 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pseudo channel reciprocity in FDD satellite channels
May 02, 2023
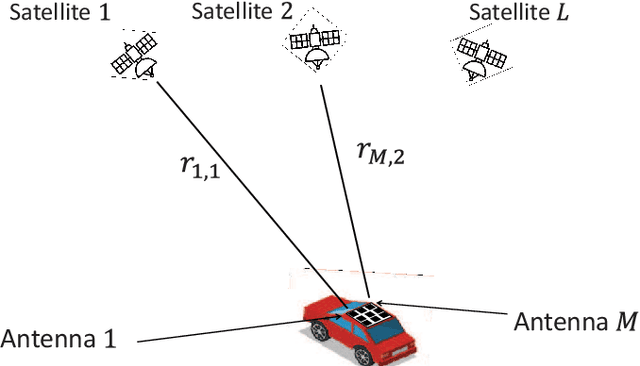
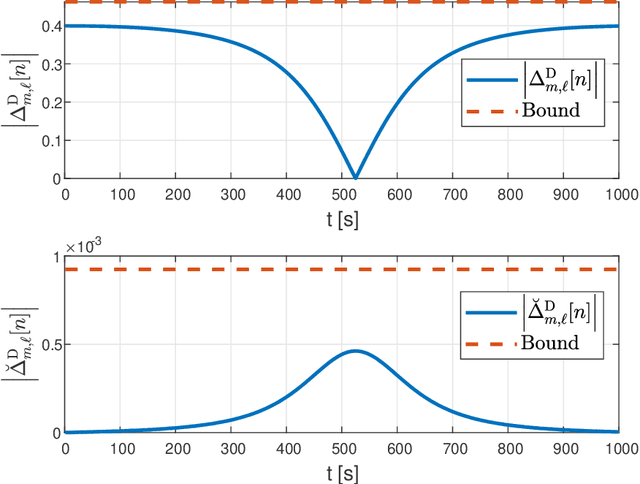
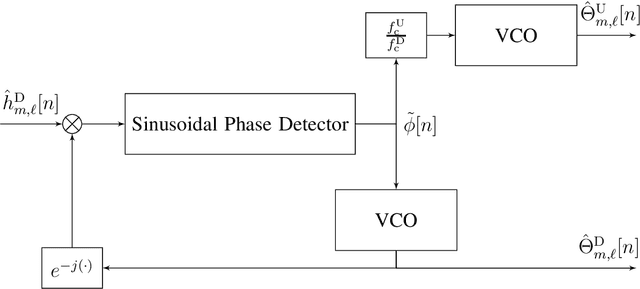
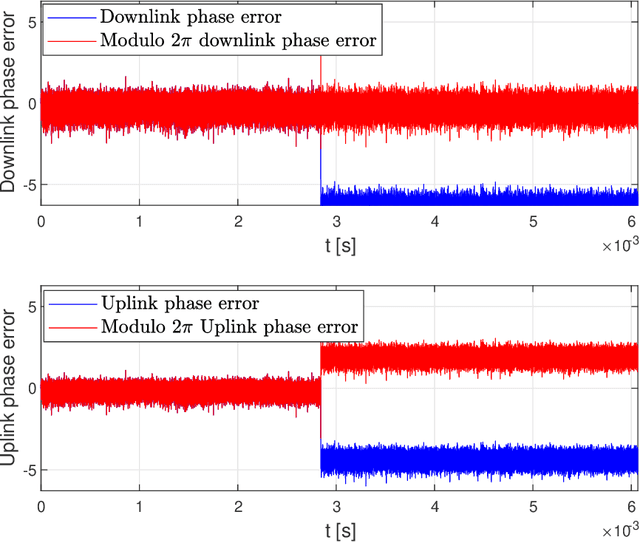
Channel reciprocity can significantly reduce the overhead of obtaining channel-state information at the transmitter (CSIT). However, true reciprocity only exists in time division duplex (TDD). In this paper, we propose a novel tracking method that exploits implicit reciprocity in FDD line-of-sight (LOS) channels as in low-earth-orbit (LEO) satellite communication (SatCom). This channel reciprocity, dubbed pseudo-reciprocity, is crucial for applying multiple-user multiple-input multiple-output (MU-MIMO) to SatCom, which requires CSIT. We consider an LEO SatCom system where multiple satellites communicate with a multi-antenna land terminal (LT). In this innovative method, the LT can track the downlink channel changes and use them to estimate the uplink channels. The proposed method achieves precoding performance that is comparable to precoding with full CSIT knowledge. Furthermore, the use of pseudo reciprocity typically requires only initial CSIT feedback when the satellite rises. Over very long periods of time, pseudo reciprocity can fail as a result of phase ambiguity, which is referred to as cycle slip. We thus also present a closed-form approximation for the expected time until cycle slip, which indicates that in normal operating conditions, these cycle slips are extremely rare. Our numerical results provide strong support for the derived theory.
Using Spatio-Temporal Dual-Stream Network with Self-Supervised Learning for Lung Tumor Classification on Radial Probe Endobronchial Ultrasound Video
May 07, 2023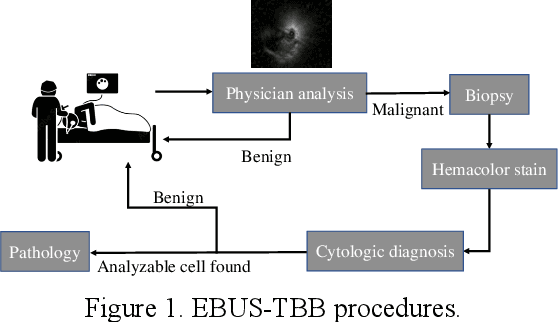
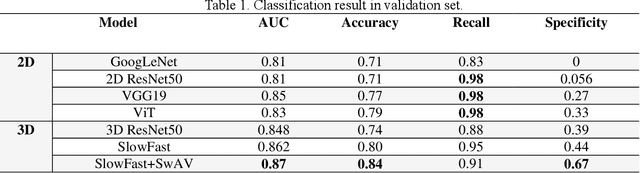
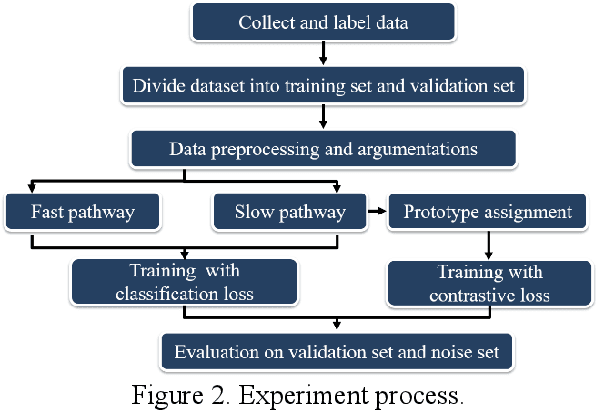
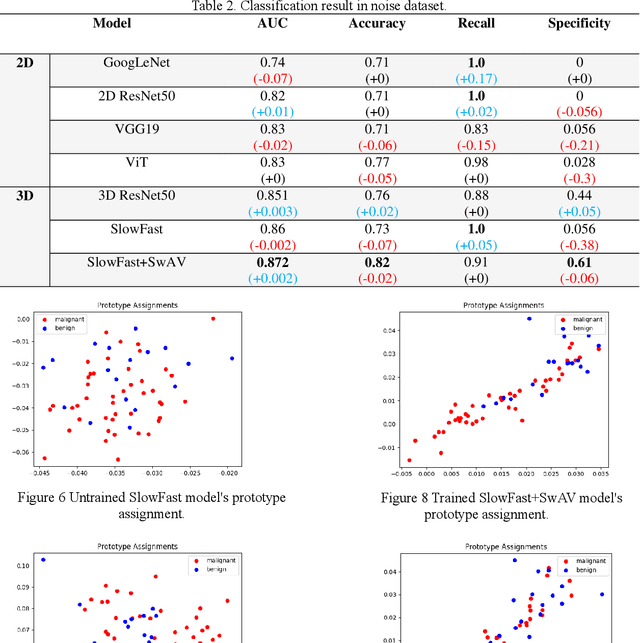
The purpose of this study is to develop a computer-aided diagnosis system for classifying benign and malignant lung lesions, and to assist physicians in real-time analysis of radial probe endobronchial ultrasound (EBUS) videos. During the biopsy process of lung cancer, physicians use real-time ultrasound images to find suitable lesion locations for sampling. However, most of these images are difficult to classify and contain a lot of noise. Previous studies have employed 2D convolutional neural networks to effectively differentiate between benign and malignant lung lesions, but doctors still need to manually select good-quality images, which can result in additional labor costs. In addition, the 2D neural network has no ability to capture the temporal information of the ultrasound video, so it is difficult to obtain the relationship between the features of the continuous images. This study designs an automatic diagnosis system based on a 3D neural network, uses the SlowFast architecture as the backbone to fuse temporal and spatial features, and uses the SwAV method of contrastive learning to enhance the noise robustness of the model. The method we propose includes the following advantages, such as (1) using clinical ultrasound films as model input, thereby reducing the need for high-quality image selection by physicians, (2) high-accuracy classification of benign and malignant lung lesions can assist doctors in clinical diagnosis and reduce the time and risk of surgery, and (3) the capability to classify well even in the presence of significant image noise. The AUC, accuracy, precision, recall and specificity of our proposed method on the validation set reached 0.87, 83.87%, 86.96%, 90.91% and 66.67%, respectively. The results have verified the importance of incorporating temporal information and the effectiveness of using the method of contrastive learning on feature extraction.
A Pattern Discovery Approach to Multivariate Time Series Forecasting
Dec 20, 2022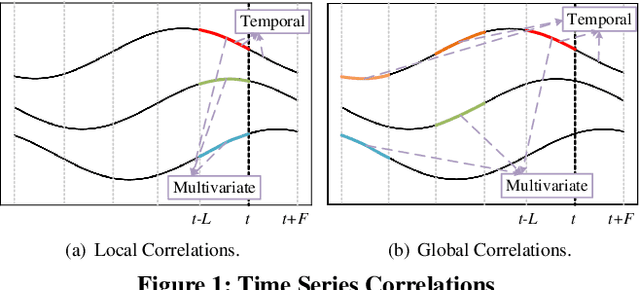

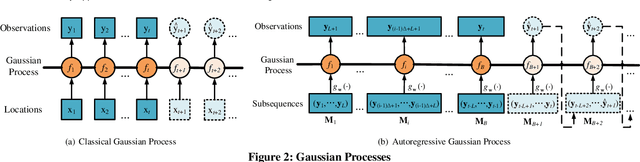
Multivariate time series forecasting constitutes important functionality in cyber-physical systems, whose prediction accuracy can be improved significantly by capturing temporal and multivariate correlations among multiple time series. State-of-the-art deep learning methods fail to construct models for full time series because model complexity grows exponentially with time series length. Rather, these methods construct local temporal and multivariate correlations within subsequences, but fail to capture correlations among subsequences, which significantly affect their forecasting accuracy. To capture the temporal and multivariate correlations among subsequences, we design a pattern discovery model, that constructs correlations via diverse pattern functions. While the traditional pattern discovery method uses shared and fixed pattern functions that ignore the diversity across time series. We propose a novel pattern discovery method that can automatically capture diverse and complex time series patterns. We also propose a learnable correlation matrix, that enables the model to capture distinct correlations among multiple time series. Extensive experiments show that our model achieves state-of-the-art prediction accuracy.
CBAGAN-RRT: Convolutional Block Attention Generative Adversarial Network for Sampling-Based Path Planning
May 13, 2023Sampling-based path planning algorithms play an important role in autonomous robotics. However, a common problem among the RRT-based algorithms is that the initial path generated is not optimal and the convergence is too slow to be used in real-world applications. In this paper, we propose a novel image-based learning algorithm (CBAGAN-RRT) using a Convolutional Block Attention Generative Adversarial Network with a combination of spatial and channel attention and a novel loss function to design the heuristics, find a better optimal path, and improve the convergence of the algorithm both concerning time and speed. The probability distribution of the paths generated from our GAN model is used to guide the sampling process for the RRT algorithm. We train and test our network on the dataset generated by \cite{zhang2021generative} and demonstrate that our algorithm outperforms the previous state-of-the-art algorithms using both the image quality generation metrics like IOU Score, Dice Score, FID score, and path planning metrics like time cost and the number of nodes. We conduct detailed experiments and ablation studies to illustrate the feasibility of our study and show that our model performs well not only on the training dataset but also on the unseen test dataset. The advantage of our approach is that we can avoid the complicated preprocessing in the state space, our model can be generalized to complicated environments like those containing turns and narrow passages without loss of accuracy, and our model can be easily integrated with other sampling-based path planning algorithms.
Efficient estimation of weighted cumulative treatment effects by double/debiased machine learning
May 03, 2023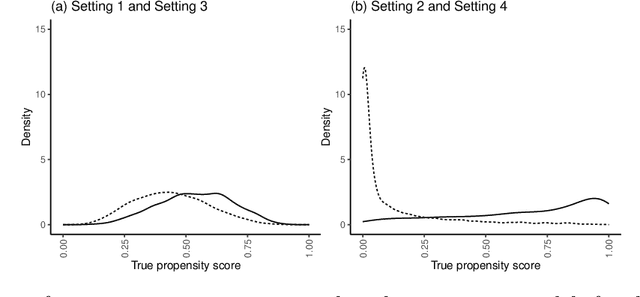
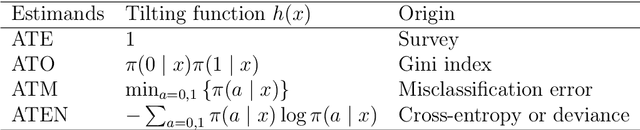
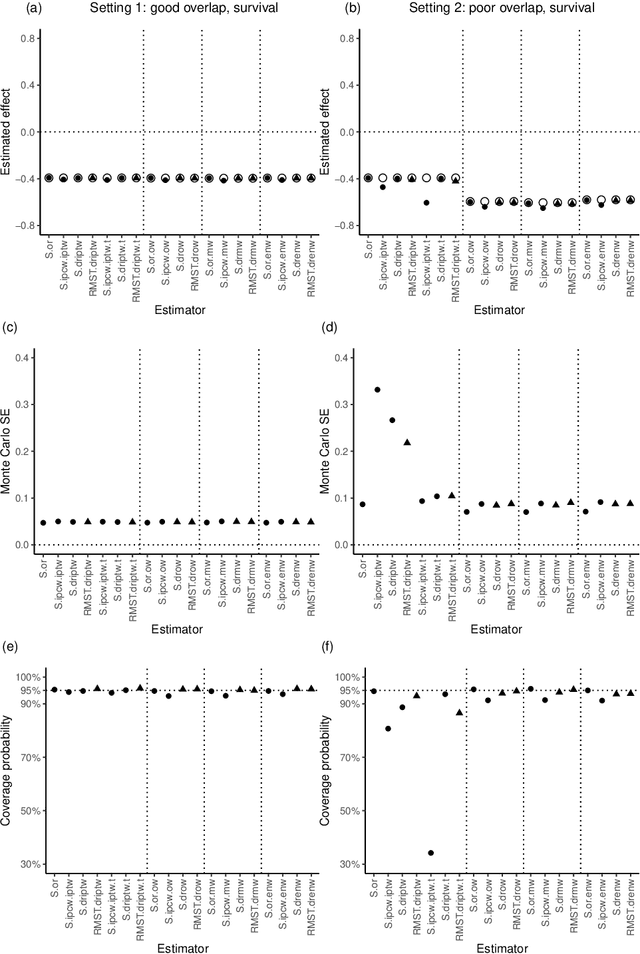
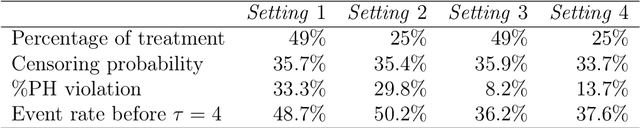
In empirical studies with time-to-event outcomes, investigators often leverage observational data to conduct causal inference on the effect of exposure when randomized controlled trial data is unavailable. Model misspecification and lack of overlap are common issues in observational studies, and they often lead to inconsistent and inefficient estimators of the average treatment effect. Estimators targeting overlap weighted effects have been proposed to address the challenge of poor overlap, and methods enabling flexible machine learning for nuisance models address model misspecification. However, the approaches that allow machine learning for nuisance models have not been extended to the setting of weighted average treatment effects for time-to-event outcomes when there is poor overlap. In this work, we propose a class of one-step cross-fitted double/debiased machine learning estimators for the weighted cumulative causal effect as a function of restriction time. We prove that the proposed estimators are consistent, asymptotically linear, and reach semiparametric efficiency bounds under regularity conditions. Our simulations show that the proposed estimators using nonparametric machine learning nuisance models perform as well as established methods that require correctly-specified parametric nuisance models, illustrating that our estimators mitigate the need for oracle parametric nuisance models. We apply the proposed methods to real-world observational data from a UK primary care database to compare the effects of anti-diabetic drugs on cancer clinical outcomes.
Fuzzy Temporal Protoforms for the Quantitative Description of Processes in Natural Language
May 16, 2023


In this paper, we propose a series of fuzzy temporal protoforms in the framework of the automatic generation of quantitative and qualitative natural language descriptions of processes. The model includes temporal and causal information from processes and attributes, quantifies attributes in time during the process life-span and recalls causal relations and temporal distances between events, among other features. Through integrating process mining techniques and fuzzy sets within the usual Data-to-Text architecture, our framework is able to extract relevant quantitative temporal as well as structural information from a process and describe it in natural language involving uncertain terms. A real use-case in the cardiology domain is presented, showing the potential of our model for providing natural language explanations addressed to domain experts.
On the Usage of Continual Learning for Out-of-Distribution Generalization in Pre-trained Language Models of Code
May 06, 2023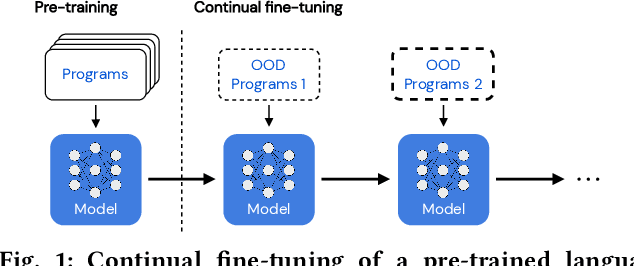
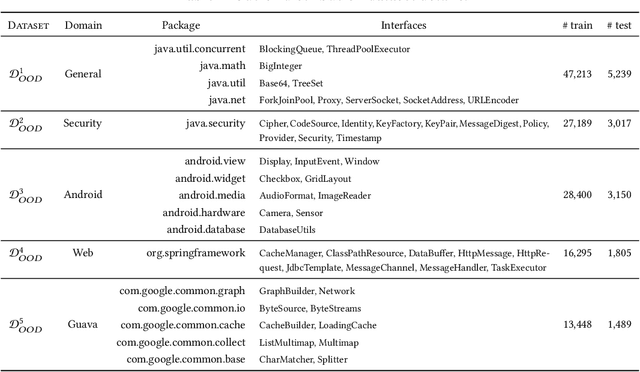
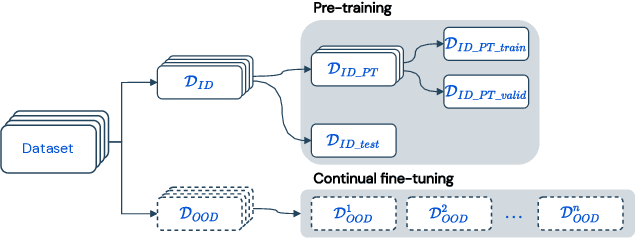
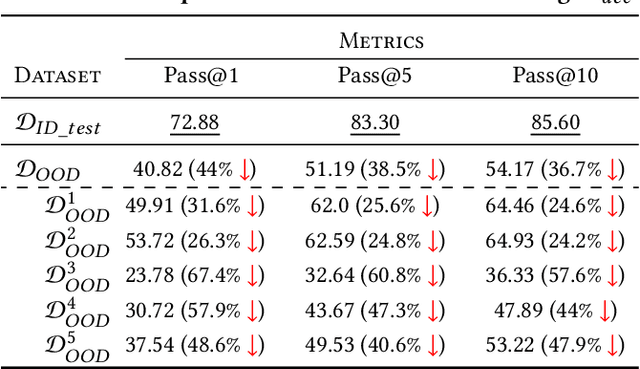
Pre-trained language models (PLMs) have become a prevalent technique in deep learning for code, utilizing a two-stage pre-training and fine-tuning procedure to acquire general knowledge about code and specialize in a variety of downstream tasks. However, the dynamic nature of software codebases poses a challenge to the effectiveness and robustness of PLMs. In particular, world-realistic scenarios potentially lead to significant differences between the distribution of the pre-training and test data, i.e., distribution shift, resulting in a degradation of the PLM's performance on downstream tasks. In this paper, we stress the need for adapting PLMs of code to software data whose distribution changes over time, a crucial problem that has been overlooked in previous works. The motivation of this work is to consider the PLM in a non-stationary environment, where fine-tuning data evolves over time according to a software evolution scenario. Specifically, we design a scenario where the model needs to learn from a stream of programs containing new, unseen APIs over time. We study two widely used PLM architectures, i.e., a GPT2 decoder and a RoBERTa encoder, on two downstream tasks, API call and API usage prediction. We demonstrate that the most commonly used fine-tuning technique from prior work is not robust enough to handle the dynamic nature of APIs, leading to the loss of previously acquired knowledge i.e., catastrophic forgetting. To address these issues, we implement five continual learning approaches, including replay-based and regularization-based methods. Our findings demonstrate that utilizing these straightforward methods effectively mitigates catastrophic forgetting in PLMs across both downstream tasks while achieving comparable or superior performance.
An efficient deep learning model to categorize brain tumor using reconstruction and fine-tuning
May 22, 2023

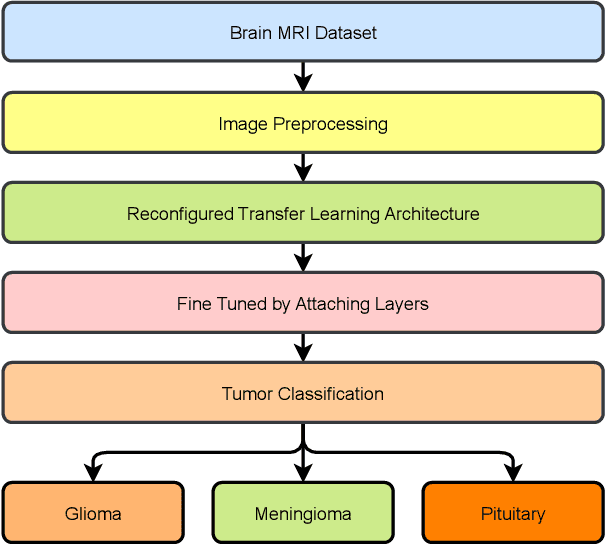
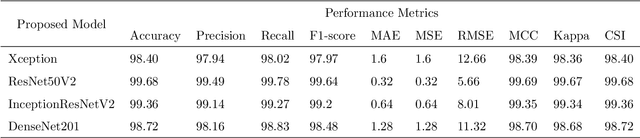
Brain tumors are among the most fatal and devastating diseases, often resulting in significantly reduced life expectancy. An accurate diagnosis of brain tumors is crucial to devise treatment plans that can extend the lives of affected individuals. Manually identifying and analyzing large volumes of MRI data is both challenging and time-consuming. Consequently, there is a pressing need for a reliable deep learning (DL) model to accurately diagnose brain tumors. In this study, we propose a novel DL approach based on transfer learning to effectively classify brain tumors. Our novel method incorporates extensive pre-processing, transfer learning architecture reconstruction, and fine-tuning. We employ several transfer learning algorithms, including Xception, ResNet50V2, InceptionResNetV2, and DenseNet201. Our experiments used the Figshare MRI brain tumor dataset, comprising 3,064 images, and achieved accuracy scores of 99.40%, 99.68%, 99.36%, and 98.72% for Xception, ResNet50V2, InceptionResNetV2, and DenseNet201, respectively. Our findings reveal that ResNet50V2 achieves the highest accuracy rate of 99.68% on the Figshare MRI brain tumor dataset, outperforming existing models. Therefore, our proposed model's ability to accurately classify brain tumors in a short timeframe can aid neurologists and clinicians in making prompt and precise diagnostic decisions for brain tumor patients.
VDT: An Empirical Study on Video Diffusion with Transformers
May 22, 2023

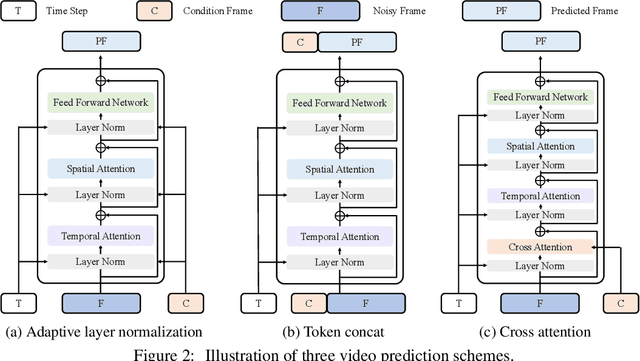

This work introduces Video Diffusion Transformer (VDT), which pioneers the use of transformers in diffusion-based video generation. It features transformer blocks with modularized temporal and spatial attention modules, allowing separate optimization of each component and leveraging the rich spatial-temporal representation inherited from transformers. VDT offers several appealing benefits. 1) It excels at capturing temporal dependencies to produce temporally consistent video frames and even simulate the dynamics of 3D objects over time. 2) It enables flexible conditioning information through simple concatenation in the token space, effectively unifying video generation and prediction tasks. 3) Its modularized design facilitates a spatial-temporal decoupled training strategy, leading to improved efficiency. Extensive experiments on video generation, prediction, and dynamics modeling (i.e., physics-based QA) tasks have been conducted to demonstrate the effectiveness of VDT in various scenarios, including autonomous driving, human action, and physics-based simulation. We hope our study on the capabilities of transformer-based video diffusion in capturing accurate temporal dependencies, handling conditioning information, and achieving efficient training will benefit future research and advance the field. Codes and models are available at https://github.com/RERV/VDT.
Road Planning for Slums via Deep Reinforcement Learning
May 22, 2023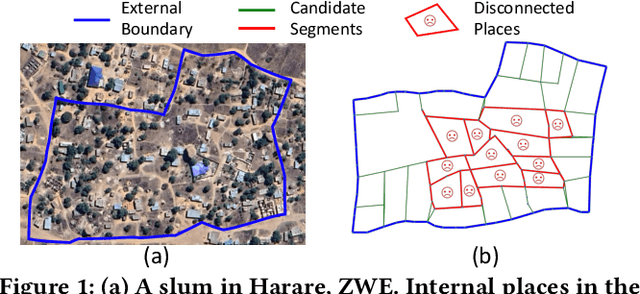
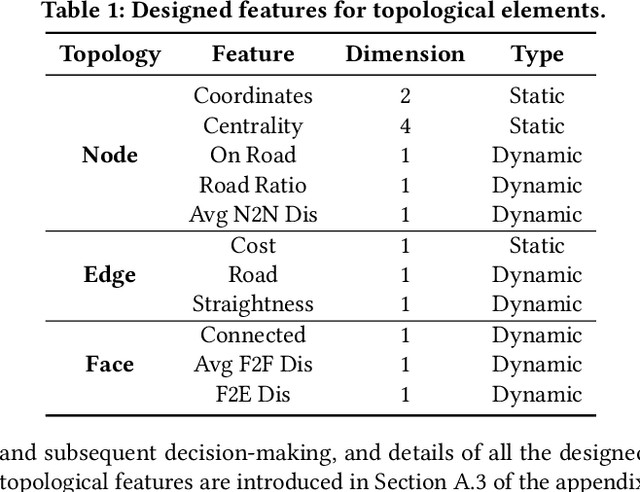
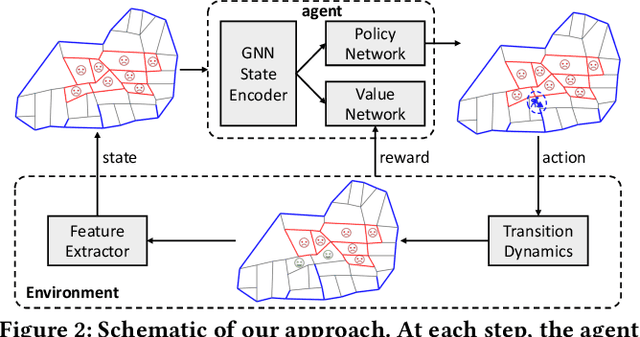
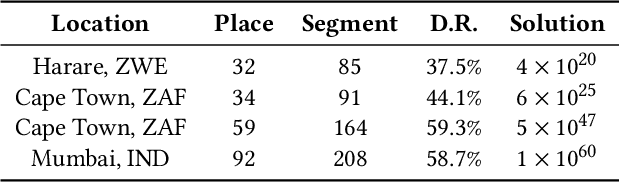
Millions of slum dwellers suffer from poor accessibility to urban services due to inadequate road infrastructure within slums, and road planning for slums is critical to the sustainable development of cities. Existing re-blocking or heuristic methods are either time-consuming which cannot generalize to different slums, or yield sub-optimal road plans in terms of accessibility and construction costs. In this paper, we present a deep reinforcement learning based approach to automatically layout roads for slums. We propose a generic graph model to capture the topological structure of a slum, and devise a novel graph neural network to select locations for the planned roads. Through masked policy optimization, our model can generate road plans that connect places in a slum at minimal construction costs. Extensive experiments on real-world slums in different countries verify the effectiveness of our model, which can significantly improve accessibility by 14.3% against existing baseline methods. Further investigations on transferring across different tasks demonstrate that our model can master road planning skills in simple scenarios and adapt them to much more complicated ones, indicating the potential of applying our model in real-world slum upgrading.