 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph2Vid: Flow graph to Video Grounding forWeakly-supervised Multi-Step Localization
Paper and Code
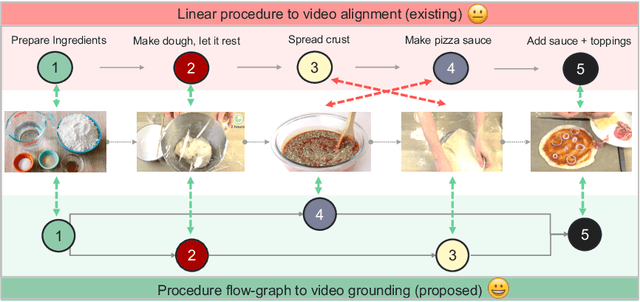
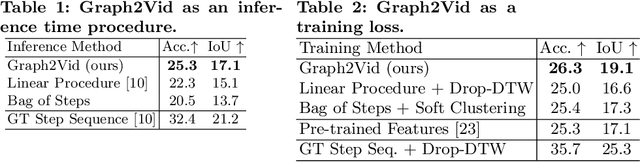

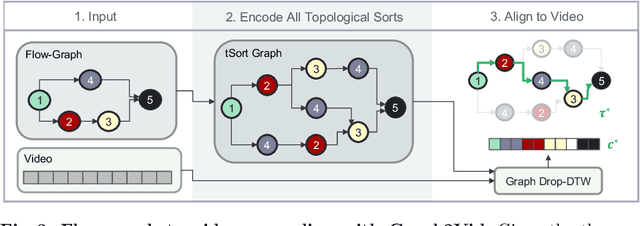
In this work, we consider the problem of weakly-supervised multi-step localization in instructional videos. An established approach to this problem is to rely on a given list of steps. However, in reality, there is often more than one way to execute a procedure successfully, by following the set of steps in slightly varying orders. Thus, for successful localization in a given video, recent works require the actual order of procedure steps in the video, to be provided by human annotators at both training and test times. Instead, here, we only rely on generic procedural text that is not tied to a specific video. We represent the various ways to complete the procedure by transforming the list of instructions into a procedure flow graph which captures the partial order of steps. Using the flow graphs reduces both training and test time annotation requirements. To this end, we introduce the new problem of flow graph to video grounding. In this setup, we seek the optimal step ordering consistent with the procedure flow graph and a given video. To solve this problem, we propose a new algorithm - Graph2Vid - that infers the actual ordering of steps in the video and simultaneously localizes them. To show the advantage of our proposed formulation, we extend the CrossTask dataset with procedure flow graph information. Our experiments show that Graph2Vid is both more efficient than the baselines and yields strong step localization results, without the need for step order annotation.