 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising guarantees for optimized sampling schemes in compressed sensing
Apr 01, 2025



Compressed sensing with subsampled unitary matrices benefits from \emph{optimized} sampling schemes, which feature improved theoretical guarantees and empirical performance relative to uniform subsampling. We provide, in a first of its kind in compressed sensing, theoretical guarantees showing that the error caused by the measurement noise vanishes with an increasing number of measurements for optimized sampling schemes, assuming that the noise is Gaussian. We moreover provide similar guarantees for measurements sampled with-replacement with arbitrary probability weights. All our results hold on prior sets contained in a union of low-dimensional subspaces. Finally, we demonstrate that this denoising behavior appears in empirical experiments with a rate that closely matches our theoretical guarantees when the prior set is the range of a generative ReLU neural network and when it is the set of sparse vectors.
Model-adapted Fourier sampling for generative compressed sensing
Oct 08, 2023



We study generative compressed sensing when the measurement matrix is randomly subsampled from a unitary matrix (with the DFT as an important special case). It was recently shown that $\textit{O}(kdn\| \boldsymbol{\alpha}\|_{\infty}^{2})$ uniformly random Fourier measurements are sufficient to recover signals in the range of a neural network $G:\mathbb{R}^k \to \mathbb{R}^n$ of depth $d$, where each component of the so-called local coherence vector $\boldsymbol{\alpha}$ quantifies the alignment of a corresponding Fourier vector with the range of $G$. We construct a model-adapted sampling strategy with an improved sample complexity of $\textit{O}(kd\| \boldsymbol{\alpha}\|_{2}^{2})$ measurements. This is enabled by: (1) new theoretical recovery guarantees that we develop for nonuniformly random sampling distributions and then (2) optimizing the sampling distribution to minimize the number of measurements needed for these guarantees. This development offers a sample complexity applicable to natural signal classes, which are often almost maximally coherent with low Fourier frequencies. Finally, we consider a surrogate sampling scheme, and validate its performance in recovery experiments using the CelebA dataset.
High-Speed and Energy-Efficient Non-Volatile Silicon Photonic Memory Based on Heterogeneously Integrated Memresonator
Mar 10, 2023Recently, interest in programmable photonics integrated circuits has grown as a potential hardware framework for deep neural networks, quantum computing, and field programmable arrays (FPGAs). However, these circuits are constrained by the limited tuning speed and large power consumption of the phase shifters used. In this paper, introduced for the first time are memresonators, or memristors heterogeneously integrated with silicon photonic microring resonators, as phase shifters with non-volatile memory. These devices are capable of retention times of 12 hours, switching voltages lower than 5 V, an endurance of 1,000 switching cycles. Also, these memresonators have been switched using voltage pulses as short as 300 ps with a record low switching energy of 0.15 pJ. Furthermore, these memresonators are fabricated on a heterogeneous III-V/Si platform capable of integrating a rich family of active, passive, and non-linear optoelectronic devices, such as lasers and detectors, directly on-chip to enable in-memory photonic computing and further advance the scalability of integrated photonic processor circuits.
Experimentally realized memristive memory augmented neural network
Apr 15, 2022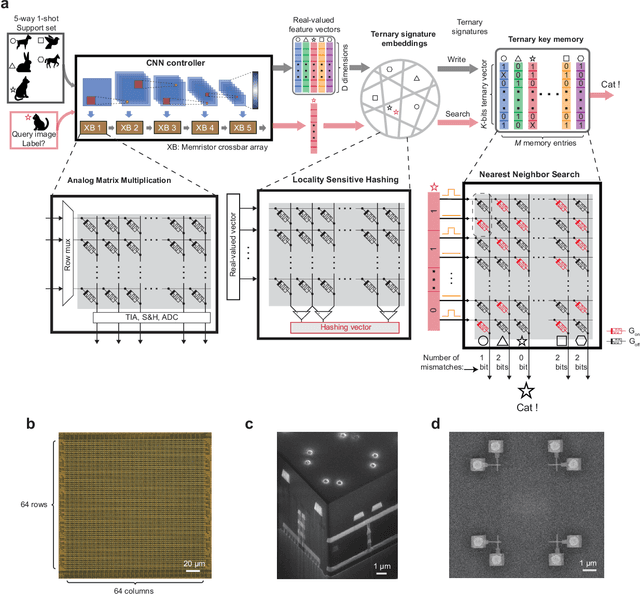
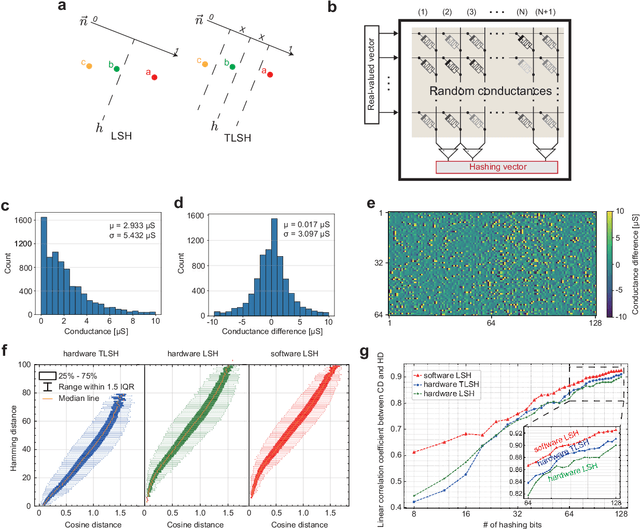
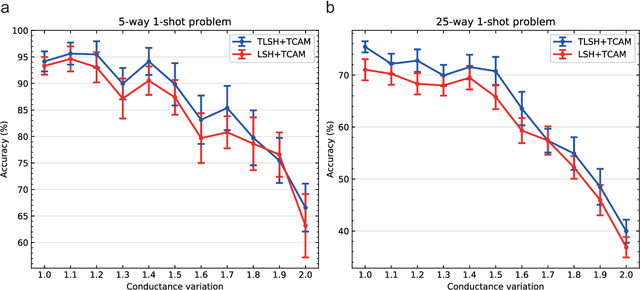
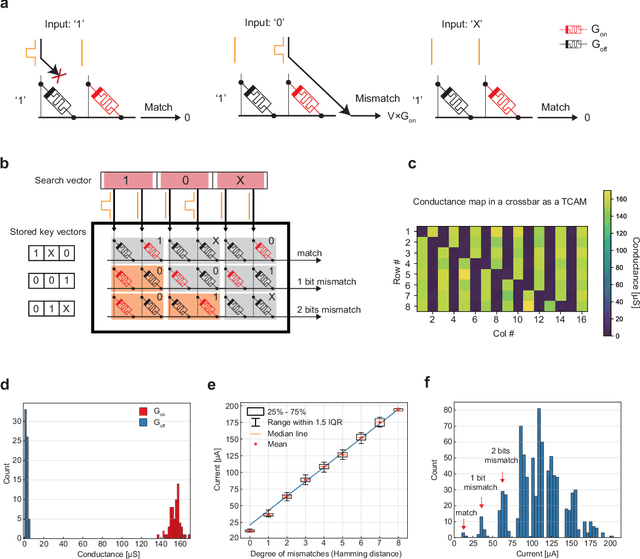
Lifelong on-device learning is a key challenge for machine intelligence, and this requires learning from few, often single, samples. Memory augmented neural network has been proposed to achieve the goal, but the memory module has to be stored in an off-chip memory due to its size. Therefore the practical use has been heavily limited. Previous works on emerging memory-based implementation have difficulties in scaling up because different modules with various structures are difficult to integrate on the same chip and the small sense margin of the content addressable memory for the memory module heavily limited the degree of mismatch calculation. In this work, we implement the entire memory augmented neural network architecture in a fully integrated memristive crossbar platform and achieve an accuracy that closely matches standard software on digital hardware for the Omniglot dataset. The successful demonstration is supported by implementing new functions in crossbars in addition to widely reported matrix multiplications. For example, the locality-sensitive hashing operation is implemented in crossbar arrays by exploiting the intrinsic stochasticity of memristor devices. Besides, the content-addressable memory module is realized in crossbars, which also supports the degree of mismatches. Simulations based on experimentally validated models show such an implementation can be efficiently scaled up for one-shot learning on the Mini-ImageNet dataset. The successful demonstration paves the way for practical on-device lifelong learning and opens possibilities for novel attention-based algorithms not possible in conventional hardware.