 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sparsifying Binary Networks
Jul 11, 2022




Binary neural networks (BNNs) have demonstrated their ability to solve complex tasks with comparable accuracy as full-precision deep neural networks (DNNs), while also reducing computational power and storage requirements and increasing the processing speed. These properties make them an attractive alternative for the development and deployment of DNN-based applications in Internet-of-Things (IoT) devices. Despite the recent improvements, they suffer from a fixed and limited compression factor that may result insufficient for certain devices with very limited resources. In this work, we propose sparse binary neural networks (SBNNs), a novel model and training scheme which introduces sparsity in BNNs and a new quantization function for binarizing the network's weights. The proposed SBNN is able to achieve high compression factors and it reduces the number of operations and parameters at inference time. We also provide tools to assist the SBNN design, while respecting hardware resource constraints. We study the generalization properties of our method for different compression factors through a set of experiments on linear and convolutional networks on three datasets. Our experiments confirm that SBNNs can achieve high compression rates, without compromising generalization, while further reducing the operations of BNNs, making SBNNs a viable option for deploying DNNs in cheap, low-cost, limited-resources IoT devices and sensors.
Horizontal Federated Learning and Secure Distributed Training for Recommendation System with Intel SGX
Jul 11, 2022
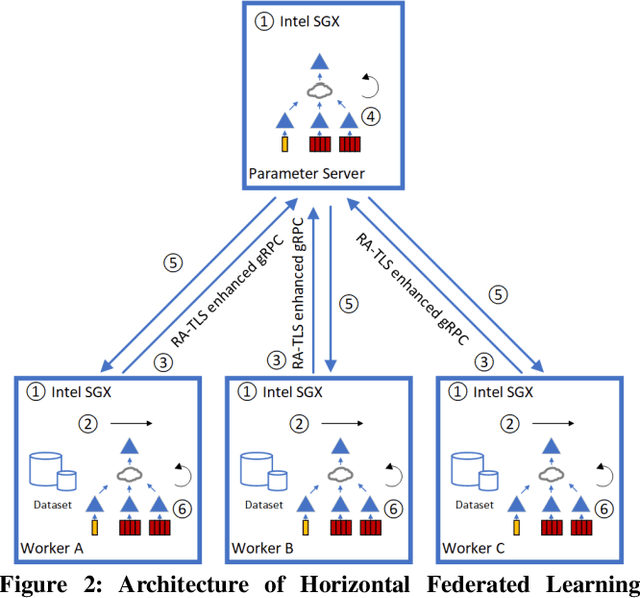
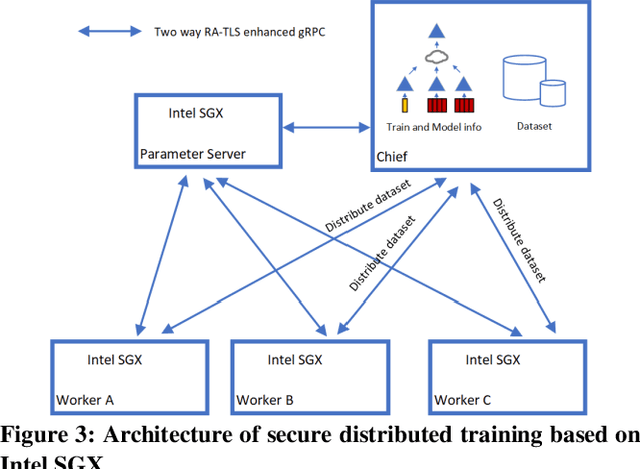
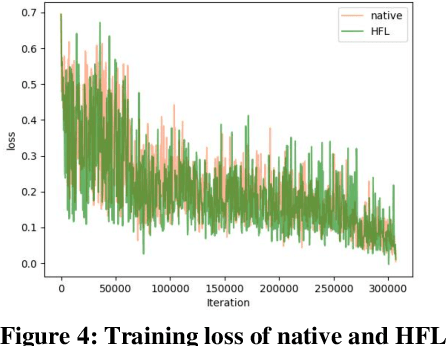
With the advent of big data era and the development of artificial intelligence and other technologies, data security and privacy protection have become more important. Recommendation systems have many applications in our society, but the model construction of recommendation systems is often inseparable from users' data. Especially for deep learning-based recommendation systems, due to the complexity of the model and the characteristics of deep learning itself, its training process not only requires long training time and abundant computational resources but also needs to use a large amount of user data, which poses a considerable challenge in terms of data security and privacy protection. How to train a distributed recommendation system while ensuring data security has become an urgent problem to be solved. In this paper, we implement two schemes, Horizontal Federated Learning and Secure Distributed Training, based on Intel SGX(Software Guard Extensions), an implementation of a trusted execution environment, and TensorFlow framework, to achieve secure, distributed recommendation system-based learning schemes in different scenarios. We experiment on the classical Deep Learning Recommendation Model (DLRM), which is a neural network-based machine learning model designed for personalization and recommendation, and the results show that our implementation introduces approximately no loss in model performance. The training speed is within acceptable limits.
Comprehensive Reactive Safety: No Need For A Trajectory If You Have A Strategy
Jul 01, 2022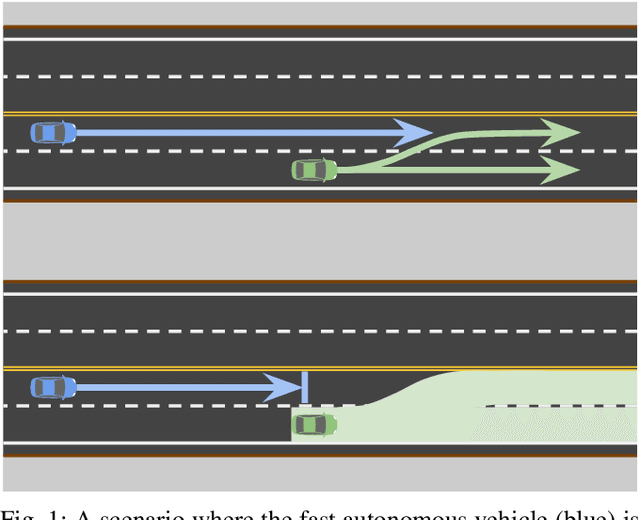
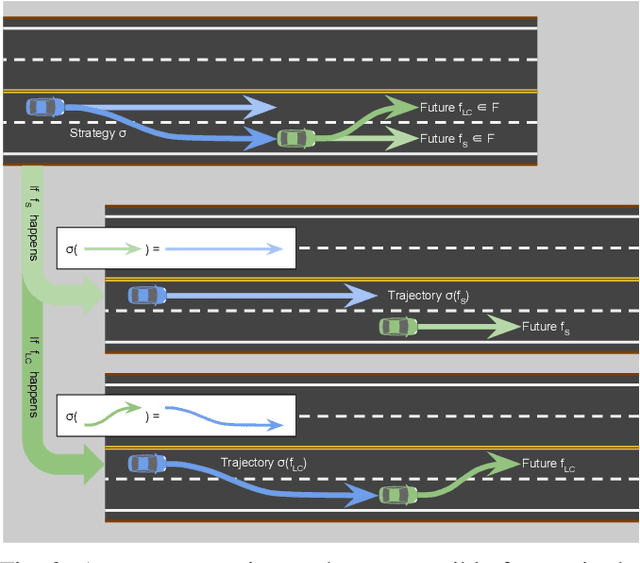
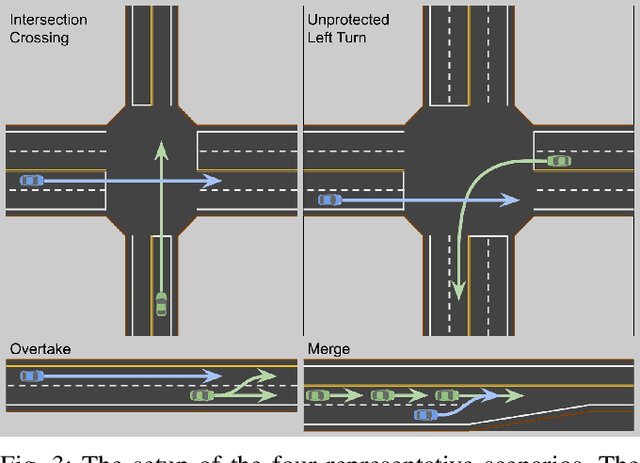

Safety guarantees in motion planning for autonomous driving typically involve certifying the trajectory to be collision-free under any motion of the uncontrollable participants in the environment, such as the human-driven vehicles on the road. As a result they usually employ a conservative bound on the behavior of such participants, such as reachability analysis. We point out that planning trajectories to rigorously avoid the entirety of the reachable regions is unnecessary and too restrictive, because observing the environment in the future will allow us to prune away most of them; disregarding this ability to react to future updates could prohibit solutions to scenarios that are easily navigated by human drivers. We propose to account for the autonomous vehicle's reactions to future environment changes by a novel safety framework, Comprehensive Reactive Safety. Validated in simulations in several urban driving scenarios such as unprotected left turns and lane merging, the resulting planning algorithm called Reactive ILQR demonstrates strong negotiation capabilities and better safety at the same time.
Transcormer: Transformer for Sentence Scoring with Sliding Language Modeling
Jun 05, 2022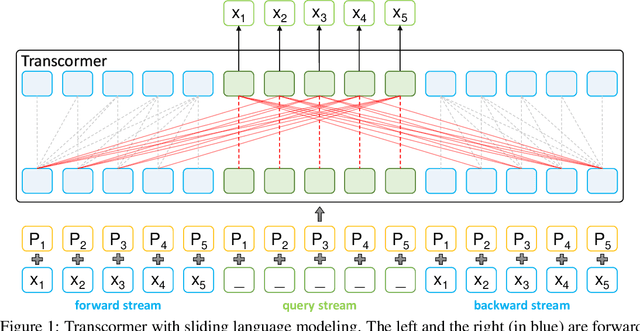

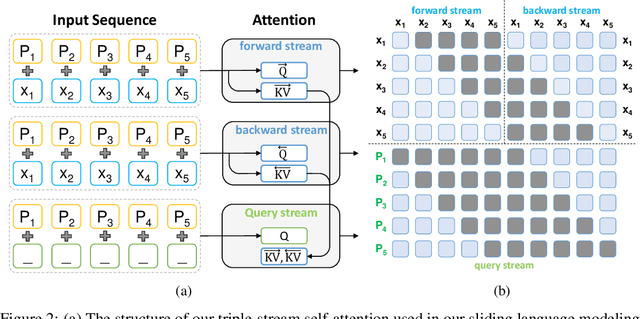
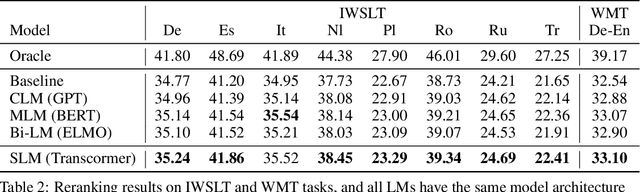
Sentence scoring aims at measuring the likelihood score of a sentence and is widely used in many natural language processing scenarios, like reranking, which is to select the best sentence from multiple candidates. Previous works on sentence scoring mainly adopted either causal language modeling (CLM) like GPT or masked language modeling (MLM) like BERT, which have some limitations: 1) CLM only utilizes unidirectional information for the probability estimation of a sentence without considering bidirectional context, which affects the scoring quality; 2) MLM can only estimate the probability of partial tokens at a time and thus requires multiple forward passes to estimate the probability of the whole sentence, which incurs large computation and time cost. In this paper, we propose \textit{Transcormer} -- a Transformer model with a novel \textit{sliding language modeling} (SLM) for sentence scoring. Specifically, our SLM adopts a triple-stream self-attention mechanism to estimate the probability of all tokens in a sentence with bidirectional context and only requires a single forward pass. SLM can avoid the limitations of CLM (only unidirectional context) and MLM (multiple forward passes) and inherit their advantages, and thus achieve high effectiveness and efficiency in scoring. Experimental results on multiple tasks demonstrate that our method achieves better performance than other language modelings.
It's a super deal -- train recurrent network on noisy data and get smooth prediction free
Jun 09, 2022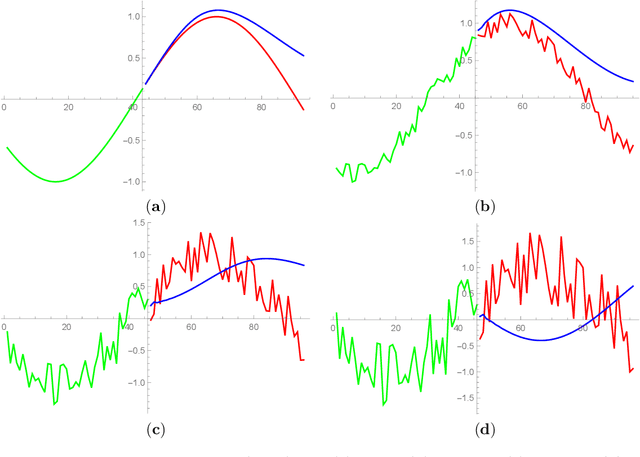
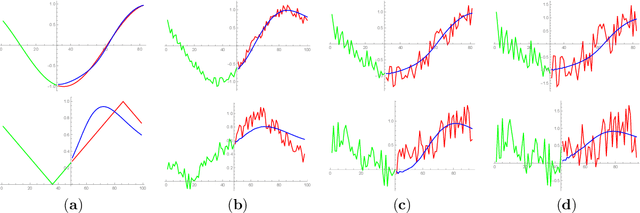
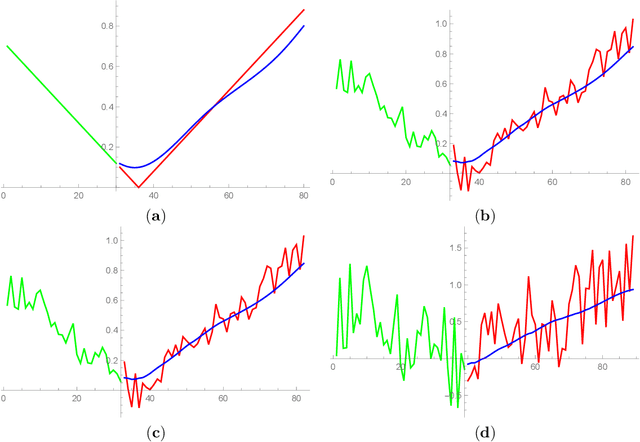
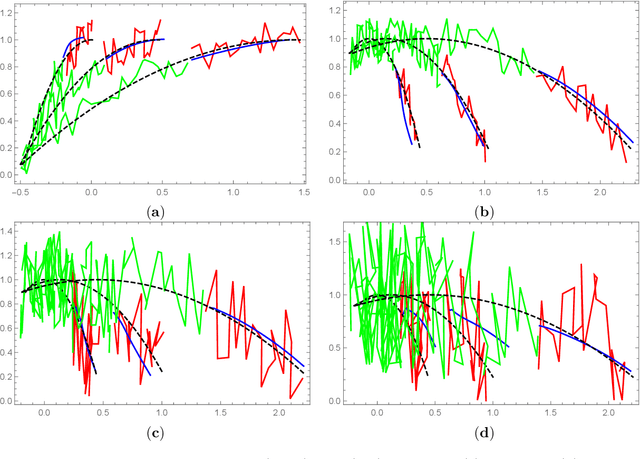
Recent research demonstrate that prediction of time series by predictive recurrent neural networks based on the noisy input generates a {\it smooth} anticipated trajectory. We examine influence of the noise component in both the training data sets and the input sequences on network prediction quality. We propose and discuss an explanation of the observed noise compression in the predictive process. We also discuss importance of this property of recurrent networks in the neuroscience context for the evolution of living organisms.
A Massively-Parallel 3D Simulator for Soft and Hybrid Robots
Jul 19, 2022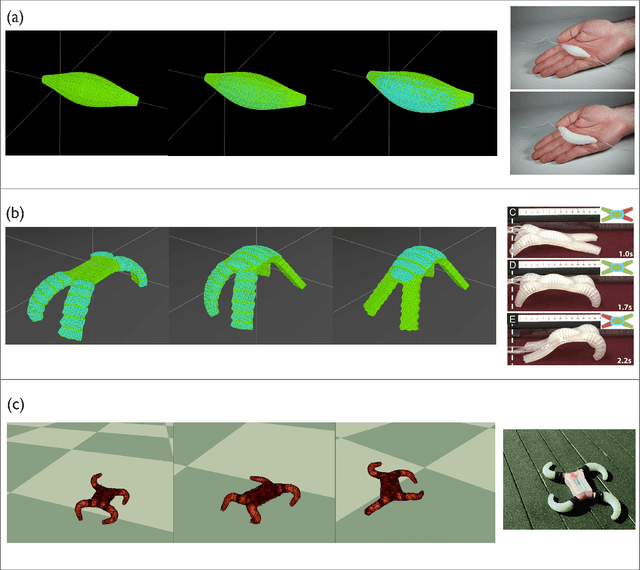

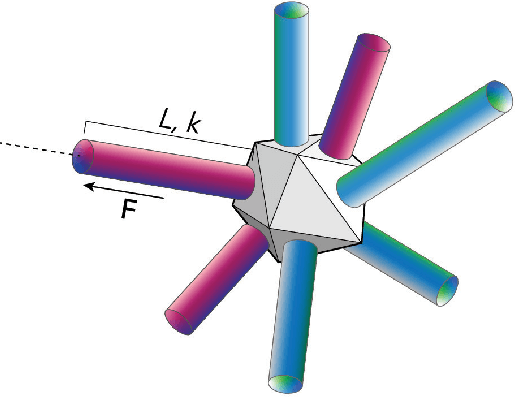
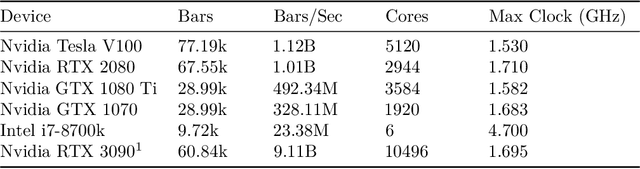
Simulation is an important step in robotics for creating control policies and testing various physical parameters. Soft robotics is a field that presents unique physical challenges for simulating its subjects due to the nonlinearity of deformable material components along with other innovative, and often complex, physical properties. Because of the computational cost of simulating soft and heterogeneous objects with traditional techniques, rigid robotics simulators are not well suited to simulating soft robots. Thus, many engineers must build their own one-off simulators tailored to their system, or use existing simulators with reduced performance. In order to facilitate the development of this exciting technology, this work presents an interactive-speed, accurate, and versatile simulator for a variety of types of soft robots. Cronos, our open-source 3D simulation engine, parallelizes a mass-spring model for ultra-fast performance on both deformable and rigid objects. Our approach is applicable to a wide array of nonlinear material configurations, including high deformability, volumetric actuation, or heterogenous stiffness. This versatility provides the ability to mix materials and geometric components freely within a single robot simulation. By exploiting the flexibility and scalability of nonlinear Hookean mass-spring systems, this framework simulates soft and rigid objects via a highly parallel model for near real-time speed. We describe an efficient GPU CUDA implementation, which we demonstrate to achieve computation of over 1 billion elements per second on consumer-grade GPU cards. Dynamic physical accuracy of the system is validated by comparing results to Euler-Bernoulli beam theory, natural frequency predictions, and empirical data of a soft structure under large deformation.
A Hybrid Energy Harvesting Protocol for Cooperative NOMA: Error Performance Approach
Jul 01, 2022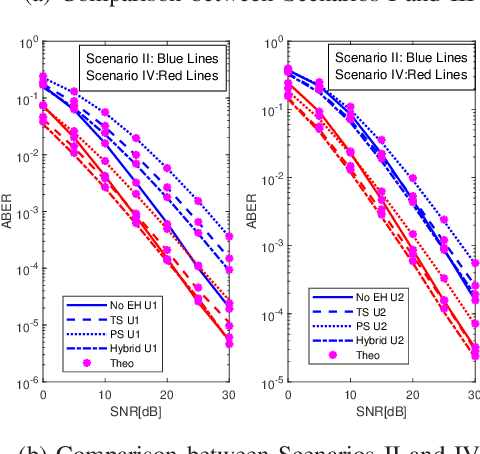
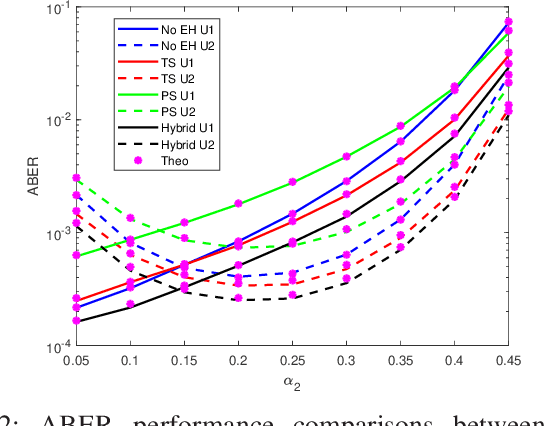
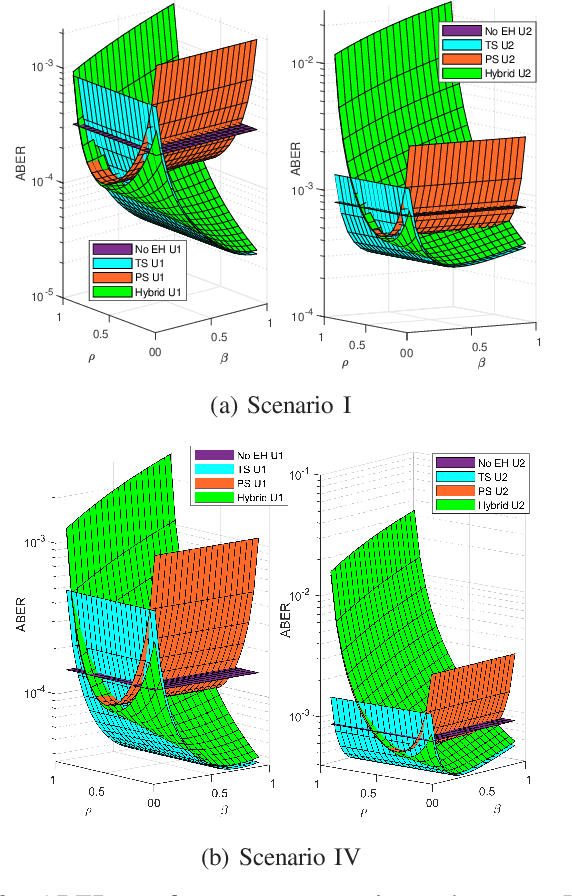
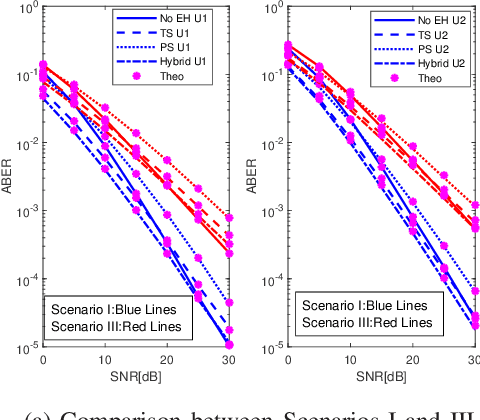
Cooperative non-orthogonal multiple access (CNOMA) has recently been adapted with energy harvesting (EH) to increase energy efficiency and extend the lifetime of energy-constrained wireless networks. This paper proposes a hybrid EH protocol-assisted CNOMA, which is a combination of the two main existing EH protocols (power splitting (PS) and time switching (TS)). The end-to-end bit error rate (BER) expressions of users in the proposed scheme are obtained over Nakagami-$m$ fading channels. The proposed hybrid EH (HEH) protocol is compared with the benchmark schemes (i.e., existing EH protocols and no EH). Based on the extensive simulations, we reveal that the analytical results match perfectly with simulations which proves the correctness of the derivations. Numerical results also show that the HEH-CNOMA outperforms the benchmarks significantly. In addition, we discuss the optimum value of EH factors to minimize the error probability in HEH-CNOMA and show that an optimum value can be obtained according to channel parameters.
A Synergistic Compilation Workflow for Tackling Crosstalk in Quantum Machines
Jul 19, 2022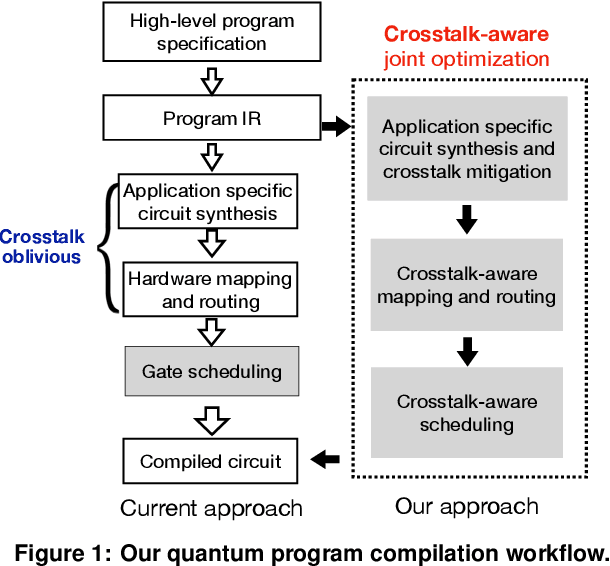
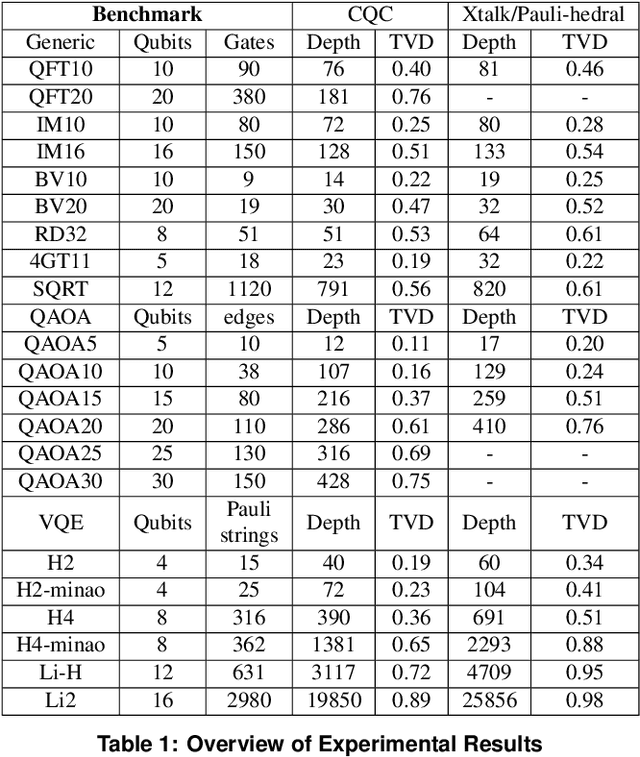
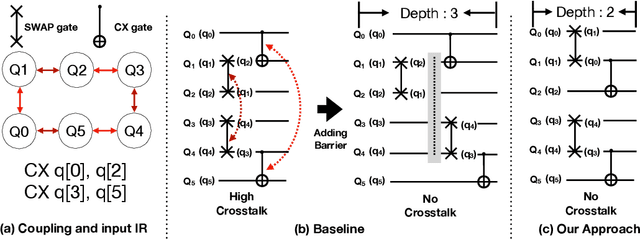
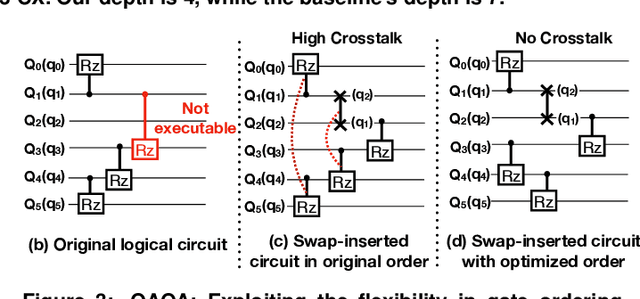
Near-term quantum systems tend to be noisy. Crosstalk noise has been recognized as one of several major types of noises in superconducting Noisy Intermediate-Scale Quantum (NISQ) devices. Crosstalk arises from the concurrent execution of two-qubit gates on nearby qubits, such as \texttt{CX}. It might significantly raise the error rate of gates in comparison to running them individually. Crosstalk can be mitigated through scheduling or hardware machine tuning. Prior scientific studies, however, manage crosstalk at a really late phase in the compilation process, usually after hardware mapping is done. It may miss great opportunities of optimizing algorithm logic, routing, and crosstalk at the same time. In this paper, we push the envelope by considering all these factors simultaneously at the very early compilation stage. We propose a crosstalk-aware quantum program compilation framework called CQC that can enhance crosstalk mitigation while achieving satisfactory circuit depth. Moreover, we identify opportunities for translation from intermediate representation to the circuit for application-specific crosstalk mitigation, for instance, the \texttt{CX} ladder construction in variational quantum eigensolvers (VQE). Evaluations through simulation and on real IBM-Q devices show that our framework can significantly reduce the error rate by up to 6$\times$, with only $\sim$60\% circuit depth compared to state-of-the-art gate scheduling approaches. In particular, for VQE, we demonstrate 49\% circuit depth reduction with 9.6\% fidelity improvement over prior art on the H4 molecule using IBMQ Guadalupe. Our CQC framework will be released on GitHub.
Vehicle Teleoperation: Successive Reference-Pose Tracking
Jun 08, 2022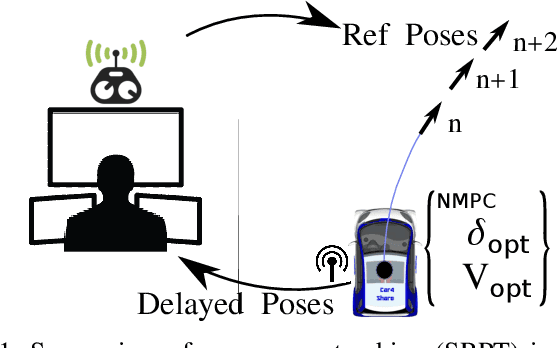
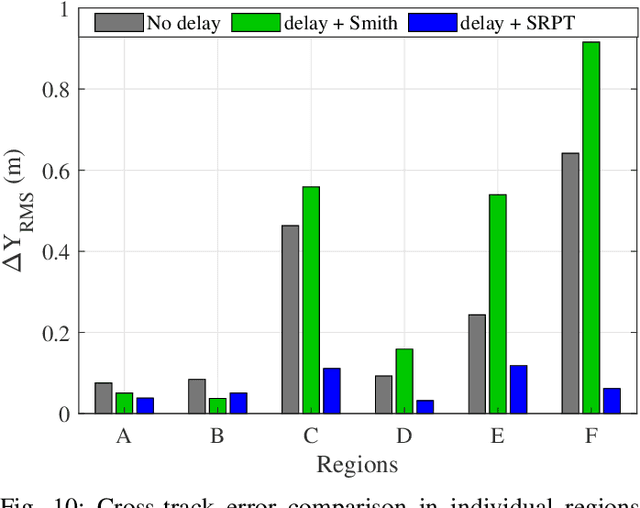
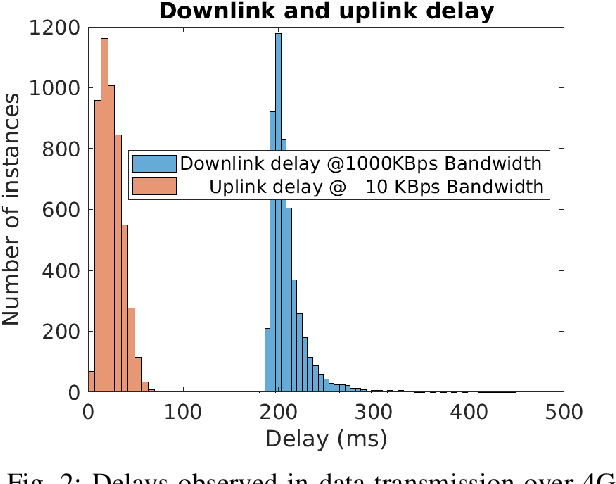
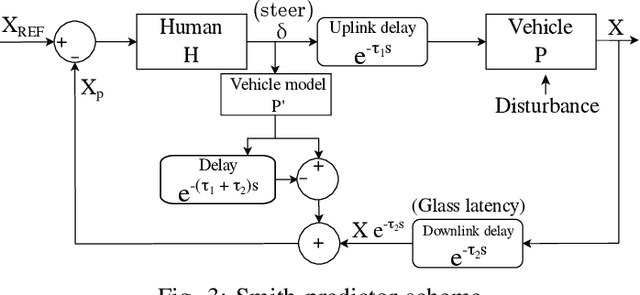
Vehicle teleoperation is an interesting feature in many fields. A typical problem of teleoperation is communication time delay which, together with actuator saturation and environmental disturbance, can cause a vehicle deviation from the target trajectory imposed by the human operator who imposes to the vehicle a steering wheel angle reference and a speed/acceleration reference. With predictive techniques, time-delay can be accounted at sufficient extent. But, in presence of disturbances, due to the absence of instantaneous haptic and visual feedback, human-operator steering command transmitted to the the vehicle is unaccounted with disturbances observed by the vehicle. To improve reference tracking without losing promptness in driving control, reference trajectory in the form of successive reference poses can be transmitted instead of steering commands to the vehicle. We introduce this new concept, namely, the 'successive reference-pose tracking (SRPT)' to improve path tracking in vehicle teleoperation. This paper discusses feasibility and advantages of this new method, compare to the smith predictor control approach. Simulations are performed in SIMULINK environment, where a 14-dof vehicle model is being controlled with Smith and SRPT controllers in presence of variable network delay. Scenarios for performance comparison are low adhesion ground, strong lateral wind and steer-rate demanding maneuvers. Simulation result shows significant improvement in reference tracking with SRPT approach.
Solving the optimal stopping problem with reinforcement learning: an application in financial option exercise
Jul 21, 2022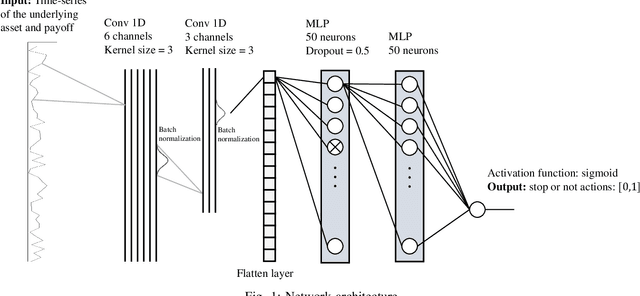
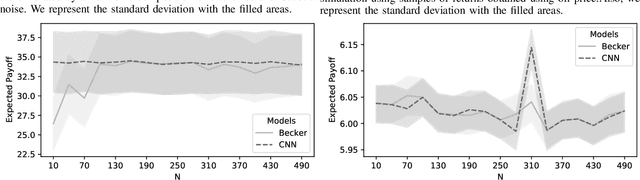
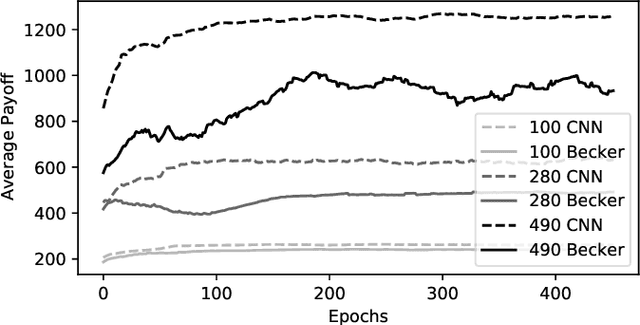

The optimal stopping problem is a category of decision problems with a specific constrained configuration. It is relevant to various real-world applications such as finance and management. To solve the optimal stopping problem, state-of-the-art algorithms in dynamic programming, such as the least-squares Monte Carlo (LSMC), are employed. This type of algorithm relies on path simulations using only the last price of the underlying asset as a state representation. Also, the LSMC was thinking for option valuation where risk-neutral probabilities can be employed to account for uncertainty. However, the general optimal stopping problem goals may not fit the requirements of the LSMC showing auto-correlated prices. We employ a data-driven method that uses Monte Carlo simulation to train and test artificial neural networks (ANN) to solve the optimal stopping problem. Using ANN to solve decision problems is not entirely new. We propose a different architecture that uses convolutional neural networks (CNN) to deal with the dimensionality problem that arises when we transform the whole history of prices into a Markovian state. We present experiments that indicate that our proposed architecture improves results over the previous implementations under specific simulated time series function sets. Lastly, we employ our proposed method to compare the optimal exercise of the financial options problem with the LSMC algorithm. Our experiments show that our method can capture more accurate exercise opportunities when compared to the LSMC. We have outstandingly higher (above 974\% improvement) expected payoff from these exercise policies under the many Monte Carlo simulations that used the real-world return database on the out-of-sample (test) data.