 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Proximal Policy Optimization for Integrated Sensing and Communication in mmWave Systems
Jun 27, 2023
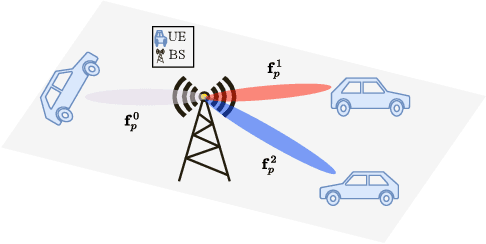
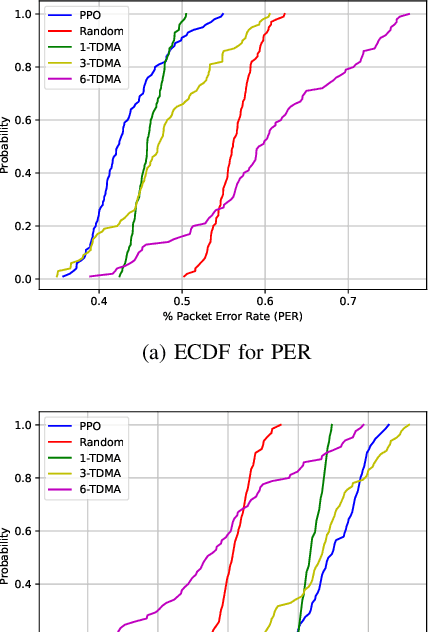
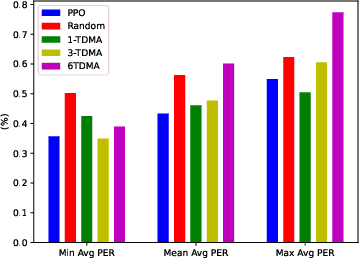
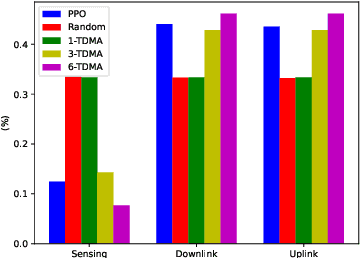
In wireless communication systems, mmWave beam tracking is a critical task that affects both sensing and communications, as it is related to the knowledge of the wireless channel. We consider a setup in which a Base Station (BS) needs to dynamically choose whether the resource will be allocated for one of the three operations: sensing (beam tracking), downlink, or uplink transmission. We devise an approach based on the Proximal Policy Optimization (PPO) algorithm for choosing the resource allocation and beam tracking at a given time slot. The proposed framework takes into account the variable quality of the wireless channel and optimizes the decisions in a coordinated manner. Simulation results demonstrate that the proposed method achieves significant performance improvements in terms of average packet error rate (PER) compared to the baseline methods while providing a significant reduction in beam tracking overhead. We also show that our proposed PPO-based framework provides an effective solution to the resource allocation problem in beam tracking and communication, exhibiting a great generalization performance regardless of the stochastic behavior of the system.
Coupling parameter and particle dynamics for adaptive sampling in Neural Galerkin schemes
Jun 27, 2023
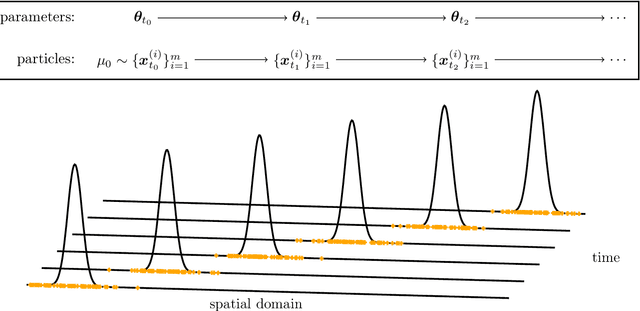
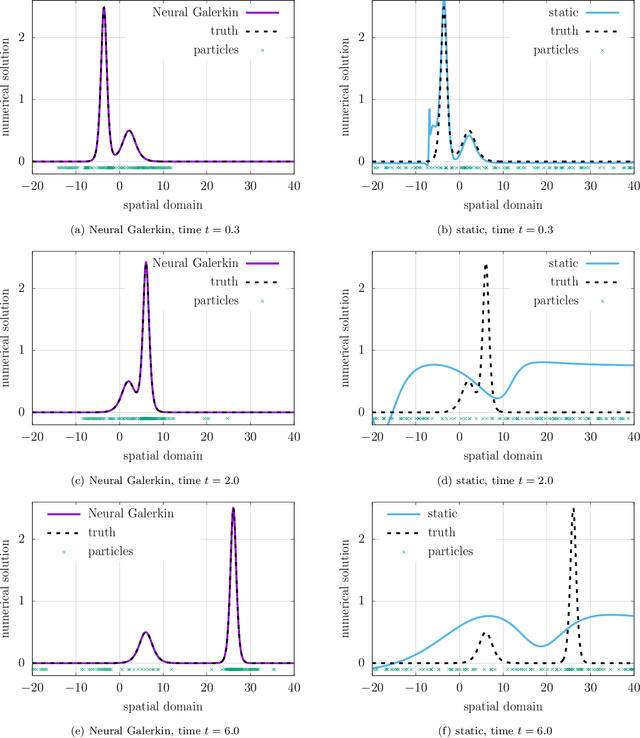
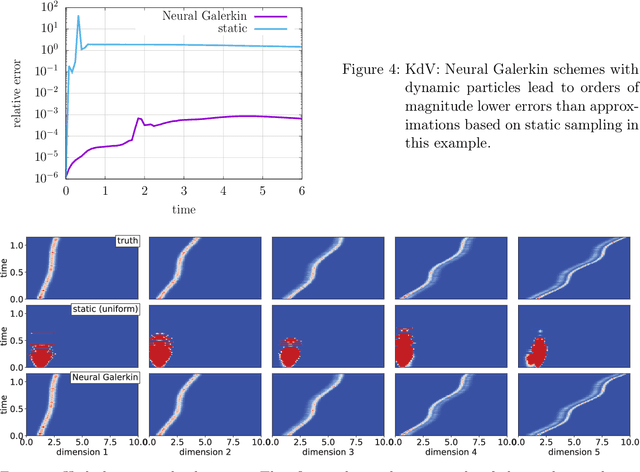
Training nonlinear parametrizations such as deep neural networks to numerically approximate solutions of partial differential equations is often based on minimizing a loss that includes the residual, which is analytically available in limited settings only. At the same time, empirically estimating the training loss is challenging because residuals and related quantities can have high variance, especially for transport-dominated and high-dimensional problems that exhibit local features such as waves and coherent structures. Thus, estimators based on data samples from un-informed, uniform distributions are inefficient. This work introduces Neural Galerkin schemes that estimate the training loss with data from adaptive distributions, which are empirically represented via ensembles of particles. The ensembles are actively adapted by evolving the particles with dynamics coupled to the nonlinear parametrizations of the solution fields so that the ensembles remain informative for estimating the training loss. Numerical experiments indicate that few dynamic particles are sufficient for obtaining accurate empirical estimates of the training loss, even for problems with local features and with high-dimensional spatial domains.
SSC-RS: Elevate LiDAR Semantic Scene Completion with Representation Separation and BEV Fusion
Jun 27, 2023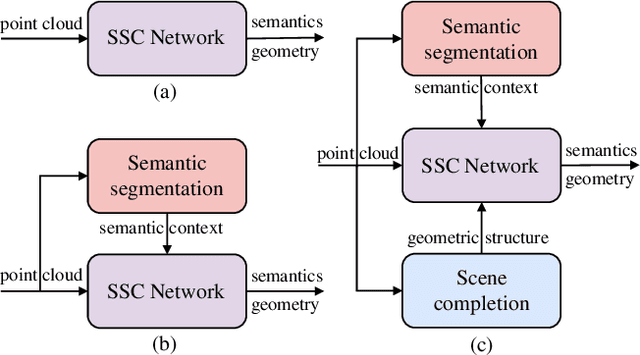
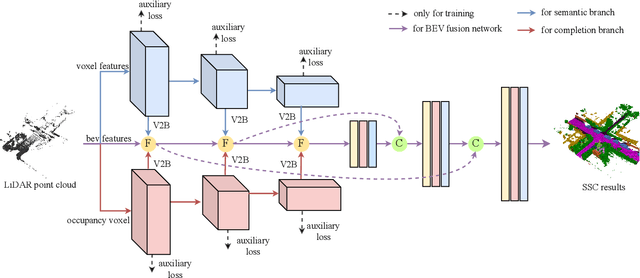
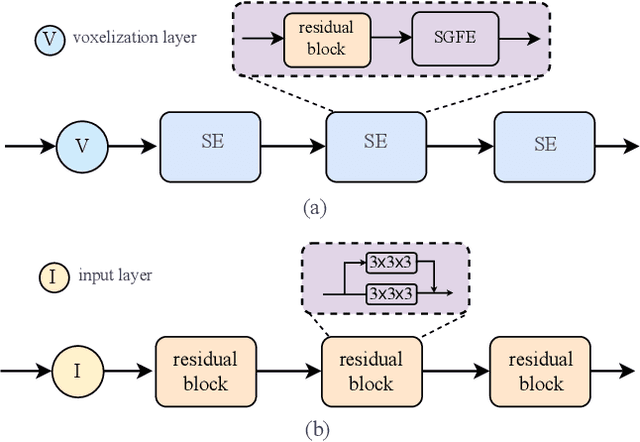
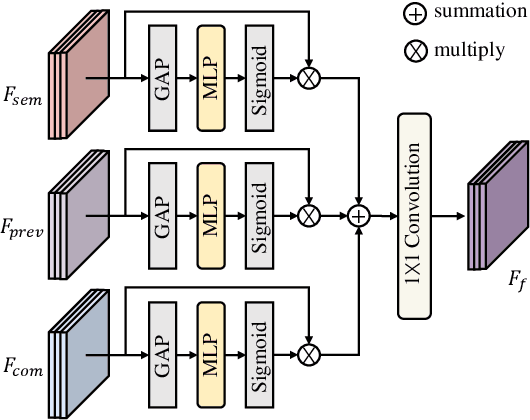
Semantic scene completion (SSC) jointly predicts the semantics and geometry of the entire 3D scene, which plays an essential role in 3D scene understanding for autonomous driving systems. SSC has achieved rapid progress with the help of semantic context in segmentation. However, how to effectively exploit the relationships between the semantic context in semantic segmentation and geometric structure in scene completion remains under exploration. In this paper, we propose to solve outdoor SSC from the perspective of representation separation and BEV fusion. Specifically, we present the network, named SSC-RS, which uses separate branches with deep supervision to explicitly disentangle the learning procedure of the semantic and geometric representations. And a BEV fusion network equipped with the proposed Adaptive Representation Fusion (ARF) module is presented to aggregate the multi-scale features effectively and efficiently. Due to the low computational burden and powerful representation ability, our model has good generality while running in real-time. Extensive experiments on SemanticKITTI demonstrate our SSC-RS achieves state-of-the-art performance.
Interpretable Neural Embeddings with Sparse Self-Representation
Jun 25, 2023
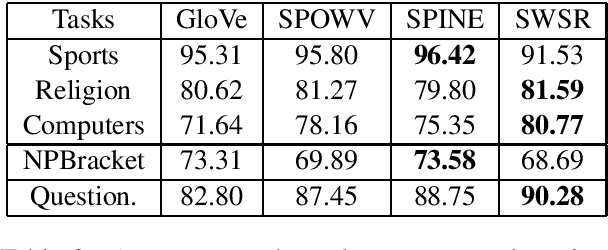
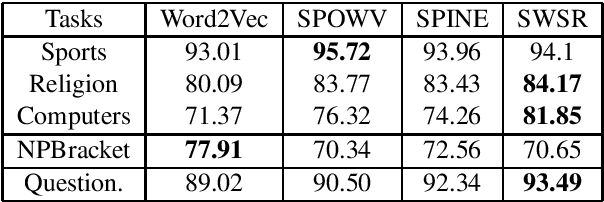
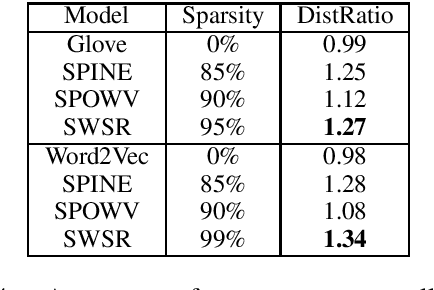
Interpretability benefits the theoretical understanding of representations. Existing word embeddings are generally dense representations. Hence, the meaning of latent dimensions is difficult to interpret. This makes word embeddings like a black-box and prevents them from being human-readable and further manipulation. Many methods employ sparse representation to learn interpretable word embeddings for better interpretability. However, they also suffer from the unstable issue of grouped selection in $\ell1$ and online dictionary learning. Therefore, they tend to yield different results each time. To alleviate this challenge, we propose a novel method to associate data self-representation with a shallow neural network to learn expressive, interpretable word embeddings. In experiments, we report that the resulting word embeddings achieve comparable and even slightly better interpretability than baseline embeddings. Besides, we also evaluate that our approach performs competitively well on all downstream tasks and outperforms benchmark embeddings on a majority of them.
DeepMediX: A Deep Learning-Driven Resource-Efficient Medical Diagnosis Across the Spectrum
Jul 01, 2023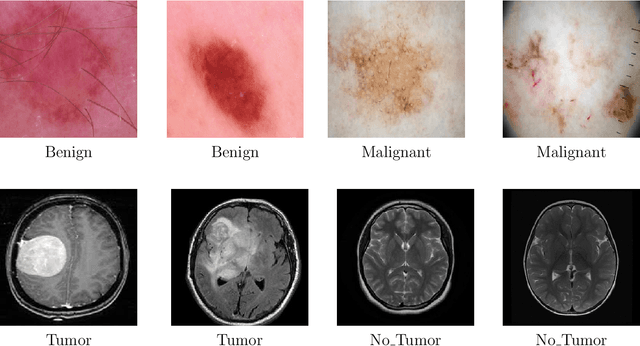
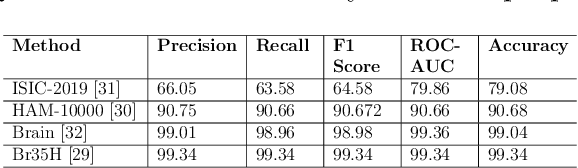
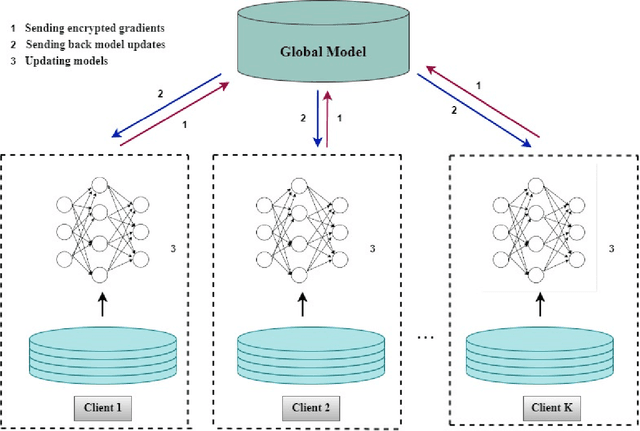
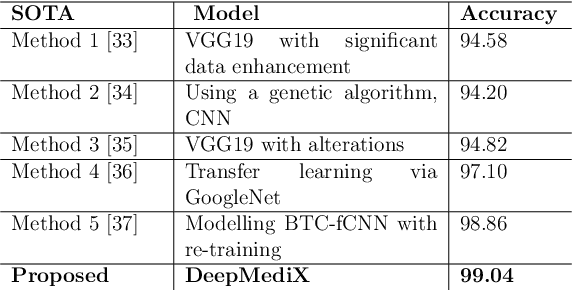
In the rapidly evolving landscape of medical imaging diagnostics, achieving high accuracy while preserving computational efficiency remains a formidable challenge. This work presents \texttt{DeepMediX}, a groundbreaking, resource-efficient model that significantly addresses this challenge. Built on top of the MobileNetV2 architecture, DeepMediX excels in classifying brain MRI scans and skin cancer images, with superior performance demonstrated on both binary and multiclass skin cancer datasets. It provides a solution to labor-intensive manual processes, the need for large datasets, and complexities related to image properties. DeepMediX's design also includes the concept of Federated Learning, enabling a collaborative learning approach without compromising data privacy. This approach allows diverse healthcare institutions to benefit from shared learning experiences without the necessity of direct data access, enhancing the model's predictive power while preserving the privacy and integrity of sensitive patient data. Its low computational footprint makes DeepMediX suitable for deployment on handheld devices, offering potential for real-time diagnostic support. Through rigorous testing on standard datasets, including the ISIC2018 for dermatological research, DeepMediX demonstrates exceptional diagnostic capabilities, matching the performance of existing models on almost all tasks and even outperforming them in some cases. The findings of this study underline significant implications for the development and deployment of AI-based tools in medical imaging and their integration into point-of-care settings. The source code and models generated would be released at https://github.com/kishorebabun/DeepMediX.
Exploration on HuBERT with Multiple Resolutions
Jun 22, 2023

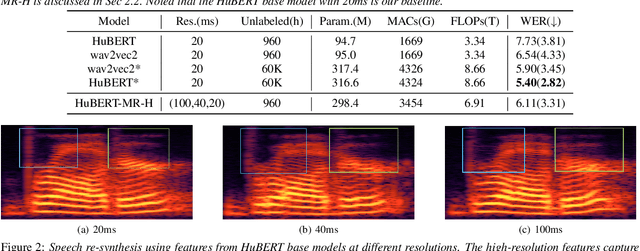
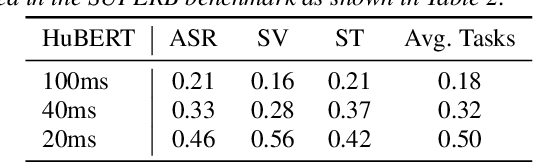
Hidden-unit BERT (HuBERT) is a widely-used self-supervised learning (SSL) model in speech processing. However, we argue that its fixed 20ms resolution for hidden representations would not be optimal for various speech-processing tasks since their attributes (e.g., speaker characteristics and semantics) are based on different time scales. To address this limitation, we propose utilizing HuBERT representations at multiple resolutions for downstream tasks. We explore two approaches, namely the parallel and hierarchical approaches, for integrating HuBERT features with different resolutions. Through experiments, we demonstrate that HuBERT with multiple resolutions outperforms the original model. This highlights the potential of utilizing multiple resolutions in SSL models like HuBERT to capture diverse information from speech signals.
Integrating Geometric Control into Text-to-Image Diffusion Models for High-Quality Detection Data Generation via Text Prompt
Jun 28, 2023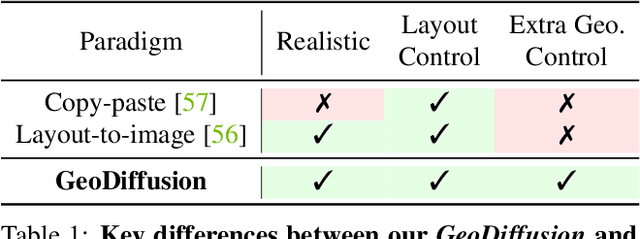
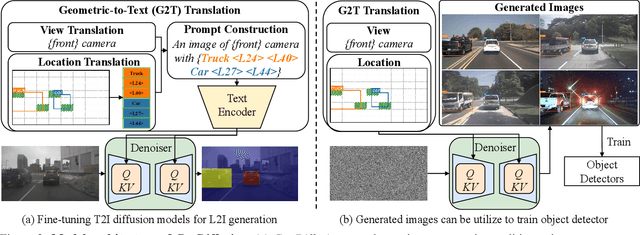
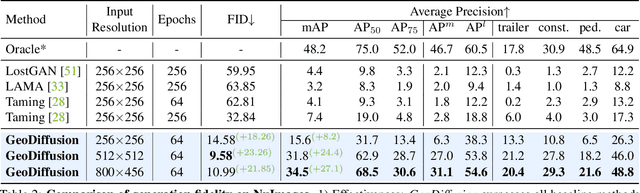
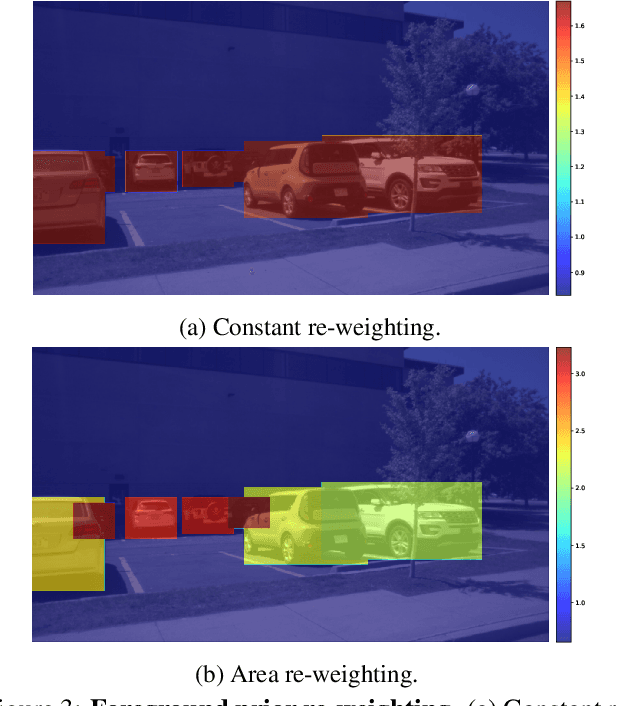
Diffusion models have attracted significant attention due to their remarkable ability to create content and generate data for tasks such as image classification. However, the usage of diffusion models to generate high-quality object detection data remains an underexplored area, where not only the image-level perceptual quality but also geometric conditions such as bounding boxes and camera views are essential. Previous studies have utilized either copy-paste synthesis or layout-to-image (L2I) generation with specifically designed modules to encode semantic layouts. In this paper, we propose GeoDiffusion, a simple framework that can flexibly translate various geometric conditions into text prompts and empower the pre-trained text-to-image (T2I) diffusion models for high-quality detection data generation. Unlike previous L2I methods, our GeoDiffusion is able to encode not only bounding boxes but also extra geometric conditions such as camera views in self-driving scenes. Extensive experiments demonstrate GeoDiffusion outperforms previous L2I methods while maintaining 4x training time faster. To the best of our knowledge, this is the first work to adopt diffusion models for layout-to-image generation with geometric conditions and demonstrate that L2I-generated images can be beneficial for improving the performance of object detectors.
Stochastic Methods in Variational Inequalities: Ergodicity, Bias and Refinements
Jun 28, 2023
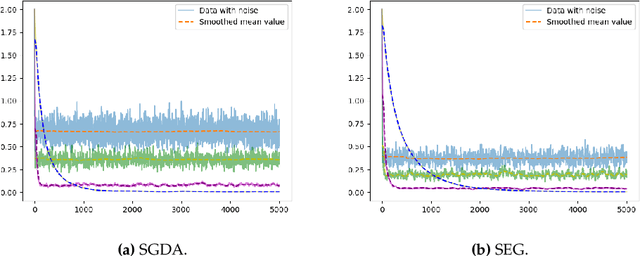
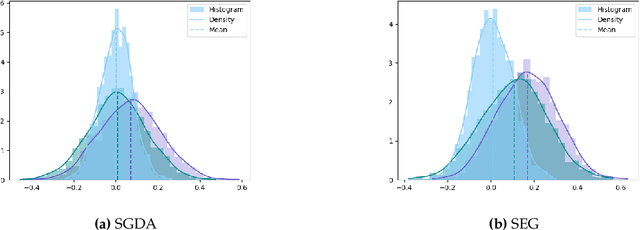
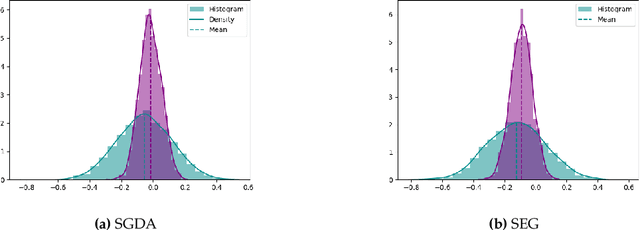
For min-max optimization and variational inequalities problems (VIP) encountered in diverse machine learning tasks, Stochastic Extragradient (SEG) and Stochastic Gradient Descent Ascent (SGDA) have emerged as preeminent algorithms. Constant step-size variants of SEG/SGDA have gained popularity, with appealing benefits such as easy tuning and rapid forgiveness of initial conditions, but their convergence behaviors are more complicated even in rudimentary bilinear models. Our work endeavors to elucidate and quantify the probabilistic structures intrinsic to these algorithms. By recasting the constant step-size SEG/SGDA as time-homogeneous Markov Chains, we establish a first-of-its-kind Law of Large Numbers and a Central Limit Theorem, demonstrating that the average iterate is asymptotically normal with a unique invariant distribution for an extensive range of monotone and non-monotone VIPs. Specializing to convex-concave min-max optimization, we characterize the relationship between the step-size and the induced bias with respect to the Von-Neumann's value. Finally, we establish that Richardson-Romberg extrapolation can improve proximity of the average iterate to the global solution for VIPs. Our probabilistic analysis, underpinned by experiments corroborating our theoretical discoveries, harnesses techniques from optimization, Markov chains, and operator theory.
SE-PQA: Personalized Community Question Answering
Jun 28, 2023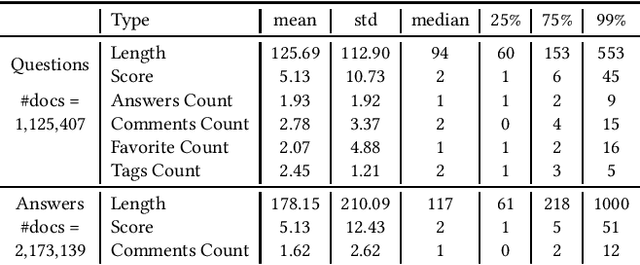
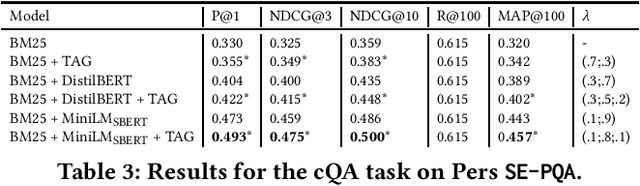
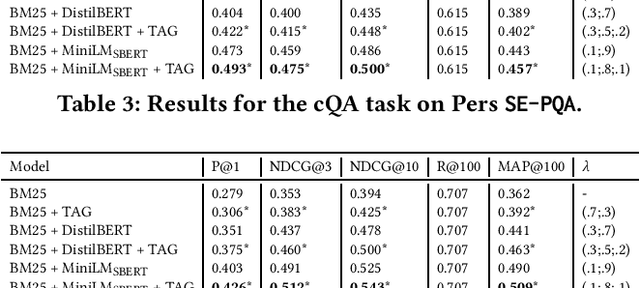
Personalization in Information Retrieval is a topic studied for a long time. Nevertheless, there is still a lack of high-quality, real-world datasets to conduct large-scale experiments and evaluate models for personalized search. This paper contributes to filling this gap by introducing SE-PQA (StackExchange - Personalized Question Answering), a new curated resource to design and evaluate personalized models related to the task of community Question Answering (cQA). The contributed dataset includes more than 1 million queries and 2 million answers, annotated with a rich set of features modeling the social interactions among the users of a popular cQA platform. We describe the characteristics of SE-PQA and detail the features associated with questions and answers. We also provide reproducible baseline methods for the cQA task based on the resource, including deep learning models and personalization approaches. The results of the preliminary experiments conducted show the appropriateness of SE-PQA to train effective cQA models; they also show that personalization remarkably improves the effectiveness of all the methods tested. Furthermore, we show the benefits in terms of robustness and generalization of combining data from multiple communities for personalization purposes.
Let Segment Anything Help Image Dehaze
Jun 28, 2023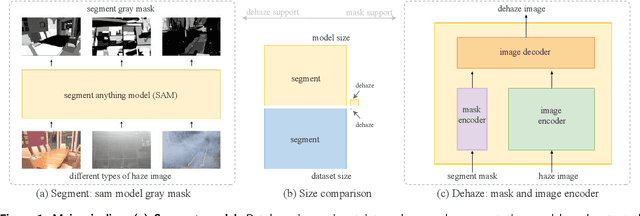
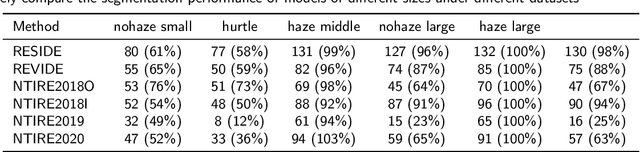

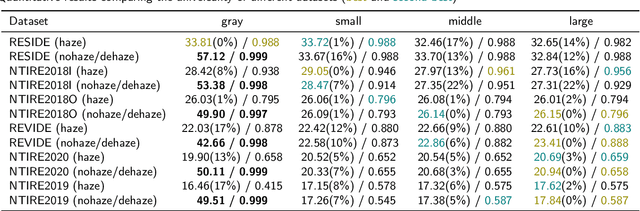
The large language model and high-level vision model have achieved impressive performance improvements with large datasets and model sizes. However, low-level computer vision tasks, such as image dehaze and blur removal, still rely on a small number of datasets and small-sized models, which generally leads to overfitting and local optima. Therefore, we propose a framework to integrate large-model prior into low-level computer vision tasks. Just as with the task of image segmentation, the degradation of haze is also texture-related. So we propose to detect gray-scale coding, network channel expansion, and pre-dehaze structures to integrate large-model prior knowledge into any low-level dehazing network. We demonstrate the effectiveness and applicability of large models in guiding low-level visual tasks through different datasets and algorithms comparison experiments. Finally, we demonstrate the effect of grayscale coding, network channel expansion, and recurrent network structures through ablation experiments. Under the conditions where additional data and training resources are not required, we successfully prove that the integration of large-model prior knowledge will improve the dehaze performance and save training time for low-level visual tasks.