 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Physics-informed State-space Neural Networks for Transport Phenomena
Sep 21, 2023
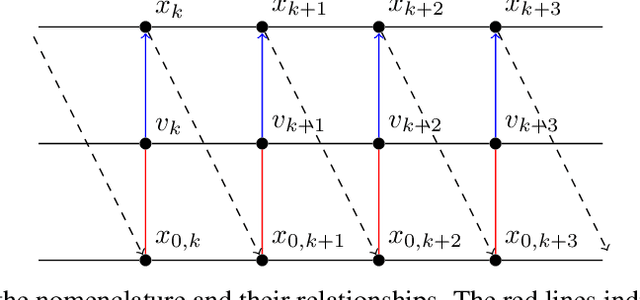
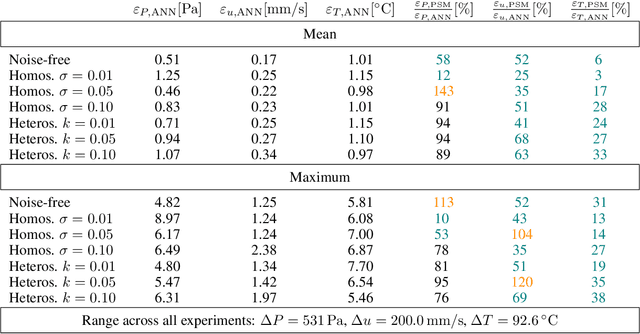
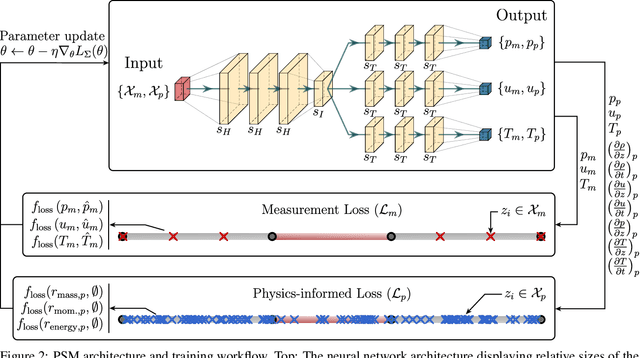

This work introduces Physics-informed State-space neural network Models (PSMs), a novel solution to achieving real-time optimization, flexibility, and fault tolerance in autonomous systems, particularly in transport-dominated systems such as chemical, biomedical, and power plants. Traditional data-driven methods fall short due to a lack of physical constraints like mass conservation; PSMs address this issue by training deep neural networks with sensor data and physics-informing using components' Partial Differential Equations (PDEs), resulting in a physics-constrained, end-to-end differentiable forward dynamics model. Through two in silico experiments - a heated channel and a cooling system loop - we demonstrate that PSMs offer a more accurate approach than purely data-driven models. Beyond accuracy, there are several compelling use cases for PSMs. In this work, we showcase two: the creation of a nonlinear supervisory controller through a sequentially updated state-space representation and the proposal of a diagnostic algorithm using residuals from each of the PDEs. The former demonstrates the ability of PSMs to handle both constant and time-dependent constraints, while the latter illustrates their value in system diagnostics and fault detection. We further posit that PSMs could serve as a foundation for Digital Twins, constantly updated digital representations of physical systems.
Reachability Analysis of ARMAX Models
Sep 21, 2023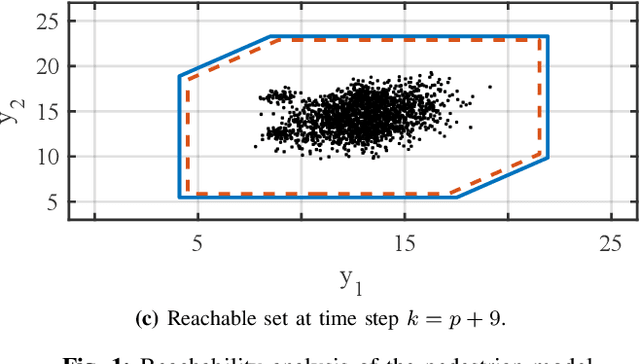

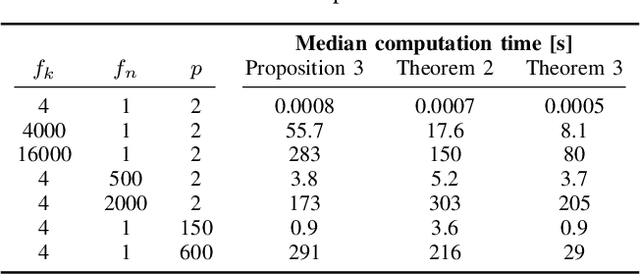
Reachability analysis is a powerful tool for computing the set of states or outputs reachable for a system. While previous work has focused on systems described by state-space models, we present the first methods to compute reachable sets of ARMAX models - one of the most common input-output models originating from data-driven system identification. The first approach we propose can only be used with dependency-preserving set representations such as symbolic zonotopes, while the second one is valid for arbitrary set representations but relies on a reformulation of the ARMAX model. By analyzing the computational complexities, we show that both approaches scale quadratically with respect to the time horizon of the reachability problem when using symbolic zonotopes. To reduce the computational complexity, we propose a third approach that scales linearly with respect to the time horizon when using set representations that are closed under Minkowski addition and linear transformation and that satisfy that the computational complexity of the Minkowski sum is independent of the representation size of the operands. Our numerical experiments demonstrate that the reachable sets of ARMAX models are tighter than the reachable sets of equivalent state space models in case of unknown initial states. Therefore, this methodology has the potential to significantly reduce the conservatism of various verification techniques.
To Adapt or Not to Adapt? Real-Time Adaptation for Semantic Segmentation
Aug 07, 2023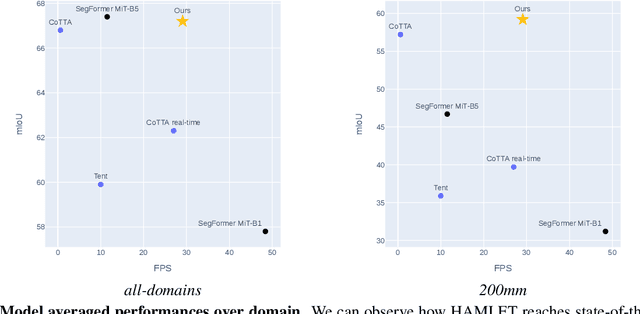
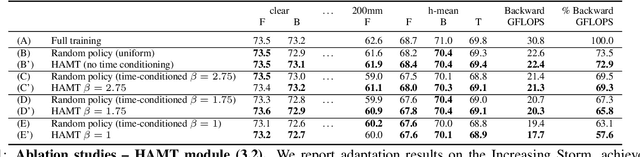
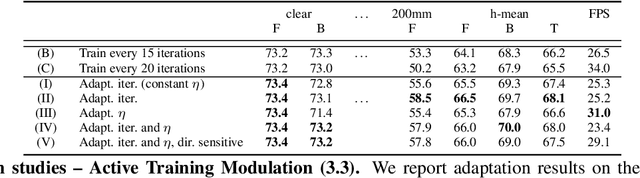
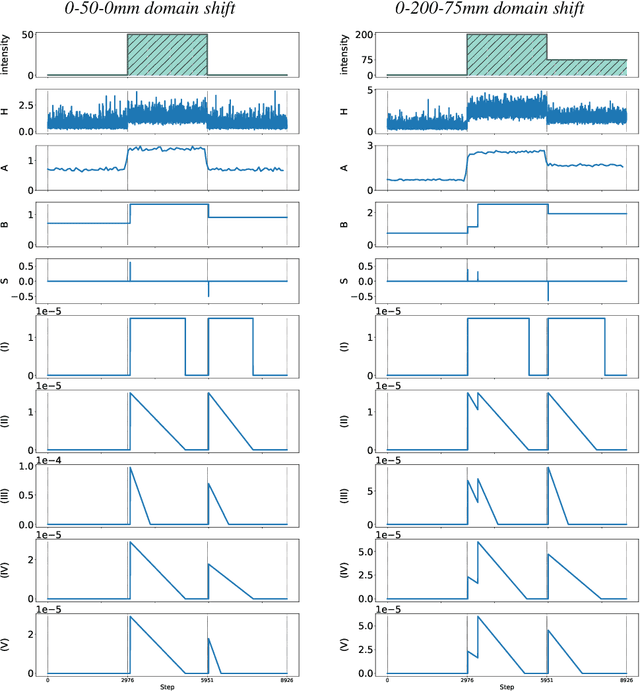
The goal of Online Domain Adaptation for semantic segmentation is to handle unforeseeable domain changes that occur during deployment, like sudden weather events. However, the high computational costs associated with brute-force adaptation make this paradigm unfeasible for real-world applications. In this paper we propose HAMLET, a Hardware-Aware Modular Least Expensive Training framework for real-time domain adaptation. Our approach includes a hardware-aware back-propagation orchestration agent (HAMT) and a dedicated domain-shift detector that enables active control over when and how the model is adapted (LT). Thanks to these advancements, our approach is capable of performing semantic segmentation while simultaneously adapting at more than 29FPS on a single consumer-grade GPU. Our framework's encouraging accuracy and speed trade-off is demonstrated on OnDA and SHIFT benchmarks through experimental results.
Reliable Majority Vote Computation with Complementary Sequences for UAV Waypoint Flight Control
Sep 26, 2023In this study, we propose a non-coherent over-the-air computation (OAC) scheme to calculate the majority vote (MV) reliably in fading channels. The proposed approach relies on modulating the amplitude of the elements of complementary sequences (CSs) based on the sign of the parameters to be aggregated. Since it does not use channel state information at the nodes, it is compatible with time-varying channels. To demonstrate the efficacy of our method, we employ it in a scenario where an unmanned aerial vehicle (UAV) is guided by distributed sensors, relying on the MV computed using our proposed scheme. We show that the proposed scheme reduces the computation error rate notably with a longer sequence length in fading channels while maintaining the peak-to-mean-envelope power ratio of the transmitted orthogonal frequency division multiplexing signals to be less than or equal to 3 dB.
Leveraging Herpangina Data to Enhance Hospital-level Prediction of Hand-Foot-and-Mouth Disease Admissions Using UPTST
Sep 26, 2023Outbreaks of hand-foot-and-mouth disease(HFMD) have been associated with significant morbidity and, in severe cases, mortality. Accurate forecasting of daily admissions of pediatric HFMD patients is therefore crucial for aiding the hospital in preparing for potential outbreaks and mitigating nosocomial transmissions. To address this pressing need, we propose a novel transformer-based model with a U-net shape, utilizing the patching strategy and the joint prediction strategy that capitalizes on insights from herpangina, a disease closely correlated with HFMD. This model also integrates representation learning by introducing reconstruction loss as an auxiliary loss. The results show that our U-net Patching Time Series Transformer (UPTST) model outperforms existing approaches in both long- and short-arm prediction accuracy of HFMD at hospital-level. Furthermore, the exploratory extension experiments show that the model's capabilities extend beyond prediction of infectious disease, suggesting broader applicability in various domains.
Safe Non-Stochastic Control of Control-Affine Systems: An Online Convex Optimization Approach
Sep 28, 2023We study how to safely control nonlinear control-affine systems that are corrupted with bounded non-stochastic noise, i.e., noise that is unknown a priori and that is not necessarily governed by a stochastic model. We focus on safety constraints that take the form of time-varying convex constraints such as collision-avoidance and control-effort constraints. We provide an algorithm with bounded dynamic regret, i.e., bounded suboptimality against an optimal clairvoyant controller that knows the realization of the noise a prior. We are motivated by the future of autonomy where robots will autonomously perform complex tasks despite real-world unpredictable disturbances such as wind gusts. To develop the algorithm, we capture our problem as a sequential game between a controller and an adversary, where the controller plays first, choosing the control input, whereas the adversary plays second, choosing the noise's realization. The controller aims to minimize its cumulative tracking error despite being unable to know the noise's realization a prior. We validate our algorithm in simulated scenarios of (i) an inverted pendulum aiming to stay upright, and (ii) a quadrotor aiming to fly to a goal location through an unknown cluttered environment.
A Metaheuristic for Amortized Search in High-Dimensional Parameter Spaces
Sep 28, 2023Parameter inference for dynamical models of (bio)physical systems remains a challenging problem. Intractable gradients, high-dimensional spaces, and non-linear model functions are typically problematic without large computational budgets. A recent body of work in that area has focused on Bayesian inference methods, which consider parameters under their statistical distributions and therefore, do not derive point estimates of optimal parameter values. Here we propose a new metaheuristic that drives dimensionality reductions from feature-informed transformations (DR-FFIT) to address these bottlenecks. DR-FFIT implements an efficient sampling strategy that facilitates a gradient-free parameter search in high-dimensional spaces. We use artificial neural networks to obtain differentiable proxies for the model's features of interest. The resulting gradients enable the estimation of a local active subspace of the model within a defined sampling region. This approach enables efficient dimensionality reductions of highly non-linear search spaces at a low computational cost. Our test data show that DR-FFIT boosts the performances of random-search and simulated-annealing against well-established metaheuristics, and improves the goodness-of-fit of the model, all within contained run-time costs.
Feed-forward and recurrent inhibition for compressing and classifying high dynamic range biosignals in spiking neural network architectures
Sep 28, 2023Neuromorphic processors that implement Spiking Neural Networks (SNNs) using mixed-signal analog/digital circuits represent a promising technology for closed-loop real-time processing of biosignals. As in biology, to minimize power consumption, the silicon neurons' circuits are configured to fire with a limited dynamic range and with maximum firing rates restricted to a few tens or hundreds of Herz. However, biosignals can have a very large dynamic range, so encoding them into spikes without saturating the neuron outputs represents an open challenge. In this work, we present a biologically-inspired strategy for compressing this high-dynamic range in SNN architectures, using three adaptation mechanisms ubiquitous in the brain: spike-frequency adaptation at the single neuron level, feed-forward inhibitory connections from neurons belonging to the input layer, and Excitatory-Inhibitory (E-I) balance via recurrent inhibition among neurons in the output layer. We apply this strategy to input biosignals encoded using both an asynchronous delta modulation method and an energy-based pulse-frequency modulation method. We validate this approach in silico, simulating a simple network applied to a gesture classification task from surface EMG recordings.
Pushing Large Language Models to the 6G Edge: Vision, Challenges, and Opportunities
Sep 28, 2023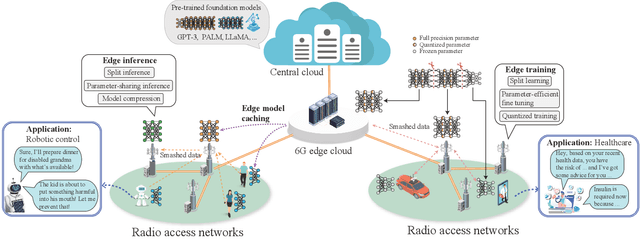
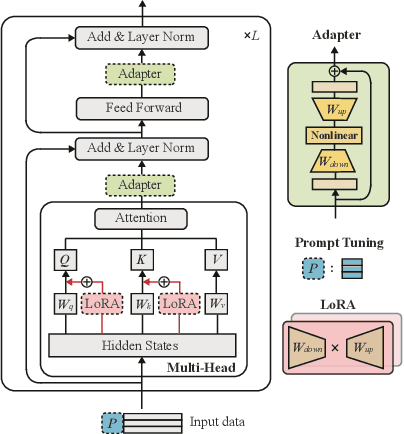
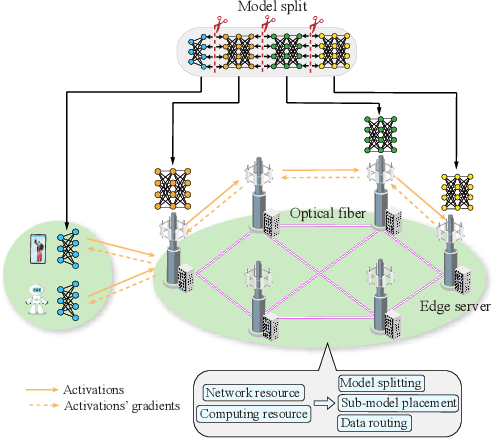
Large language models (LLMs), which have shown remarkable capabilities, are revolutionizing AI development and potentially shaping our future. However, given their multimodality, the status quo cloud-based deployment faces some critical challenges: 1) long response time; 2) high bandwidth costs; and 3) the violation of data privacy. 6G mobile edge computing (MEC) systems may resolve these pressing issues. In this article, we explore the potential of deploying LLMs at the 6G edge. We start by introducing killer applications powered by multimodal LLMs, including robotics and healthcare, to highlight the need for deploying LLMs in the vicinity of end users. Then, we identify the critical challenges for LLM deployment at the edge and envision the 6G MEC architecture for LLMs. Furthermore, we delve into two design aspects, i.e., edge training and edge inference for LLMs. In both aspects, considering the inherent resource limitations at the edge, we discuss various cutting-edge techniques, including split learning/inference, parameter-efficient fine-tuning, quantization, and parameter-sharing inference, to facilitate the efficient deployment of LLMs. This article serves as a position paper for thoroughly identifying the motivation, challenges, and pathway for empowering LLMs at the 6G edge.
E2Net: Resource-Efficient Continual Learning with Elastic Expansion Network
Sep 28, 2023Continual Learning methods are designed to learn new tasks without erasing previous knowledge. However, Continual Learning often requires massive computational power and storage capacity for satisfactory performance. In this paper, we propose a resource-efficient continual learning method called the Elastic Expansion Network (E2Net). Leveraging core subnet distillation and precise replay sample selection, E2Net achieves superior average accuracy and diminished forgetting within the same computational and storage constraints, all while minimizing processing time. In E2Net, we propose Representative Network Distillation to identify the representative core subnet by assessing parameter quantity and output similarity with the working network, distilling analogous subnets within the working network to mitigate reliance on rehearsal buffers and facilitating knowledge transfer across previous tasks. To enhance storage resource utilization, we then propose Subnet Constraint Experience Replay to optimize rehearsal efficiency through a sample storage strategy based on the structures of representative networks. Extensive experiments conducted predominantly on cloud environments with diverse datasets and also spanning the edge environment demonstrate that E2Net consistently outperforms state-of-the-art methods. In addition, our method outperforms competitors in terms of both storage and computational requirements.