 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactCorrector: A Graph-Inspired Approach to Long-Form Factuality Correction of Large Language Models
Jan 16, 2026Large language models (LLMs) are widely used in knowledge-intensive applications but often generate factually incorrect responses. A promising approach to rectify these flaws is correcting LLMs using feedback. Therefore, in this paper, we introduce FactCorrector, a new post-hoc correction method that adapts across domains without retraining and leverages structured feedback about the factuality of the original response to generate a correction. To support rigorous evaluations of factuality correction methods, we also develop the VELI5 benchmark, a novel dataset containing systematically injected factual errors and ground-truth corrections. Experiments on VELI5 and several popular long-form factuality datasets show that the FactCorrector approach significantly improves factual precision while preserving relevance, outperforming strong baselines. We release our code at https://ibm.biz/factcorrector.
FactReasoner: A Probabilistic Approach to Long-Form Factuality Assessment for Large Language Models
Feb 25, 2025



Large language models (LLMs) have demonstrated vast capabilities on generative tasks in recent years, yet they struggle with guaranteeing the factual correctness of the generated content. This makes these models unreliable in realistic situations where factually accurate responses are expected. In this paper, we propose FactReasoner, a new factuality assessor that relies on probabilistic reasoning to assess the factuality of a long-form generated response. Specifically, FactReasoner decomposes the response into atomic units, retrieves relevant contexts for them from an external knowledge source, and constructs a joint probability distribution over the atoms and contexts using probabilistic encodings of the logical relationships (entailment, contradiction) between the textual utterances corresponding to the atoms and contexts. FactReasoner then computes the posterior probability of whether atomic units in the response are supported by the retrieved contexts. Our experiments on labeled and unlabeled benchmark datasets demonstrate clearly that FactReasoner improves considerably over state-of-the-art prompt-based approaches in terms of both factual precision and recall.
WikiContradict: A Benchmark for Evaluating LLMs on Real-World Knowledge Conflicts from Wikipedia
Jun 19, 2024



Retrieval-augmented generation (RAG) has emerged as a promising solution to mitigate the limitations of large language models (LLMs), such as hallucinations and outdated information. However, it remains unclear how LLMs handle knowledge conflicts arising from different augmented retrieved passages, especially when these passages originate from the same source and have equal trustworthiness. In this work, we conduct a comprehensive evaluation of LLM-generated answers to questions that have varying answers based on contradictory passages from Wikipedia, a dataset widely regarded as a high-quality pre-training resource for most LLMs. Specifically, we introduce WikiContradict, a benchmark consisting of 253 high-quality, human-annotated instances designed to assess LLM performance when augmented with retrieved passages containing real-world knowledge conflicts. We benchmark a diverse range of both closed and open-source LLMs under different QA scenarios, including RAG with a single passage, and RAG with 2 contradictory passages. Through rigorous human evaluations on a subset of WikiContradict instances involving 5 LLMs and over 3,500 judgements, we shed light on the behaviour and limitations of these models. For instance, when provided with two passages containing contradictory facts, all models struggle to generate answers that accurately reflect the conflicting nature of the context, especially for implicit conflicts requiring reasoning. Since human evaluation is costly, we also introduce an automated model that estimates LLM performance using a strong open-source language model, achieving an F-score of 0.8. Using this automated metric, we evaluate more than 1,500 answers from seven LLMs across all WikiContradict instances. To facilitate future work, we release WikiContradict on: https://ibm.biz/wikicontradict.
Foundation Model Sherpas: Guiding Foundation Models through Knowledge and Reasoning
Feb 02, 2024


Foundation models (FMs) such as large language models have revolutionized the field of AI by showing remarkable performance in various tasks. However, they exhibit numerous limitations that prevent their broader adoption in many real-world systems, which often require a higher bar for trustworthiness and usability. Since FMs are trained using loss functions aimed at reconstructing the training corpus in a self-supervised manner, there is no guarantee that the model's output aligns with users' preferences for a specific task at hand. In this survey paper, we propose a conceptual framework that encapsulates different modes by which agents could interact with FMs and guide them suitably for a set of tasks, particularly through knowledge augmentation and reasoning. Our framework elucidates agent role categories such as updating the underlying FM, assisting with prompting the FM, and evaluating the FM output. We also categorize several state-of-the-art approaches into agent interaction protocols, highlighting the nature and extent of involvement of the various agent roles. The proposed framework provides guidance for future directions to further realize the power of FMs in practical AI systems.
Boosting AND/OR-Based Computational Protein Design: Dynamic Heuristics and Generalizable UFO
Aug 31, 2023



Scientific computing has experienced a surge empowered by advancements in technologies such as neural networks. However, certain important tasks are less amenable to these technologies, benefiting from innovations to traditional inference schemes. One such task is protein re-design. Recently a new re-design algorithm, AOBB-K*, was introduced and was competitive with state-of-the-art BBK* on small protein re-design problems. However, AOBB-K* did not scale well. In this work we focus on scaling up AOBB-K* and introduce three new versions: AOBB-K*-b (boosted), AOBB-K*-DH (with dynamic heuristics), and AOBB-K*-UFO (with underflow optimization) that significantly enhance scalability.
* In proceedings of the 39th Conference on Uncertainty in Artificial Intelligence (UAI 2023) and published in Proceedings of Machine Learning Research (PMLR)
Iterative Reward Shaping using Human Feedback for Correcting Reward Misspecification
Aug 30, 2023



A well-defined reward function is crucial for successful training of an reinforcement learning (RL) agent. However, defining a suitable reward function is a notoriously challenging task, especially in complex, multi-objective environments. Developers often have to resort to starting with an initial, potentially misspecified reward function, and iteratively adjusting its parameters, based on observed learned behavior. In this work, we aim to automate this process by proposing ITERS, an iterative reward shaping approach using human feedback for mitigating the effects of a misspecified reward function. Our approach allows the user to provide trajectory-level feedback on agent's behavior during training, which can be integrated as a reward shaping signal in the following training iteration. We also allow the user to provide explanations of their feedback, which are used to augment the feedback and reduce user effort and feedback frequency. We evaluate ITERS in three environments and show that it can successfully correct misspecified reward functions.
An Ensemble Approach for Automated Theorem Proving Based on Efficient Name Invariant Graph Neural Representations
May 15, 2023



Using reinforcement learning for automated theorem proving has recently received much attention. Current approaches use representations of logical statements that often rely on the names used in these statements and, as a result, the models are generally not transferable from one domain to another. The size of these representations and whether to include the whole theory or part of it are other important decisions that affect the performance of these approaches as well as their runtime efficiency. In this paper, we present NIAGRA; an ensemble Name InvAriant Graph RepresentAtion. NIAGRA addresses this problem by using 1) improved Graph Neural Networks for learning name-invariant formula representations that is tailored for their unique characteristics and 2) an efficient ensemble approach for automated theorem proving. Our experimental evaluation shows state-of-the-art performance on multiple datasets from different domains with improvements up to 10% compared to the best learning-based approaches. Furthermore, transfer learning experiments show that our approach significantly outperforms other learning-based approaches by up to 28%.
AutoDOViz: Human-Centered Automation for Decision Optimization
Feb 19, 2023



We present AutoDOViz, an interactive user interface for automated decision optimization (AutoDO) using reinforcement learning (RL). Decision optimization (DO) has classically being practiced by dedicated DO researchers where experts need to spend long periods of time fine tuning a solution through trial-and-error. AutoML pipeline search has sought to make it easier for a data scientist to find the best machine learning pipeline by leveraging automation to search and tune the solution. More recently, these advances have been applied to the domain of AutoDO, with a similar goal to find the best reinforcement learning pipeline through algorithm selection and parameter tuning. However, Decision Optimization requires significantly more complex problem specification when compared to an ML problem. AutoDOViz seeks to lower the barrier of entry for data scientists in problem specification for reinforcement learning problems, leverage the benefits of AutoDO algorithms for RL pipeline search and finally, create visualizations and policy insights in order to facilitate the typical interactive nature when communicating problem formulation and solution proposals between DO experts and domain experts. In this paper, we report our findings from semi-structured expert interviews with DO practitioners as well as business consultants, leading to design requirements for human-centered automation for DO with RL. We evaluate a system implementation with data scientists and find that they are significantly more open to engage in DO after using our proposed solution. AutoDOViz further increases trust in RL agent models and makes the automated training and evaluation process more comprehensible. As shown for other automation in ML tasks, we also conclude automation of RL for DO can benefit from user and vice-versa when the interface promotes human-in-the-loop.
Boolean Decision Rules for Reinforcement Learning Policy Summarisation
Jul 18, 2022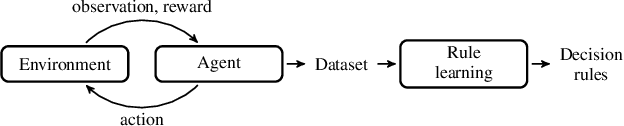

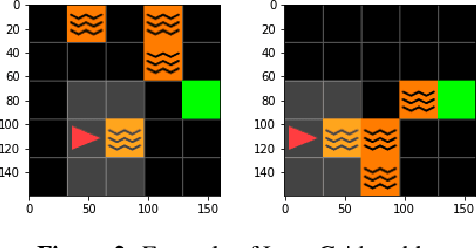
Explainability of Reinforcement Learning (RL) policies remains a challenging research problem, particularly when considering RL in a safety context. Understanding the decisions and intentions of an RL policy offer avenues to incorporate safety into the policy by limiting undesirable actions. We propose the use of a Boolean Decision Rules model to create a post-hoc rule-based summary of an agent's policy. We evaluate our proposed approach using a DQN agent trained on an implementation of a lava gridworld and show that, given a hand-crafted feature representation of this gridworld, simple generalised rules can be created, giving a post-hoc explainable summary of the agent's policy. We discuss possible avenues to introduce safety into a RL agent's policy by using rules generated by this rule-based model as constraints imposed on the agent's policy, as well as discuss how creating simple rule summaries of an agent's policy may help in the debugging process of RL agents.
Contrastive Explanations for Comparing Preferences of Reinforcement Learning Agents
Dec 17, 2021


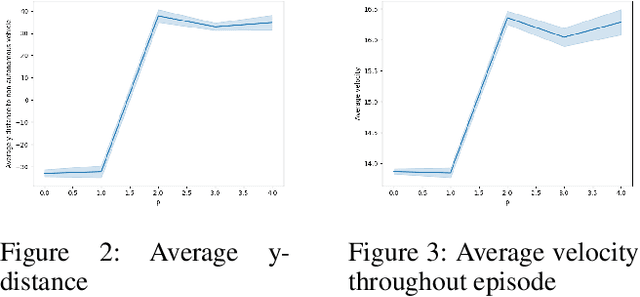
In complex tasks where the reward function is not straightforward and consists of a set of objectives, multiple reinforcement learning (RL) policies that perform task adequately, but employ different strategies can be trained by adjusting the impact of individual objectives on reward function. Understanding the differences in strategies between policies is necessary to enable users to choose between offered policies, and can help developers understand different behaviors that emerge from various reward functions and training hyperparameters in RL systems. In this work we compare behavior of two policies trained on the same task, but with different preferences in objectives. We propose a method for distinguishing between differences in behavior that stem from different abilities from those that are a consequence of opposing preferences of two RL agents. Furthermore, we use only data on preference-based differences in order to generate contrasting explanations about agents' preferences. Finally, we test and evaluate our approach on an autonomous driving task and compare the behavior of a safety-oriented policy and one that prefers speed.