 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Provably Efficient Model-Free Algorithms for Non-stationary CMDPs
Mar 10, 2023
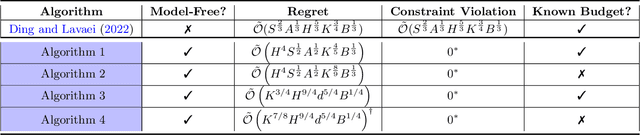
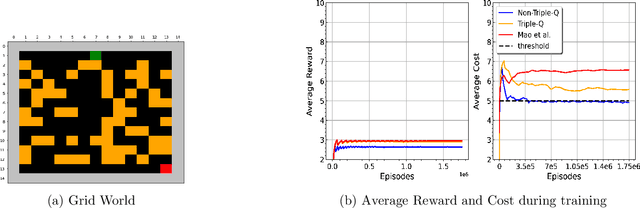

We study model-free reinforcement learning (RL) algorithms in episodic non-stationary constrained Markov Decision Processes (CMDPs), in which an agent aims to maximize the expected cumulative reward subject to a cumulative constraint on the expected utility (cost). In the non-stationary environment, reward, utility functions, and transition kernels can vary arbitrarily over time as long as the cumulative variations do not exceed certain variation budgets. We propose the first model-free, simulator-free RL algorithms with sublinear regret and zero constraint violation for non-stationary CMDPs in both tabular and linear function approximation settings with provable performance guarantees. Our results on regret bound and constraint violation for the tabular case match the corresponding best results for stationary CMDPs when the total budget is known. Additionally, we present a general framework for addressing the well-known challenges associated with analyzing non-stationary CMDPs, without requiring prior knowledge of the variation budget. We apply the approach for both tabular and linear approximation settings.
3D Masked Autoencoders with Application to Anomaly Detection in Non-Contrast Enhanced Breast MRI
Mar 10, 2023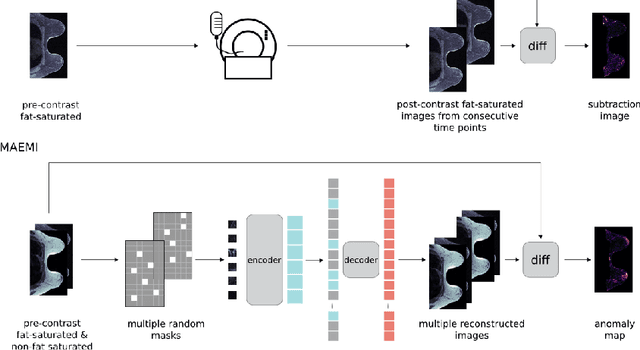
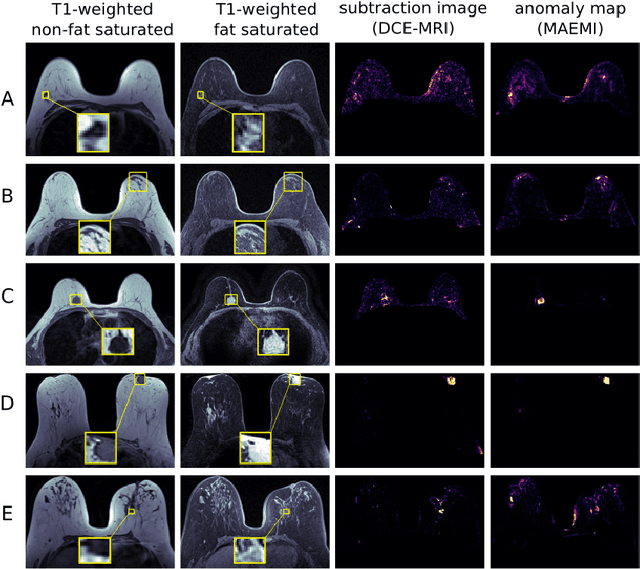
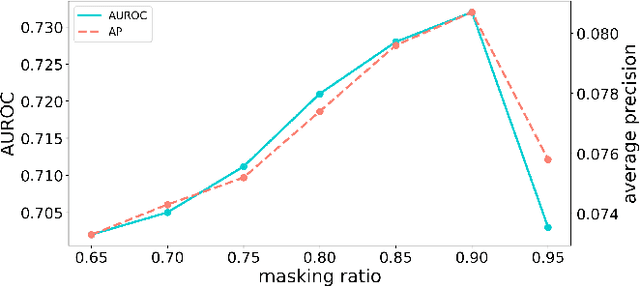

Self-supervised models allow (pre-)training on unlabeled data and therefore have the potential to overcome the need for large annotated cohorts. One leading self-supervised model is the masked autoencoder (MAE) which was developed on natural imaging data. The MAE is masking out a high fraction of visual transformer (ViT) input patches, to then recover the uncorrupted images as a pretraining task. In this work, we extend MAE to perform anomaly detection on breast magnetic resonance imaging (MRI). This new model, coined masked autoencoder for medical imaging (MAEMI) is trained on two non-contrast enhanced MRI sequences, aiming at lesion detection without the need for intravenous injection of contrast media and temporal image acquisition. During training, only non-cancerous images are presented to the model, with the purpose of localizing anomalous tumor regions during test time. We use a public dataset for model development. Performance of the architecture is evaluated in reference to subtraction images created from dynamic contrast enhanced (DCE)-MRI.
Deep Learning for Predicting Metastasis on Melanoma WSIs
Mar 10, 2023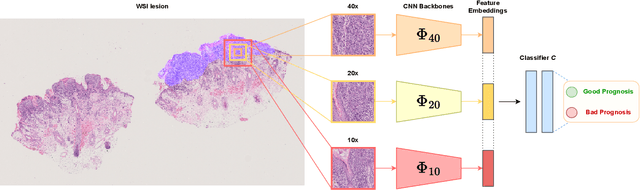
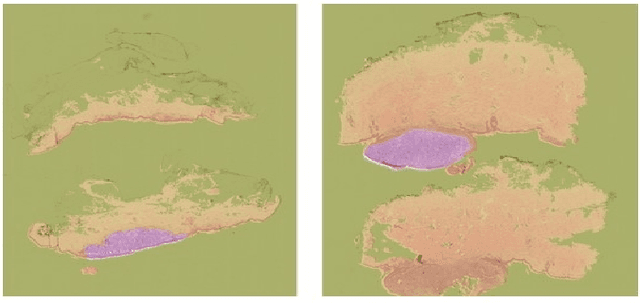
Northern Europe has the second highest mortality rate of melanoma globally. In 2020, the mortality rate of melanoma rose to 1.9 per 100 000 habitants. Melanoma prognosis is based on a pathologist's subjective visual analysis of the patient's tumor. This methodology is heavily time-consuming, and the prognosis variability among experts is notable, drastically jeopardizing its reproducibility. Thus, the need for faster and more reproducible methods arises. Machine learning has paved its way into digital pathology, but so far, most contributions are on localization, segmentation, and diagnostics, with little emphasis on prognostics. This paper presents a convolutional neural network (CNN) method based on VGG16 to predict melanoma prognosis as the presence of metastasis within five years. Patches are extracted from regions of interest from Whole Slide Images (WSIs) at different magnification levels used in model training and validation. Results infer that utilizing WSI patches at 20x magnification level has the best performance, with an F1 score of 0.7667 and an AUC of 0.81.
MCROOD: Multi-Class Radar Out-Of-Distribution Detection
Mar 10, 2023
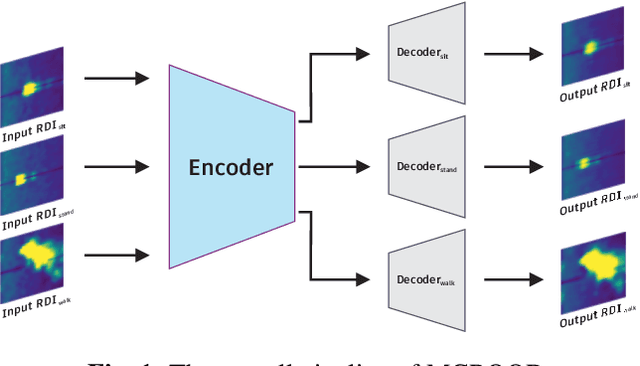
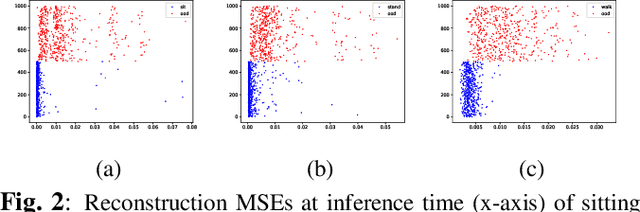
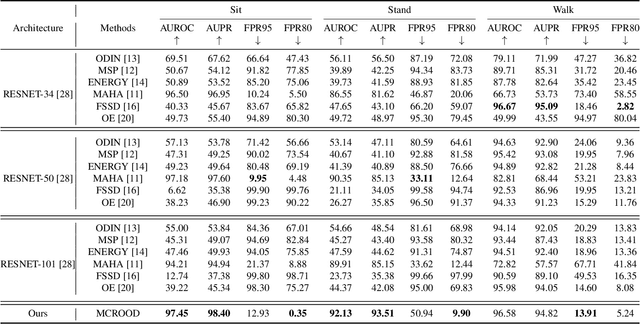
Out-of-distribution (OOD) detection has recently received special attention due to its critical role in safely deploying modern deep learning (DL) architectures. This work proposes a reconstruction-based multi-class OOD detector that operates on radar range doppler images (RDIs). The detector aims to classify any moving object other than a person sitting, standing, or walking as OOD. We also provide a simple yet effective pre-processing technique to detect minor human body movements like breathing. The simple idea is called respiration detector (RESPD) and eases the OOD detection, especially for human sitting and standing classes. On our dataset collected by 60GHz short-range FMCW Radar, we achieve AUROCs of 97.45%, 92.13%, and 96.58% for sitting, standing, and walking classes, respectively. We perform extensive experiments and show that our method outperforms state-of-the-art (SOTA) OOD detection methods. Also, our pipeline performs 24 times faster than the second-best method and is very suitable for real-time processing.
High-Speed and Energy-Efficient Non-Volatile Silicon Photonic Memory Based on Heterogeneously Integrated Memresonator
Mar 10, 2023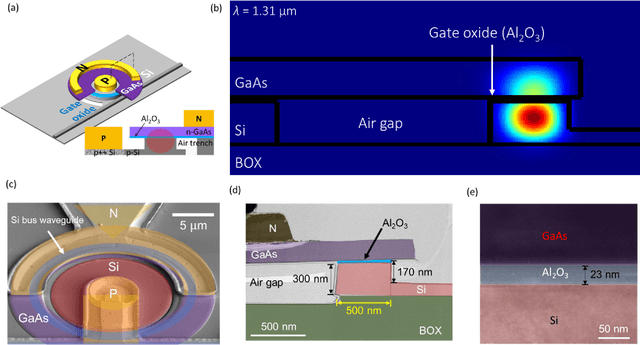
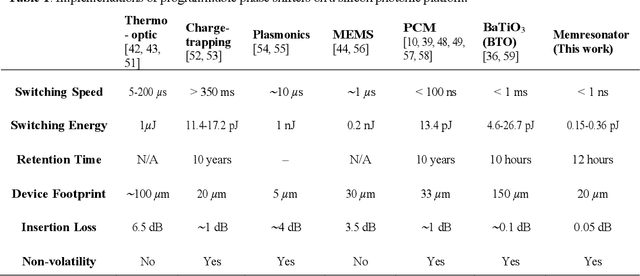
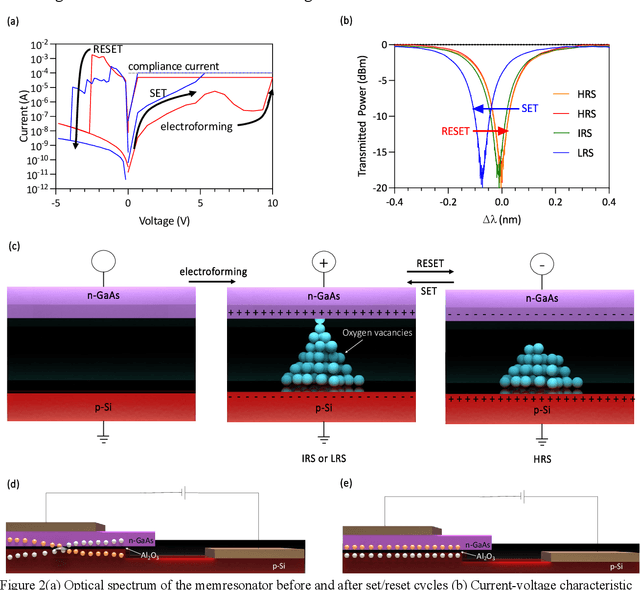
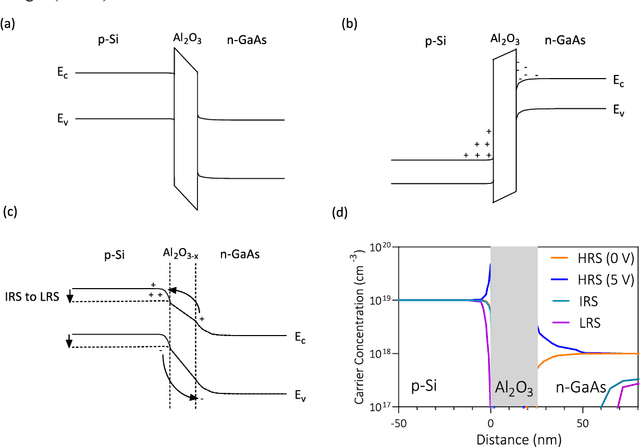
Recently, interest in programmable photonics integrated circuits has grown as a potential hardware framework for deep neural networks, quantum computing, and field programmable arrays (FPGAs). However, these circuits are constrained by the limited tuning speed and large power consumption of the phase shifters used. In this paper, introduced for the first time are memresonators, or memristors heterogeneously integrated with silicon photonic microring resonators, as phase shifters with non-volatile memory. These devices are capable of retention times of 12 hours, switching voltages lower than 5 V, an endurance of 1,000 switching cycles. Also, these memresonators have been switched using voltage pulses as short as 300 ps with a record low switching energy of 0.15 pJ. Furthermore, these memresonators are fabricated on a heterogeneous III-V/Si platform capable of integrating a rich family of active, passive, and non-linear optoelectronic devices, such as lasers and detectors, directly on-chip to enable in-memory photonic computing and further advance the scalability of integrated photonic processor circuits.
DULDA: Dual-domain Unsupervised Learned Descent Algorithm for PET image reconstruction
Mar 10, 2023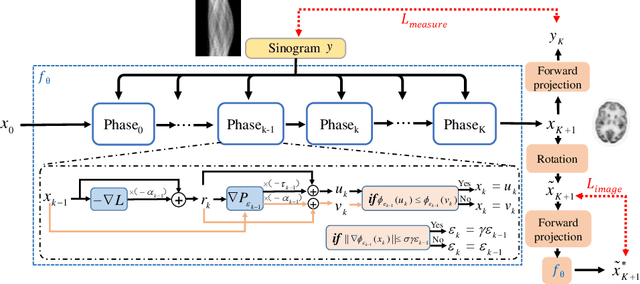
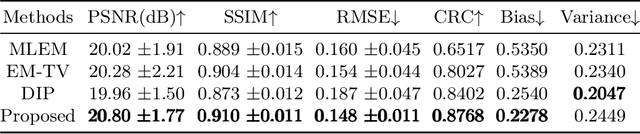
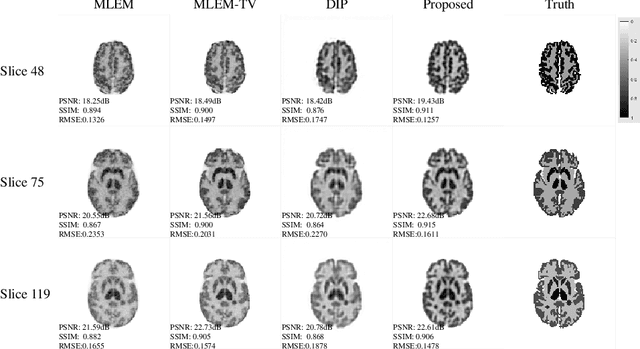
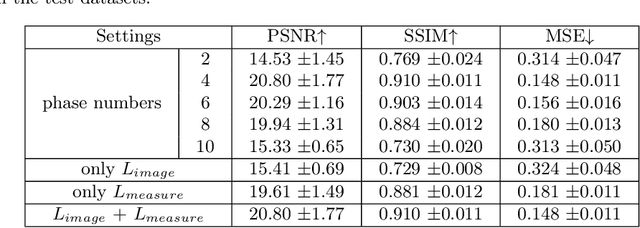
Deep learning based PET image reconstruction methods have achieved promising results recently. However, most of these methods follow a supervised learning paradigm, which rely heavily on the availability of high-quality training labels. In particular, the long scanning time required and high radiation exposure associated with PET scans make obtaining this labels impractical. In this paper, we propose a dual-domain unsupervised PET image reconstruction method based on learned decent algorithm, which reconstructs high-quality PET images from sinograms without the need for image labels. Specifically, we unroll the proximal gradient method with a learnable l2,1 norm for PET image reconstruction problem. The training is unsupervised, using measurement domain loss based on deep image prior as well as image domain loss based on rotation equivariance property. The experimental results domonstrate the superior performance of proposed method compared with maximum likelihood expectation maximazation (MLEM), total-variation regularized EM (EM-TV) and deep image prior based method (DIP).
Structure-Aware Group Discrimination with Adaptive-View Graph Encoder: A Fast Graph Contrastive Learning Framework
Mar 09, 2023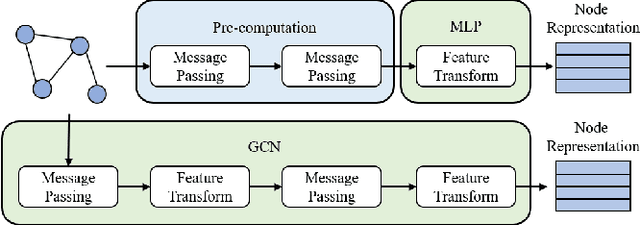
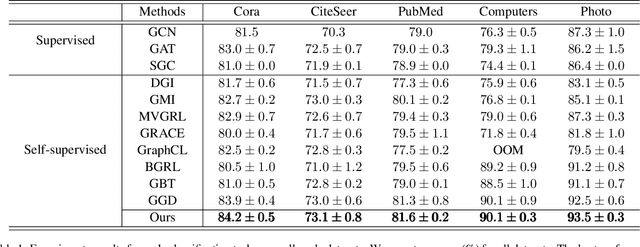
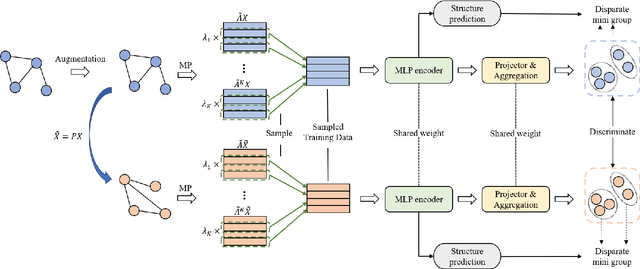
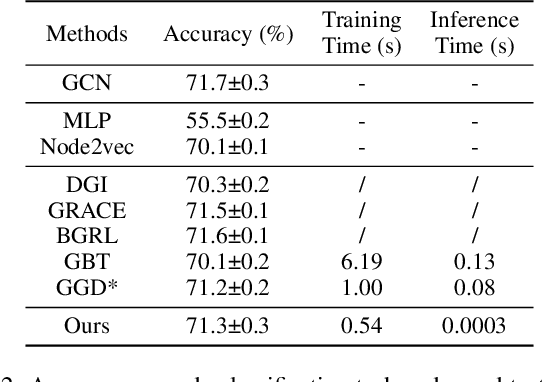
Albeit having gained significant progress lately, large-scale graph representation learning remains expensive to train and deploy for two main reasons: (i) the repetitive computation of multi-hop message passing and non-linearity in graph neural networks (GNNs); (ii) the computational cost of complex pairwise contrastive learning loss. Two main contributions are made in this paper targeting this twofold challenge: we first propose an adaptive-view graph neural encoder (AVGE) with a limited number of message passing to accelerate the forward pass computation, and then we propose a structure-aware group discrimination (SAGD) loss in our framework which avoids inefficient pairwise loss computing in most common GCL and improves the performance of the simple group discrimination. By the framework proposed, we manage to bring down the training and inference cost on various large-scale datasets by a significant margin (250x faster inference time) without loss of the downstream-task performance.
Efficient Transformer-based 3D Object Detection with Dynamic Token Halting
Mar 09, 2023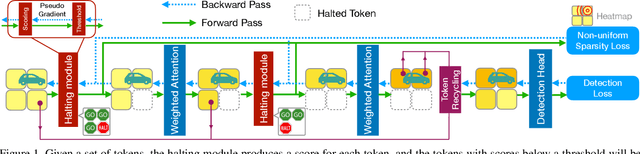
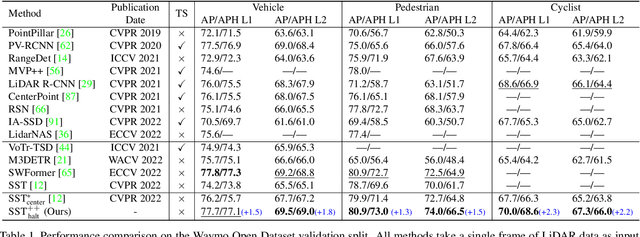
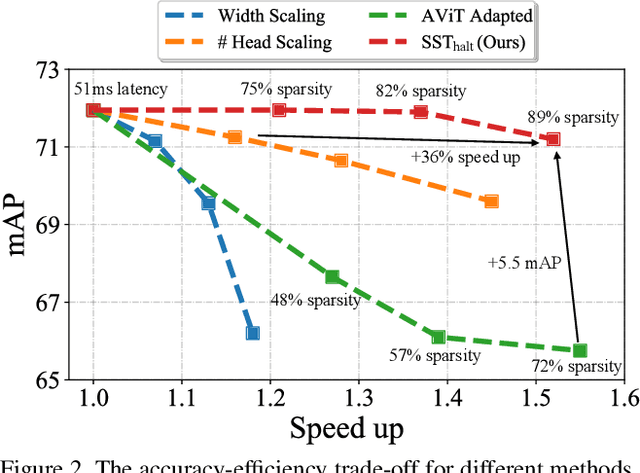

Balancing efficiency and accuracy is a long-standing problem for deploying deep learning models. The trade-off is even more important for real-time safety-critical systems like autonomous vehicles. In this paper, we propose an effective approach for accelerating transformer-based 3D object detectors by dynamically halting tokens at different layers depending on their contribution to the detection task. Although halting a token is a non-differentiable operation, our method allows for differentiable end-to-end learning by leveraging an equivalent differentiable forward-pass. Furthermore, our framework allows halted tokens to be reused to inform the model's predictions through a straightforward token recycling mechanism. Our method significantly improves the Pareto frontier of efficiency versus accuracy when compared with the existing approaches. By halting tokens and increasing model capacity, we are able to improve the baseline model's performance without increasing the model's latency on the Waymo Open Dataset.
Decision-BADGE: Decision-based Adversarial Batch Attack with Directional Gradient Estimation
Mar 09, 2023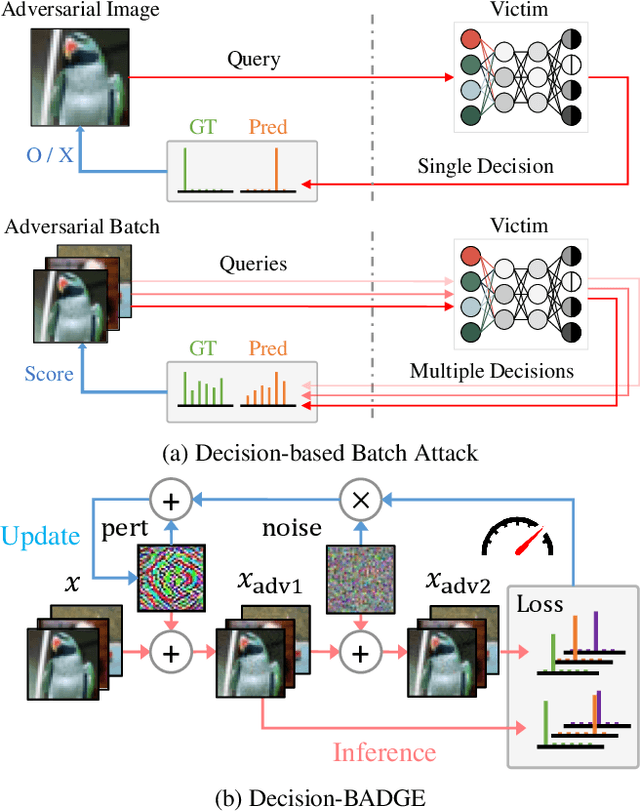

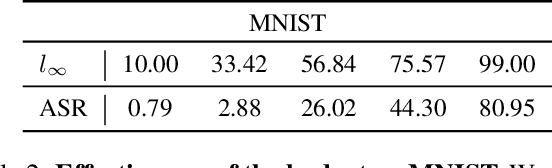
The vulnerability of deep neural networks to adversarial examples has led to the rise in the use of adversarial attacks. While various decision-based and universal attack methods have been proposed, none have attempted to create a decision-based universal adversarial attack. This research proposes Decision-BADGE, which uses random gradient-free optimization and batch attack to generate universal adversarial perturbations for decision-based attacks. Multiple adversarial examples are combined to optimize a single universal perturbation, and the accuracy metric is reformulated into a continuous Hamming distance form. The effectiveness of accuracy metric as a loss function is demonstrated and mathematically proven. The combination of Decision-BADGE and the accuracy loss function performs better than both score-based image-dependent attack and white-box universal attack methods in terms of attack time efficiency. The research also shows that Decision-BADGE can successfully deceive unseen victims and accurately target specific classes.
A Policy Gradient Framework for Stochastic Optimal Control Problems with Global Convergence Guarantee
Feb 11, 2023In this work, we consider the stochastic optimal control problem in continuous time and a policy gradient method to solve it. In particular, we study the gradient flow for the control, viewed as a continuous time limit of the policy gradient. We prove the global convergence of the gradient flow and establish a convergence rate under some regularity assumptions. The main novelty in the analysis is the notion of local optimal control function, which is introduced to compare the local optimality of the iterate.