 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Zero-Shot ECG Classification with Multimodal Learning and Test-time Clinical Knowledge Enhancement
Mar 11, 2024
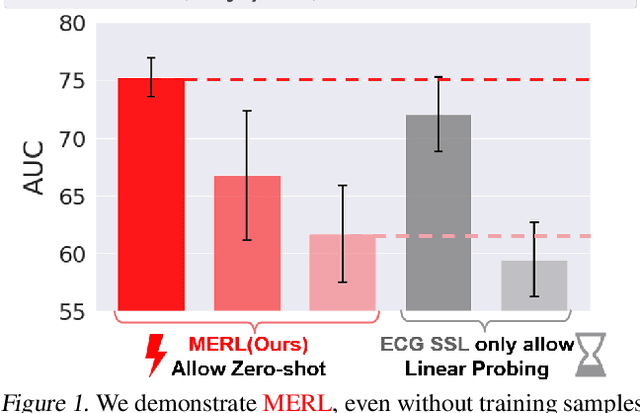
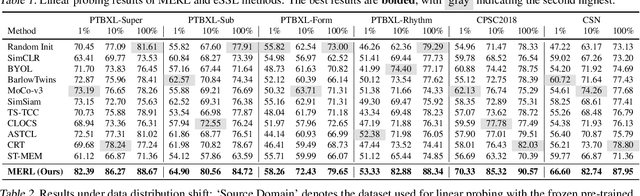
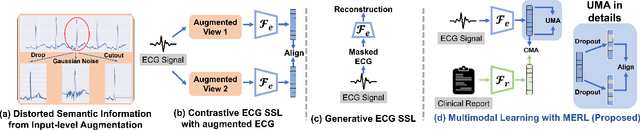
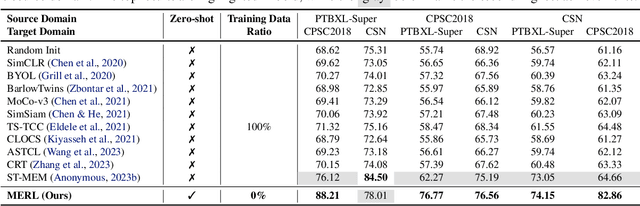
Electrocardiograms (ECGs) are non-invasive diagnostic tools crucial for detecting cardiac arrhythmic diseases in clinical practice. While ECG Self-supervised Learning (eSSL) methods show promise in representation learning from unannotated ECG data, they often overlook the clinical knowledge that can be found in reports. This oversight and the requirement for annotated samples for downstream tasks limit eSSL's versatility. In this work, we address these issues with the Multimodal ECG Representation Learning (MERL}) framework. Through multimodal learning on ECG records and associated reports, MERL is capable of performing zero-shot ECG classification with text prompts, eliminating the need for training data in downstream tasks. At test time, we propose the Clinical Knowledge Enhanced Prompt Engineering (CKEPE) approach, which uses Large Language Models (LLMs) to exploit external expert-verified clinical knowledge databases, generating more descriptive prompts and reducing hallucinations in LLM-generated content to boost zero-shot classification. Based on MERL, we perform the first benchmark across six public ECG datasets, showing the superior performance of MERL compared against eSSL methods. Notably, MERL achieves an average AUC score of 75.2% in zero-shot classification (without training data), 3.2% higher than linear probed eSSL methods with 10\% annotated training data, averaged across all six datasets.
Enhancing Demand Prediction in Open Systems by Cartogram-aided Deep Learning
Mar 24, 2024Predicting temporal patterns across various domains poses significant challenges due to their nuanced and often nonlinear trajectories. To address this challenge, prediction frameworks have been continuously refined, employing data-driven statistical methods, mathematical models, and machine learning. Recently, as one of the challenging systems, shared transport systems such as public bicycles have gained prominence due to urban constraints and environmental concerns. Predicting rental and return patterns at bicycle stations remains a formidable task due to the system's openness and imbalanced usage patterns across stations. In this study, we propose a deep learning framework to predict rental and return patterns by leveraging cartogram approaches. The cartogram approach facilitates the prediction of demand for newly installed stations with no training data as well as long-period prediction, which has not been achieved before. We apply this method to public bicycle rental-and-return data in Seoul, South Korea, employing a spatial-temporal convolutional graph attention network. Our improved architecture incorporates batch attention and modified node feature updates for better prediction accuracy across different time scales. We demonstrate the effectiveness of our framework in predicting temporal patterns and its potential applications.
Robust Diffusion Models for Adversarial Purification
Mar 24, 2024Diffusion models (DMs) based adversarial purification (AP) has shown to be the most powerful alternative to adversarial training (AT). However, these methods neglect the fact that pre-trained diffusion models themselves are not robust to adversarial attacks as well. Additionally, the diffusion process can easily destroy semantic information and generate a high quality image but totally different from the original input image after the reverse process, leading to degraded standard accuracy. To overcome these issues, a natural idea is to harness adversarial training strategy to retrain or fine-tune the pre-trained diffusion model, which is computationally prohibitive. We propose a novel robust reverse process with adversarial guidance, which is independent of given pre-trained DMs and avoids retraining or fine-tuning the DMs. This robust guidance can not only ensure to generate purified examples retaining more semantic content but also mitigate the accuracy-robustness trade-off of DMs for the first time, which also provides DM-based AP an efficient adaptive ability to new attacks. Extensive experiments are conducted to demonstrate that our method achieves the state-of-the-art results and exhibits generalization against different attacks.
HMD-Poser: On-Device Real-time Human Motion Tracking from Scalable Sparse Observations
Mar 06, 2024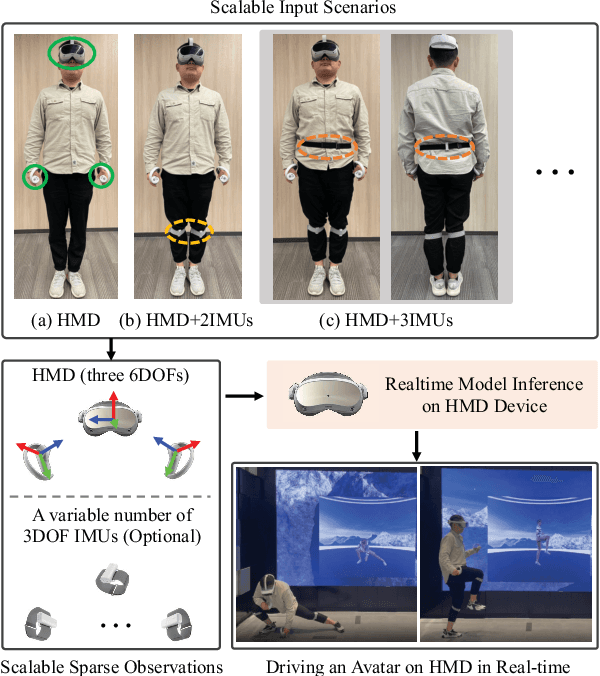
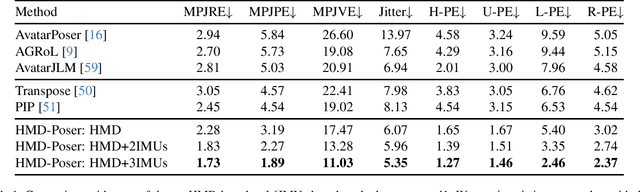
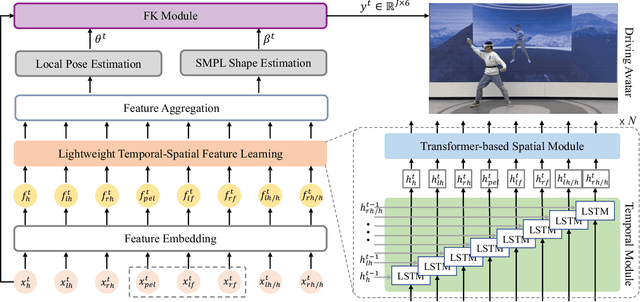
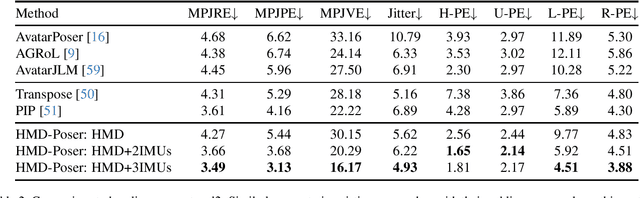
It is especially challenging to achieve real-time human motion tracking on a standalone VR Head-Mounted Display (HMD) such as Meta Quest and PICO. In this paper, we propose HMD-Poser, the first unified approach to recover full-body motions using scalable sparse observations from HMD and body-worn IMUs. In particular, it can support a variety of input scenarios, such as HMD, HMD+2IMUs, HMD+3IMUs, etc. The scalability of inputs may accommodate users' choices for both high tracking accuracy and easy-to-wear. A lightweight temporal-spatial feature learning network is proposed in HMD-Poser to guarantee that the model runs in real-time on HMDs. Furthermore, HMD-Poser presents online body shape estimation to improve the position accuracy of body joints. Extensive experimental results on the challenging AMASS dataset show that HMD-Poser achieves new state-of-the-art results in both accuracy and real-time performance. We also build a new free-dancing motion dataset to evaluate HMD-Poser's on-device performance and investigate the performance gap between synthetic data and real-captured sensor data. Finally, we demonstrate our HMD-Poser with a real-time Avatar-driving application on a commercial HMD. Our code and free-dancing motion dataset are available https://pico-ai-team.github.io/hmd-poser
Bi-objective Optimization in Role Mining
Mar 25, 2024Role mining is a technique used to derive a role-based authorization policy from an existing policy. Given a set of users $U$, a set of permissions $P$ and a user-permission authorization relation $\mahtit{UPA}\subseteq U\times P$, a role mining algorithm seeks to compute a set of roles $R$, a user-role authorization relation $\mathit{UA}\subseteq U\times R$ and a permission-role authorization relation $\mathit{PA}\subseteq R\times P$, such that the composition of $\mathit{UA}$ and $\mathit{PA}$ is close (in some appropriate sense) to $\mathit{UPA}$. In this paper, we first introduce the Generalized Noise Role Mining problem (GNRM) -- a generalization of the MinNoise Role Mining problem -- which we believe has considerable practical relevance. Extending work of Fomin et al., we show that GNRM is fixed parameter tractable, with parameter $r + k$, where $r$ is the number of roles in the solution and $k$ is the number of discrepancies between $\mathit{UPA}$ and the relation defined by the composition of $\mathit{UA}$ and $\mathit{PA}$. We further introduce a bi-objective optimization variant of GNRM, where we wish to minimize both $r$ and $k$ subject to upper bounds $r\le \bar{r}$ and $k\le \bar{k}$, where $\bar{r}$ and $\bar{k}$ are constants. We show that the Pareto front of this bi-objective optimization problem (BO-GNRM) can be computed in fixed-parameter tractable time with parameter $\bar{r}+\bar{k}$. We then report the results of our experimental work using the integer programming solver Gurobi to solve instances of BO-GNRM. Our key findings are that (a) we obtained strong support that Gurobi's performance is fixed-parameter tractable, (b) our results suggest that our techniques may be useful for role mining in practice, based on our experiments in the context of three well-known real-world authorization policies.
RCBEVDet: Radar-camera Fusion in Bird's Eye View for 3D Object Detection
Mar 25, 2024Three-dimensional object detection is one of the key tasks in autonomous driving. To reduce costs in practice, low-cost multi-view cameras for 3D object detection are proposed to replace the expansive LiDAR sensors. However, relying solely on cameras is difficult to achieve highly accurate and robust 3D object detection. An effective solution to this issue is combining multi-view cameras with the economical millimeter-wave radar sensor to achieve more reliable multi-modal 3D object detection. In this paper, we introduce RCBEVDet, a radar-camera fusion 3D object detection method in the bird's eye view (BEV). Specifically, we first design RadarBEVNet for radar BEV feature extraction. RadarBEVNet consists of a dual-stream radar backbone and a Radar Cross-Section (RCS) aware BEV encoder. In the dual-stream radar backbone, a point-based encoder and a transformer-based encoder are proposed to extract radar features, with an injection and extraction module to facilitate communication between the two encoders. The RCS-aware BEV encoder takes RCS as the object size prior to scattering the point feature in BEV. Besides, we present the Cross-Attention Multi-layer Fusion module to automatically align the multi-modal BEV feature from radar and camera with the deformable attention mechanism, and then fuse the feature with channel and spatial fusion layers. Experimental results show that RCBEVDet achieves new state-of-the-art radar-camera fusion results on nuScenes and view-of-delft (VoD) 3D object detection benchmarks. Furthermore, RCBEVDet achieves better 3D detection results than all real-time camera-only and radar-camera 3D object detectors with a faster inference speed at 21~28 FPS. The source code will be released at https://github.com/VDIGPKU/RCBEVDet.
BlazeBVD: Make Scale-Time Equalization Great Again for Blind Video Deflickering
Mar 10, 2024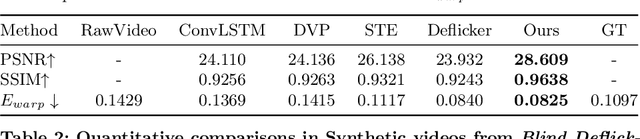

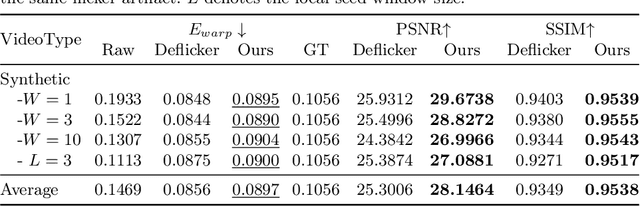
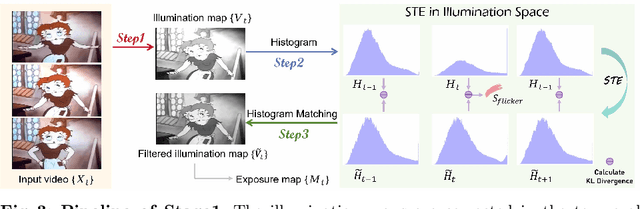
Developing blind video deflickering (BVD) algorithms to enhance video temporal consistency, is gaining importance amid the flourish of image processing and video generation. However, the intricate nature of video data complicates the training of deep learning methods, leading to high resource consumption and instability, notably under severe lighting flicker. This underscores the critical need for a compact representation beyond pixel values to advance BVD research and applications. Inspired by the classic scale-time equalization (STE), our work introduces the histogram-assisted solution, called BlazeBVD, for high-fidelity and rapid BVD. Compared with STE, which directly corrects pixel values by temporally smoothing color histograms, BlazeBVD leverages smoothed illumination histograms within STE filtering to ease the challenge of learning temporal data using neural networks. In technique, BlazeBVD begins by condensing pixel values into illumination histograms that precisely capture flickering and local exposure variations. These histograms are then smoothed to produce singular frames set, filtered illumination maps, and exposure maps. Resorting to these deflickering priors, BlazeBVD utilizes a 2D network to restore faithful and consistent texture impacted by lighting changes or localized exposure issues. BlazeBVD also incorporates a lightweight 3D network to amend slight temporal inconsistencies, avoiding the resource consumption issue. Comprehensive experiments on synthetic, real-world and generated videos, showcase the superior qualitative and quantitative results of BlazeBVD, achieving inference speeds up to 10x faster than state-of-the-arts.
Raw Instinct: Trust Your Classifiers and Skip the Conversion
Mar 21, 2024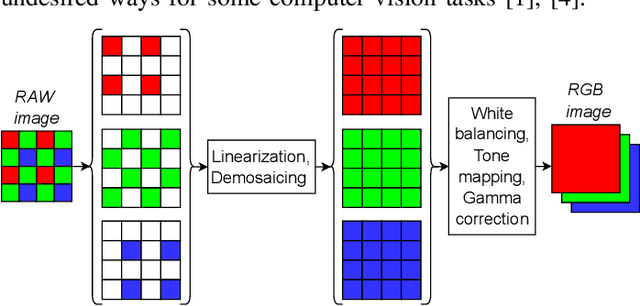
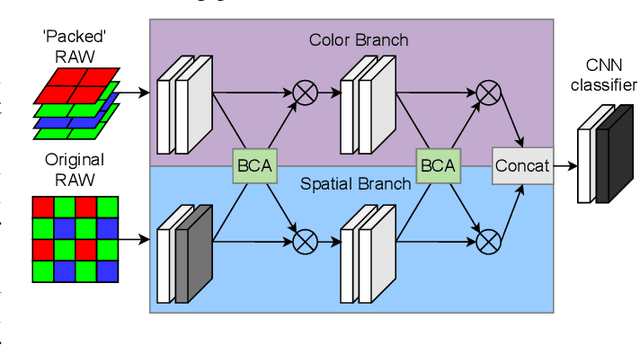

Using RAW-images in computer vision problems is surprisingly underexplored considering that converting from RAW to RGB does not introduce any new capture information. In this paper, we show that a sufficiently advanced classifier can yield equivalent results on RAW input compared to RGB and present a new public dataset consisting of RAW images and the corresponding converted RGB images. Classifying images directly from RAW is attractive, as it allows for skipping the conversion to RGB, lowering computation time significantly. Two CNN classifiers are used to classify the images in both formats, confirming that classification performance can indeed be preserved. We furthermore show that the total computation time from RAW image data to classification results for RAW images can be up to 8.46 times faster than RGB. These results contribute to the evidence found in related works, that using RAW images as direct input to computer vision algorithms looks very promising.
* https://www.kaggle.com/datasets/mathiasviborg/raw-instinct
Multi-agent transformer-accelerated RL for satisfaction of STL specifications
Mar 23, 2024One of the main challenges in multi-agent reinforcement learning is scalability as the number of agents increases. This issue is further exacerbated if the problem considered is temporally dependent. State-of-the-art solutions today mainly follow centralized training with decentralized execution paradigm in order to handle the scalability concerns. In this paper, we propose time-dependent multi-agent transformers which can solve the temporally dependent multi-agent problem efficiently with a centralized approach via the use of transformers that proficiently handle the large input. We highlight the efficacy of this method on two problems and use tools from statistics to verify the probability that the trajectories generated under the policy satisfy the task. The experiments show that our approach has superior performance against the literature baseline algorithms in both cases.
The Interplay Between Symmetries and Impact Effects on Hybrid Mechanical Systems
Mar 19, 2024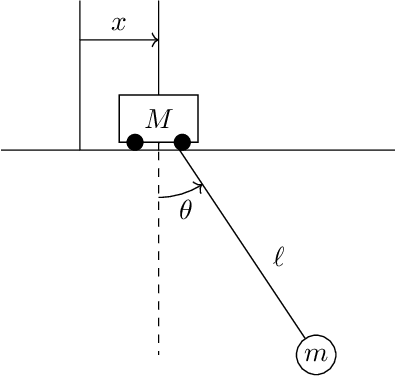
Hybrid systems are dynamical systems with continuous-time and discrete-time components in their dynamics. When hybrid systems are defined on a principal bundle we are able to define two classes of impacts for the discrete-time transition of the dynamics: interior impacts and exterior impacts. In this paper we define hybrid systems on principal bundles, study the underlying geometry on the switching surface where impacts occur and we find conditions for which both exterior and interior impacts are preserved by the mechanical connection induced in the principal bundle.