experiments on synthetic and real-world tasks demonstrate the effectiveness of SymPO.
Learning with Complementary Labels Revisited: A Consistent Approach via Negative-Unlabeled Learning
Nov 27, 2023Complementary-label learning is a weakly supervised learning problem in which each training example is associated with one or multiple complementary labels indicating the classes to which it does not belong. Existing consistent approaches have relied on the uniform distribution assumption to model the generation of complementary labels, or on an ordinary-label training set to estimate the transition matrix. However, both conditions may not be satisfied in real-world scenarios. In this paper, we propose a novel complementary-label learning approach that does not rely on these conditions. We find that complementary-label learning can be expressed as a set of negative-unlabeled binary classification problems when using the one-versus-rest strategy. This observation allows us to propose a risk-consistent approach with theoretical guarantees. Furthermore, we introduce a risk correction approach to address overfitting problems when using complex models. We also prove the statistical consistency and convergence rate of the corrected risk estimator. Extensive experimental results on both synthetic and real-world benchmark datasets validate the superiority of our proposed approach over state-of-the-art methods.
Adapting to Continuous Covariate Shift via Online Density Ratio Estimation
Feb 06, 2023



Dealing with distribution shifts is one of the central challenges for modern machine learning. One fundamental situation is the \emph{covariate shift}, where the input distributions of data change from training to testing stages while the input-conditional output distribution remains unchanged. In this paper, we initiate the study of a more challenging scenario -- \emph{continuous} covariate shift -- in which the test data appear sequentially, and their distributions can shift continuously. Our goal is to adaptively train the predictor such that its prediction risk accumulated over time can be minimized. Starting with the importance-weighted learning, we show the method works effectively if the time-varying density ratios of test and train inputs can be accurately estimated. However, existing density ratio estimation methods would fail due to data scarcity at each time step. To this end, we propose an online method that can appropriately reuse historical information. Our density ratio estimation method is proven to perform well by enjoying a dynamic regret bound, which finally leads to an excess risk guarantee for the predictor. Empirical results also validate the effectiveness.
Adapting to Online Label Shift with Provable Guarantees
Jul 05, 2022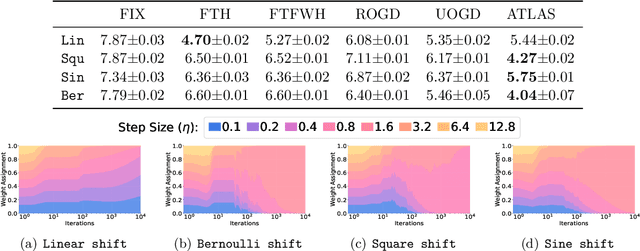
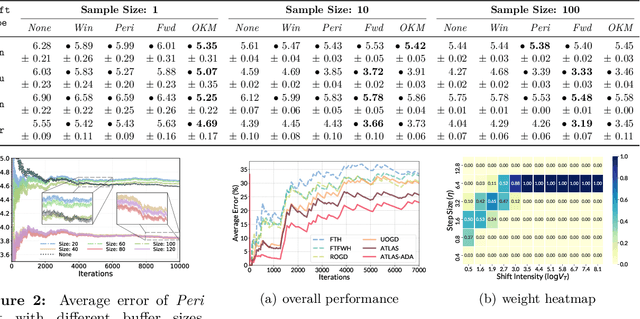
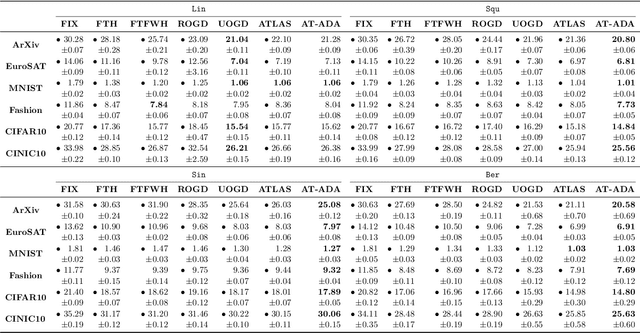
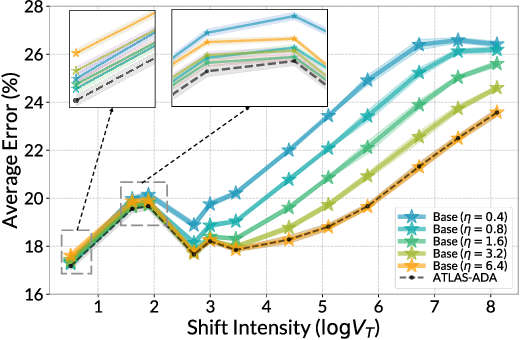
The standard supervised learning paradigm works effectively when training data shares the same distribution as the upcoming testing samples. However, this assumption is often violated in real-world applications, especially when testing data appear in an online fashion. In this paper, we formulate and investigate the problem of online label shift (OLaS): the learner trains an initial model from the labeled offline data and then deploys it to an unlabeled online environment where the underlying label distribution changes over time but the label-conditional density does not. The non-stationarity nature and the lack of supervision make the problem challenging to be tackled. To address the difficulty, we construct a new unbiased risk estimator that utilizes the unlabeled data, which exhibits many benign properties albeit with potential non-convexity. Building upon that, we propose novel online ensemble algorithms to deal with the non-stationarity of the environments. Our approach enjoys optimal dynamic regret, indicating that the performance is competitive with a clairvoyant who knows the online environments in hindsight and then chooses the best decision for each round. The obtained dynamic regret bound scales with the intensity and pattern of label distribution shift, hence exhibiting the adaptivity in the OLaS problem. Extensive experiments are conducted to validate the effectiveness and support our theoretical findings.
Adaptivity and Non-stationarity: Problem-dependent Dynamic Regret for Online Convex Optimization
Dec 29, 2021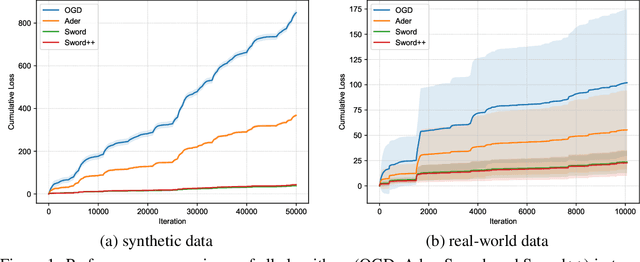
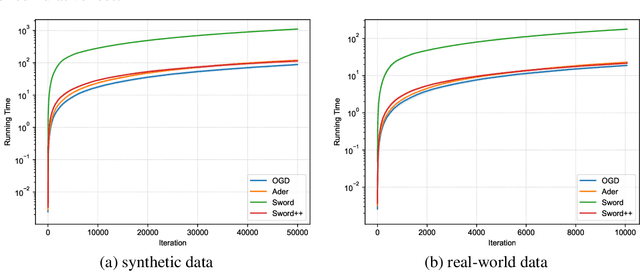
We investigate online convex optimization in non-stationary environments and choose the \emph{dynamic regret} as the performance measure, defined as the difference between cumulative loss incurred by the online algorithm and that of any feasible comparator sequence. Let $T$ be the time horizon and $P_T$ be the path-length that essentially reflects the non-stationarity of environments, the state-of-the-art dynamic regret is $\mathcal{O}(\sqrt{T(1+P_T)})$. Although this bound is proved to be minimax optimal for convex functions, in this paper, we demonstrate that it is possible to further enhance the guarantee for some easy problem instances, particularly when online functions are smooth. Specifically, we propose novel online algorithms that can leverage smoothness and replace the dependence on $T$ in the dynamic regret by \emph{problem-dependent} quantities: the variation in gradients of loss functions, the cumulative loss of the comparator sequence, and the minimum of the previous two terms. These quantities are at most $\mathcal{O}(T)$ while could be much smaller in benign environments. Therefore, our results are adaptive to the intrinsic difficulty of the problem, since the bounds are tighter than existing results for easy problems and meanwhile guarantee the same rate in the worst case. Notably, our algorithm requires only \emph{one} gradient per iteration, which shares the same gradient query complexity with the methods developed for optimizing the static regret. As a further application, we extend the results from the full-information setting to bandit convex optimization with two-point feedback and thereby attain the first problem-dependent dynamic regret for such bandit tasks.