 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Open-Source LiDAR Time Synchronization System by Mimicking GPS-clock
Jul 06, 2021

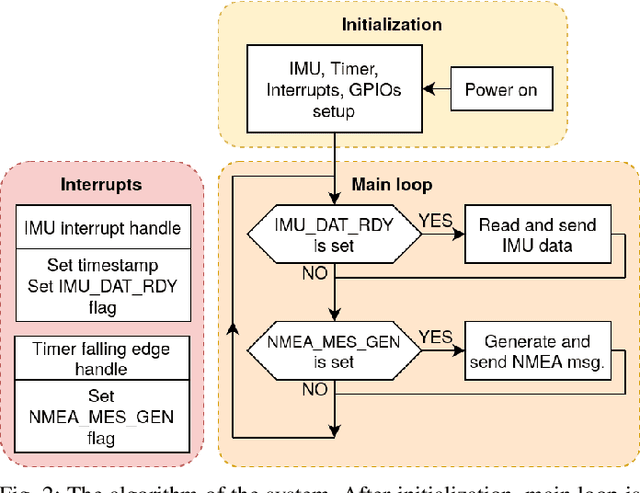
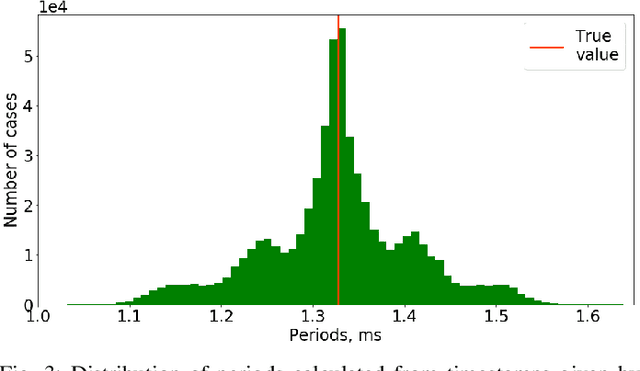
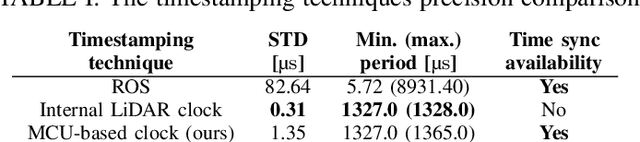
Time synchronization of multiple sensors is one of the main issues when building sensor networks. Data fusion algorithms and their applications, such as LiDAR-IMU Odometry (LIO), rely on precise timestamping. We introduce open-source LiDAR to inertial measurement unit (IMU) hardware time synchronization system, which could be generalized to multiple sensors such as cameras, encoders, other LiDARs, etc. The system mimics a GPS-supplied clock interface by a microcontroller-powered platform and provides 1 microsecond synchronization precision. In addition, we conduct an evaluation of the system precision comparing to other synchronization methods, including timestamping provided by ROS software and LiDAR inner clock, showing clear advantages over both baseline methods.
Self-Supervised Interactive Object Segmentation Through a Singulation-and-Grasping Approach
Jul 20, 2022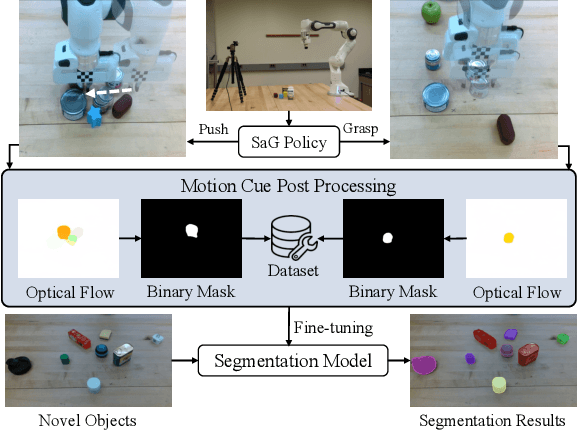
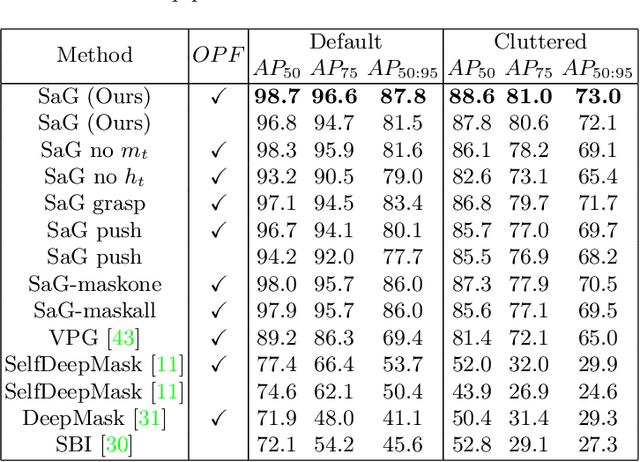
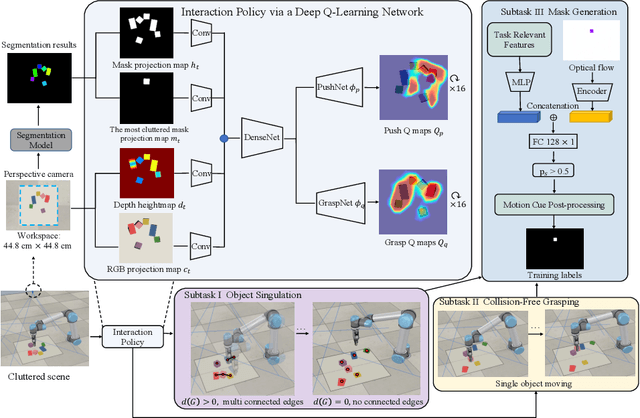
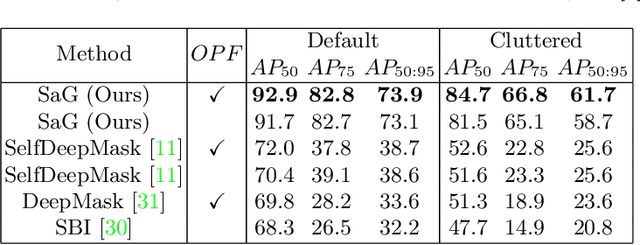
Instance segmentation with unseen objects is a challenging problem in unstructured environments. To solve this problem, we propose a robot learning approach to actively interact with novel objects and collect each object's training label for further fine-tuning to improve the segmentation model performance, while avoiding the time-consuming process of manually labeling a dataset. The Singulation-and-Grasping (SaG) policy is trained through end-to-end reinforcement learning. Given a cluttered pile of objects, our approach chooses pushing and grasping motions to break the clutter and conducts object-agnostic grasping for which the SaG policy takes as input the visual observations and imperfect segmentation. We decompose the problem into three subtasks: (1) the object singulation subtask aims to separate the objects from each other, which creates more space that alleviates the difficulty of (2) the collision-free grasping subtask; (3) the mask generation subtask to obtain the self-labeled ground truth masks by using an optical flow-based binary classifier and motion cue post-processing for transfer learning. Our system achieves 70% singulation success rate in simulated cluttered scenes. The interactive segmentation of our system achieves 87.8%, 73.9%, and 69.3% average precision for toy blocks, YCB objects in simulation and real-world novel objects, respectively, which outperforms several baselines.
Model-Driven Based Deep Unfolding Equalizer for Underwater Acoustic OFDM Communications
Jul 10, 2022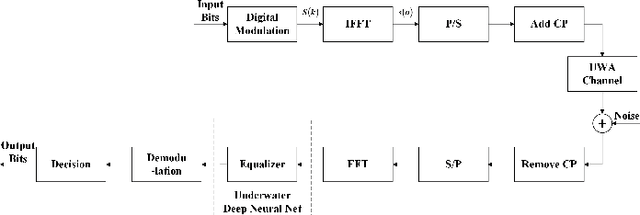
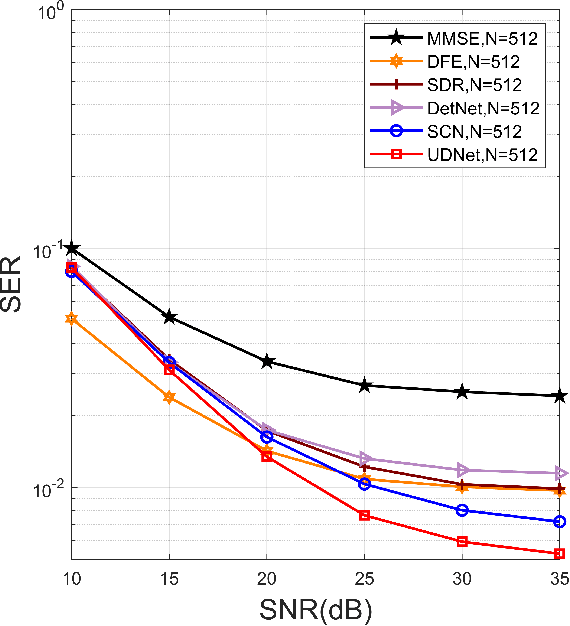
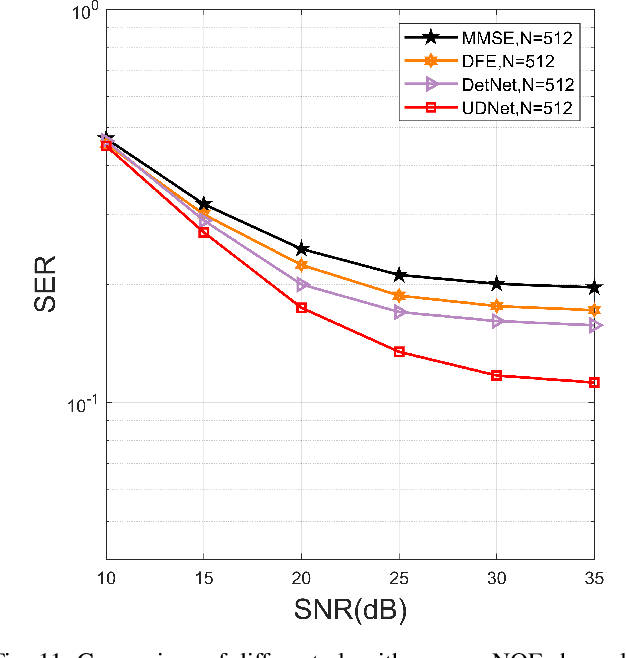
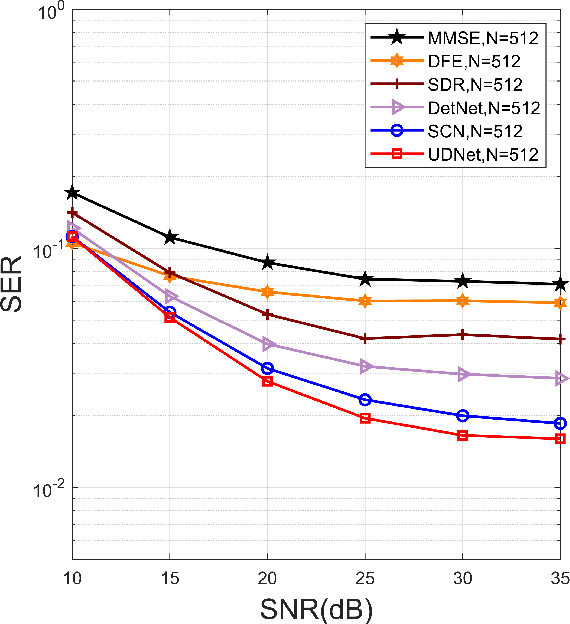
It is a challenge to design a equalizer for complex time-frequency doubly-spread channels. In this paper, we employ the deep learning (DL) architecture by that unfolding an existing iterative algorithm to build an equalizer named underwater deep network (UDNet) for underwater acoustic (UWA) orthogonal frequency division multiplexing (OFDM) signal. Considering constellation recognition is a classification issue, the one-hot coding and softmax layer are adopted in the proposed network to achieve the minimum Kullback-Leibler (KL) criterion. Simultaneously, we introduce a sliding structure based on the banded approximation of the channel matrix to reduce computational complexity and aid UDNet performs well for different length signals without changing the network structure. Furthermore, we apply the environment of the true UWA channel as much as possible, including utilize measured doubly-spread UWA channel and offshore background noise to evaluate the UDNet. Experimental results show that in the case of 10-35dB SNR, UDNet achieves better performance with low computational complexity.
Survival Kernets: Scalable and Interpretable Deep Kernel Survival Analysis with an Accuracy Guarantee
Jun 21, 2022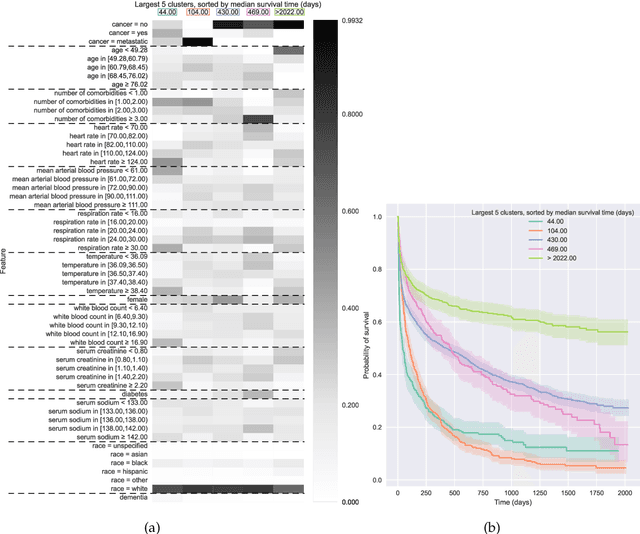
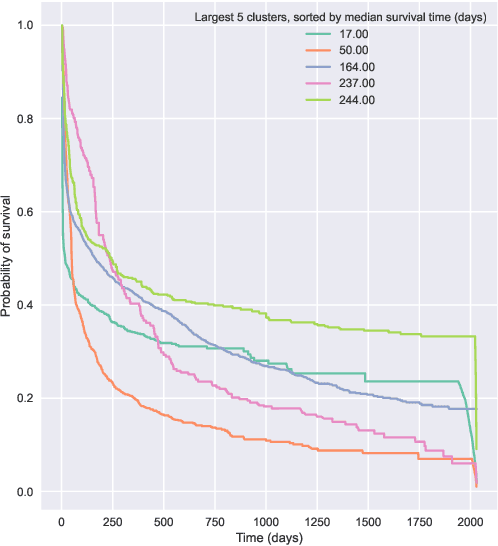
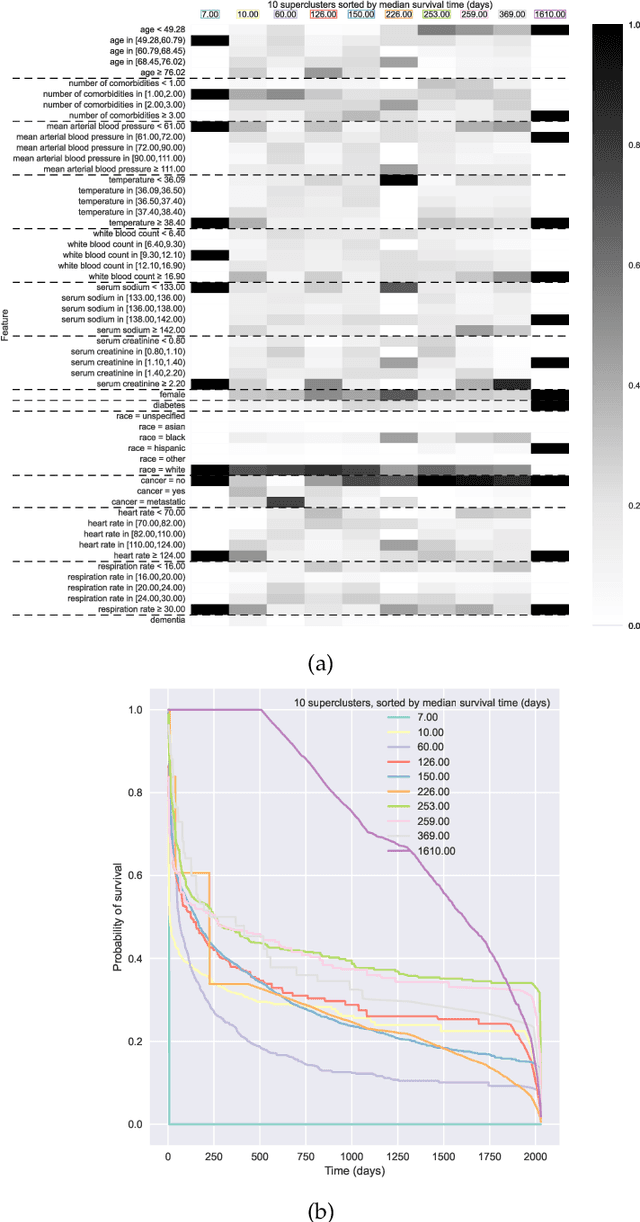
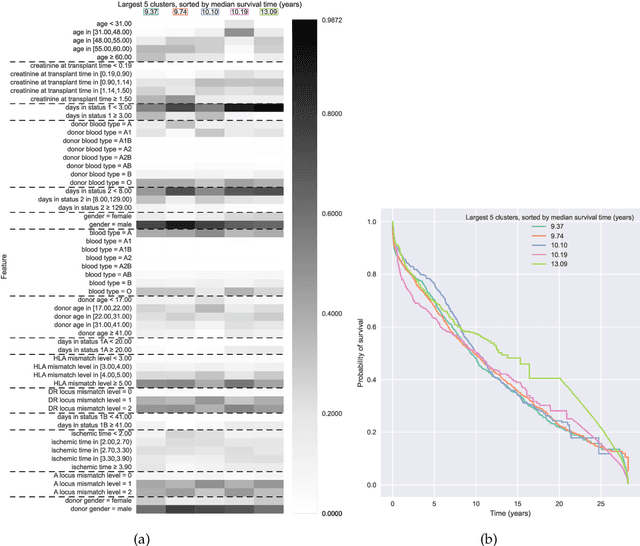
Kernel survival analysis models estimate individual survival distributions with the help of a kernel function, which measures the similarity between any two data points. Such a kernel function can be learned using deep kernel survival models. In this paper, we present a new deep kernel survival model called a survival kernet, which scales to large datasets in a manner that is amenable to model interpretation and also theoretical analysis. Specifically, the training data are partitioned into clusters based on a recently developed training set compression scheme for classification and regression called kernel netting that we extend to the survival analysis setting. At test-time, each data point is represented as a weighted combination of these clusters, and each such cluster can be visualized. For a special case of survival kernets, we establish a finite-sample error bound on predicted survival distributions that is, up to a log factor, optimal. Whereas scalability at test time is achieved using the aforementioned kernel netting compression strategy, scalability during training is achieved by a warm-start procedure based on tree ensembles such as XGBoost and a heuristic approach to accelerating neural architecture search. On three standard survival analysis datasets of varying sizes (up to roughly 3 million data points), we show that survival kernets are highly competitive with the best of baselines tested in terms of concordance index. Our code is available at: https://github.com/georgehc/survival-kernets
SECLEDS: Sequence Clustering in Evolving Data Streams via Multiple Medoids and Medoid Voting
Jun 24, 2022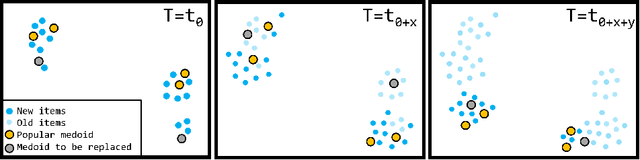

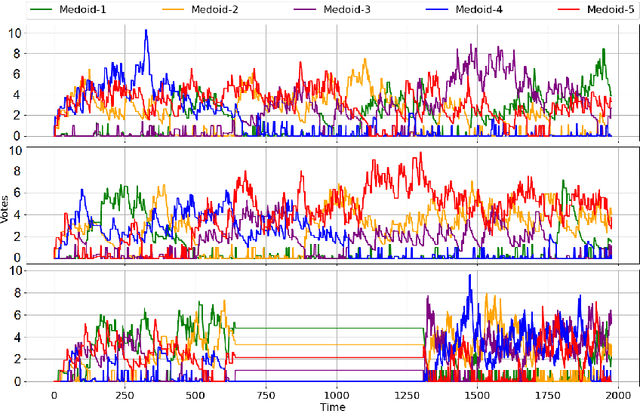
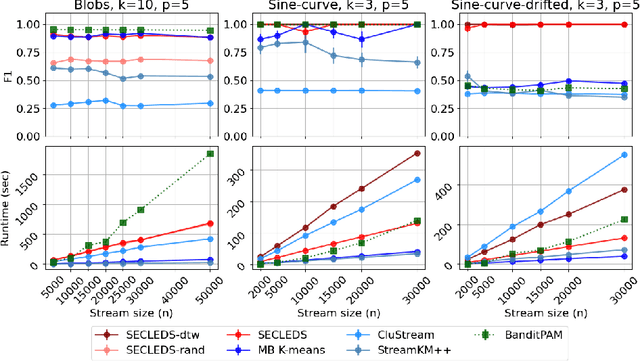
Sequence clustering in a streaming environment is challenging because it is computationally expensive, and the sequences may evolve over time. K-medoids or Partitioning Around Medoids (PAM) is commonly used to cluster sequences since it supports alignment-based distances, and the k-centers being actual data items helps with cluster interpretability. However, offline k-medoids has no support for concept drift, while also being prohibitively expensive for clustering data streams. We therefore propose SECLEDS, a streaming variant of the k-medoids algorithm with constant memory footprint. SECLEDS has two unique properties: i) it uses multiple medoids per cluster, producing stable high-quality clusters, and ii) it handles concept drift using an intuitive Medoid Voting scheme for approximating cluster distances. Unlike existing adaptive algorithms that create new clusters for new concepts, SECLEDS follows a fundamentally different approach, where the clusters themselves evolve with an evolving stream. Using real and synthetic datasets, we empirically demonstrate that SECLEDS produces high-quality clusters regardless of drift, stream size, data dimensionality, and number of clusters. We compare against three popular stream and batch clustering algorithms. The state-of-the-art BanditPAM is used as an offline benchmark. SECLEDS achieves comparable F1 score to BanditPAM while reducing the number of required distance computations by 83.7%. Importantly, SECLEDS outperforms all baselines by 138.7% when the stream contains drift. We also cluster real network traffic, and provide evidence that SECLEDS can support network bandwidths of up to 1.08 Gbps while using the (expensive) dynamic time warping distance.
Autonomous Platoon Control with Integrated Deep Reinforcement Learning and Dynamic Programming
Jun 15, 2022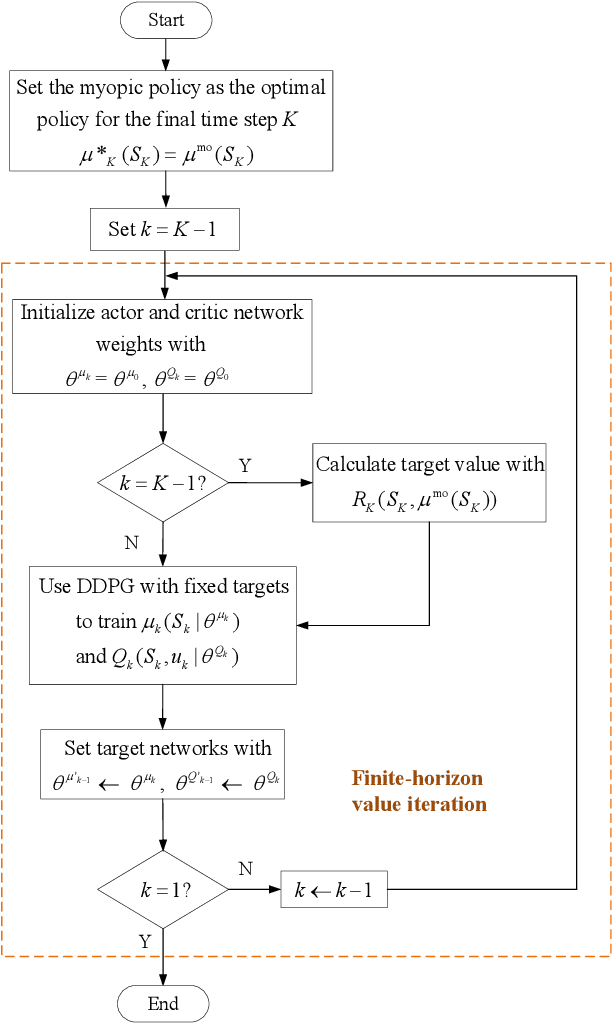
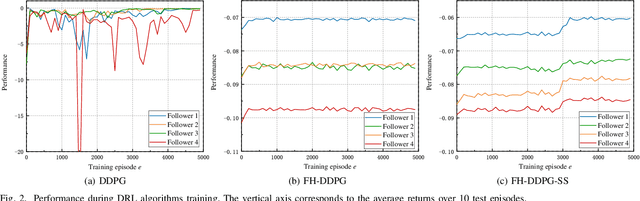
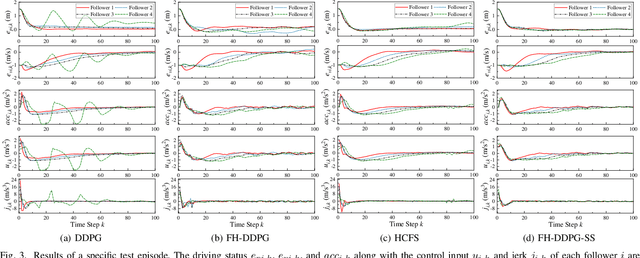
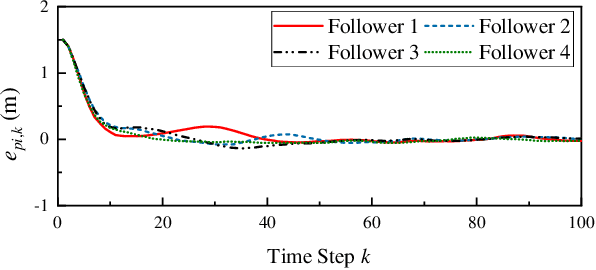
Deep Reinforcement Learning (DRL) is regarded as a potential method for car-following control and has been mostly studied to support a single following vehicle. However, it is more challenging to learn a stable and efficient car-following policy when there are multiple following vehicles in a platoon, especially with unpredictable leading vehicle behavior. In this context, we adopt an integrated DRL and Dynamic Programming (DP) approach to learn autonomous platoon control policies, which embeds the Deep Deterministic Policy Gradient (DDPG) algorithm into a finite-horizon value iteration framework. Although the DP framework can improve the stability and performance of DDPG, it has the limitations of lower sampling and training efficiency. In this paper, we propose an algorithm, namely Finite-Horizon-DDPG with Sweeping through reduced state space using Stationary approximation (FH-DDPG-SS), which uses three key ideas to overcome the above limitations, i.e., transferring network weights backward in time, stationary policy approximation for earlier time steps, and sweeping through reduced state space. In order to verify the effectiveness of FH-DDPG-SS, simulation using real driving data is performed, where the performance of FH-DDPG-SS is compared with those of the benchmark algorithms. Finally, platoon safety and string stability for FH-DDPG-SS are demonstrated.
Physics-Informed Deep Neural Operator Networks
Jul 17, 2022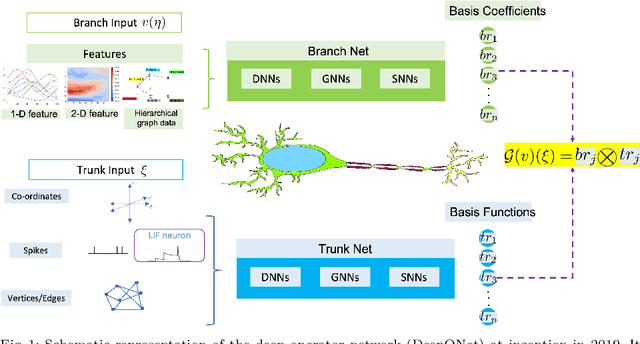
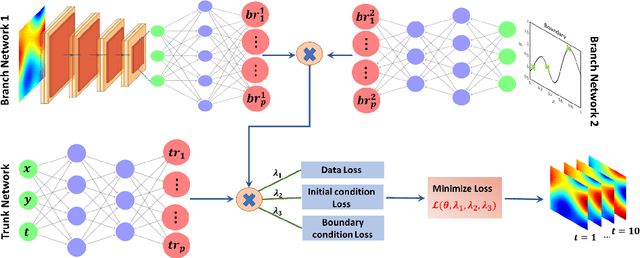
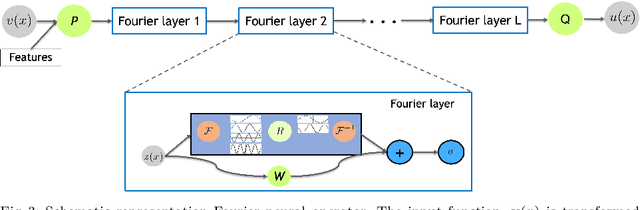
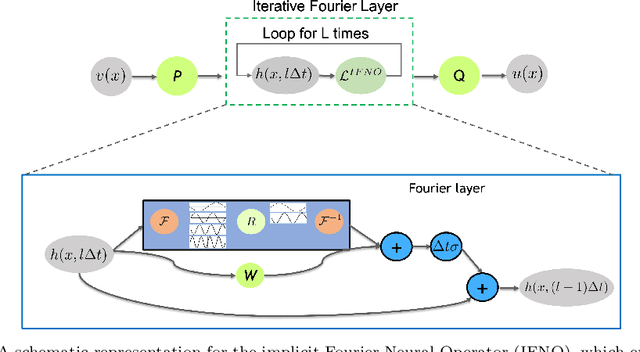
Standard neural networks can approximate general nonlinear operators, represented either explicitly by a combination of mathematical operators, e.g., in an advection-diffusion-reaction partial differential equation, or simply as a black box, e.g., a system-of-systems. The first neural operator was the Deep Operator Network (DeepONet), proposed in 2019 based on rigorous approximation theory. Since then, a few other less general operators have been published, e.g., based on graph neural networks or Fourier transforms. For black box systems, training of neural operators is data-driven only but if the governing equations are known they can be incorporated into the loss function during training to develop physics-informed neural operators. Neural operators can be used as surrogates in design problems, uncertainty quantification, autonomous systems, and almost in any application requiring real-time inference. Moreover, independently pre-trained DeepONets can be used as components of a complex multi-physics system by coupling them together with relatively light training. Here, we present a review of DeepONet, the Fourier neural operator, and the graph neural operator, as well as appropriate extensions with feature expansions, and highlight their usefulness in diverse applications in computational mechanics, including porous media, fluid mechanics, and solid mechanics.
Self-Supervised-RCNN for Medical Image Segmentation with Limited Data Annotation
Jul 17, 2022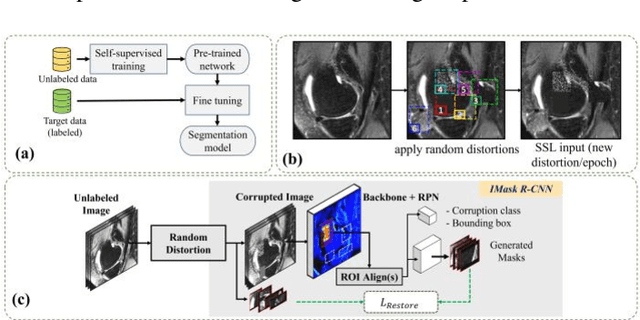
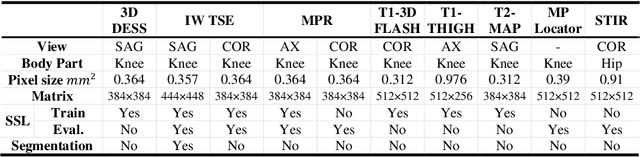
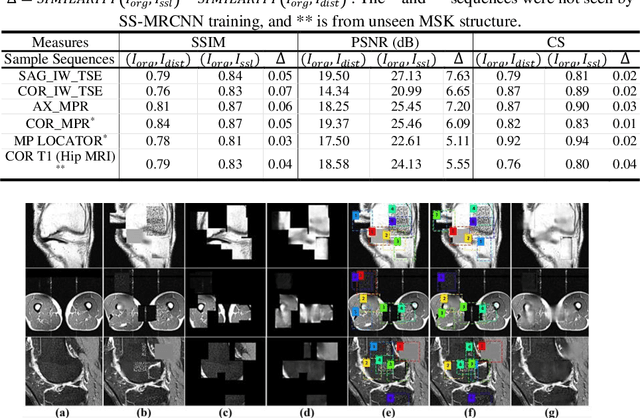
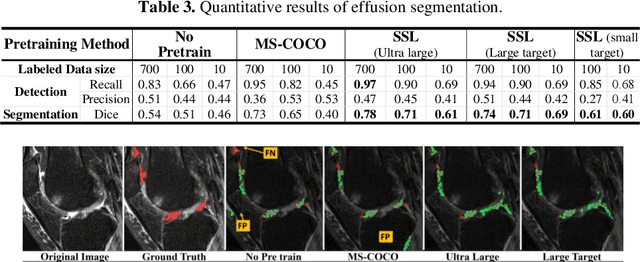
Many successful methods developed for medical image analysis that are based on machine learning use supervised learning approaches, which often require large datasets annotated by experts to achieve high accuracy. However, medical data annotation is time-consuming and expensive, especially for segmentation tasks. To solve the problem of learning with limited labeled medical image data, an alternative deep learning training strategy based on self-supervised pretraining on unlabeled MRI scans is proposed in this work. Our pretraining approach first, randomly applies different distortions to random areas of unlabeled images and then predicts the type of distortions and loss of information. To this aim, an improved version of Mask-RCNN architecture has been adapted to localize the distortion location and recover the original image pixels. The effectiveness of the proposed method for segmentation tasks in different pre-training and fine-tuning scenarios is evaluated based on the Osteoarthritis Initiative dataset. Using this self-supervised pretraining method improved the Dice score by 20% compared to training from scratch. The proposed self-supervised learning is simple, effective, and suitable for different ranges of medical image analysis tasks including anomaly detection, segmentation, and classification.
Progressive Voronoi Diagram Subdivision: Towards A Holistic Geometric Framework for Exemplar-free Class-Incremental Learning
Jul 28, 2022
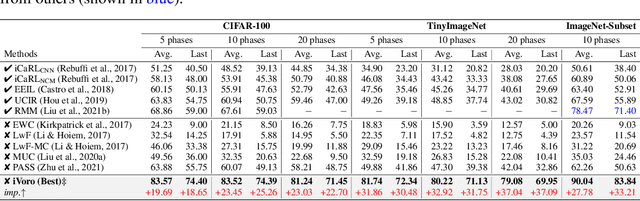
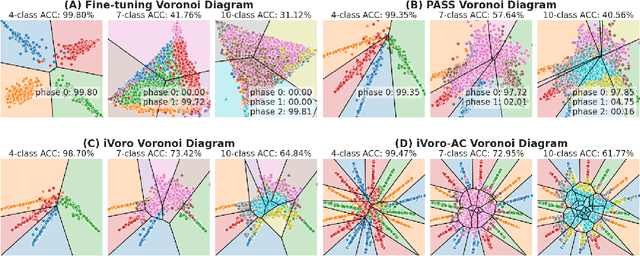
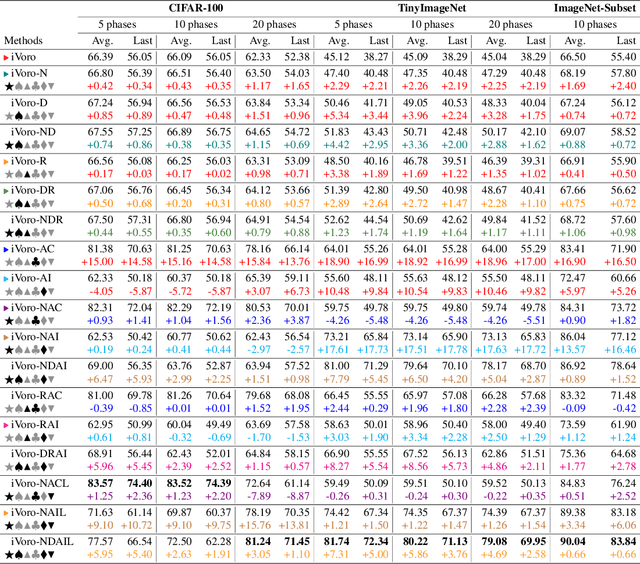
Exemplar-free Class-incremental Learning (CIL) is a challenging problem because rehearsing data from previous phases is strictly prohibited, causing catastrophic forgetting of Deep Neural Networks (DNNs). In this paper, we present iVoro, a holistic framework for CIL, derived from computational geometry. We found Voronoi Diagram (VD), a classical model for space subdivision, is especially powerful for solving the CIL problem, because VD itself can be constructed favorably in an incremental manner -- the newly added sites (classes) will only affect the proximate classes, making the non-contiguous classes hardly forgettable. Further, in order to find a better set of centers for VD construction, we colligate DNN with VD using Power Diagram and show that the VD structure can be optimized by integrating local DNN models using a divide-and-conquer algorithm. Moreover, our VD construction is not restricted to the deep feature space, but is also applicable to multiple intermediate feature spaces, promoting VD to be multi-centered VD (CIVD) that efficiently captures multi-grained features from DNN. Importantly, iVoro is also capable of handling uncertainty-aware test-time Voronoi cell assignment and has exhibited high correlations between geometric uncertainty and predictive accuracy (up to ~0.9). Putting everything together, iVoro achieves up to 25.26%, 37.09%, and 33.21% improvements on CIFAR-100, TinyImageNet, and ImageNet-Subset, respectively, compared to the state-of-the-art non-exemplar CIL approaches. In conclusion, iVoro enables highly accurate, privacy-preserving, and geometrically interpretable CIL that is particularly useful when cross-phase data sharing is forbidden, e.g. in medical applications. Our code is available at https://machunwei.github.io/ivoro.
Mobility-Aware Cooperative Caching in Vehicular Edge Computing Based on Asynchronous Federated and Deep Reinforcement Learning
Aug 02, 2022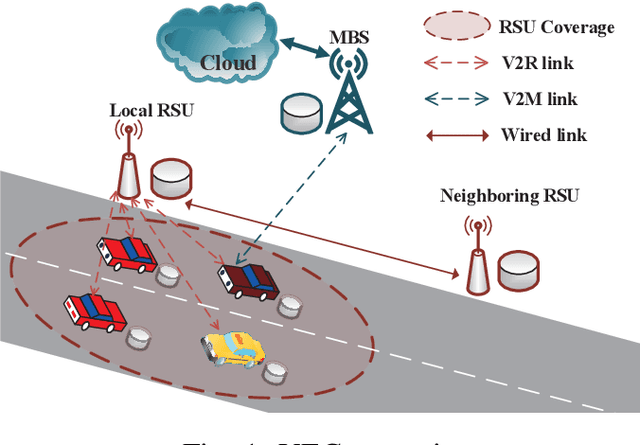
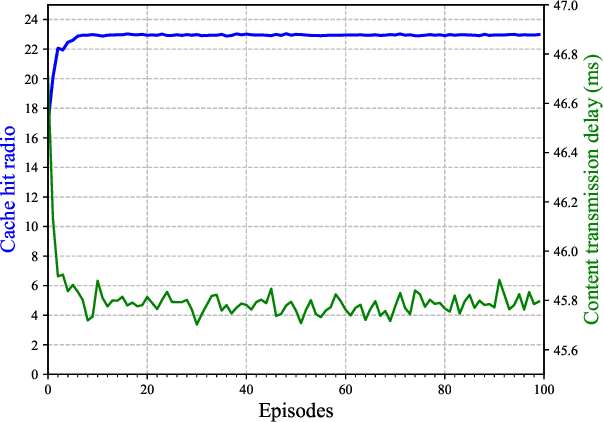
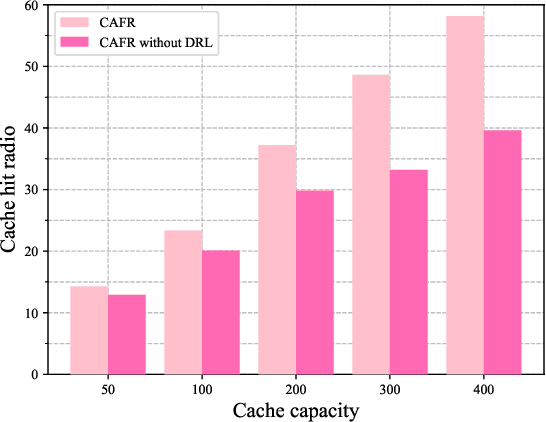
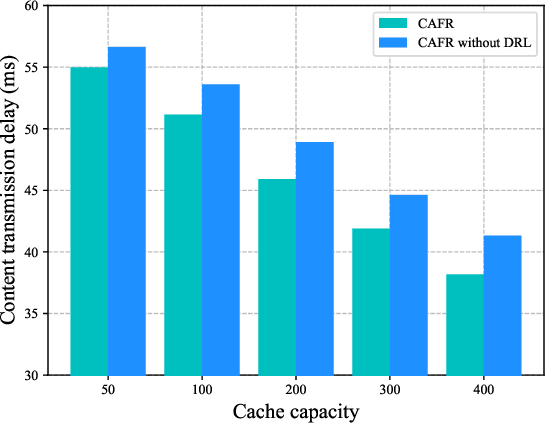
The vehicular edge computing (VEC) can cache contents in different RSUs at the network edge to support the real-time vehicular applications. In VEC, owing to the high-mobility characteristics of vehicles, it is necessary to cache the user data in advance and learn the most popular and interesting contents for vehicular users. Since user data usually contains privacy information, users are reluctant to share their data with others. To solve this problem, traditional federated learning (FL) needs to update the global model synchronously through aggregating all users' local models to protect users' privacy. However, vehicles may frequently drive out of the coverage area of the VEC before they achieve their local model trainings and thus the local models cannot be uploaded as expected, which would reduce the accuracy of the global model. In addition, the caching capacity of the local RSU is limited and the popular contents are diverse, thus the size of the predicted popular contents usually exceeds the cache capacity of the local RSU. Hence, the VEC should cache the predicted popular contents in different RSUs while considering the content transmission delay. In this paper, we consider the mobility of vehicles and propose a cooperative Caching scheme in the VEC based on Asynchronous Federated and deep Reinforcement learning (CAFR). We first consider the mobility of vehicles and propose an asynchronous FL algorithm to obtain an accurate global model, and then propose an algorithm to predict the popular contents based on the global model. In addition, we consider the mobility of vehicles and propose a deep reinforcement learning algorithm to obtain the optimal cooperative caching location for the predicted popular contents in order to optimize the content transmission delay. Extensive experimental results have demonstrated that the CAFR scheme outperforms other baseline caching schemes.