 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CPGNet: Cascade Point-Grid Fusion Network for Real-Time LiDAR Semantic Segmentation
Apr 27, 2022
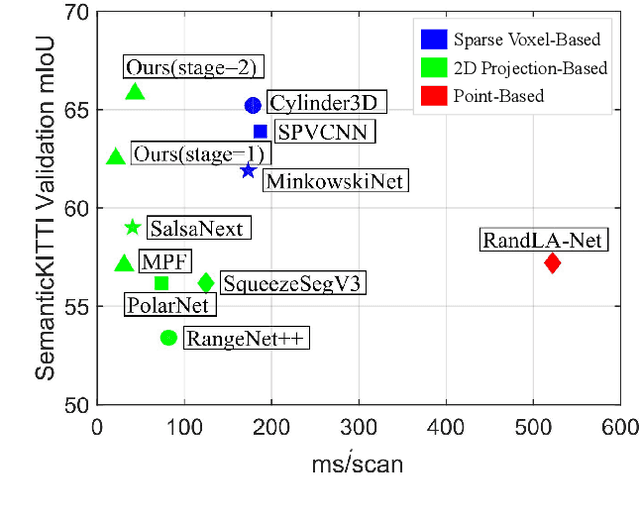
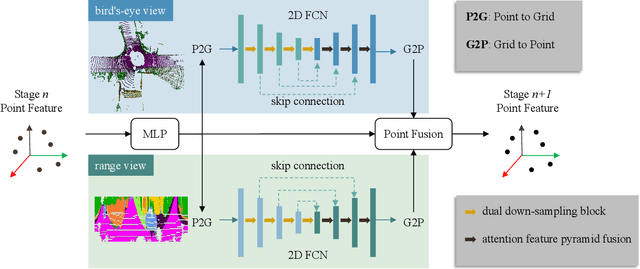
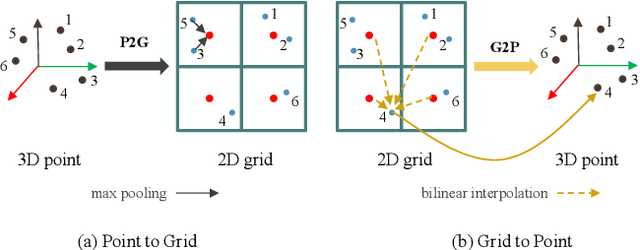
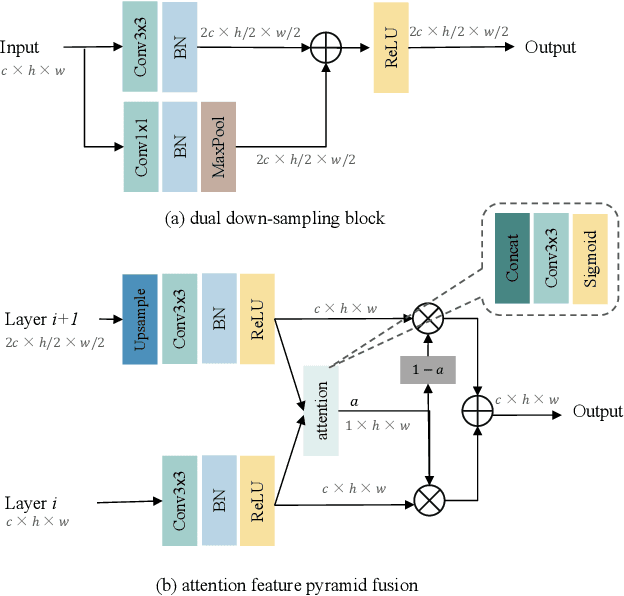
LiDAR semantic segmentation essential for advanced autonomous driving is required to be accurate, fast, and easy-deployed on mobile platforms. Previous point-based or sparse voxel-based methods are far away from real-time applications since time-consuming neighbor searching or sparse 3D convolution are employed. Recent 2D projection-based methods, including range view and multi-view fusion, can run in real time, but suffer from lower accuracy due to information loss during the 2D projection. Besides, to improve the performance, previous methods usually adopt test time augmentation (TTA), which further slows down the inference process. To achieve a better speed-accuracy trade-off, we propose Cascade Point-Grid Fusion Network (CPGNet), which ensures both effectiveness and efficiency mainly by the following two techniques: 1) the novel Point-Grid (PG) fusion block extracts semantic features mainly on the 2D projected grid for efficiency, while summarizes both 2D and 3D features on 3D point for minimal information loss; 2) the proposed transformation consistency loss narrows the gap between the single-time model inference and TTA. The experiments on the SemanticKITTI and nuScenes benchmarks demonstrate that the CPGNet without ensemble models or TTA is comparable with the state-of-the-art RPVNet, while it runs 4.7 times faster.
Learning Detail-Structure Alternative Optimization for Blind Super-Resolution
Dec 03, 2022



Existing convolutional neural networks (CNN) based image super-resolution (SR) methods have achieved impressive performance on bicubic kernel, which is not valid to handle unknown degradations in real-world applications. Recent blind SR methods suggest to reconstruct SR images relying on blur kernel estimation. However, their results still remain visible artifacts and detail distortion due to the estimation errors. To alleviate these problems, in this paper, we propose an effective and kernel-free network, namely DSSR, which enables recurrent detail-structure alternative optimization without blur kernel prior incorporation for blind SR. Specifically, in our DSSR, a detail-structure modulation module (DSMM) is built to exploit the interaction and collaboration of image details and structures. The DSMM consists of two components: a detail restoration unit (DRU) and a structure modulation unit (SMU). The former aims at regressing the intermediate HR detail reconstruction from LR structural contexts, and the latter performs structural contexts modulation conditioned on the learned detail maps at both HR and LR spaces. Besides, we use the output of DSMM as the hidden state and design our DSSR architecture from a recurrent convolutional neural network (RCNN) view. In this way, the network can alternatively optimize the image details and structural contexts, achieving co-optimization across time. Moreover, equipped with the recurrent connection, our DSSR allows low- and high-level feature representations complementary by observing previous HR details and contexts at every unrolling time. Extensive experiments on synthetic datasets and real-world images demonstrate that our method achieves the state-of-the-art against existing methods. The source code can be found at https://github.com/Arcananana/DSSR.
Adaptive Low-Precision Training for Embeddings in Click-Through Rate Prediction
Dec 12, 2022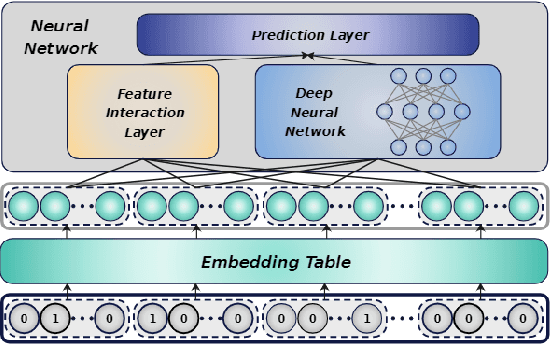
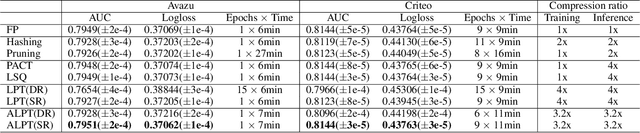
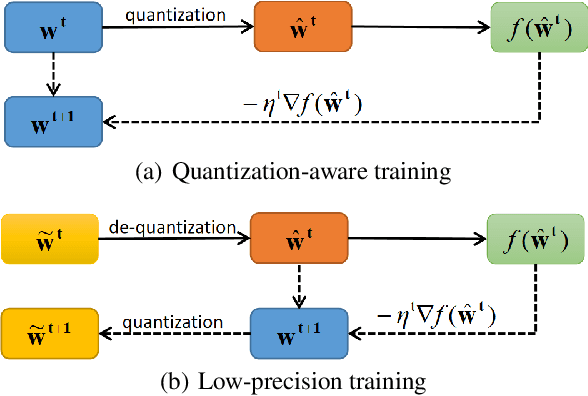
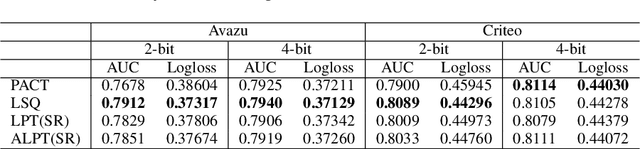
Embedding tables are usually huge in click-through rate (CTR) prediction models. To train and deploy the CTR models efficiently and economically, it is necessary to compress their embedding tables at the training stage. To this end, we formulate a novel quantization training paradigm to compress the embeddings from the training stage, termed low-precision training (LPT). Also, we provide theoretical analysis on its convergence. The results show that stochastic weight quantization has a faster convergence rate and a smaller convergence error than deterministic weight quantization in LPT. Further, to reduce the accuracy degradation, we propose adaptive low-precision training (ALPT) that learns the step size (i.e., the quantization resolution) through gradient descent. Experiments on two real-world datasets confirm our analysis and show that ALPT can significantly improve the prediction accuracy, especially at extremely low bit widths. For the first time in CTR models, we successfully train 8-bit embeddings without sacrificing prediction accuracy. The code of ALPT is publicly available.
SpeechNet: Weakly Supervised, End-to-End Speech Recognition at Industrial Scale
Nov 21, 2022
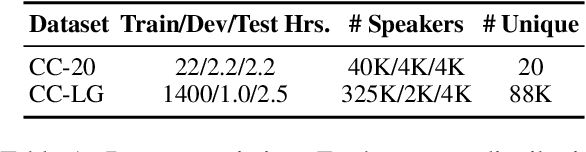
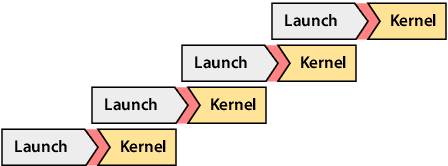
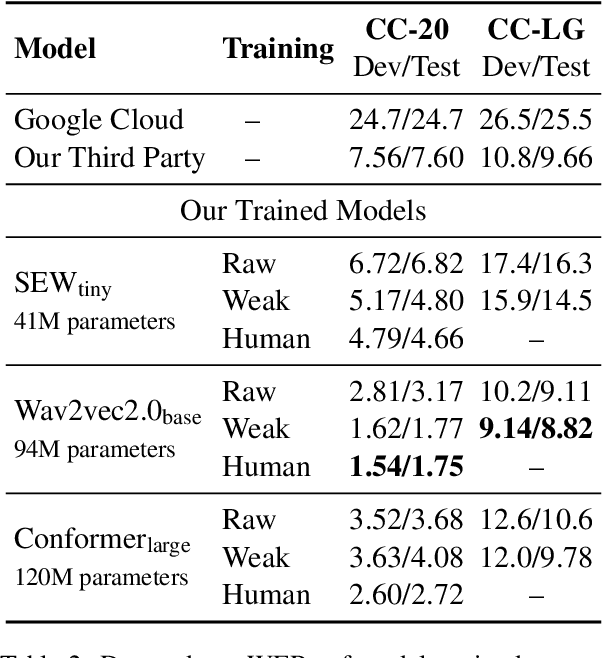
End-to-end automatic speech recognition systems represent the state of the art, but they rely on thousands of hours of manually annotated speech for training, as well as heavyweight computation for inference. Of course, this impedes commercialization since most companies lack vast human and computational resources. In this paper, we explore training and deploying an ASR system in the label-scarce, compute-limited setting. To reduce human labor, we use a third-party ASR system as a weak supervision source, supplemented with labeling functions derived from implicit user feedback. To accelerate inference, we propose to route production-time queries across a pool of CUDA graphs of varying input lengths, the distribution of which best matches the traffic's. Compared to our third-party ASR, we achieve a relative improvement in word-error rate of 8% and a speedup of 600%. Our system, called SpeechNet, currently serves 12 million queries per day on our voice-enabled smart television. To our knowledge, this is the first time a large-scale, Wav2vec-based deployment has been described in the academic literature.
Tensor4D : Efficient Neural 4D Decomposition for High-fidelity Dynamic Reconstruction and Rendering
Nov 21, 2022
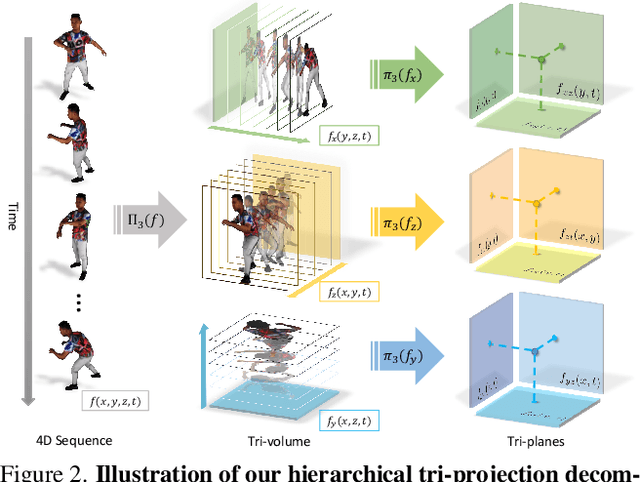
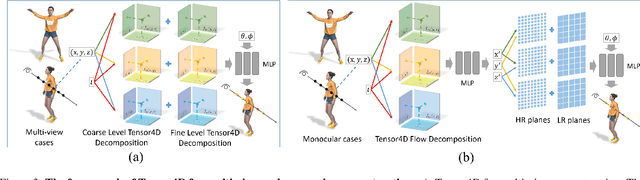
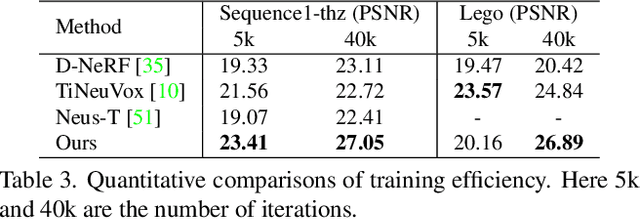
We present Tensor4D, an efficient yet effective approach to dynamic scene modeling. The key of our solution is an efficient 4D tensor decomposition method so that the dynamic scene can be directly represented as a 4D spatio-temporal tensor. To tackle the accompanying memory issue, we decompose the 4D tensor hierarchically by projecting it first into three time-aware volumes and then nine compact feature planes. In this way, spatial information over time can be simultaneously captured in a compact and memory-efficient manner. When applying Tensor4D for dynamic scene reconstruction and rendering, we further factorize the 4D fields to different scales in the sense that structural motions and dynamic detailed changes can be learned from coarse to fine. The effectiveness of our method is validated on both synthetic and real-world scenes. Extensive experiments show that our method is able to achieve high-quality dynamic reconstruction and rendering from sparse-view camera rigs or even a monocular camera. The code and dataset will be released at https://liuyebin.com/tensor4d/tensor4d.html.
Knowledge Retrieval for Robotic Cooking
Nov 16, 2022Search algorithms are applied where data retrieval with specified specifications is required. The motivation behind developing search algorithms in Functional Object-Oriented Networks is that most of the time, a certain recipe needs to be retrieved or ingredients for a certain recipe needs to be determined. According to the introduction, there is a time when execution of an entire recipe is not available for a robot thus prompting the need to retrieve a certain recipe or ingredients. With a quality FOON, robots can decipher a task goal, find the correct objects at the required states on which to operate and output a sequence of proper manipulation motions. This paper shows several proposed weighted FOON and task planning algorithms that allow a robot and a human to successfully complete complicated tasks together with higher success rates than a human doing them alone.
EvoSTS Forecasting: Evolutionary Sparse Time-Series Forecasting
Apr 14, 2022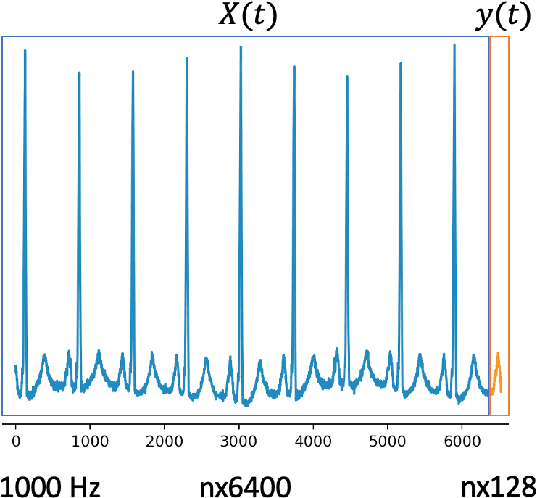
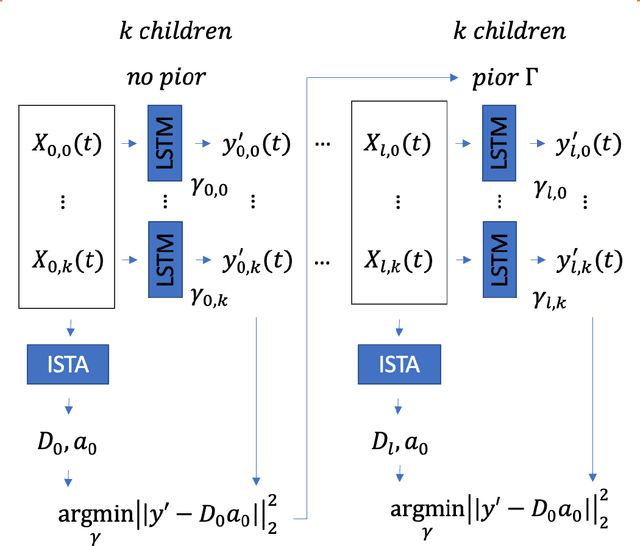

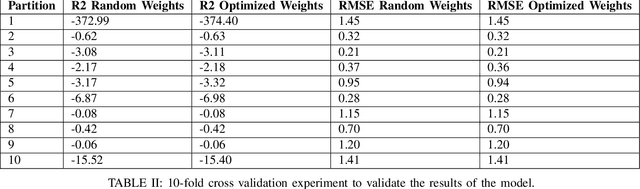
In this work, we highlight our novel evolutionary sparse time-series forecasting algorithm also known as EvoSTS. The algorithm attempts to evolutionary prioritize weights of Long Short-Term Memory (LSTM) Network that best minimize the reconstruction loss of a predicted signal using a learned sparse coded dictionary. In each generation of our evolutionary algorithm, a set number of children with the same initial weights are spawned. Each child undergoes a training step and adjusts their weights on the same data. Due to stochastic back-propagation, the set of children has a variety of weights with different levels of performance. The weights that best minimize the reconstruction loss with a given signal dictionary are passed to the next generation. The predictions from the best-performing weights of the first and last generation are compared. We found improvements while comparing the weights of these two generations. However, due to several confounding parameters and hyperparameter limitations, some of the weights had negligible improvements. To the best of our knowledge, this is the first attempt to use sparse coding in this way to optimize time series forecasting model weights, such as those of an LSTM network.
Bayesian Methods in Automated Vehicle's Car-following Uncertainties: Enabling Strategic Decision Making
Oct 25, 2022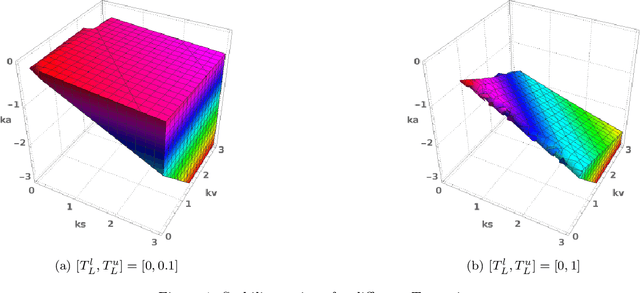

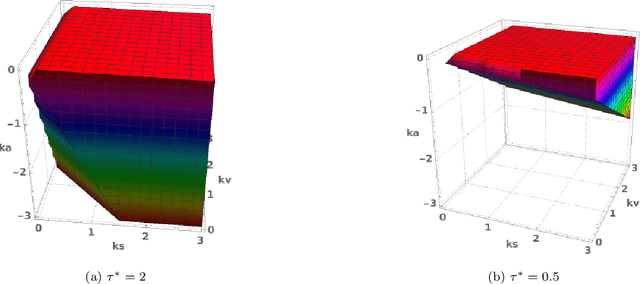

This paper proposes a methodology to estimate uncertainty in automated vehicle (AV) dynamics in real time via Bayesian inference. Based on the estimated uncertainty, the method aims to continuously monitor the car-following (CF) performance of the AV to support strategic actions to maintain a desired performance. Our methodology consists of three sequential components: (i) the Stochastic Gradient Langevin Dynamics (SGLD) is adopted to estimate parameter uncertainty relative to vehicular dynamics in real time, (ii) dynamic monitoring of car-following stability (local and string-wise), and (iii) strategic actions for control adjustment if anomaly is detected. The proposed methodology provides means to gauge AV car-following performance in real time and preserve desired performance against real time uncertainty that are unaccounted for in the vehicle control algorithm.
Hand gesture recognition using 802.11ad mmWave sensor in the mobile device
Nov 14, 2022

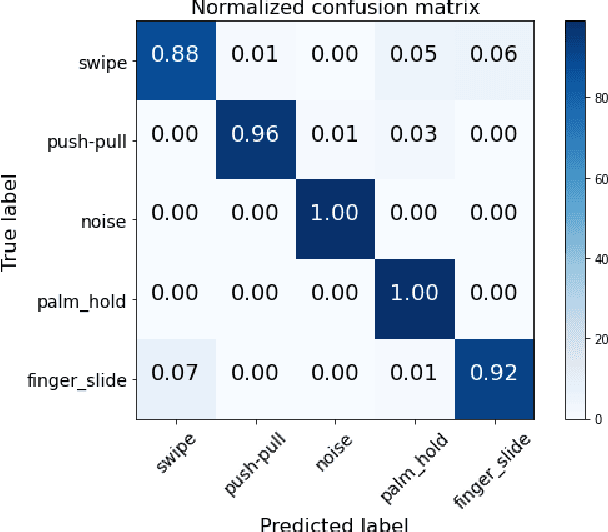
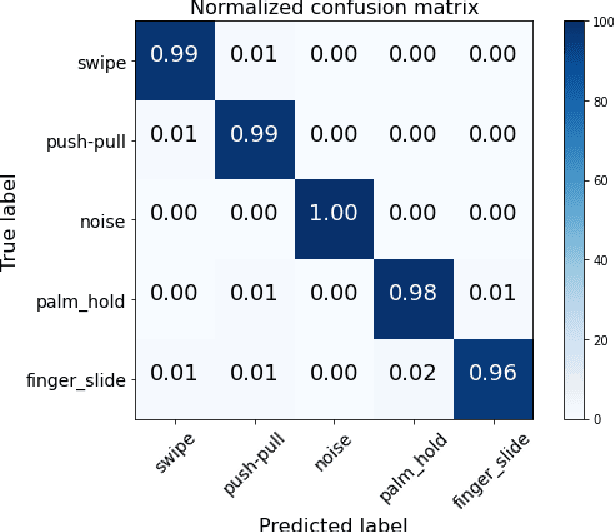
We explore the feasibility of AI assisted hand-gesture recognition using 802.11ad 60GHz (mmWave) technology in smartphones. Range-Doppler information (RDI) is obtained by using pulse Doppler radar for gesture recognition. We built a prototype system, where radar sensing and WLAN communication waveform can coexist by time-division duplex (TDD), to demonstrate the real-time hand-gesture inference. It can gather sensing data and predict gestures within 100 milliseconds. First, we build the pipeline for the real-time feature processing, which is robust to occasional frame drops in the data stream. RDI sequence restoration is implemented to handle the frame dropping in the continuous data stream, and also applied to data augmentation. Second, different gestures RDI are analyzed, where finger and hand motions can clearly show distinctive features. Third, five typical gestures (swipe, palm-holding, pull-push, finger-sliding and noise) are experimented with, and a classification framework is explored to segment the different gestures in the continuous gesture sequence with arbitrary inputs. We evaluate our architecture on a large multi-person dataset and report > 95% accuracy with one CNN + LSTM model. Further, a pure CNN model is developed to fit to on-device implementation, which minimizes the inference latency, power consumption and computation cost. And the accuracy of this CNN model is more than 93% with only 2.29K parameters.
* 6 pages, 12 figures
AI-enabled exploration of Instagram profiles predicts soft skills and personality traits to empower hiring decisions
Dec 24, 2022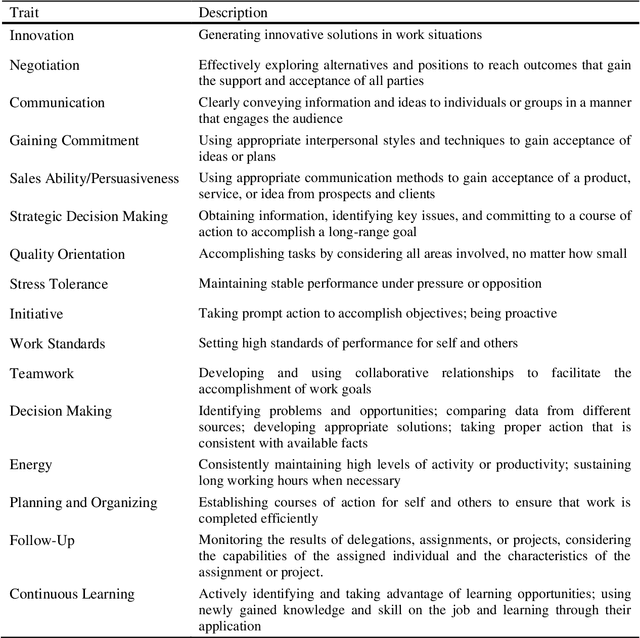
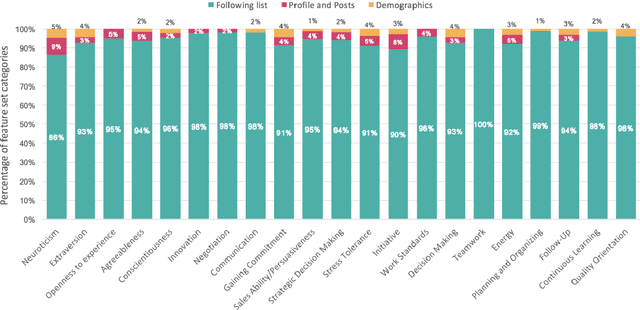
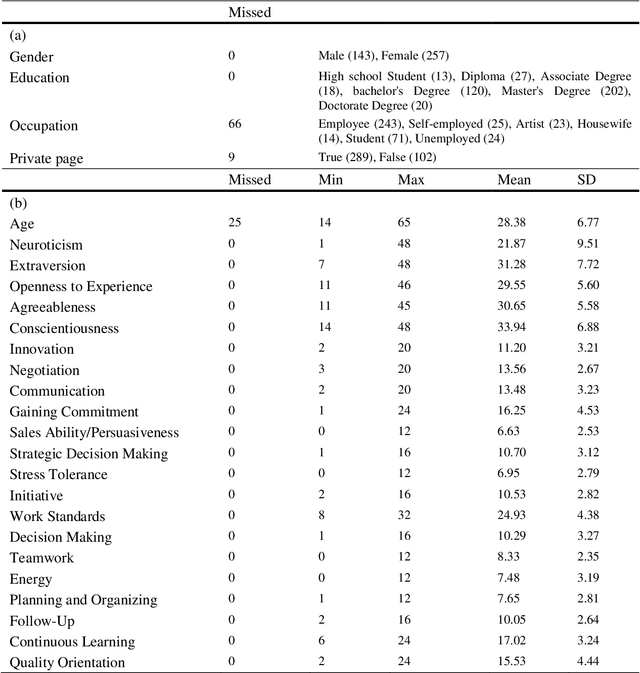
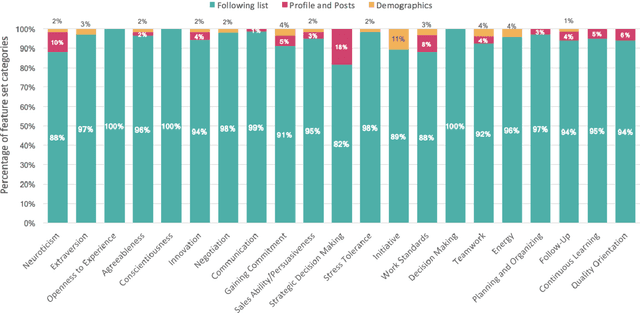
It does not matter whether it is a job interview with Tech Giants, Wall Street firms, or a small startup; all candidates want to demonstrate their best selves or even present themselves better than they really are. Meanwhile, recruiters want to know the candidates' authentic selves and detect soft skills that prove an expert candidate would be a great fit in any company. Recruiters worldwide usually struggle to find employees with the highest level of these skills. Digital footprints can assist recruiters in this process by providing candidates' unique set of online activities, while social media delivers one of the largest digital footprints to track people. In this study, for the first time, we show that a wide range of behavioral competencies consisting of 16 in-demand soft skills can be automatically predicted from Instagram profiles based on the following lists and other quantitative features using machine learning algorithms. We also provide predictions on Big Five personality traits. Models were built based on a sample of 400 Iranian volunteer users who answered an online questionnaire and provided their Instagram usernames which allowed us to crawl the public profiles. We applied several machine learning algorithms to the uniformed data. Deep learning models mostly outperformed by demonstrating 70% and 69% average Accuracy in two-level and three-level classifications respectively. Creating a large pool of people with the highest level of soft skills, and making more accurate evaluations of job candidates is possible with the application of AI on social media user-generated data.