 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Design and Implementation of A Soccer Ball Detection System with Multiple Cameras
Jan 31, 2023

The detection of small and medium-sized objects in three dimensions has always been a frontier exploration problem. This technology has a very wide application in sports analysis, games, virtual reality, human animation and other fields. The traditional three-dimensional small target detection technology has the disadvantages of high cost, low precision and inconvenience, so it is difficult to apply in practice. With the development of machine learning and deep learning, the technology of computer vision algorithms is becoming more mature. Creating an immersive media experience is considered to be a very important research work in sports. The main work is to explore and solve the problem of football detection under the multiple cameras, aiming at the research and implementation of the live broadcast system of football matches. Using multi cameras detects a target ball and determines its position in three dimension with the occlusion, motion, low illumination of the target object. This paper designed and implemented football detection system under multiple cameras for the detection and capture of targets in real-time matches. The main work mainly consists of three parts, football detector, single camera detection, and multi-cameras detection. The system used bundle adjustment to obtain the three-dimensional position of the target, and the GPU to accelerates data pre-processing and achieve accurate real-time capture of the target. By testing the system, it shows that the system can accurately detect and capture the moving targets in 3D. In addition, the solution in this paper is reusable for large-scale competitions, like basketball and soccer. The system framework can be well transplanted into other similar engineering project systems. It has been put into the market.
Deepfake CAPTCHA: A Method for Preventing Fake Calls
Jan 08, 2023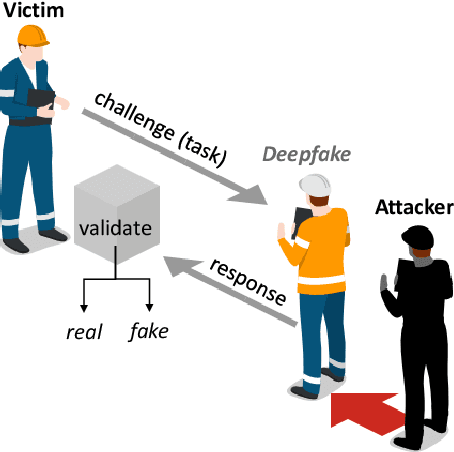
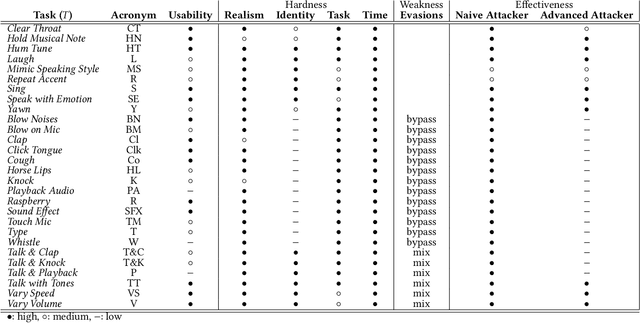
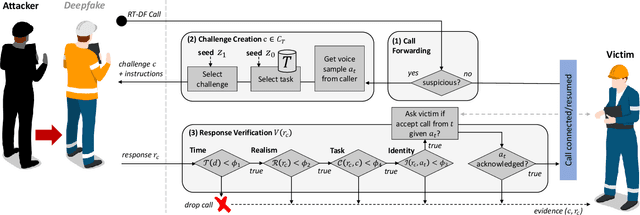
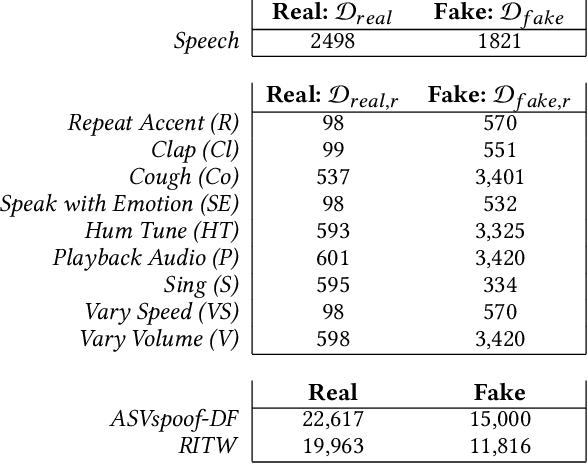
Deep learning technology has made it possible to generate realistic content of specific individuals. These `deepfakes' can now be generated in real-time which enables attackers to impersonate people over audio and video calls. Moreover, some methods only need a few images or seconds of audio to steal an identity. Existing defenses perform passive analysis to detect fake content. However, with the rapid progress of deepfake quality, this may be a losing game. In this paper, we propose D-CAPTCHA: an active defense against real-time deepfakes. The approach is to force the adversary into the spotlight by challenging the deepfake model to generate content which exceeds its capabilities. By doing so, passive detection becomes easier since the content will be distorted. In contrast to existing CAPTCHAs, we challenge the AI's ability to create content as opposed to its ability to classify content. In this work we focus on real-time audio deepfakes and present preliminary results on video. In our evaluation we found that D-CAPTCHA outperforms state-of-the-art audio deepfake detectors with an accuracy of 91-100% depending on the challenge (compared to 71% without challenges). We also performed a study on 41 volunteers to understand how threatening current real-time deepfake attacks are. We found that the majority of the volunteers could not tell the difference between real and fake audio.
AutoDOViz: Human-Centered Automation for Decision Optimization
Feb 19, 2023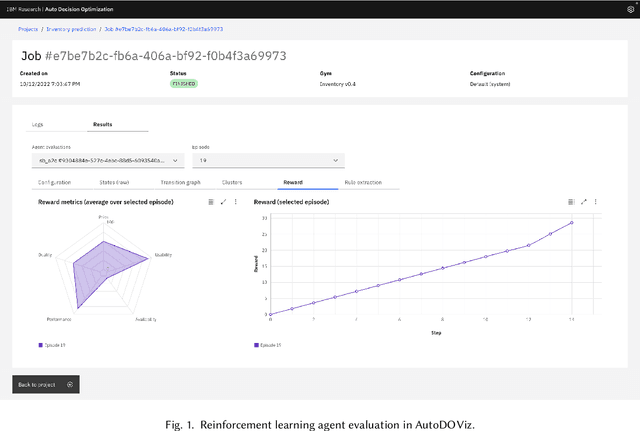

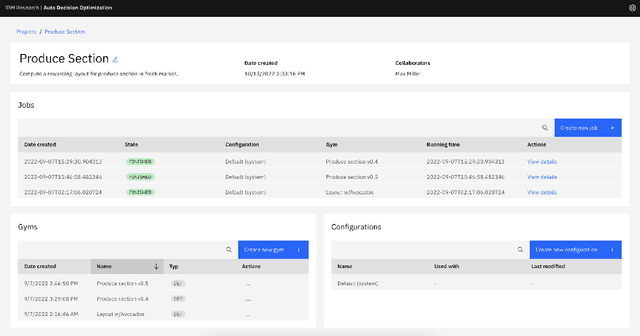
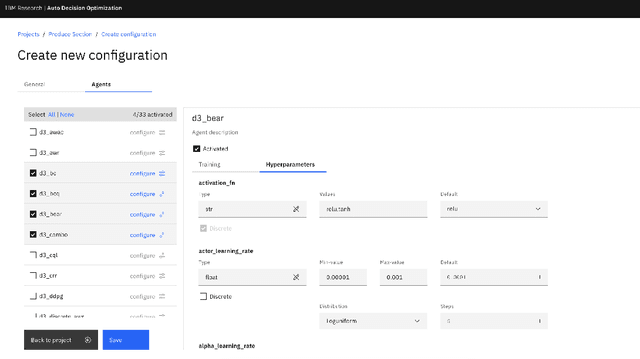
We present AutoDOViz, an interactive user interface for automated decision optimization (AutoDO) using reinforcement learning (RL). Decision optimization (DO) has classically being practiced by dedicated DO researchers where experts need to spend long periods of time fine tuning a solution through trial-and-error. AutoML pipeline search has sought to make it easier for a data scientist to find the best machine learning pipeline by leveraging automation to search and tune the solution. More recently, these advances have been applied to the domain of AutoDO, with a similar goal to find the best reinforcement learning pipeline through algorithm selection and parameter tuning. However, Decision Optimization requires significantly more complex problem specification when compared to an ML problem. AutoDOViz seeks to lower the barrier of entry for data scientists in problem specification for reinforcement learning problems, leverage the benefits of AutoDO algorithms for RL pipeline search and finally, create visualizations and policy insights in order to facilitate the typical interactive nature when communicating problem formulation and solution proposals between DO experts and domain experts. In this paper, we report our findings from semi-structured expert interviews with DO practitioners as well as business consultants, leading to design requirements for human-centered automation for DO with RL. We evaluate a system implementation with data scientists and find that they are significantly more open to engage in DO after using our proposed solution. AutoDOViz further increases trust in RL agent models and makes the automated training and evaluation process more comprehensible. As shown for other automation in ML tasks, we also conclude automation of RL for DO can benefit from user and vice-versa when the interface promotes human-in-the-loop.
An Efficient and Robust Method for Chest X-Ray Rib Suppression that Improves Pulmonary Abnormality Diagnosis
Feb 19, 2023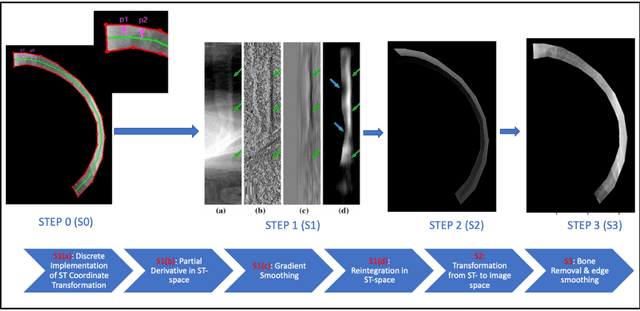
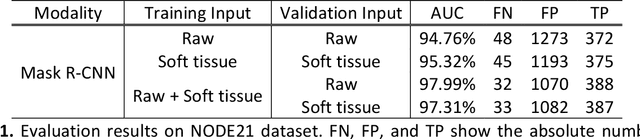

Suppression of thoracic bone shadows on chest X-rays (CXRs) has been indicated to improve the diagnosis of pulmonary disease. Previous approaches can be categorized as unsupervised physical and supervised deep learning models. Nevertheless, with physical models able to preserve morphological details but at the cost of extremely long processing time, existing DL methods face challenges of gathering sufficient/qualitative ground truth (GT) for robust training, thus leading to failure in maintaining clinically acceptable false positive rates. We hereby propose a generalizable yet efficient workflow of two stages: (1) training pairs generation with GT bone shadows eliminated in by a physical model in spatially transformed gradient fields. (2) fully supervised image denoising network training on stage-one datasets for fast rib removal on incoming CXRs. For step two, we designed a densely connected network called SADXNet, combined with peak signal to noise ratio and multi-scale structure similarity index measure objective minimization to suppress bony structures. The SADXNet organizes spatial filters in U shape (e.g., X=7; filters = 16, 64, 256, 512, 256, 64, 16) and preserves the feature map dimension throughout the network flow. Visually, SADXNet can suppress the rib edge and that near the lung wall/vertebra without jeopardizing the vessel/abnormality conspicuity. Quantitively, it achieves RMSE of ~0 during testing with one prediction taking <1s. Downstream tasks including lung nodule detection as well as common lung disease classification and localization are used to evaluate our proposed rib suppression mechanism. We observed 3.23% and 6.62% area under the curve (AUC) increase as well as 203 and 385 absolute false positive decrease for lung nodule detection and common lung disease localization, separately.
Fast Kinodynamic Planning on the Constraint Manifold with Deep Neural Networks
Jan 12, 2023
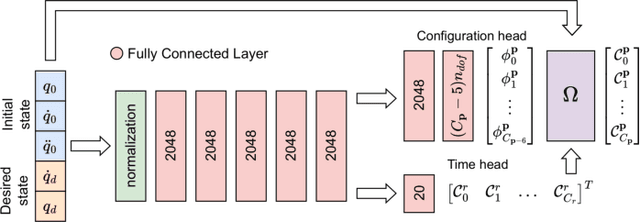
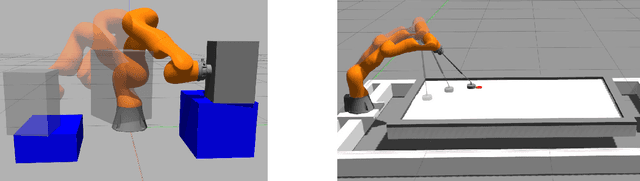
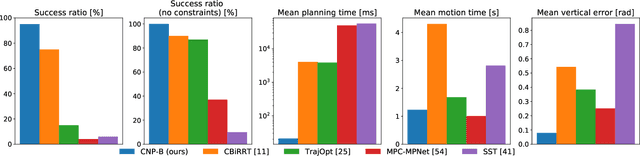
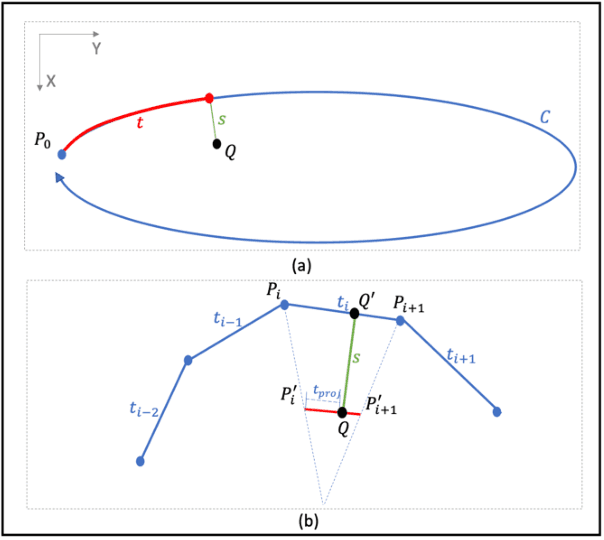
Motion planning is a mature area of research in robotics with many well-established methods based on optimization or sampling the state space, suitable for solving kinematic motion planning. However, when dynamic motions under constraints are needed and computation time is limited, fast kinodynamic planning on the constraint manifold is indispensable. In recent years, learning-based solutions have become alternatives to classical approaches, but they still lack comprehensive handling of complex constraints, such as planning on a lower-dimensional manifold of the task space while considering the robot's dynamics. This paper introduces a novel learning-to-plan framework that exploits the concept of constraint manifold, including dynamics, and neural planning methods. Our approach generates plans satisfying an arbitrary set of constraints and computes them in a short constant time, namely the inference time of a neural network. This allows the robot to plan and replan reactively, making our approach suitable for dynamic environments. We validate our approach on two simulated tasks and in a demanding real-world scenario, where we use a Kuka LBR Iiwa 14 robotic arm to perform the hitting movement in robotic Air Hockey.
A Minimax Approach Against Multi-Armed Adversarial Attacks Detection
Feb 04, 2023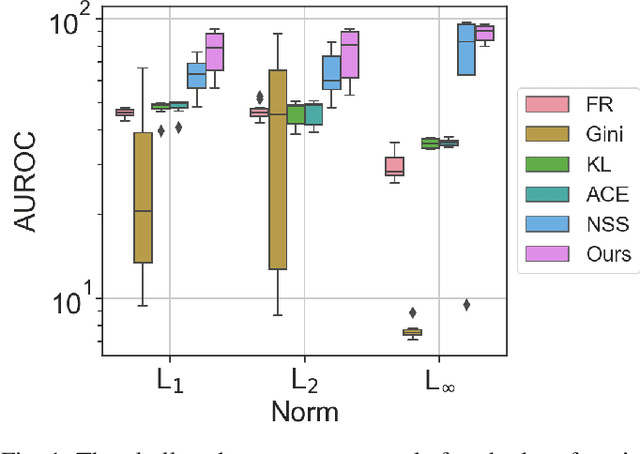
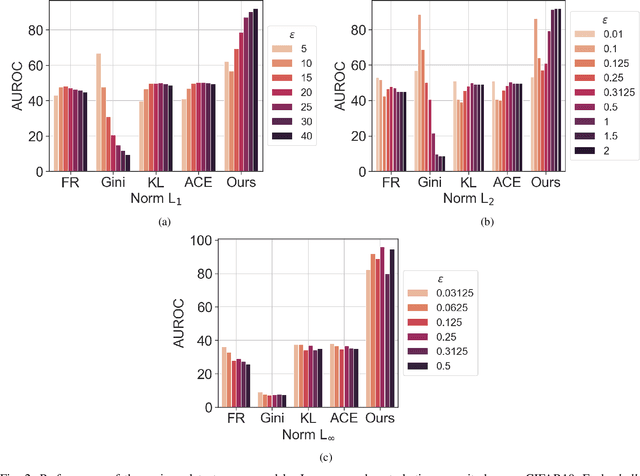
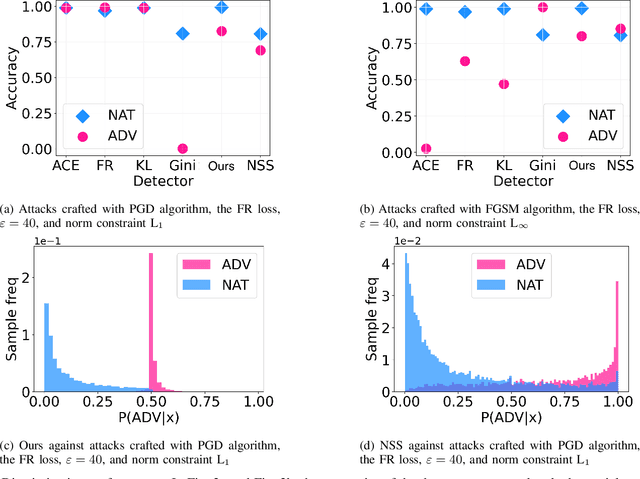
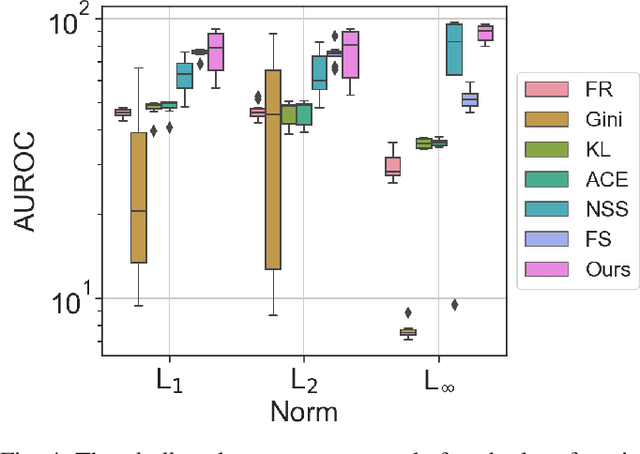
Multi-armed adversarial attacks, in which multiple algorithms and objective loss functions are simultaneously used at evaluation time, have been shown to be highly successful in fooling state-of-the-art adversarial examples detectors while requiring no specific side information about the detection mechanism. By formalizing the problem at hand, we can propose a solution that aggregates the soft-probability outputs of multiple pre-trained detectors according to a minimax approach. The proposed framework is mathematically sound, easy to implement, and modular, allowing for integrating existing or future detectors. Through extensive evaluation on popular datasets (e.g., CIFAR10 and SVHN), we show that our aggregation consistently outperforms individual state-of-the-art detectors against multi-armed adversarial attacks, making it an effective solution to improve the resilience of available methods.
Reinforcement Learning with History-Dependent Dynamic Contexts
Feb 04, 2023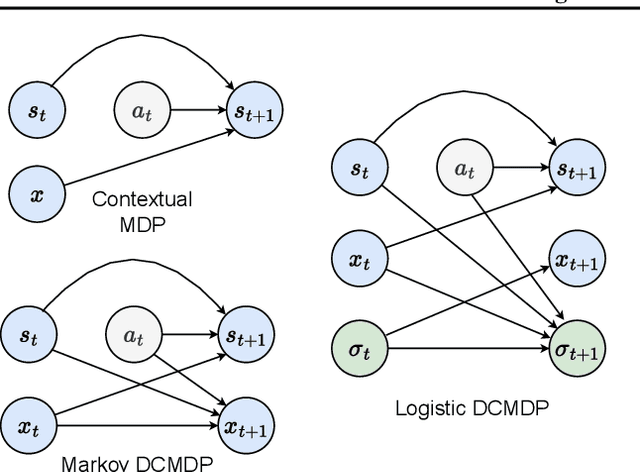
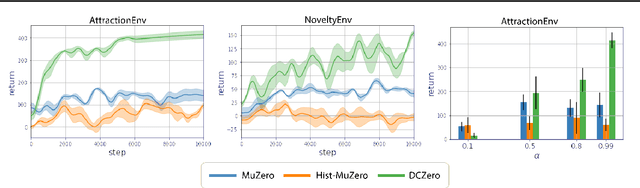
We introduce Dynamic Contextual Markov Decision Processes (DCMDPs), a novel reinforcement learning framework for history-dependent environments that generalizes the contextual MDP framework to handle non-Markov environments, where contexts change over time. We consider special cases of the model, with a focus on logistic DCMDPs, which break the exponential dependence on history length by leveraging aggregation functions to determine context transitions. This special structure allows us to derive an upper-confidence-bound style algorithm for which we establish regret bounds. Motivated by our theoretical results, we introduce a practical model-based algorithm for logistic DCMDPs that plans in a latent space and uses optimism over history-dependent features. We demonstrate the efficacy of our approach on a recommendation task (using MovieLens data) where user behavior dynamics evolve in response to recommendations.
Time-domain speech super-resolution with GAN based modeling for telephony speaker verification
Sep 04, 2022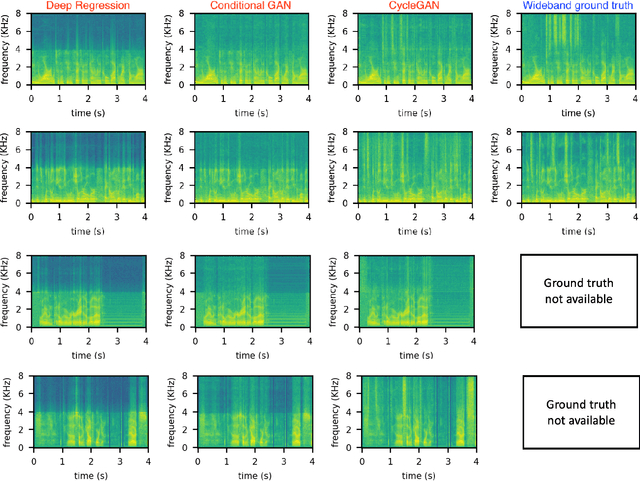
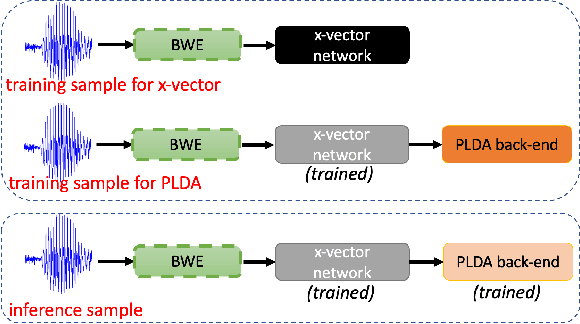
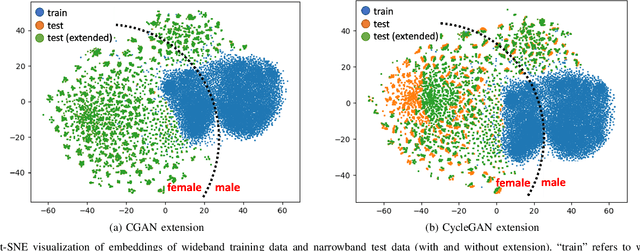
Automatic Speaker Verification (ASV) technology has become commonplace in virtual assistants. However, its performance suffers when there is a mismatch between the train and test domains. Mixed bandwidth training, i.e., pooling training data from both domains, is a preferred choice for developing a universal model that works for both narrowband and wideband domains. We propose complementing this technique by performing neural upsampling of narrowband signals, also known as bandwidth extension. Our main goal is to discover and analyze high-performing time-domain Generative Adversarial Network (GAN) based models to improve our downstream state-of-the-art ASV system. We choose GANs since they (1) are powerful for learning conditional distribution and (2) allow flexible plug-in usage as a pre-processor during the training of downstream task (ASV) with data augmentation. Prior works mainly focus on feature-domain bandwidth extension and limited experimental setups. We address these limitations by 1) using time-domain extension models, 2) reporting results on three real test sets, 2) extending training data, and 3) devising new test-time schemes. We compare supervised (conditional GAN) and unsupervised GANs (CycleGAN) and demonstrate average relative improvement in Equal Error Rate of 8.6% and 7.7%, respectively. For further analysis, we study changes in spectrogram visual quality, audio perceptual quality, t-SNE embeddings, and ASV score distributions. We show that our bandwidth extension leads to phenomena such as a shift of telephone (test) embeddings towards wideband (train) signals, a negative correlation of perceptual quality with downstream performance, and condition-independent score calibration.
Policy Gradient for s-Rectangular Robust Markov Decision Processes
Jan 31, 2023
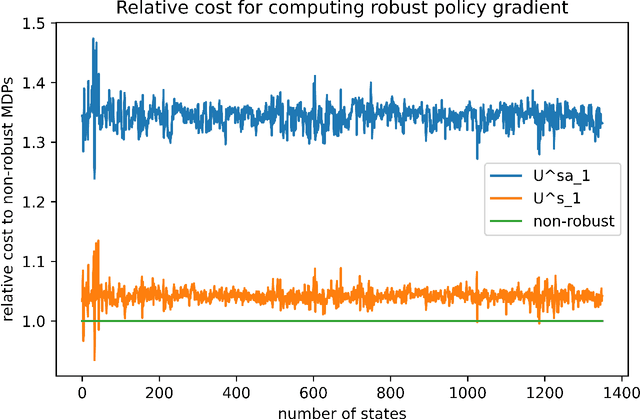


We present a novel robust policy gradient method (RPG) for s-rectangular robust Markov Decision Processes (MDPs). We are the first to derive the adversarial kernel in a closed form and demonstrate that it is a one-rank perturbation of the nominal kernel. This allows us to derive an RPG that is similar to the one used in non-robust MDPs, except with a robust Q-value function and an additional correction term. Both robust Q-values and correction terms are efficiently computable, thus the time complexity of our method matches that of non-robust MDPs, which is significantly faster compared to existing black box methods.
ClaSP -- Parameter-free Time Series Segmentation
Jul 28, 2022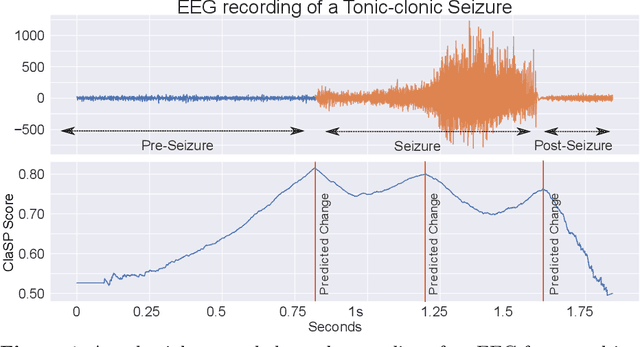
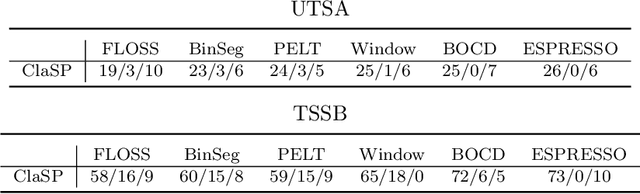
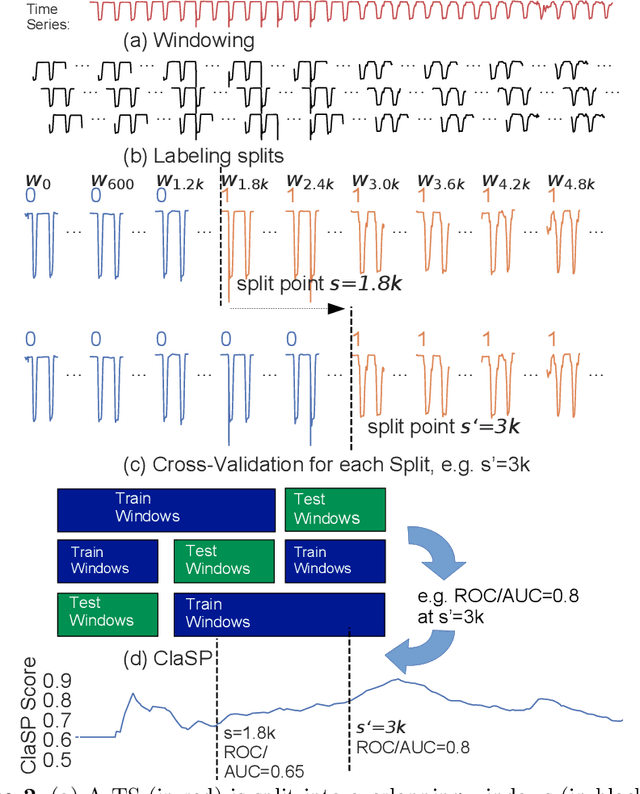
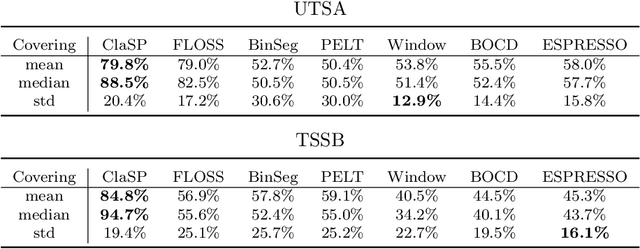
The study of natural and human-made processes often results in long sequences of temporally-ordered values, aka time series (TS). Such processes often consist of multiple states, e.g. operating modes of a machine, such that state changes in the observed processes result in changes in the distribution of shape of the measured values. Time series segmentation (TSS) tries to find such changes in TS post-hoc to deduce changes in the data-generating process. TSS is typically approached as an unsupervised learning problem aiming at the identification of segments distinguishable by some statistical property. Current algorithms for TSS require domain-dependent hyper-parameters to be set by the user, make assumptions about the TS value distribution or the types of detectable changes which limits their applicability. Common hyperparameters are the measure of segment homogeneity and the number of change points, which are particularly hard to tune for each data set. We present ClaSP, a novel, highly accurate, hyper-parameter-free and domain-agnostic method for TSS. ClaSP hierarchically splits a TS into two parts. A change point is determined by training a binary TS classifier for each possible split point and selecting the one split that is best at identifying subsequences to be from either of the partitions. ClaSP learns its main two model-parameters from the data using two novel bespoke algorithms. In our experimental evaluation using a benchmark of 115 data sets, we show that ClaSP outperforms the state of the art in terms of accuracy and is fast and scalable. Furthermore, we highlight properties of ClaSP using several real-world case studies.