 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Tokenizer Distillation via Approximate Likelihood Matching
Mar 27, 2025Distillation has shown remarkable success in transferring knowledge from a Large Language Model (LLM) teacher to a student LLM. However, current distillation methods predominantly require the same tokenizer between the teacher and the student, restricting their applicability to only a small subset of teacher-student pairs. In this work, we develop a cross-tokenizer distillation method to solve this crucial deficiency. Our method is the first to enable cross-tokenizer distillation without a next-token prediction loss as the main objective, instead purely maximizing the student predictions' similarity to the teacher's predictions (known as pure distillation), while also being robust to large mismatches between the teacher and the student tokenizer function and vocabulary. Empirically, our method enables substantially improved performance as tested on two use cases. First, we show that viewing tokenizer transfer as self-distillation enables unprecedently effective transfer across tokenizers. We transfer (subword-level) Llama and Gemma models to byte-level tokenization more effectively than prior methods transfer to a similar subword tokenizer under a comparable training budget. Transferring different base models to the same tokenizer also enables ensembling them (e.g., via averaging their predicted probabilities) which boosts performance. Second, we use our cross-tokenizer distillation method to distil a large maths-specialized LLM into a smaller model, achieving competitive maths problem-solving performance. Overall, our results make substantial strides toward better adaptability and enhanced interaction between different LLMs.
Towards Modular LLMs by Building and Reusing a Library of LoRAs
May 18, 2024



The growing number of parameter-efficient adaptations of a base large language model (LLM) calls for studying whether we can reuse such trained adapters to improve performance for new tasks. We study how to best build a library of adapters given multi-task data and devise techniques for both zero-shot and supervised task generalization through routing in such library. We benchmark existing approaches to build this library and introduce model-based clustering, MBC, a method that groups tasks based on the similarity of their adapter parameters, indirectly optimizing for transfer across the multi-task dataset. To re-use the library, we present a novel zero-shot routing mechanism, Arrow, which enables dynamic selection of the most relevant adapters for new inputs without the need for retraining. We experiment with several LLMs, such as Phi-2 and Mistral, on a wide array of held-out tasks, verifying that MBC-based adapters and Arrow routing lead to superior generalization to new tasks. We make steps towards creating modular, adaptable LLMs that can match or outperform traditional joint training.
Zero-Shot Tokenizer Transfer
May 13, 2024



Language models (LMs) are bound to their tokenizer, which maps raw text to a sequence of vocabulary items (tokens). This restricts their flexibility: for example, LMs trained primarily on English may still perform well in other natural and programming languages, but have vastly decreased efficiency due to their English-centric tokenizer. To mitigate this, we should be able to swap the original LM tokenizer with an arbitrary one, on the fly, without degrading performance. Hence, in this work we define a new problem: Zero-Shot Tokenizer Transfer (ZeTT). The challenge at the core of ZeTT is finding embeddings for the tokens in the vocabulary of the new tokenizer. Since prior heuristics for initializing embeddings often perform at chance level in a ZeTT setting, we propose a new solution: we train a hypernetwork taking a tokenizer as input and predicting the corresponding embeddings. We empirically demonstrate that the hypernetwork generalizes to new tokenizers both with encoder (e.g., XLM-R) and decoder LLMs (e.g., Mistral-7B). Our method comes close to the original models' performance in cross-lingual and coding tasks while markedly reducing the length of the tokenized sequence. We also find that the remaining gap can be quickly closed by continued training on less than 1B tokens. Finally, we show that a ZeTT hypernetwork trained for a base (L)LM can also be applied to fine-tuned variants without extra training. Overall, our results make substantial strides toward detaching LMs from their tokenizer.
Model Merging by Uncertainty-Based Gradient Matching
Oct 19, 2023



Models trained on different datasets can be merged by a weighted-averaging of their parameters, but why does it work and when can it fail? Here, we connect the inaccuracy of weighted-averaging to mismatches in the gradients and propose a new uncertainty-based scheme to improve the performance by reducing the mismatch. The connection also reveals implicit assumptions in other schemes such as averaging, task arithmetic, and Fisher-weighted averaging. Our new method gives consistent improvements for large language models and vision transformers, both in terms of performance and robustness to hyperparameters.
Distilling Efficient Language-Specific Models for Cross-Lingual Transfer
Jun 02, 2023



Massively multilingual Transformers (MMTs), such as mBERT and XLM-R, are widely used for cross-lingual transfer learning. While these are pretrained to represent hundreds of languages, end users of NLP systems are often interested only in individual languages. For such purposes, the MMTs' language coverage makes them unnecessarily expensive to deploy in terms of model size, inference time, energy, and hardware cost. We thus propose to extract compressed, language-specific models from MMTs which retain the capacity of the original MMTs for cross-lingual transfer. This is achieved by distilling the MMT bilingually, i.e., using data from only the source and target language of interest. Specifically, we use a two-phase distillation approach, termed BiStil: (i) the first phase distils a general bilingual model from the MMT, while (ii) the second, task-specific phase sparsely fine-tunes the bilingual "student" model using a task-tuned variant of the original MMT as its "teacher". We evaluate this distillation technique in zero-shot cross-lingual transfer across a number of standard cross-lingual benchmarks. The key results indicate that the distilled models exhibit minimal degradation in target language performance relative to the base MMT despite being significantly smaller and faster. Furthermore, we find that they outperform multilingually distilled models such as DistilmBERT and MiniLMv2 while having a very modest training budget in comparison, even on a per-language basis. We also show that bilingual models distilled from MMTs greatly outperform bilingual models trained from scratch. Our code and models are available at https://github.com/AlanAnsell/bistil.
Modular Deep Learning
Feb 22, 2023Transfer learning has recently become the dominant paradigm of machine learning. Pre-trained models fine-tuned for downstream tasks achieve better performance with fewer labelled examples. Nonetheless, it remains unclear how to develop models that specialise towards multiple tasks without incurring negative interference and that generalise systematically to non-identically distributed tasks. Modular deep learning has emerged as a promising solution to these challenges. In this framework, units of computation are often implemented as autonomous parameter-efficient modules. Information is conditionally routed to a subset of modules and subsequently aggregated. These properties enable positive transfer and systematic generalisation by separating computation from routing and updating modules locally. We offer a survey of modular architectures, providing a unified view over several threads of research that evolved independently in the scientific literature. Moreover, we explore various additional purposes of modularity, including scaling language models, causal inference, programme induction, and planning in reinforcement learning. Finally, we report various concrete applications where modularity has been successfully deployed such as cross-lingual and cross-modal knowledge transfer. Related talks and projects to this survey, are available at https://www.modulardeeplearning.com/.
Exposing Cross-Lingual Lexical Knowledge from Multilingual Sentence Encoders
Apr 30, 2022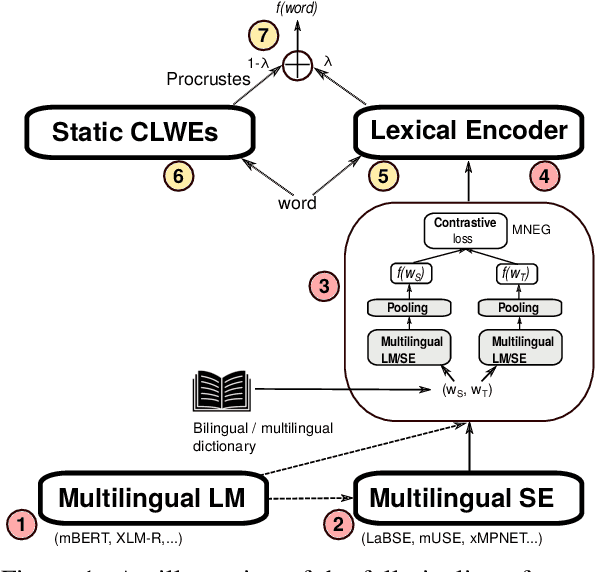
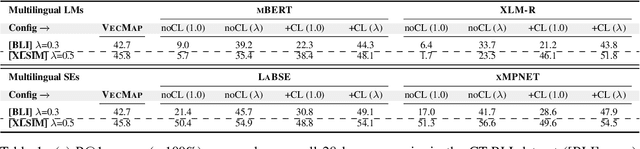
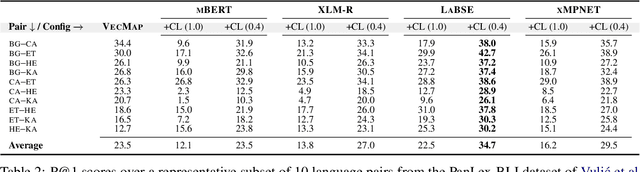

Pretrained multilingual language models (LMs) can be successfully transformed into multilingual sentence encoders (SEs; e.g., LaBSE, xMPNET) via additional fine-tuning or model distillation on parallel data. However, it remains uncertain how to best leverage their knowledge to represent sub-sentence lexical items (i.e., words and phrases) in cross-lingual lexical tasks. In this work, we probe these SEs for the amount of cross-lingual lexical knowledge stored in their parameters, and compare them against the original multilingual LMs. We also devise a novel method to expose this knowledge by additionally fine-tuning multilingual models through inexpensive contrastive learning procedure, requiring only a small amount of word translation pairs. We evaluate our method on bilingual lexical induction (BLI), cross-lingual lexical semantic similarity, and cross-lingual entity linking, and report substantial gains on standard benchmarks (e.g., +10 Precision@1 points in BLI), validating that the SEs such as LaBSE can be 'rewired' into effective cross-lingual lexical encoders. Moreover, we show that resulting representations can be successfully interpolated with static embeddings from cross-lingual word embedding spaces to further boost the performance in lexical tasks. In sum, our approach provides an effective tool for exposing and harnessing multilingual lexical knowledge 'hidden' in multilingual sentence encoders.
Cross-Lingual Dialogue Dataset Creation via Outline-Based Generation
Jan 31, 2022Multilingual task-oriented dialogue (ToD) facilitates access to services and information for many (communities of) speakers. Nevertheless, the potential of this technology is not fully realised, as current datasets for multilingual ToD - both for modular and end-to-end modelling - suffer from severe limitations. 1) When created from scratch, they are usually small in scale and fail to cover many possible dialogue flows. 2) Translation-based ToD datasets might lack naturalness and cultural specificity in the target language. In this work, to tackle these limitations we propose a novel outline-based annotation process for multilingual ToD datasets, where domain-specific abstract schemata of dialogue are mapped into natural language outlines. These in turn guide the target language annotators in writing a dialogue by providing instructions about each turn's intents and slots. Through this process we annotate a new large-scale dataset for training and evaluation of multilingual and cross-lingual ToD systems. Our Cross-lingual Outline-based Dialogue dataset (termed COD) enables natural language understanding, dialogue state tracking, and end-to-end dialogue modelling and evaluation in 4 diverse languages: Arabic, Indonesian, Russian, and Kiswahili. Qualitative and quantitative analyses of COD versus an equivalent translation-based dataset demonstrate improvements in data quality, unlocked by the outline-based approach. Finally, we benchmark a series of state-of-the-art systems for cross-lingual ToD, setting reference scores for future work and demonstrating that COD prevents over-inflated performance, typically met with prior translation-based ToD datasets.
IGLUE: A Benchmark for Transfer Learning across Modalities, Tasks, and Languages
Jan 27, 2022
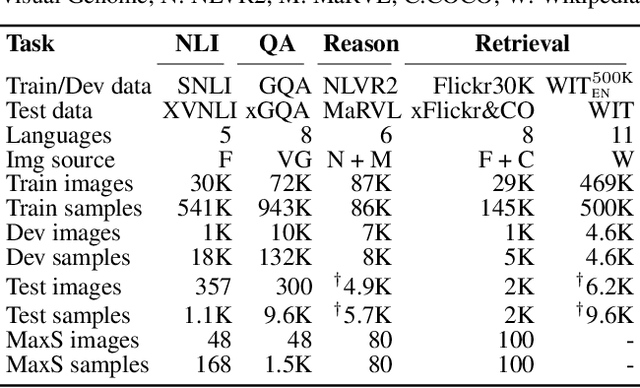
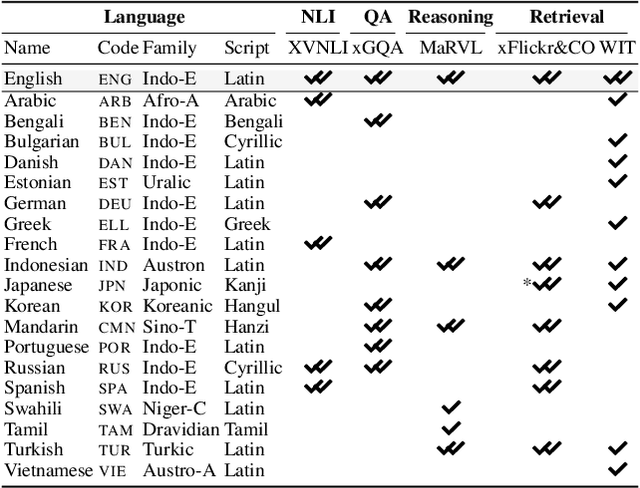
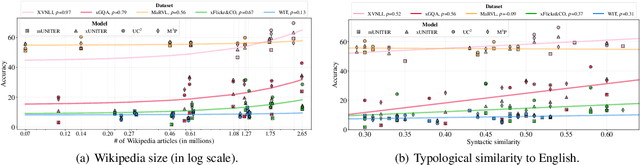
Reliable evaluation benchmarks designed for replicability and comprehensiveness have driven progress in machine learning. Due to the lack of a multilingual benchmark, however, vision-and-language research has mostly focused on English language tasks. To fill this gap, we introduce the Image-Grounded Language Understanding Evaluation benchmark. IGLUE brings together - by both aggregating pre-existing datasets and creating new ones - visual question answering, cross-modal retrieval, grounded reasoning, and grounded entailment tasks across 20 diverse languages. Our benchmark enables the evaluation of multilingual multimodal models for transfer learning, not only in a zero-shot setting, but also in newly defined few-shot learning setups. Based on the evaluation of the available state-of-the-art models, we find that translate-test transfer is superior to zero-shot transfer and that few-shot learning is hard to harness for many tasks. Moreover, downstream performance is partially explained by the amount of available unlabelled textual data for pretraining, and only weakly by the typological distance of target-source languages. We hope to encourage future research efforts in this area by releasing the benchmark to the community.
Composable Sparse Fine-Tuning for Cross-Lingual Transfer
Oct 14, 2021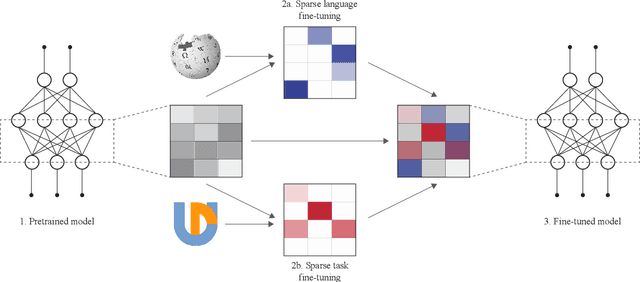
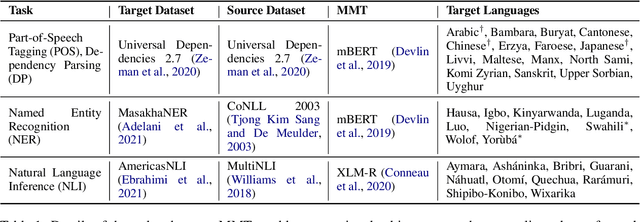
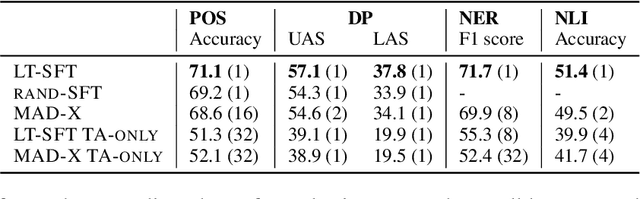
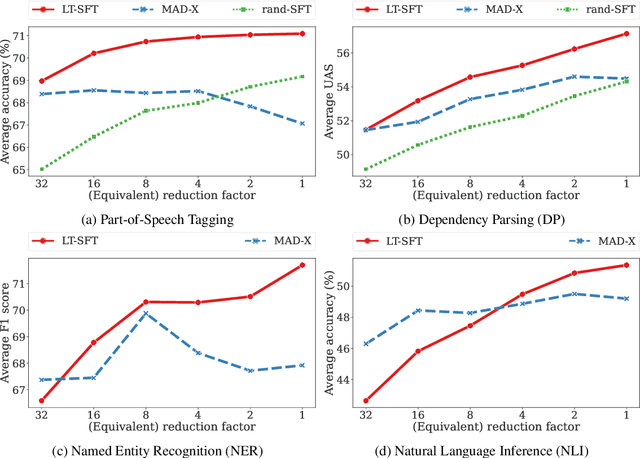
Fine-tuning all parameters of a pre-trained model has become the mainstream approach for transfer learning. To increase its efficiency and prevent catastrophic forgetting and interference, techniques like adapters and sparse fine-tuning have been developed. Adapters are modular, as they can be combined to adapt a model towards different facets of knowledge (e.g., dedicated language and/or task adapters). Sparse fine-tuning is expressive, as it controls the behavior of all model components. In this work, we introduce a new fine-tuning method with both these desirable properties. In particular, we learn sparse, real-valued masks based on a simple variant of the Lottery Ticket Hypothesis. Task-specific masks are obtained from annotated data in a source language, and language-specific masks from masked language modeling in a target language. Both these masks can then be composed with the pre-trained model. Unlike adapter-based fine-tuning, this method neither increases the number of parameters at inference time nor alters the original model architecture. Most importantly, it outperforms adapters in zero-shot cross-lingual transfer by a large margin in a series of multilingual benchmarks, including Universal Dependencies, MasakhaNER, and AmericasNLI. Based on an in-depth analysis, we additionally find that sparsity is crucial to prevent both 1) interference between the fine-tunings to be composed and 2) overfitting. We release the code and models at https://github.com/cambridgeltl/composable-sft.