 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-Warping Invariant Quantum Recurrent Neural Networks via Quantum-Classical Adaptive Gating
Jan 20, 2023

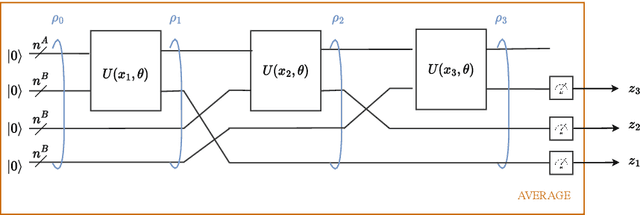
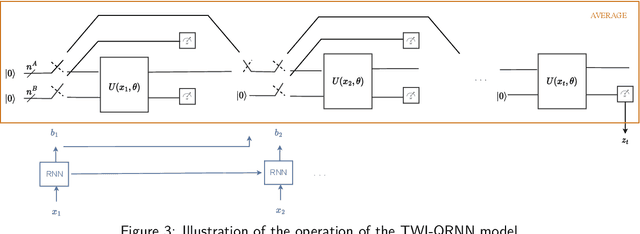

Adaptive gating plays a key role in temporal data processing via classical recurrent neural networks (RNN), as it facilitates retention of past information necessary to predict the future, providing a mechanism that preserves invariance to time warping transformations. This paper builds on quantum recurrent neural networks (QRNNs), a dynamic model with quantum memory, to introduce a novel class of temporal data processing quantum models that preserve invariance to time-warping transformations of the (classical) input-output sequences. The model, referred to as time warping-invariant QRNN (TWI-QRNN), augments a QRNN with a quantum-classical adaptive gating mechanism that chooses whether to apply a parameterized unitary transformation at each time step as a function of the past samples of the input sequence via a classical recurrent model. The TWI-QRNN model class is derived from first principles, and its capacity to successfully implement time-warping transformations is experimentally demonstrated on examples with classical or quantum dynamics.
Catalysis distillation neural network for the few shot open catalyst challenge
May 31, 2023The integration of artificial intelligence and science has resulted in substantial progress in computational chemistry methods for the design and discovery of novel catalysts. Nonetheless, the challenges of electrocatalytic reactions and developing a large-scale language model in catalysis persist, and the recent success of ChatGPT's (Chat Generative Pre-trained Transformer) few-shot methods surpassing BERT (Bidirectional Encoder Representation from Transformers) underscores the importance of addressing limited data, expensive computations, time constraints and structure-activity relationship in research. Hence, the development of few-shot techniques for catalysis is critical and essential, regardless of present and future requirements. This paper introduces the Few-Shot Open Catalyst Challenge 2023, a competition aimed at advancing the application of machine learning technology for predicting catalytic reactions on catalytic surfaces, with a specific focus on dual-atom catalysts in hydrogen peroxide electrocatalysis. To address the challenge of limited data in catalysis, we propose a machine learning approach based on MLP-Like and a framework called Catalysis Distillation Graph Neural Network (CDGNN). Our results demonstrate that CDGNN effectively learns embeddings from catalytic structures, enabling the capture of structure-adsorption relationships. This accomplishment has resulted in the utmost advanced and efficient determination of the reaction pathway for hydrogen peroxide, surpassing the current graph neural network approach by 16.1%.. Consequently, CDGNN presents a promising approach for few-shot learning in catalysis.
Bytes Are All You Need: Transformers Operating Directly On File Bytes
May 31, 2023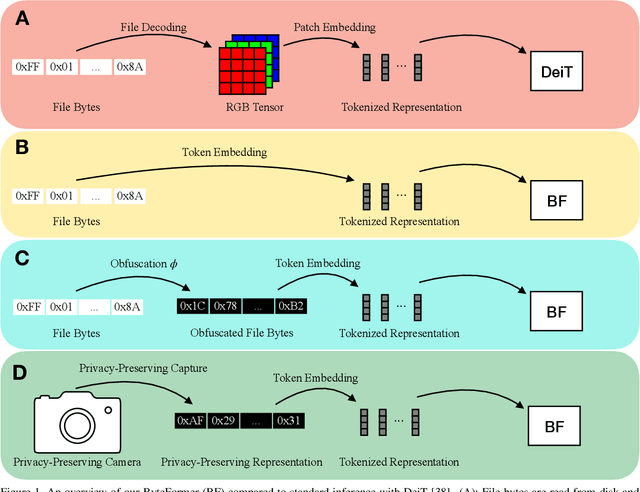

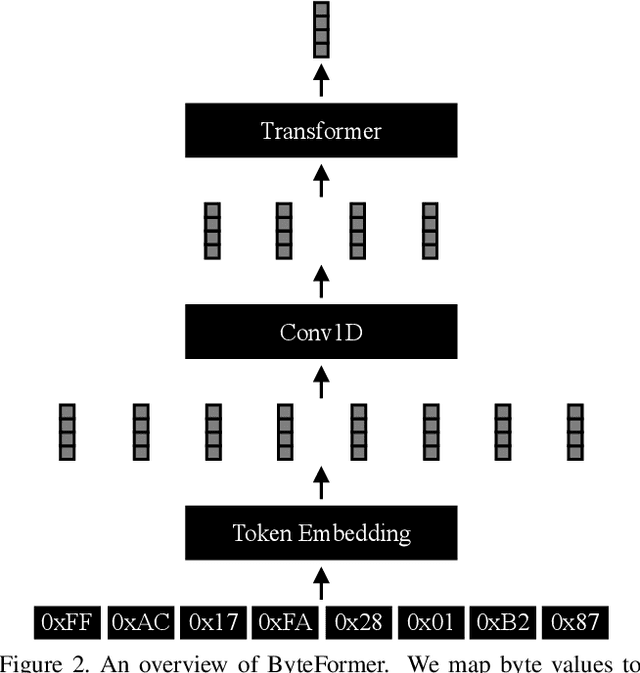
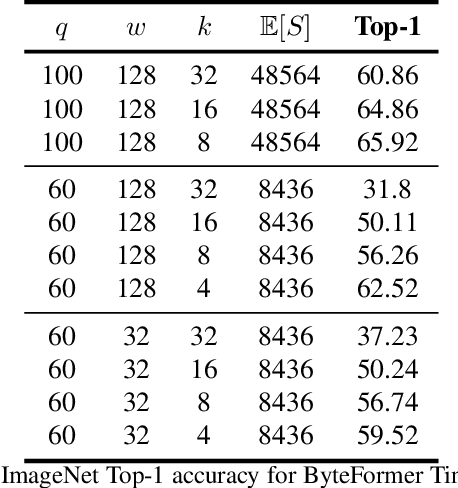
Modern deep learning approaches usually transform inputs into a modality-specific form. For example, the most common deep learning approach to image classification involves decoding image file bytes into an RGB tensor which is passed into a neural network. Instead, we investigate performing classification directly on file bytes, without the need for decoding files at inference time. Using file bytes as model inputs enables the development of models which can operate on multiple input modalities. Our model, \emph{ByteFormer}, achieves an ImageNet Top-1 classification accuracy of $77.33\%$ when training and testing directly on TIFF file bytes using a transformer backbone with configuration similar to DeiT-Ti ($72.2\%$ accuracy when operating on RGB images). Without modifications or hyperparameter tuning, ByteFormer achieves $95.42\%$ classification accuracy when operating on WAV files from the Speech Commands v2 dataset (compared to state-of-the-art accuracy of $98.7\%$). Additionally, we demonstrate that ByteFormer has applications in privacy-preserving inference. ByteFormer is capable of performing inference on particular obfuscated input representations with no loss of accuracy. We also demonstrate ByteFormer's ability to perform inference with a hypothetical privacy-preserving camera which avoids forming full images by consistently masking $90\%$ of pixel channels, while still achieving $71.35\%$ accuracy on ImageNet. Our code will be made available at https://github.com/apple/ml-cvnets/tree/main/examples/byteformer.
Evolutionary Solution Adaption for Multi-Objective Metal Cutting Process Optimization
May 31, 2023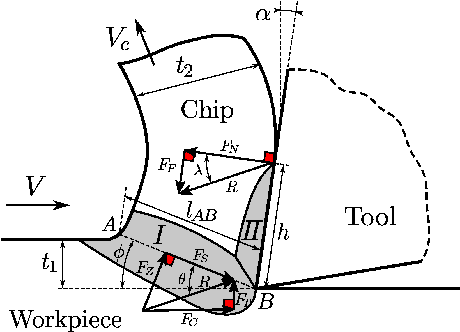

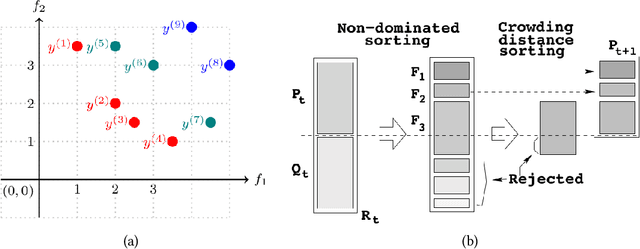
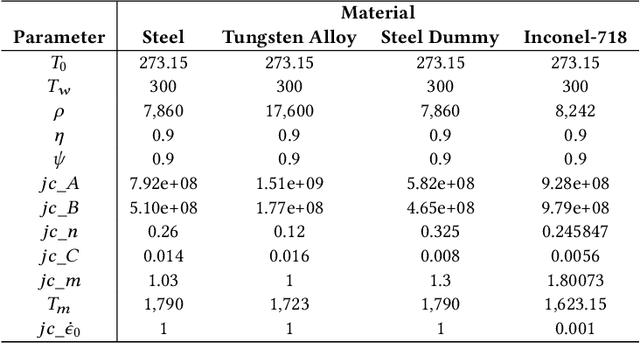
Optimizing manufacturing process parameters is typically a multi-objective problem with often contradictory objectives such as production quality and production time. If production requirements change, process parameters have to be optimized again. Since optimization usually requires costly simulations based on, for example, the Finite Element method, it is of great interest to have means to reduce the number of evaluations needed for optimization. To this end, we consider optimizing for different production requirements from the viewpoint of a framework for system flexibility that allows us to study the ability of an algorithm to transfer solutions from previous optimization tasks, which also relates to dynamic evolutionary optimization. Based on the extended Oxley model for orthogonal metal cutting, we introduce a multi-objective optimization benchmark where different materials define related optimization tasks, and use it to study the flexibility of NSGA-II, which we extend by two variants: 1) varying goals, that optimizes solutions for two tasks simultaneously to obtain in-between source solutions expected to be more adaptable, and 2) active-inactive genotype, that accommodates different possibilities that can be activated or deactivated. Results show that adaption with standard NSGA-II greatly reduces the number of evaluations required for optimization to a target goal, while the proposed variants further improve the adaption costs, although further work is needed towards making the methods advantageous for real applications.
M3ICRO: Machine Learning-Enabled Compact Photonic Tensor Core based on PRogrammable Multi-Operand Multimode Interference
May 31, 2023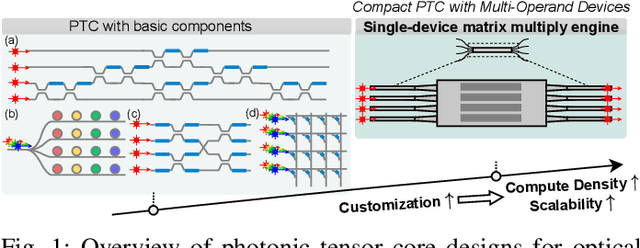
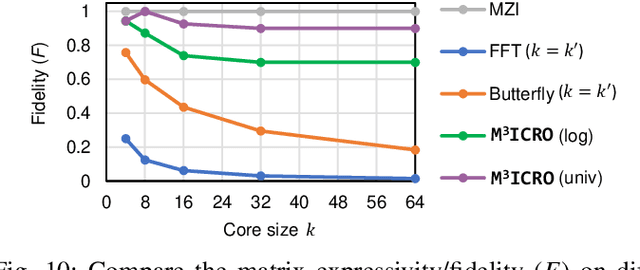
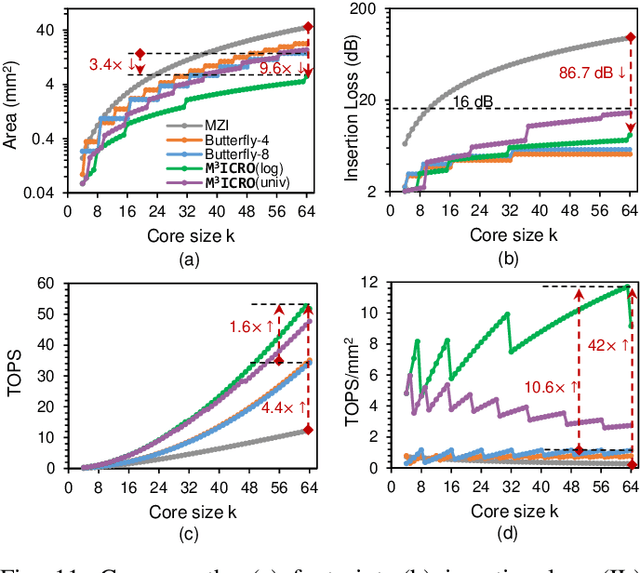
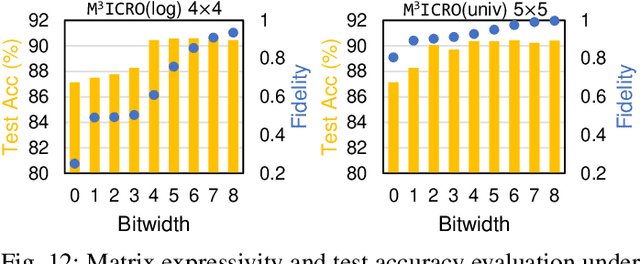
Photonic computing shows promise for transformative advancements in machine learning (ML) acceleration, offering ultra-fast speed, massive parallelism, and high energy efficiency. However, current photonic tensor core (PTC) designs based on standard optical components hinder scalability and compute density due to their large spatial footprint. To address this, we propose an ultra-compact PTC using customized programmable multi-operand multimode interference (MOMMI) devices, named M3ICRO. The programmable MOMMI leverages the intrinsic light propagation principle, providing a single-device programmable matrix unit beyond the conventional computing paradigm of one multiply-accumulate (MAC) operation per device. To overcome the optimization difficulty of customized devices that often requires time-consuming simulation, we apply ML for optics to predict the device behavior and enable a differentiable optimization flow. We thoroughly investigate the reconfigurability and matrix expressivity of our customized PTC, and introduce a novel block unfolding method to fully exploit the computing capabilities of a complex-valued PTC for near-universal real-valued linear transformations. Extensive evaluations demonstrate that M3ICRO achieves a 3.4-9.6x smaller footprint, 1.6-4.4x higher speed, 10.6-42x higher compute density, 3.7-12x higher system throughput, and superior noise robustness compared to state-of-the-art coherent PTC designs, while maintaining close-to-digital task accuracy across various ML benchmarks. Our code is open-sourced at https://github.com/JeremieMelo/M3ICRO-MOMMI.
TOFG: A Unified and Fine-Grained Environment Representation in Autonomous Driving
May 31, 2023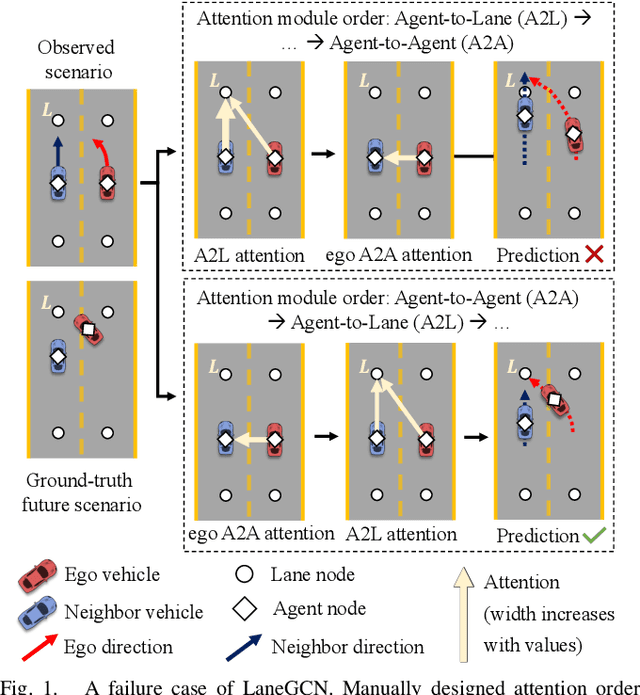
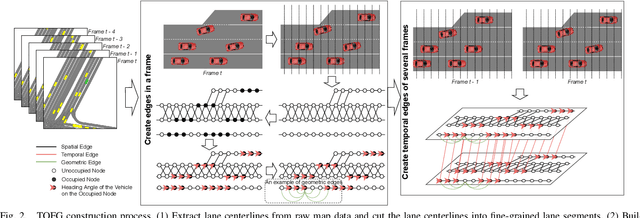
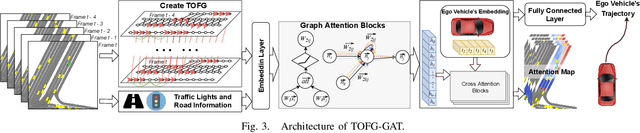
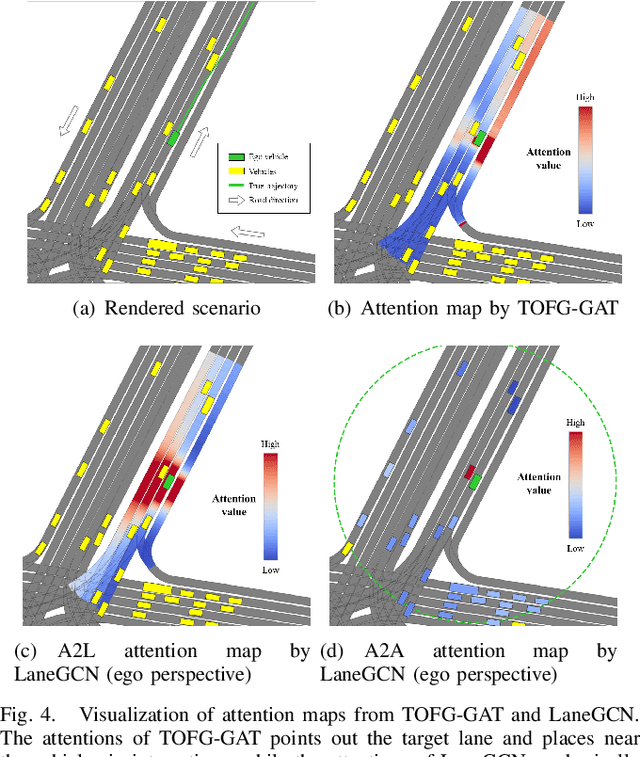
In autonomous driving, an accurate understanding of environment, e.g., the vehicle-to-vehicle and vehicle-to-lane interactions, plays a critical role in many driving tasks such as trajectory prediction and motion planning. Environment information comes from high-definition (HD) map and historical trajectories of vehicles. Due to the heterogeneity of the map data and trajectory data, many data-driven models for trajectory prediction and motion planning extract vehicle-to-vehicle and vehicle-to-lane interactions in a separate and sequential manner. However, such a manner may capture biased interpretation of interactions, causing lower prediction and planning accuracy. Moreover, separate extraction leads to a complicated model structure and hence the overall efficiency and scalability are sacrificed. To address the above issues, we propose an environment representation, Temporal Occupancy Flow Graph (TOFG). Specifically, the occupancy flow-based representation unifies the map information and vehicle trajectories into a homogeneous data format and enables a consistent prediction. The temporal dependencies among vehicles can help capture the change of occupancy flow timely to further promote model performance. To demonstrate that TOFG is capable of simplifying the model architecture, we incorporate TOFG with a simple graph attention (GAT) based neural network and propose TOFG-GAT, which can be used for both trajectory prediction and motion planning. Experiment results show that TOFG-GAT achieves better or competitive performance than all the SOTA baselines with less training time.
Distilling Efficient Language-Specific Models for Cross-Lingual Transfer
Jun 02, 2023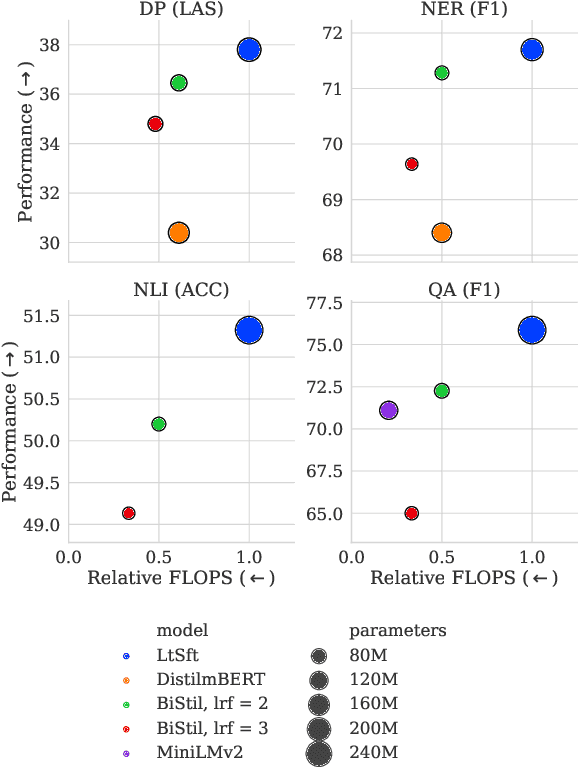
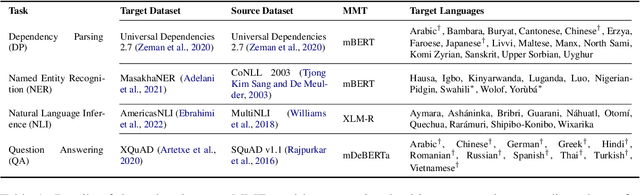
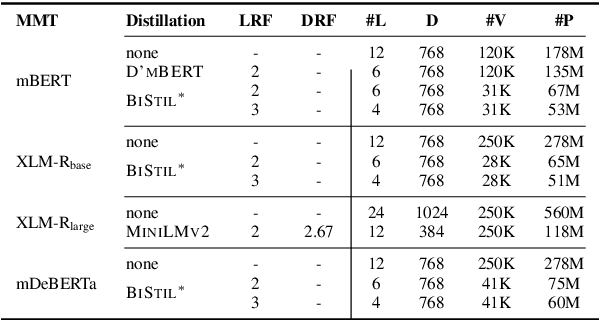

Massively multilingual Transformers (MMTs), such as mBERT and XLM-R, are widely used for cross-lingual transfer learning. While these are pretrained to represent hundreds of languages, end users of NLP systems are often interested only in individual languages. For such purposes, the MMTs' language coverage makes them unnecessarily expensive to deploy in terms of model size, inference time, energy, and hardware cost. We thus propose to extract compressed, language-specific models from MMTs which retain the capacity of the original MMTs for cross-lingual transfer. This is achieved by distilling the MMT bilingually, i.e., using data from only the source and target language of interest. Specifically, we use a two-phase distillation approach, termed BiStil: (i) the first phase distils a general bilingual model from the MMT, while (ii) the second, task-specific phase sparsely fine-tunes the bilingual "student" model using a task-tuned variant of the original MMT as its "teacher". We evaluate this distillation technique in zero-shot cross-lingual transfer across a number of standard cross-lingual benchmarks. The key results indicate that the distilled models exhibit minimal degradation in target language performance relative to the base MMT despite being significantly smaller and faster. Furthermore, we find that they outperform multilingually distilled models such as DistilmBERT and MiniLMv2 while having a very modest training budget in comparison, even on a per-language basis. We also show that bilingual models distilled from MMTs greatly outperform bilingual models trained from scratch. Our code and models are available at https://github.com/AlanAnsell/bistil.
Minding Language Models' (Lack of) Theory of Mind: A Plug-and-Play Multi-Character Belief Tracker
Jun 01, 2023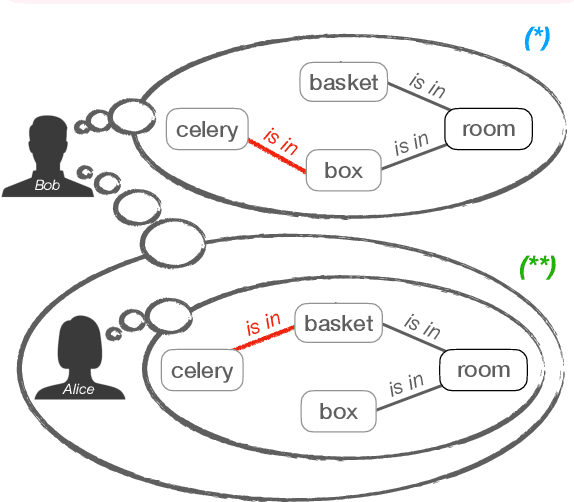

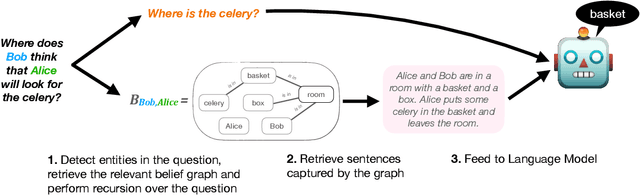
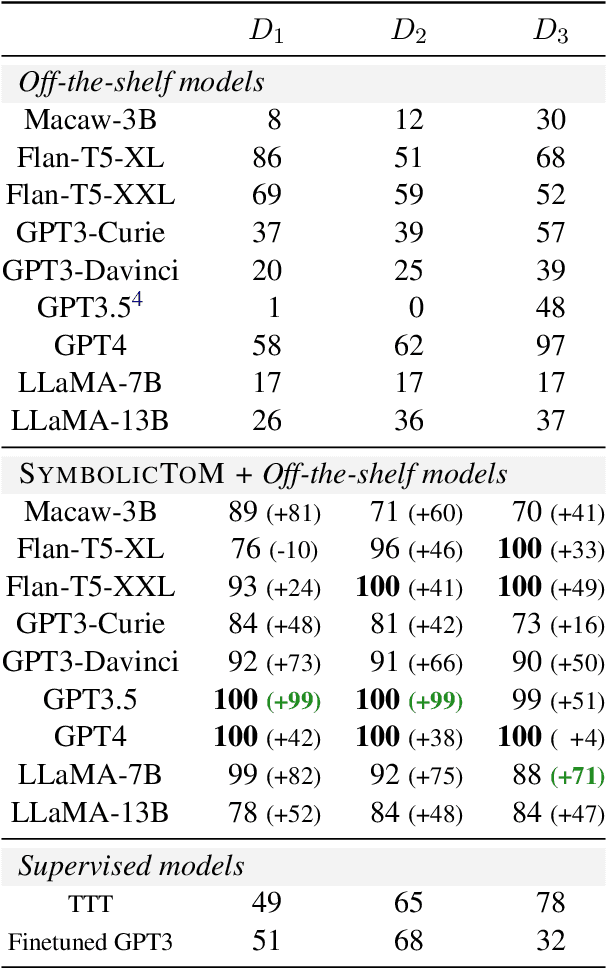
Theory of Mind (ToM)$\unicode{x2014}$the ability to reason about the mental states of other people$\unicode{x2014}$is a key element of our social intelligence. Yet, despite their ever more impressive performance, large-scale neural language models still lack basic theory of mind capabilities out-of-the-box. We posit that simply scaling up models will not imbue them with theory of mind due to the inherently symbolic and implicit nature of the phenomenon, and instead investigate an alternative: can we design a decoding-time algorithm that enhances theory of mind of off-the-shelf neural language models without explicit supervision? We present SymbolicToM, a plug-and-play approach to reason about the belief states of multiple characters in reading comprehension tasks via explicit symbolic representation. More concretely, our approach tracks each entity's beliefs, their estimation of other entities' beliefs, and higher-order levels of reasoning, all through graphical representations, allowing for more precise and interpretable reasoning than previous approaches. Empirical results on the well-known ToMi benchmark (Le et al., 2019) demonstrate that SymbolicToM dramatically enhances off-the-shelf neural networks' theory of mind in a zero-shot setting while showing robust out-of-distribution performance compared to supervised baselines. Our work also reveals spurious patterns in existing theory of mind benchmarks, emphasizing the importance of out-of-distribution evaluation and methods that do not overfit a particular dataset.
S$^2$ME: Spatial-Spectral Mutual Teaching and Ensemble Learning for Scribble-supervised Polyp Segmentation
Jun 01, 2023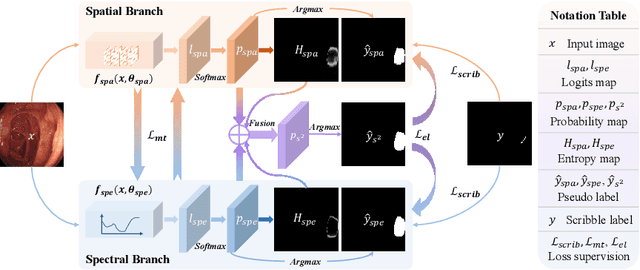
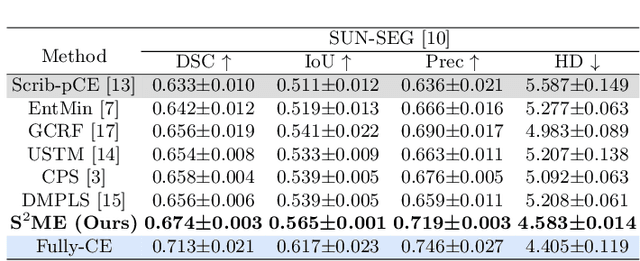
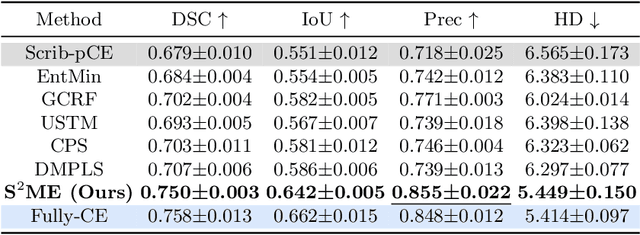
Fully-supervised polyp segmentation has accomplished significant triumphs over the years in advancing the early diagnosis of colorectal cancer. However, label-efficient solutions from weak supervision like scribbles are rarely explored yet primarily meaningful and demanding in medical practice due to the expensiveness and scarcity of densely-annotated polyp data. Besides, various deployment issues, including data shifts and corruption, put forward further requests for model generalization and robustness. To address these concerns, we design a framework of Spatial-Spectral Dual-branch Mutual Teaching and Entropy-guided Pseudo Label Ensemble Learning (S$^2$ME). Concretely, for the first time in weakly-supervised medical image segmentation, we promote the dual-branch co-teaching framework by leveraging the intrinsic complementarity of features extracted from the spatial and spectral domains and encouraging cross-space consistency through collaborative optimization. Furthermore, to produce reliable mixed pseudo labels, which enhance the effectiveness of ensemble learning, we introduce a novel adaptive pixel-wise fusion technique based on the entropy guidance from the spatial and spectral branches. Our strategy efficiently mitigates the deleterious effects of uncertainty and noise present in pseudo labels and surpasses previous alternatives in terms of efficacy. Ultimately, we formulate a holistic optimization objective to learn from the hybrid supervision of scribbles and pseudo labels. Extensive experiments and evaluation on four public datasets demonstrate the superiority of our method regarding in-distribution accuracy, out-of-distribution generalization, and robustness, highlighting its promising clinical significance. Our code is available at https://github.com/lofrienger/S2ME.
MTS-Mixers: Multivariate Time Series Forecasting via Factorized Temporal and Channel Mixing
Feb 09, 2023
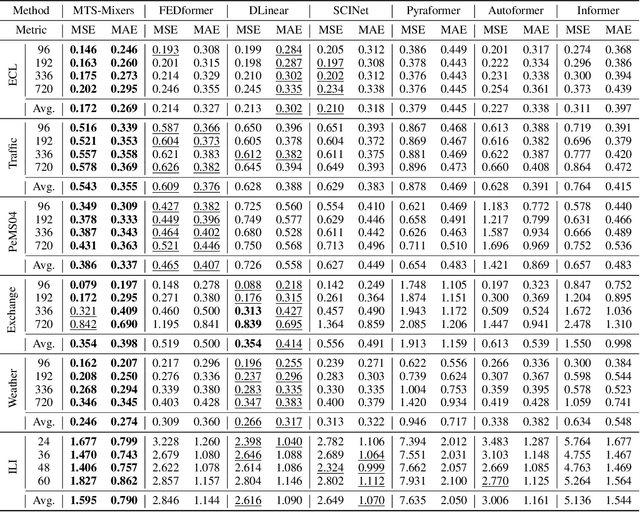
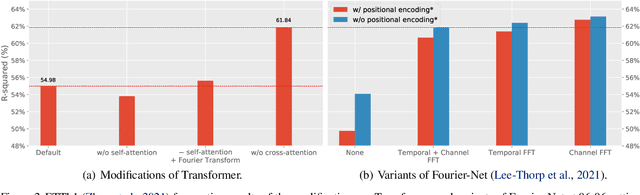
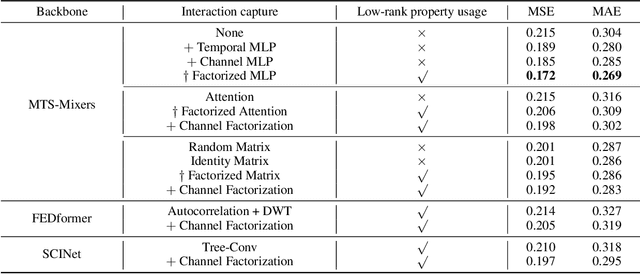
Multivariate time series forecasting has been widely used in various practical scenarios. Recently, Transformer-based models have shown significant potential in forecasting tasks due to the capture of long-range dependencies. However, recent studies in the vision and NLP fields show that the role of attention modules is not clear, which can be replaced by other token aggregation operations. This paper investigates the contributions and deficiencies of attention mechanisms on the performance of time series forecasting. Specifically, we find that (1) attention is not necessary for capturing temporal dependencies, (2) the entanglement and redundancy in the capture of temporal and channel interaction affect the forecasting performance, and (3) it is important to model the mapping between the input and the prediction sequence. To this end, we propose MTS-Mixers, which use two factorized modules to capture temporal and channel dependencies. Experimental results on several real-world datasets show that MTS-Mixers outperform existing Transformer-based models with higher efficiency.