 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Rewards, Not Labels: Adversarial Inverse Reinforcement Learning for Machinery Fault Detection
Feb 25, 2026Reinforcement learning (RL) offers significant promise for machinery fault detection (MFD). However, most existing RL-based MFD approaches do not fully exploit RL's sequential decision-making strengths, often treating MFD as a simple guessing game (Contextual Bandits). To bridge this gap, we formulate MFD as an offline inverse reinforcement learning problem, where the agent learns the reward dynamics directly from healthy operational sequences, thereby bypassing the need for manual reward engineering and fault labels. Our framework employs Adversarial Inverse Reinforcement Learning to train a discriminator that distinguishes between normal (expert) and policy-generated transitions. The discriminator's learned reward serves as an anomaly score, indicating deviations from normal operating behaviour. When evaluated on three run-to-failure benchmark datasets (HUMS2023, IMS, and XJTU-SY), the model consistently assigns low anomaly scores to normal samples and high scores to faulty ones, enabling early and robust fault detection. By aligning RL's sequential reasoning with MFD's temporal structure, this work opens a path toward RL-based diagnostics in data-driven industrial settings.
DMS2F-HAD: A Dual-branch Mamba-based Spatial-Spectral Fusion Network for Hyperspectral Anomaly Detection
Feb 04, 2026Hyperspectral anomaly detection (HAD) aims to identify rare and irregular targets in high-dimensional hyperspectral images (HSIs), which are often noisy and unlabelled data. Existing deep learning methods either fail to capture long-range spectral dependencies (e.g., convolutional neural networks) or suffer from high computational cost (e.g., Transformers). To address these challenges, we propose DMS2F-HAD, a novel dual-branch Mamba-based model. Our architecture utilizes Mamba's linear-time modeling to efficiently learn distinct spatial and spectral features in specialized branches, which are then integrated by a dynamic gated fusion mechanism to enhance anomaly localization. Across fourteen benchmark HSI datasets, our proposed DMS2F-HAD not only achieves a state-of-the-art average AUC of 98.78%, but also demonstrates superior efficiency with an inference speed 4.6 times faster than comparable deep learning methods. The results highlight DMS2FHAD's strong generalization and scalability, positioning it as a strong candidate for practical HAD applications.
MissHDD: Hybrid Deterministic Diffusion for Hetrogeneous Incomplete Data Imputation
Nov 18, 2025Incomplete data are common in real-world tabular applications, where numerical, categorical, and discrete attributes coexist within a single dataset. This heterogeneous structure presents significant challenges for existing diffusion-based imputation models, which typically assume a homogeneous feature space and rely on stochastic denoising trajectories. Such assumptions make it difficult to maintain conditional consistency, and they often lead to information collapse for categorical variables or instability when numerical variables require deterministic updates. These limitations indicate that a single diffusion process is insufficient for mixed-type tabular imputation. We propose a hybrid deterministic diffusion framework that separates heterogeneous features into two complementary generative channels. A continuous DDIM-based channel provides efficient and stable deterministic denoising for numerical variables, while a discrete latent-path diffusion channel, inspired by loopholing-based discrete diffusion, models categorical and discrete features without leaving their valid sample manifolds. The two channels are trained under a unified conditional imputation objective, enabling coherent reconstruction of mixed-type incomplete data. Extensive experiments on multiple real-world datasets show that the proposed framework achieves higher imputation accuracy, more stable sampling trajectories, and improved robustness across MCAR, MAR, and MNAR settings compared with existing diffusion-based and classical methods. These results demonstrate the importance of structure-aware diffusion processes for advancing deep learning approaches to incomplete tabular data.
Spectral Masking and Interpolation Attack (SMIA): A Black-box Adversarial Attack against Voice Authentication and Anti-Spoofing Systems
Sep 09, 2025Voice Authentication Systems (VAS) use unique vocal characteristics for verification. They are increasingly integrated into high-security sectors such as banking and healthcare. Despite their improvements using deep learning, they face severe vulnerabilities from sophisticated threats like deepfakes and adversarial attacks. The emergence of realistic voice cloning complicates detection, as systems struggle to distinguish authentic from synthetic audio. While anti-spoofing countermeasures (CMs) exist to mitigate these risks, many rely on static detection models that can be bypassed by novel adversarial methods, leaving a critical security gap. To demonstrate this vulnerability, we propose the Spectral Masking and Interpolation Attack (SMIA), a novel method that strategically manipulates inaudible frequency regions of AI-generated audio. By altering the voice in imperceptible zones to the human ear, SMIA creates adversarial samples that sound authentic while deceiving CMs. We conducted a comprehensive evaluation of our attack against state-of-the-art (SOTA) models across multiple tasks, under simulated real-world conditions. SMIA achieved a strong attack success rate (ASR) of at least 82% against combined VAS/CM systems, at least 97.5% against standalone speaker verification systems, and 100% against countermeasures. These findings conclusively demonstrate that current security postures are insufficient against adaptive adversarial attacks. This work highlights the urgent need for a paradigm shift toward next-generation defenses that employ dynamic, context-aware frameworks capable of evolving with the threat landscape.
Multi-Scale Attention and Gated Shifting for Fine-Grained Event Spotting in Videos
Jul 10, 2025
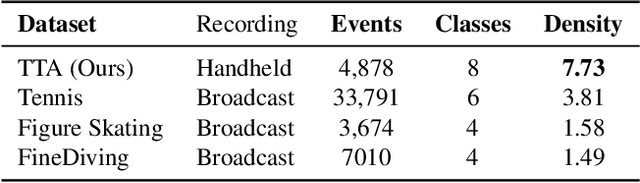
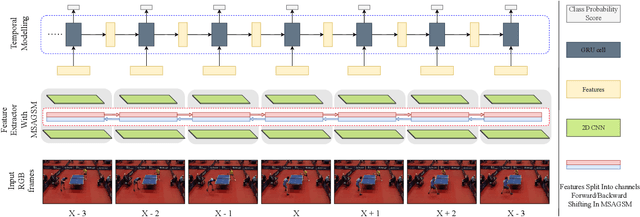
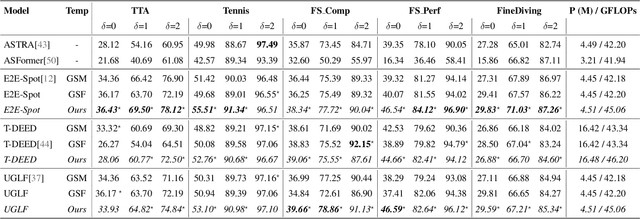
Precise Event Spotting (PES) in sports videos requires frame-level recognition of fine-grained actions from single-camera footage. Existing PES models typically incorporate lightweight temporal modules such as Gate Shift Module (GSM) or Gate Shift Fuse (GSF) to enrich 2D CNN feature extractors with temporal context. However, these modules are limited in both temporal receptive field and spatial adaptability. We propose a Multi-Scale Attention Gate Shift Module (MSAGSM) that enhances GSM with multi-scale temporal dilations and multi-head spatial attention, enabling efficient modeling of both short- and long-term dependencies while focusing on salient regions. MSAGSM is a lightweight plug-and-play module that can be easily integrated with various 2D backbones. To further advance the field, we introduce the Table Tennis Australia (TTA) dataset-the first PES benchmark for table tennis-containing over 4800 precisely annotated events. Extensive experiments across five PES benchmarks demonstrate that MSAGSM consistently improves performance with minimal overhead, setting new state-of-the-art results.
Far From Sight, Far From Mind: Inverse Distance Weighting for Graph Federated Recommendation
Jul 02, 2025Graph federated recommendation systems offer a privacy-preserving alternative to traditional centralized recommendation architectures, which often raise concerns about data security. While federated learning enables personalized recommendations without exposing raw user data, existing aggregation methods overlook the unique properties of user embeddings in this setting. Indeed, traditional aggregation methods fail to account for their complexity and the critical role of user similarity in recommendation effectiveness. Moreover, evolving user interactions require adaptive aggregation while preserving the influence of high-relevance anchor users (the primary users before expansion in graph-based frameworks). To address these limitations, we introduce Dist-FedAvg, a novel distance-based aggregation method designed to enhance personalization and aggregation efficiency in graph federated learning. Our method assigns higher aggregation weights to users with similar embeddings, while ensuring that anchor users retain significant influence in local updates. Empirical evaluations on multiple datasets demonstrate that Dist-FedAvg consistently outperforms baseline aggregation techniques, improving recommendation accuracy while maintaining seamless integration into existing federated learning frameworks.
Ensemble Elastic DQN: A novel multi-step ensemble approach to address overestimation in deep value-based reinforcement learning
Jun 06, 2025While many algorithmic extensions to Deep Q-Networks (DQN) have been proposed, there remains limited understanding of how different improvements interact. In particular, multi-step and ensemble style extensions have shown promise in reducing overestimation bias, thereby improving sample efficiency and algorithmic stability. In this paper, we introduce a novel algorithm called Ensemble Elastic Step DQN (EEDQN), which unifies ensembles with elastic step updates to stabilise algorithmic performance. EEDQN is designed to address two major challenges in deep reinforcement learning: overestimation bias and sample efficiency. We evaluated EEDQN against standard and ensemble DQN variants across the MinAtar benchmark, a set of environments that emphasise behavioral learning while reducing representational complexity. Our results show that EEDQN achieves consistently robust performance across all tested environments, outperforming baseline DQN methods and matching or exceeding state-of-the-art ensemble DQNs in final returns on most of the MinAtar environments. These findings highlight the potential of systematically combining algorithmic improvements and provide evidence that ensemble and multi-step methods, when carefully integrated, can yield substantial gains.
Navigating loss manifolds via rigid body dynamics: A promising avenue for robustness and generalisation
May 26, 2025



Training large neural networks through gradient-based optimization requires navigating high-dimensional loss landscapes, which often exhibit pathological geometry, leading to undesirable training dynamics. In particular, poor generalization frequently results from convergence to sharp minima that are highly sensitive to input perturbations, causing the model to overfit the training data while failing to generalize to unseen examples. Furthermore, these optimization procedures typically display strong dependence on the fine structure of the loss landscape, leading to unstable training dynamics, due to the fractal-like nature of the loss surface. In this work, we propose an alternative optimizer that simultaneously reduces this dependence, and avoids sharp minima, thereby improving generalization. This is achieved by simulating the motion of the center of a ball rolling on the loss landscape. The degree to which our optimizer departs from the standard gradient descent is controlled by a hyperparameter, representing the radius of the ball. Changing this hyperparameter allows for probing the loss landscape at different scales, making it a valuable tool for understanding its geometry.
A Comprehensive Analysis of Large Language Model Outputs: Similarity, Diversity, and Bias
May 14, 2025Large Language Models (LLMs) represent a major step toward artificial general intelligence, significantly advancing our ability to interact with technology. While LLMs perform well on Natural Language Processing tasks -- such as translation, generation, code writing, and summarization -- questions remain about their output similarity, variability, and ethical implications. For instance, how similar are texts generated by the same model? How does this compare across different models? And which models best uphold ethical standards? To investigate, we used 5{,}000 prompts spanning diverse tasks like generation, explanation, and rewriting. This resulted in approximately 3 million texts from 12 LLMs, including proprietary and open-source systems from OpenAI, Google, Microsoft, Meta, and Mistral. Key findings include: (1) outputs from the same LLM are more similar to each other than to human-written texts; (2) models like WizardLM-2-8x22b generate highly similar outputs, while GPT-4 produces more varied responses; (3) LLM writing styles differ significantly, with Llama 3 and Mistral showing higher similarity, and GPT-4 standing out for distinctiveness; (4) differences in vocabulary and tone underscore the linguistic uniqueness of LLM-generated content; (5) some LLMs demonstrate greater gender balance and reduced bias. These results offer new insights into the behavior and diversity of LLM outputs, helping guide future development and ethical evaluation.
Action Spotting and Precise Event Detection in Sports: Datasets, Methods, and Challenges
May 06, 2025Video event detection has become an essential component of sports analytics, enabling automated identification of key moments and enhancing performance analysis, viewer engagement, and broadcast efficiency. Recent advancements in deep learning, particularly Convolutional Neural Networks (CNNs) and Transformers, have significantly improved accuracy and efficiency in Temporal Action Localization (TAL), Action Spotting (AS), and Precise Event Spotting (PES). This survey provides a comprehensive overview of these three key tasks, emphasizing their differences, applications, and the evolution of methodological approaches. We thoroughly review and categorize existing datasets and evaluation metrics specifically tailored for sports contexts, highlighting the strengths and limitations of each. Furthermore, we analyze state-of-the-art techniques, including multi-modal approaches that integrate audio and visual information, methods utilizing self-supervised learning and knowledge distillation, and approaches aimed at generalizing across multiple sports. Finally, we discuss critical open challenges and outline promising research directions toward developing more generalized, efficient, and robust event detection frameworks applicable to diverse sports. This survey serves as a foundation for future research on efficient, generalizable, and multi-modal sports event detection.