 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust and Explainable Autoencoders for Unsupervised Time Series Outlier Detection---Extended Version
Apr 07, 2022

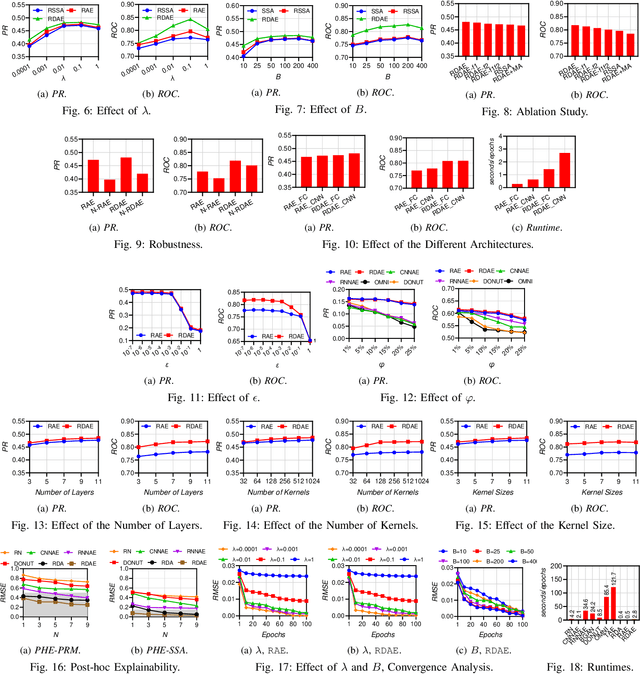

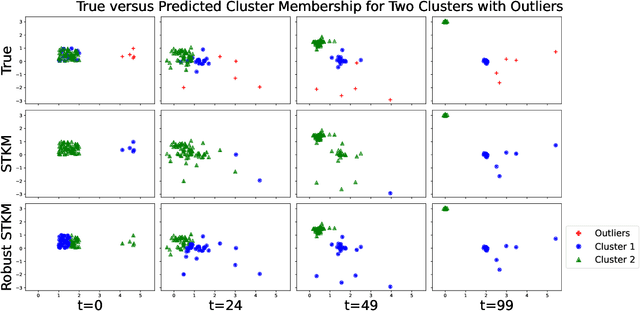
Time series data occurs widely, and outlier detection is a fundamental problem in data mining, which has numerous applications. Existing autoencoder-based approaches deliver state-of-the-art performance on challenging real-world data but are vulnerable to outliers and exhibit low explainability. To address these two limitations, we propose robust and explainable unsupervised autoencoder frameworks that decompose an input time series into a clean time series and an outlier time series using autoencoders. Improved explainability is achieved because clean time series are better explained with easy-to-understand patterns such as trends and periodicities. We provide insight into this by means of a post-hoc explainability analysis and empirical studies. In addition, since outliers are separated from clean time series iteratively, our approach offers improved robustness to outliers, which in turn improves accuracy. We evaluate our approach on five real-world datasets and report improvements over the state-of-the-art approaches in terms of robustness and explainability. This is an extended version of "Robust and Explainable Autoencoders for Unsupervised Time Series Outlier Detection", to appear in IEEE ICDE 2022.
Spatial-Temporal Synchronous Graph Transformer network (STSGT) for COVID-19 forecasting
Oct 31, 2022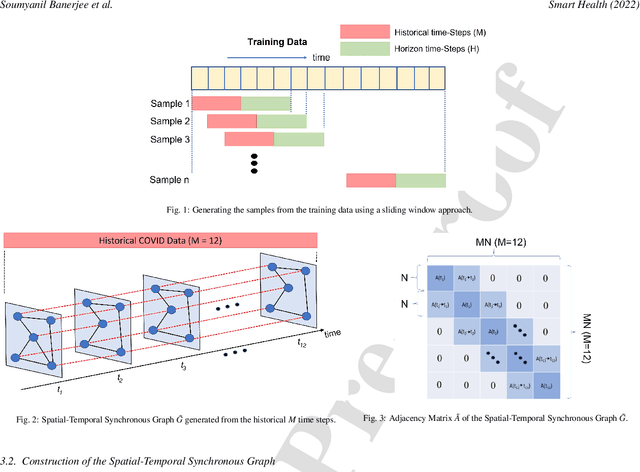
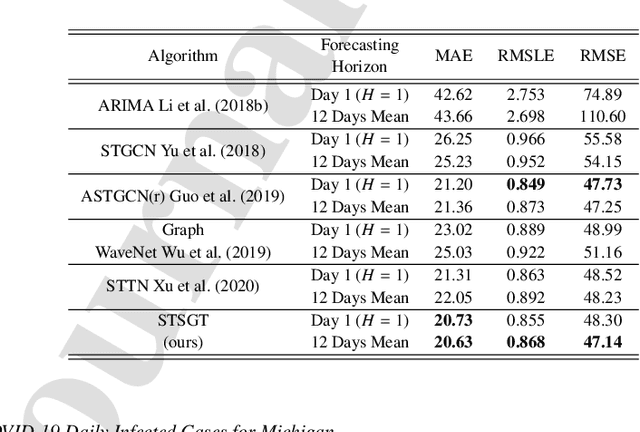
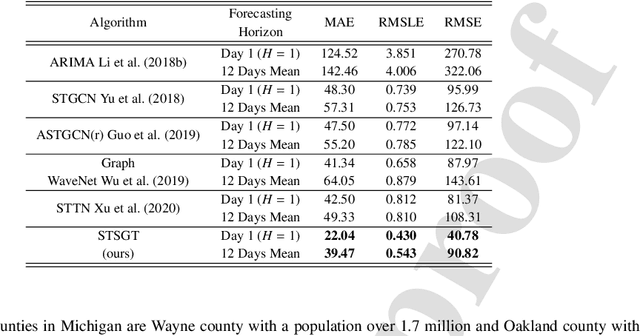
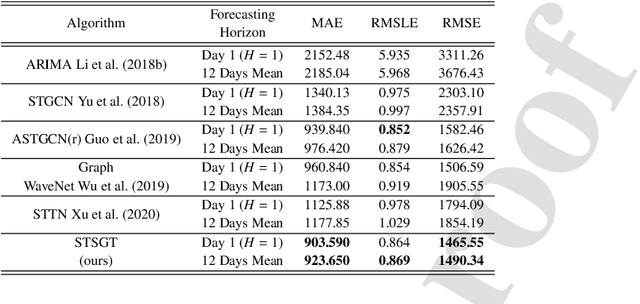
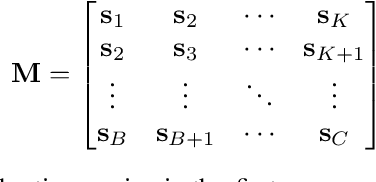
COVID-19 has become a matter of serious concern over the last few years. It has adversely affected numerous people around the globe and has led to the loss of billions of dollars of business capital. In this paper, we propose a novel Spatial-Temporal Synchronous Graph Transformer network (STSGT) to capture the complex spatial and temporal dependency of the COVID-19 time series data and forecast the future status of an evolving pandemic. The layers of STSGT combine the graph convolution network (GCN) with the self-attention mechanism of transformers on a synchronous spatial-temporal graph to capture the dynamically changing pattern of the COVID time series. The spatial-temporal synchronous graph simultaneously captures the spatial and temporal dependencies between the vertices of the graph at a given and subsequent time-steps, which helps capture the heterogeneity in the time series and improve the forecasting accuracy. Our extensive experiments on two publicly available real-world COVID-19 time series datasets demonstrate that STSGT significantly outperforms state-of-the-art algorithms that were designed for spatial-temporal forecasting tasks. Specifically, on average over a 12-day horizon, we observe a potential improvement of 12.19% and 3.42% in Mean Absolute Error(MAE) over the next best algorithm while forecasting the daily infected and death cases respectively for the 50 states of US and Washington, D.C. Additionally, STSGT also outperformed others when forecasting the daily infected cases at the state level, e.g., for all the counties in the State of Michigan. The code and models are publicly available at https://github.com/soumbane/STSGT.
A noise based novel strategy for faster SNN training
Nov 10, 2022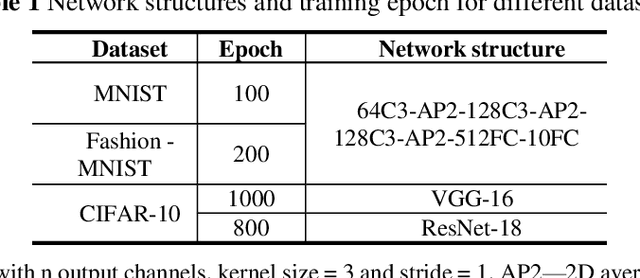
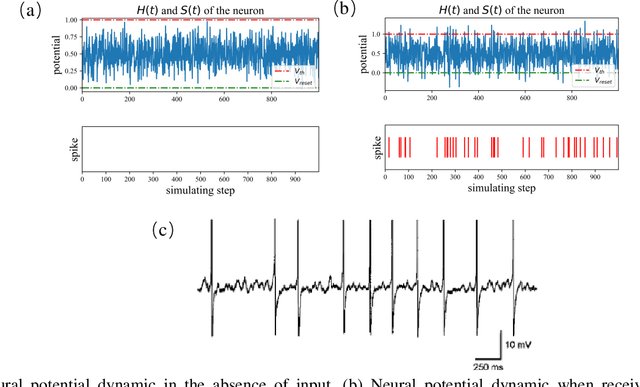
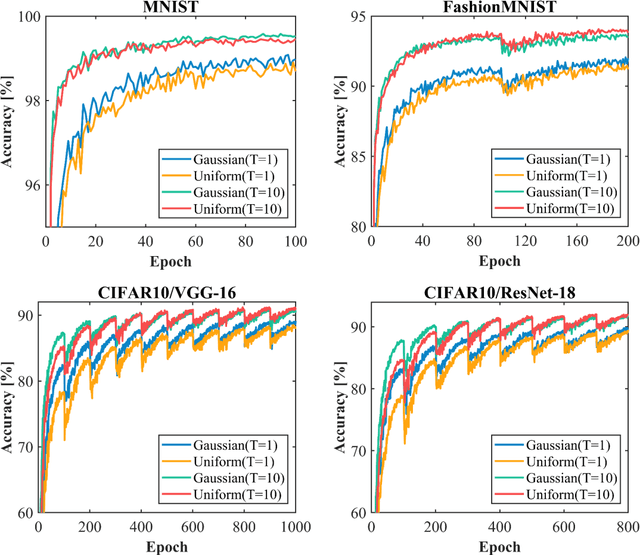
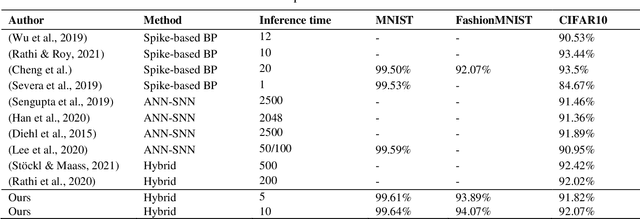
Spiking neural networks (SNNs) are receiving increasing attention due to their low power consumption and strong bio-plausibility. Optimization of SNNs is a challenging task. Two main methods, artificial neural network (ANN)-to-SNN conversion and spike-based backpropagation (BP), both have their advantages and limitations. For ANN-to-SNN conversion, it requires a long inference time to approximate the accuracy of ANN, thus diminishing the benefits of SNN. With spike-based BP, training high-precision SNNs typically consumes dozens of times more computational resources and time than their ANN counterparts. In this paper, we propose a novel SNN training approach that combines the benefits of the two methods. We first train a single-step SNN by approximating the neural potential distribution with random noise, then convert the single-step SNN to a multi-step SNN losslessly. The introduction of Gaussian distributed noise leads to a significant gain in accuracy after conversion. The results show that our method considerably reduces the training and inference times of SNNs while maintaining their high accuracy. Compared to the previous two methods, ours can reduce training time by 65%-75% and achieves more than 100 times faster inference speed. We also argue that the neuron model augmented with noise makes it more bio-plausible.
4DVarNet-SSH: end-to-end learning of variational interpolation schemes for nadir and wide-swath satellite altimetry
Nov 10, 2022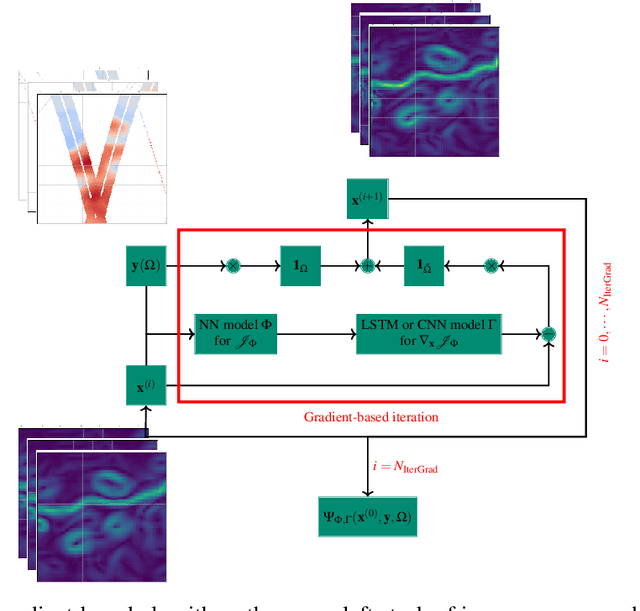

The reconstruction of sea surface currents from satellite altimeter data is a key challenge in spatial oceanography, especially with the upcoming wide-swath SWOT (Surface Ocean and Water Topography) altimeter mission. Operational systems however generally fail to retrieve mesoscale dynamics for horizontal scales below 100km and time-scale below 10 days. Here, we address this challenge through the 4DVarnet framework, an end-to-end neural scheme backed on a variational data assimilation formulation. We introduce a parametrization of the 4DVarNet scheme dedicated to the space-time interpolation of satellite altimeter data. Within an observing system simulation experiment (NATL60), we demonstrate the relevance of the proposed approach both for nadir and nadir+swot altimeter configurations for two contrasted case-study regions in terms of upper ocean dynamics. We report relative improvement with respect to the operational optimal interpolation between 30% and 60% in terms of reconstruction error. Interestingly, for the nadir+swot altimeter configuration, we reach resolved space-time scales below 70km and 7days. The code is open-source to enable reproductibility and future collaborative developments. Beyond its applicability to large-scale domains, we also address uncertainty quantification issues and generalization properties of the proposed learning setting. We discuss further future research avenues and extensions to other ocean data assimilation and space oceanography challenges.
Spatiotemporal k-means
Nov 10, 2022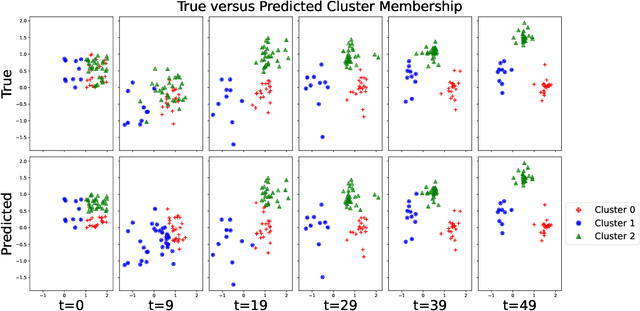

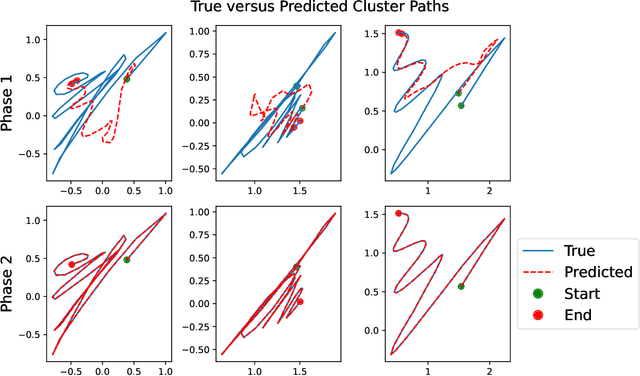
Spatiotemporal data is readily available due to emerging sensor and data acquisition technologies that track the positions of moving objects of interest. Spatiotemporal clustering addresses the need to efficiently discover patterns and trends in moving object behavior without human supervision. One application of interest is the discovery of moving clusters, where clusters have a static identity, but their location and content can change over time. We propose a two phase spatiotemporal clustering method called spatiotemporal k-means (STKM) that is able to analyze the multi-scale relationships within spatiotemporal data. Phase 1 of STKM frames the moving cluster problem as the minimization of an objective function unified over space and time. It outputs the short-term associations between objects and is uniquely able to track dynamic cluster centers with minimal parameter tuning and without post-processing. Phase 2 outputs the long-term associations and can be applied to any method that provides a cluster label for each object at every point in time. We evaluate STKM against baseline methods on a recently developed benchmark dataset and show that STKM outperforms existing methods, particularly in the low-data domain, with significant performance improvements demonstrated for common evaluation metrics on the moving cluster problem.
Online Learning-based Waveform Selection for Improved Vehicle Recognition in Automotive Radar
Dec 01, 2022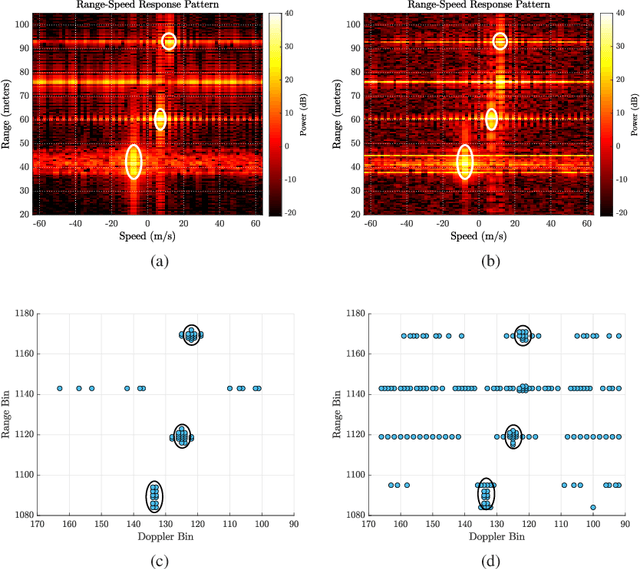
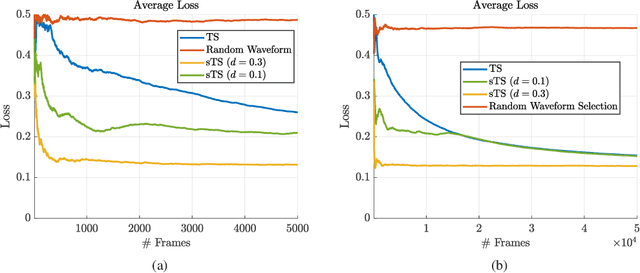
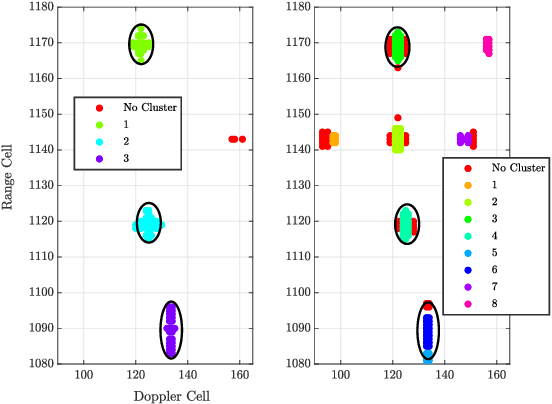
This paper describes important considerations and challenges associated with online reinforcement-learning based waveform selection for target identification in frequency modulated continuous wave (FMCW) automotive radar systems. We present a novel learning approach based on satisficing Thompson sampling, which quickly identifies a waveform expected to yield satisfactory classification performance. We demonstrate through measurement-level simulations that effective waveform selection strategies can be quickly learned, even in cases where the radar must select from a large catalog of candidate waveforms. The radar learns to adaptively select a bandwidth for appropriate resolution and a slow-time unimodular code for interference mitigation in the scene of interest by optimizing an expected classification metric.
A Comprehensive Study on Machine Learning Methods to Increase the Prediction Accuracy of Classifiers and Reduce the Number of Medical Tests Required to Diagnose Alzheimer'S Disease
Dec 01, 2022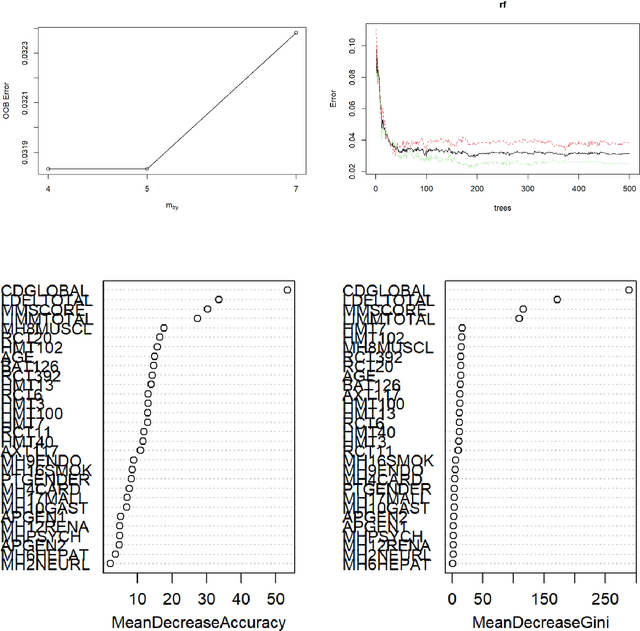
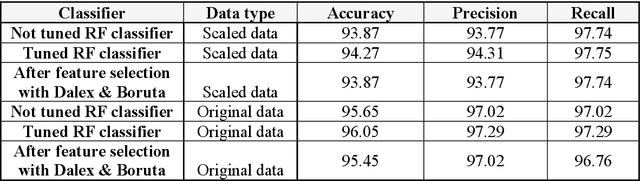
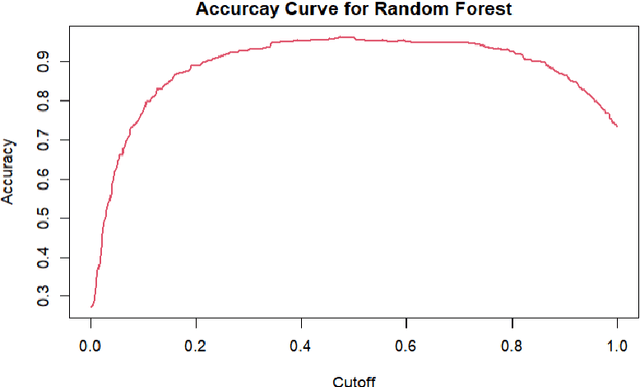
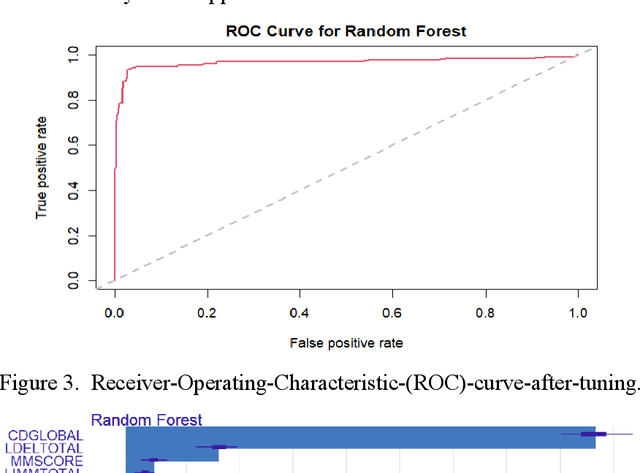
Alzheimer's patients gradually lose their ability to think, behave, and interact with others. Medical history, laboratory tests, daily activities, and personality changes can all be used to diagnose the disorder. A series of time-consuming and expensive tests are used to diagnose the illness. The most effective way to identify Alzheimer's disease is using a Random-forest classifier in this study, along with various other Machine Learning techniques. The main goal of this study is to fine-tune the classifier to detect illness with fewer tests while maintaining a reasonable disease discovery accuracy. We successfully identified the condition in almost 94% of cases using four of the thirty frequently utilized indicators.
Unseen Object Instance Segmentation with Fully Test-time RGB-D Embeddings Adaptation
Apr 21, 2022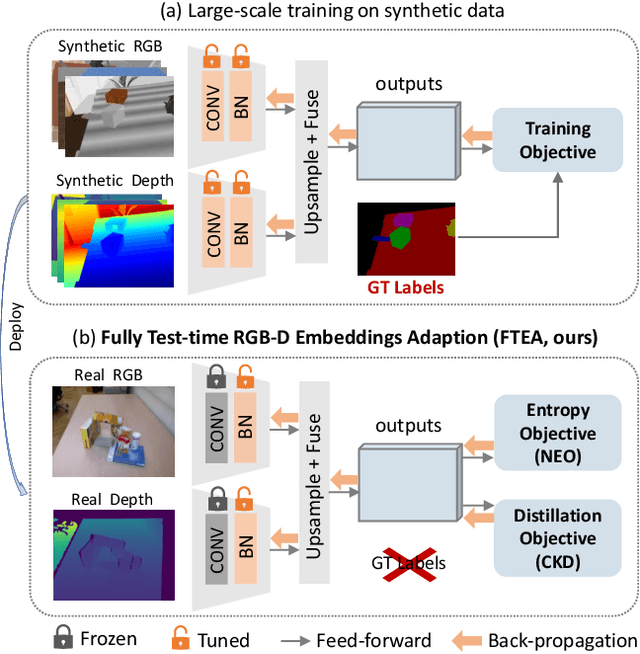
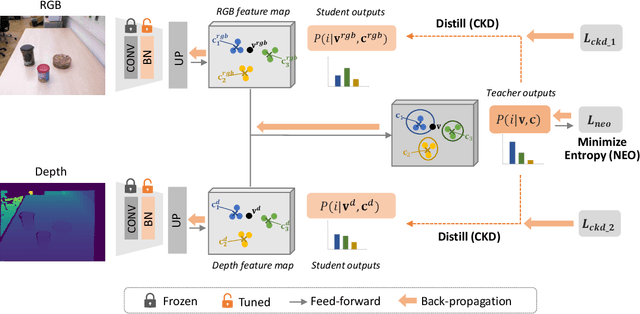
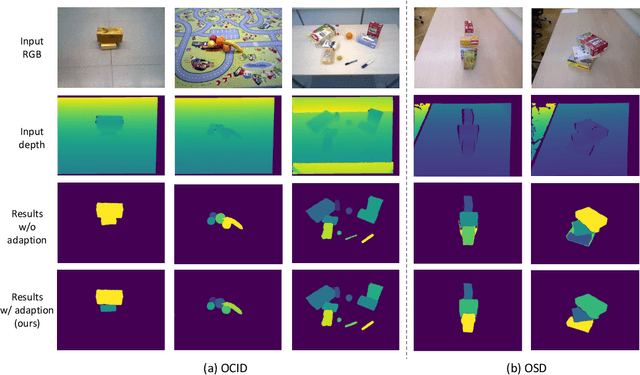
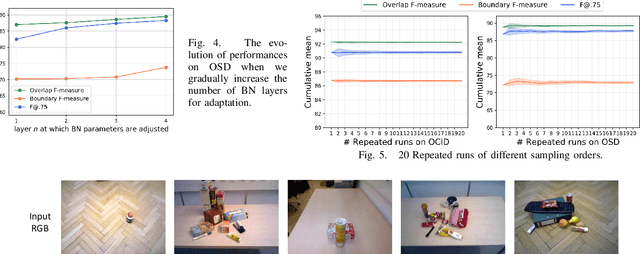
Segmenting unseen objects is a crucial ability for the robot since it may encounter new environments during the operation. Recently, a popular solution is leveraging RGB-D features of large-scale synthetic data and directly applying the model to unseen real-world scenarios. However, even though depth data have fair generalization ability, the domain shift due to the Sim2Real gap is inevitable, which presents a key challenge to the unseen object instance segmentation (UOIS) model. To tackle this problem, we re-emphasize the adaptation process across Sim2Real domains in this paper. Specifically, we propose a framework to conduct the Fully Test-time RGB-D Embeddings Adaptation (FTEA) based on parameters of the BatchNorm layer. To construct the learning objective for test-time back-propagation, we propose a novel non-parametric entropy objective that can be implemented without explicit classification layers. Moreover, we design a cross-modality knowledge distillation module to encourage the information transfer during test time. The proposed method can be efficiently conducted with test-time images, without requiring annotations or revisiting the large-scale synthetic training data. Besides significant time savings, the proposed method consistently improves segmentation results on both overlap and boundary metrics, achieving state-of-the-art performances on two real-world RGB-D image datasets. We hope our work could draw attention to the test-time adaptation and reveal a promising direction for robot perception in unseen environments.
ElegantSeg: End-to-End Holistic Learning for Extra-Large Image Semantic Segmentation
Nov 21, 2022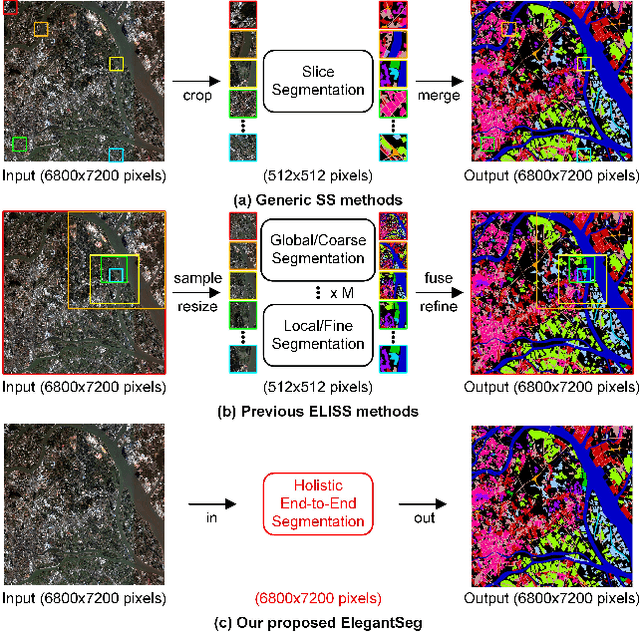
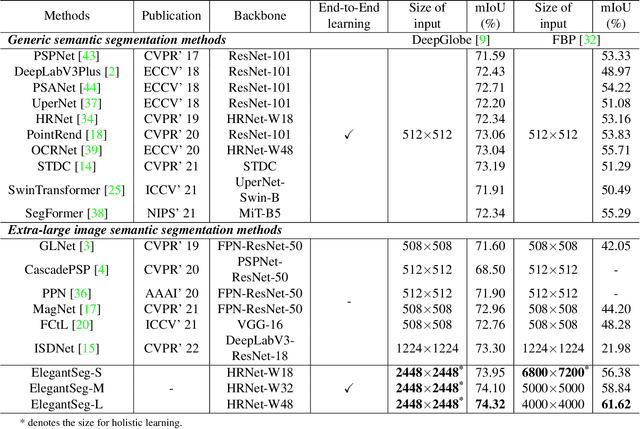


This paper presents a new paradigm for Extra-large image semantic Segmentation, called ElegantSeg, that capably processes holistic extra-large image semantic segmentation (ELISS). The extremely large sizes of extra-large images (ELIs) tend to cause GPU memory exhaustion. To tackle this issue, prevailing works either follow the global-local fusion pipeline or conduct the multi-stage refinement. These methods can only process limited information at one time, and they are not able to thoroughly exploit the abundant information in ELIs. Unlike previous methods, ElegantSeg can elegantly process holistic ELISS by extending the tensor storage from GPU memory to host memory. To the best of our knowledge, it is the first time that ELISS can be performed holistically. Besides, ElegantSeg is specifically designed with three modules to utilize the characteristics of ELIs, including the multiple large kernel module for developing long-range dependency, the efficient class relation module for building holistic contextual relationships, and the boundary-aware enhancement module for obtaining complete object boundaries. ElegantSeg outperforms previous state-of-the-art on two typical ELISS datasets. We hope that ElegantSeg can open a new perspective for ELISS. The code and models will be made publicly available.
A Graph Regularized Point Process Model For Event Propagation Sequence
Nov 21, 2022
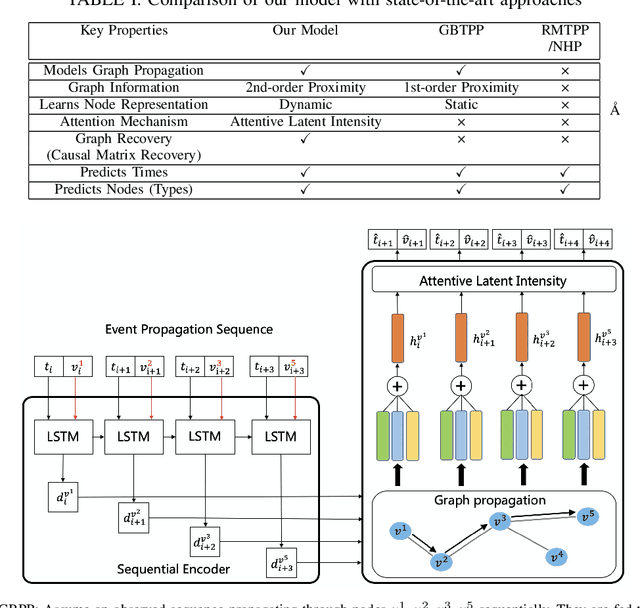
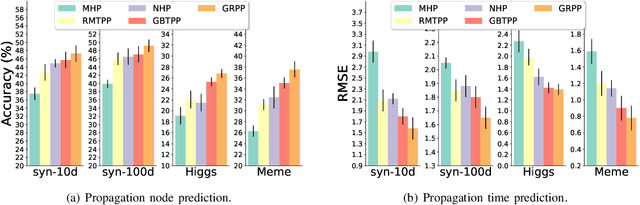
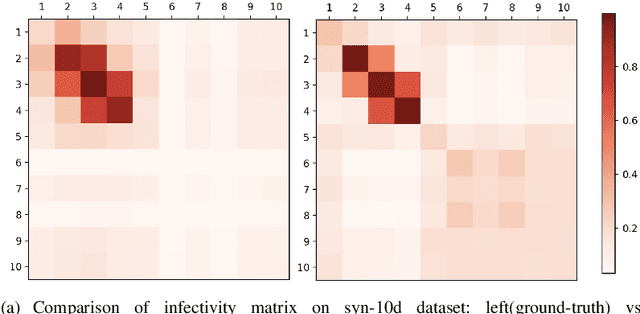
Point process is the dominant paradigm for modeling event sequences occurring at irregular intervals. In this paper we aim at modeling latent dynamics of event propagation in graph, where the event sequence propagates in a directed weighted graph whose nodes represent event marks (e.g., event types). Most existing works have only considered encoding sequential event history into event representation and ignored the information from the latent graph structure. Besides they also suffer from poor model explainability, i.e., failing to uncover causal influence across a wide variety of nodes. To address these problems, we propose a Graph Regularized Point Process (GRPP) that can be decomposed into: 1) a graph propagation model that characterizes the event interactions across nodes with neighbors and inductively learns node representations; 2) a temporal attentive intensity model, whose excitation and time decay factors of past events on the current event are constructed via the contextualization of the node embedding. Moreover, by applying a graph regularization method, GRPP provides model interpretability by uncovering influence strengths between nodes. Numerical experiments on various datasets show that GRPP outperforms existing models on both the propagation time and node prediction by notable margins.
* IJCNN 2021