 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-objective optimization via equivariant deep hypervolume approximation
Oct 05, 2022
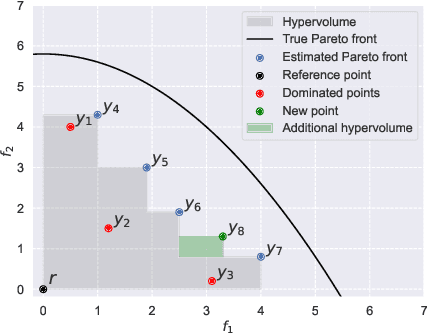
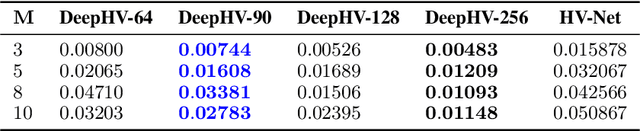
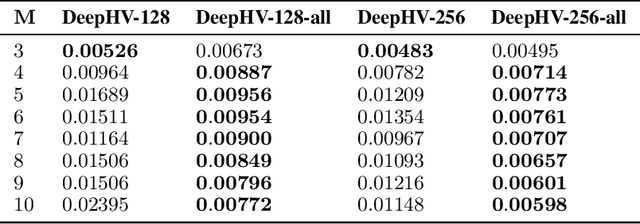
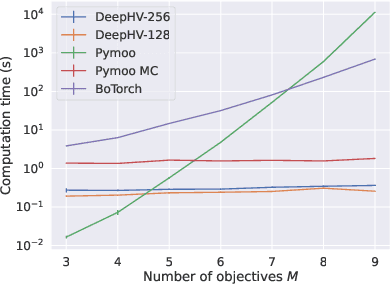
Optimizing multiple competing objectives is a common problem across science and industry. The inherent inextricable trade-off between those objectives leads one to the task of exploring their Pareto front. A meaningful quantity for the purpose of the latter is the hypervolume indicator, which is used in Bayesian Optimization (BO) and Evolutionary Algorithms (EAs). However, the computational complexity for the calculation of the hypervolume scales unfavorably with increasing number of objectives and data points, which restricts its use in those common multi-objective optimization frameworks. To overcome these restrictions we propose to approximate the hypervolume function with a deep neural network, which we call DeepHV. For better sample efficiency and generalization, we exploit the fact that the hypervolume is scale-equivariant in each of the objectives as well as permutation invariant w.r.t. both the objectives and the samples, by using a deep neural network that is equivariant w.r.t. the combined group of scalings and permutations. We evaluate our method against exact, and approximate hypervolume methods in terms of accuracy, computation time, and generalization. We also apply and compare our methods to state-of-the-art multi-objective BO methods and EAs on a range of synthetic benchmark test cases. The results show that our methods are promising for such multi-objective optimization tasks.
Blinder: End-to-end Privacy Protection in Sensing Systems via Personalized Federated Learning
Sep 27, 2022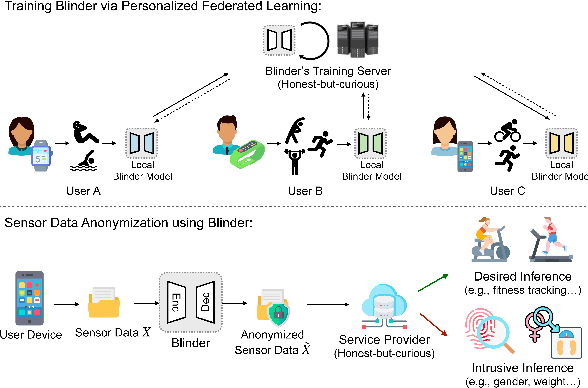

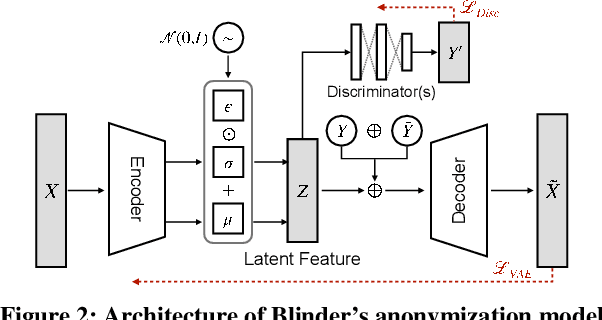
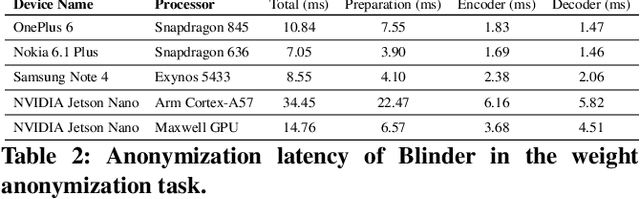
This paper proposes a sensor data anonymization model that is trained on decentralized data and strikes a desirable trade-off between data utility and privacy, even in heterogeneous settings where the collected sensor data have different underlying distributions. Our anonymization model, dubbed Blinder, is based on a variational autoencoder and discriminator networks trained in an adversarial fashion. We use the model-agnostic meta-learning framework to adapt the anonymization model trained via federated learning to each user's data distribution. We evaluate Blinder under different settings and show that it provides end-to-end privacy protection at the cost of increasing privacy loss by up to 4.00% and decreasing data utility by up to 4.24%, compared to the state-of-the-art anonymization model trained on centralized data. Our experiments confirm that Blinder can obscure multiple private attributes at once, and has sufficiently low power consumption and computational overhead for it to be deployed on edge devices and smartphones to perform real-time anonymization of sensor data.
Model-based Safe Deep Reinforcement Learning via a Constrained Proximal Policy Optimization Algorithm
Oct 14, 2022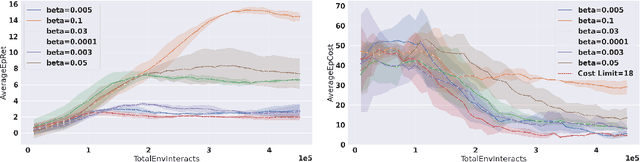
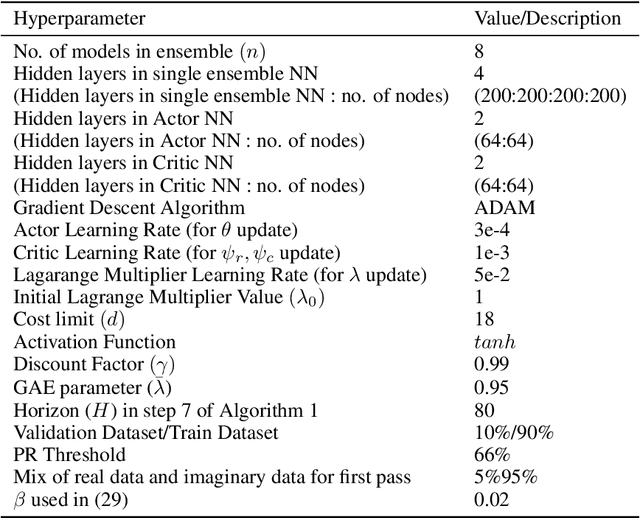
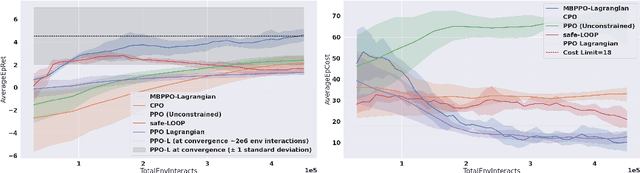
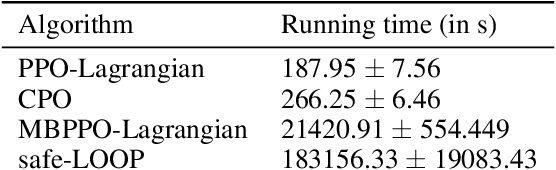
During initial iterations of training in most Reinforcement Learning (RL) algorithms, agents perform a significant number of random exploratory steps. In the real world, this can limit the practicality of these algorithms as it can lead to potentially dangerous behavior. Hence safe exploration is a critical issue in applying RL algorithms in the real world. This problem has been recently well studied under the Constrained Markov Decision Process (CMDP) Framework, where in addition to single-stage rewards, an agent receives single-stage costs or penalties as well depending on the state transitions. The prescribed cost functions are responsible for mapping undesirable behavior at any given time-step to a scalar value. The goal then is to find a feasible policy that maximizes reward returns while constraining the cost returns to be below a prescribed threshold during training as well as deployment. We propose an On-policy Model-based Safe Deep RL algorithm in which we learn the transition dynamics of the environment in an online manner as well as find a feasible optimal policy using the Lagrangian Relaxation-based Proximal Policy Optimization. We use an ensemble of neural networks with different initializations to tackle epistemic and aleatoric uncertainty issues faced during environment model learning. We compare our approach with relevant model-free and model-based approaches in Constrained RL using the challenging Safe Reinforcement Learning benchmark - the Open AI Safety Gym. We demonstrate that our algorithm is more sample efficient and results in lower cumulative hazard violations as compared to constrained model-free approaches. Further, our approach shows better reward performance than other constrained model-based approaches in the literature.
S4ND: Modeling Images and Videos as Multidimensional Signals Using State Spaces
Oct 14, 2022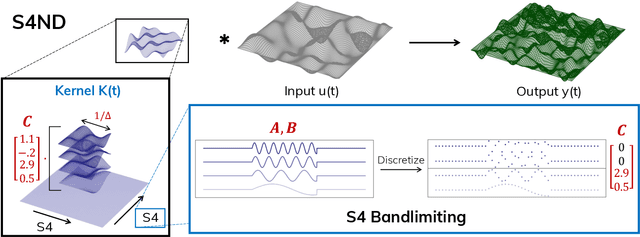
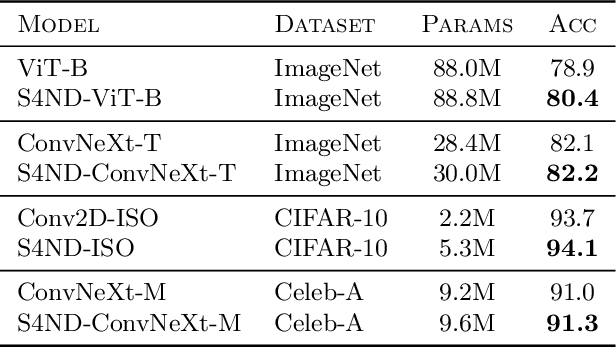
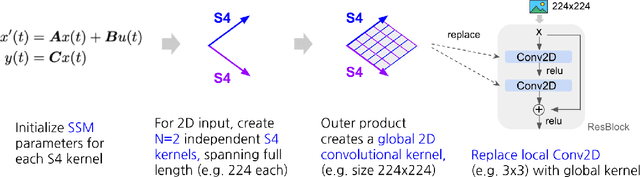
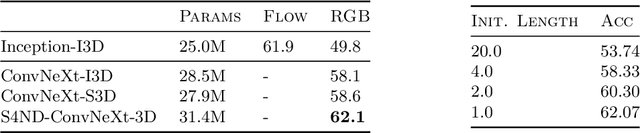
Visual data such as images and videos are typically modeled as discretizations of inherently continuous, multidimensional signals. Existing continuous-signal models attempt to exploit this fact by modeling the underlying signals of visual (e.g., image) data directly. However, these models have not yet been able to achieve competitive performance on practical vision tasks such as large-scale image and video classification. Building on a recent line of work on deep state space models (SSMs), we propose S4ND, a new multidimensional SSM layer that extends the continuous-signal modeling ability of SSMs to multidimensional data including images and videos. We show that S4ND can model large-scale visual data in $1$D, $2$D, and $3$D as continuous multidimensional signals and demonstrates strong performance by simply swapping Conv2D and self-attention layers with S4ND layers in existing state-of-the-art models. On ImageNet-1k, S4ND exceeds the performance of a Vision Transformer baseline by $1.5\%$ when training with a $1$D sequence of patches, and matches ConvNeXt when modeling images in $2$D. For videos, S4ND improves on an inflated $3$D ConvNeXt in activity classification on HMDB-51 by $4\%$. S4ND implicitly learns global, continuous convolutional kernels that are resolution invariant by construction, providing an inductive bias that enables generalization across multiple resolutions. By developing a simple bandlimiting modification to S4 to overcome aliasing, S4ND achieves strong zero-shot (unseen at training time) resolution performance, outperforming a baseline Conv2D by $40\%$ on CIFAR-10 when trained on $8 \times 8$ and tested on $32 \times 32$ images. When trained with progressive resizing, S4ND comes within $\sim 1\%$ of a high-resolution model while training $22\%$ faster.
Multi-dataset Training of Transformers for Robust Action Recognition
Sep 27, 2022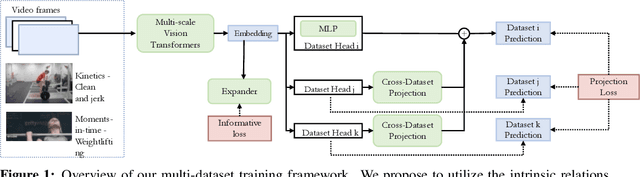
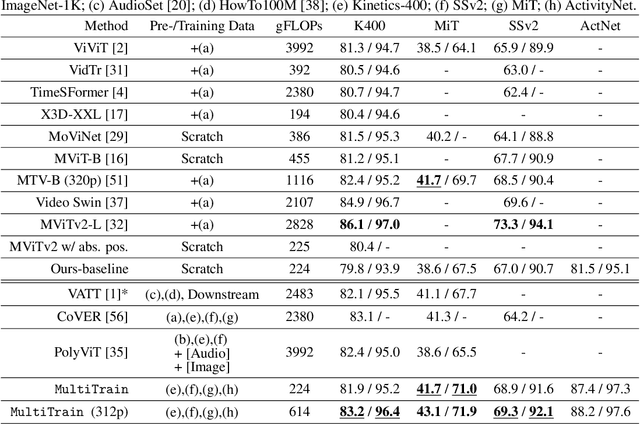
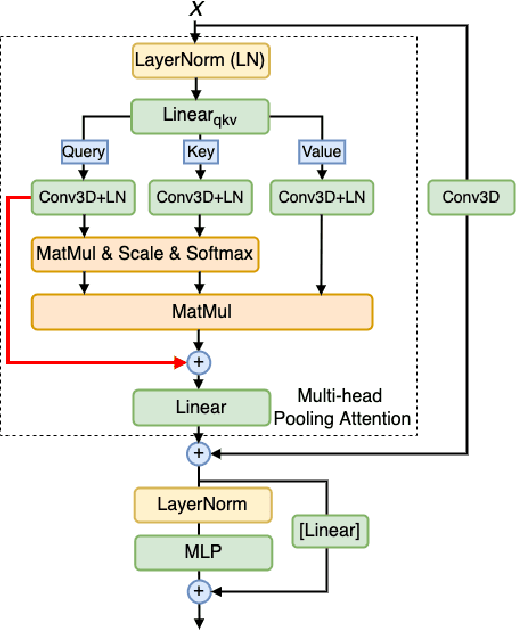

We study the task of robust feature representations, aiming to generalize well on multiple datasets for action recognition. We build our method on Transformers for its efficacy. Although we have witnessed great progress for video action recognition in the past decade, it remains challenging yet valuable how to train a single model that can perform well across multiple datasets. Here, we propose a novel multi-dataset training paradigm, MultiTrain, with the design of two new loss terms, namely informative loss and projection loss, aiming to learn robust representations for action recognition. In particular, the informative loss maximizes the expressiveness of the feature embedding while the projection loss for each dataset mines the intrinsic relations between classes across datasets. We verify the effectiveness of our method on five challenging datasets, Kinetics-400, Kinetics-700, Moments-in-Time, Activitynet and Something-something-v2 datasets. Extensive experimental results show that our method can consistently improve the state-of-the-art performance.
Graph2Vid: Flow graph to Video Grounding forWeakly-supervised Multi-Step Localization
Oct 10, 2022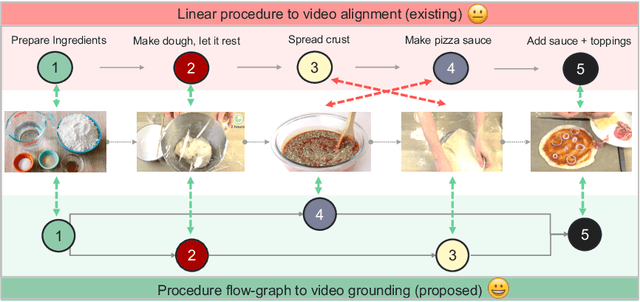
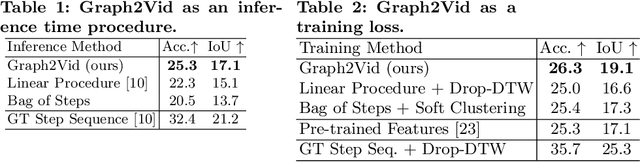

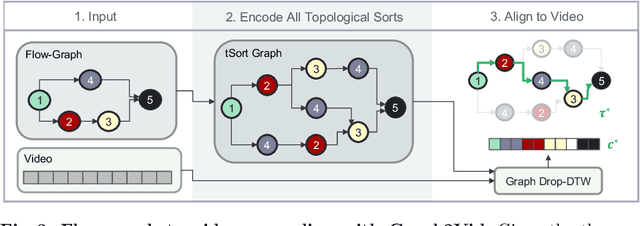
In this work, we consider the problem of weakly-supervised multi-step localization in instructional videos. An established approach to this problem is to rely on a given list of steps. However, in reality, there is often more than one way to execute a procedure successfully, by following the set of steps in slightly varying orders. Thus, for successful localization in a given video, recent works require the actual order of procedure steps in the video, to be provided by human annotators at both training and test times. Instead, here, we only rely on generic procedural text that is not tied to a specific video. We represent the various ways to complete the procedure by transforming the list of instructions into a procedure flow graph which captures the partial order of steps. Using the flow graphs reduces both training and test time annotation requirements. To this end, we introduce the new problem of flow graph to video grounding. In this setup, we seek the optimal step ordering consistent with the procedure flow graph and a given video. To solve this problem, we propose a new algorithm - Graph2Vid - that infers the actual ordering of steps in the video and simultaneously localizes them. To show the advantage of our proposed formulation, we extend the CrossTask dataset with procedure flow graph information. Our experiments show that Graph2Vid is both more efficient than the baselines and yields strong step localization results, without the need for step order annotation.
* ECCV'22, oral
Latent Space Unsupervised Semantic Segmentation
Jul 22, 2022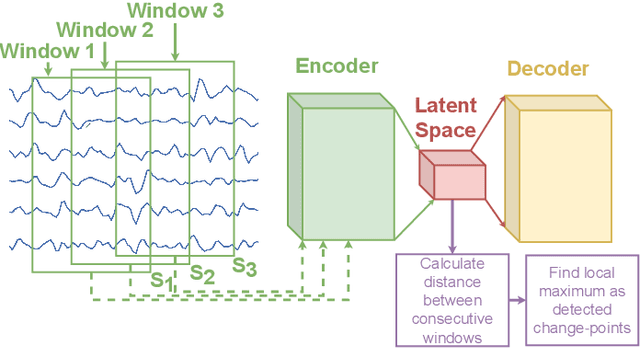
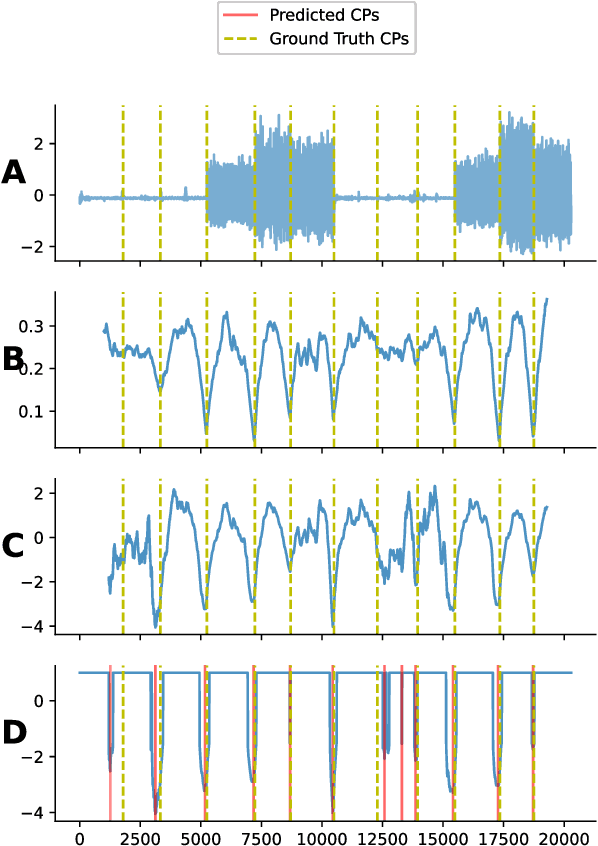
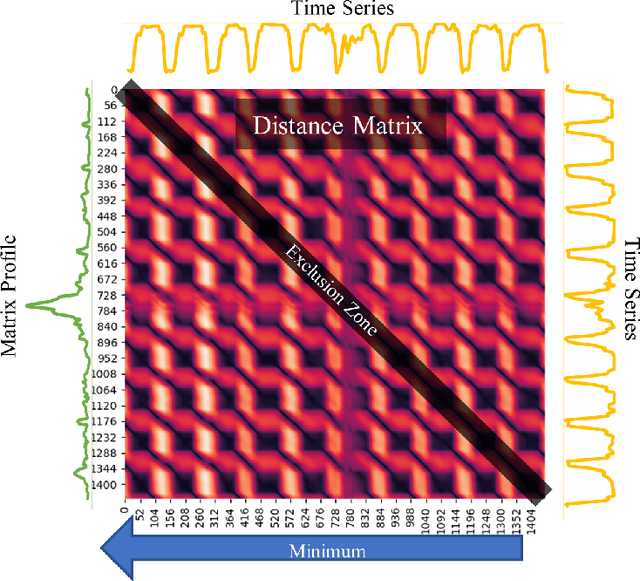
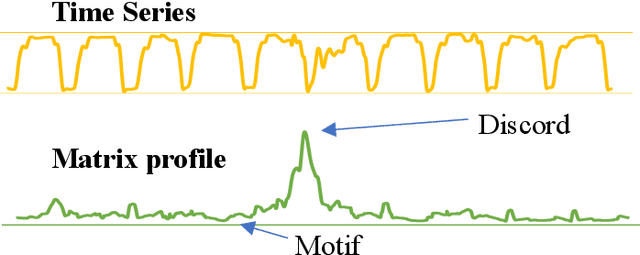
The development of compact and energy-efficient wearable sensors has led to an increase in the availability of biosignals. To analyze these continuously recorded, and often multidimensional, time series at scale, being able to conduct meaningful unsupervised data segmentation is an auspicious target. A common way to achieve this is to identify change-points within the time series as the segmentation basis. However, traditional change-point detection algorithms often come with drawbacks, limiting their real-world applicability. Notably, they generally rely on the complete time series to be available and thus cannot be used for real-time applications. Another common limitation is that they poorly (or cannot) handle the segmentation of multidimensional time series. Consequently, the main contribution of this work is to propose a novel unsupervised segmentation algorithm for multidimensional time series named Latent Space Unsupervised Semantic Segmentation (LS-USS), which was designed to work easily with both online and batch data. When comparing LS-USS against other state-of-the-art change-point detection algorithms on a variety of real-world datasets, in both the offline and real-time setting, LS-USS systematically achieves on par or better performances.
On Text Style Transfer via Style Masked Language Models
Oct 12, 2022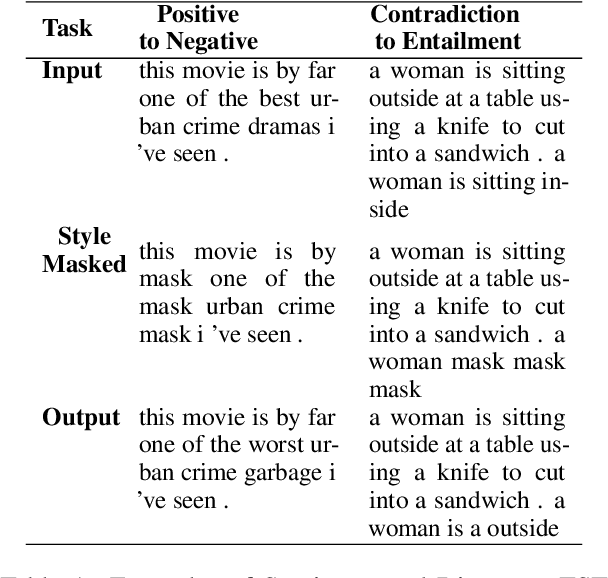
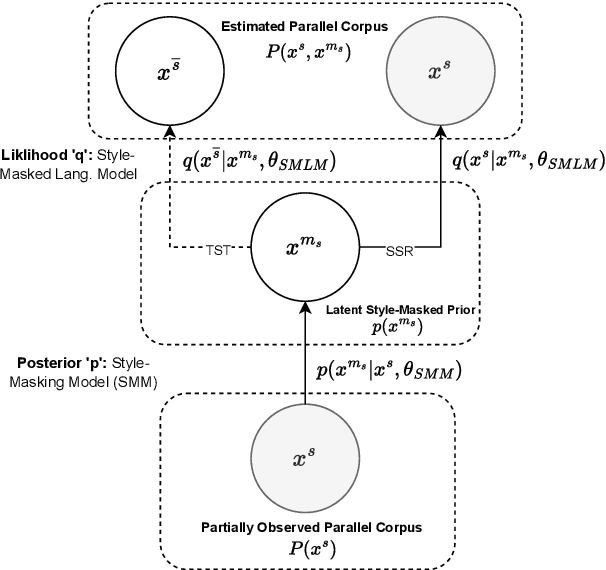
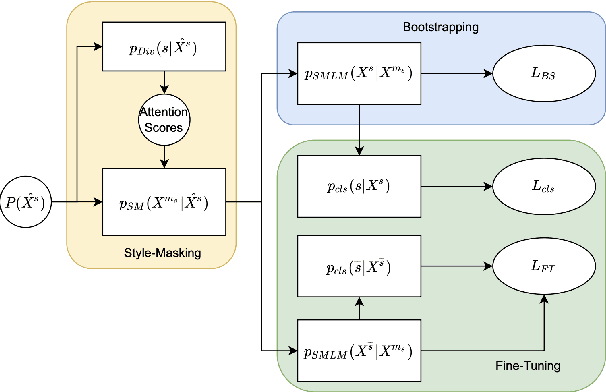
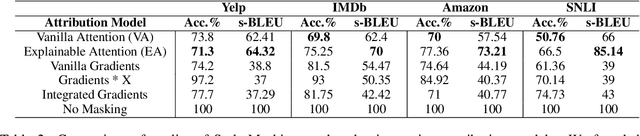
Text Style Transfer (TST) is performable through approaches such as latent space disentanglement, cycle-consistency losses, prototype editing etc. The prototype editing approach, which is known to be quite successful in TST, involves two key phases a) Masking of source style-associated tokens and b) Reconstruction of this source-style masked sentence conditioned with the target style. We follow a similar transduction method, in which we transpose the more difficult direct source to target TST task to a simpler Style-Masked Language Model (SMLM) Task, wherein, similar to BERT \cite{bert}, the goal of our model is now to reconstruct the source sentence from its style-masked version. We arrive at the SMLM mechanism naturally by formulating prototype editing/ transduction methods in a probabilistic framework, where TST resolves into estimating a hypothetical parallel dataset from a partially observed parallel dataset, wherein each domain is assumed to have a common latent style-masked prior. To generate this style-masked prior, we use "Explainable Attention" as our choice of attribution for a more precise style-masking step and also introduce a cost-effective and accurate "Attribution-Surplus" method of determining the position of masks from any arbitrary attribution model in O(1) time. We empirically show that this non-generational approach well suites the "content preserving" criteria for a task like TST, even for a complex style like Discourse Manipulation. Our model, the Style MLM, outperforms strong TST baselines and is on par with state-of-the-art TST models, which use complex architectures and orders of more parameters.
Parallel Spatio-Temporal Attention-Based TCN for Multivariate Time Series Prediction
Mar 02, 2022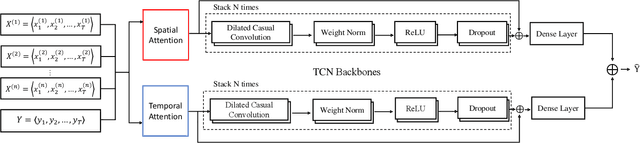
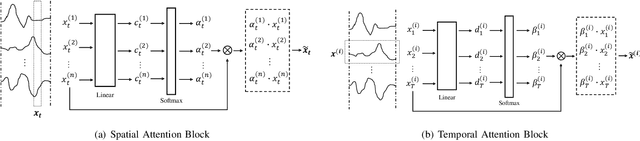

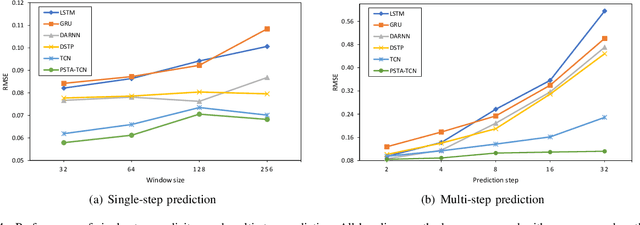
As industrial systems become more complex and monitoring sensors for everything from surveillance to our health become more ubiquitous, multivariate time series prediction is taking an important place in the smooth-running of our society. A recurrent neural network with attention to help extend the prediction windows is the current-state-of-the-art for this task. However, we argue that their vanishing gradients, short memories, and serial architecture make RNNs fundamentally unsuited to long-horizon forecasting with complex data. Temporal convolutional networks (TCNs) do not suffer from gradient problems and they support parallel calculations, making them a more appropriate choice. Additionally, they have longer memories than RNNs, albeit with some instability and efficiency problems. Hence, we propose a framework, called PSTA-TCN, that combines a parallel spatio-temporal attention mechanism to extract dynamic internal correlations with stacked TCN backbones to extract features from different window sizes. The framework makes full use parallel calculations to dramatically reduce training times, while substantially increasing accuracy with stable prediction windows up to 13 times longer than the status quo.
Out-of-Distribution Detection and Selective Generation for Conditional Language Models
Sep 30, 2022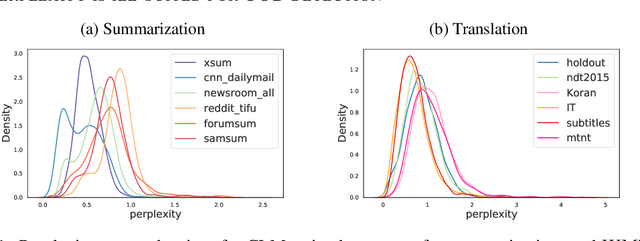
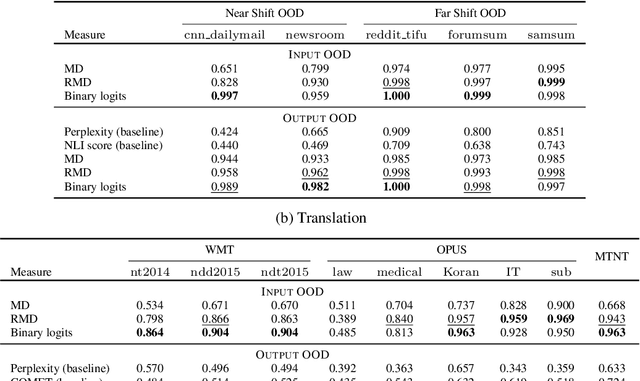
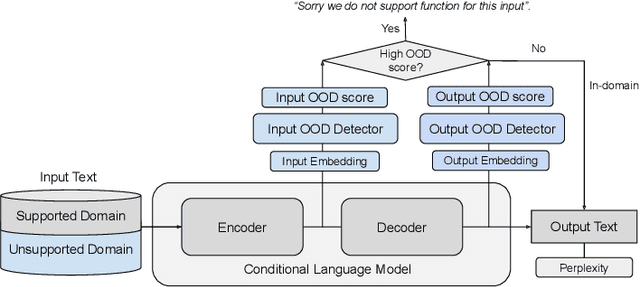
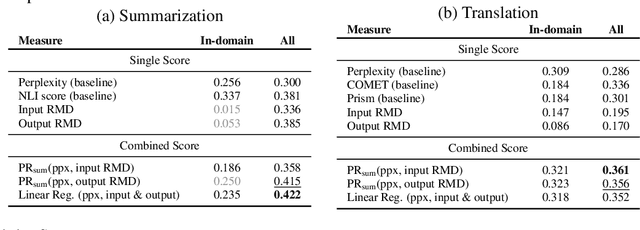
Machine learning algorithms typically assume independent and identically distributed samples in training and at test time. Much work has shown that high-performing ML classifiers can degrade significantly and provide overly-confident, wrong classification predictions, particularly for out-of-distribution (OOD) inputs. Conditional language models (CLMs) are predominantly trained to classify the next token in an output sequence, and may suffer even worse degradation on OOD inputs as the prediction is done auto-regressively over many steps. Furthermore, the space of potential low-quality outputs is larger as arbitrary text can be generated and it is important to know when to trust the generated output. We present a highly accurate and lightweight OOD detection method for CLMs, and demonstrate its effectiveness on abstractive summarization and translation. We also show how our method can be used under the common and realistic setting of distribution shift for selective generation (analogous to selective prediction for classification) of high-quality outputs, while automatically abstaining from low-quality ones, enabling safer deployment of generative language models.