 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomizing Spider Silk: Generative Models with Mechanical Property Conditioning for Protein Engineering
Apr 11, 2025The remarkable mechanical properties of spider silk, including its tensile strength and extensibility, are primarily governed by the repetitive regions of the proteins that constitute the fiber, the major ampullate spidroins (MaSps). However, establishing correlations between mechanical characteristics and repeat sequences is challenging due to the intricate sequence-structure-function relationships of MaSps and the limited availability of annotated datasets. In this study, we present a novel computational framework for designing MaSp repeat sequences with customizable mechanical properties. To achieve this, we developed a lightweight GPT-based generative model by distilling the pre-trained ProtGPT2 protein language model. The distilled model was subjected to multilevel fine-tuning using curated subsets of the Spider Silkome dataset. Specifically, we adapt the model for MaSp repeat generation using 6,000 MaSp repeat sequences and further refine it with 572 repeats associated with experimentally determined fiber-level mechanical properties. Our model generates biologically plausible MaSp repeat regions tailored to specific mechanical properties while also predicting those properties for given sequences. Validation includes sequence-level analysis, assessing physicochemical attributes and expected distribution of key motifs as well as secondary structure compositions. A correlation study using BLAST on the Spider Silkome dataset and a test set of MaSp repeats with known mechanical properties further confirmed the predictive accuracy of the model. This framework advances the rational design of spider silk-inspired biomaterials, offering a versatile tool for engineering protein sequences with tailored mechanical attributes.
CARL-GT: Evaluating Causal Reasoning Capabilities of Large Language Models
Dec 23, 2024



Causal reasoning capabilities are essential for large language models (LLMs) in a wide range of applications, such as education and healthcare. But there is still a lack of benchmarks for a better understanding of such capabilities. Current LLM benchmarks are mainly based on conversational tasks, academic math tests, and coding tests. Such benchmarks evaluate LLMs in well-regularized settings, but they are limited in assessing the skills and abilities to solve real-world problems. In this work, we provide a benchmark, named by CARL-GT, which evaluates CAusal Reasoning capabilities of large Language models using Graphs and Tabular data. The benchmark has a diverse range of tasks for evaluating LLMs from causal graph reasoning, knowledge discovery, and decision-making aspects. In addition, effective zero-shot learning prompts are developed for the tasks. In our experiments, we leverage the benchmark for evaluating open-source LLMs and provide a detailed comparison of LLMs for causal reasoning abilities. We found that LLMs are still weak in casual reasoning, especially with tabular data to discover new insights. Furthermore, we investigate and discuss the relationships of different benchmark tasks by analyzing the performance of LLMs. The experimental results show that LLMs have different strength over different tasks and that their performance on tasks in different categories, i.e., causal graph reasoning, knowledge discovery, and decision-making, shows stronger correlation than tasks in the same category.
Dessie: Disentanglement for Articulated 3D Horse Shape and Pose Estimation from Images
Oct 04, 2024In recent years, 3D parametric animal models have been developed to aid in estimating 3D shape and pose from images and video. While progress has been made for humans, it's more challenging for animals due to limited annotated data. To address this, we introduce the first method using synthetic data generation and disentanglement to learn to regress 3D shape and pose. Focusing on horses, we use text-based texture generation and a synthetic data pipeline to create varied shapes, poses, and appearances, learning disentangled spaces. Our method, Dessie, surpasses existing 3D horse reconstruction methods and generalizes to other large animals like zebras, cows, and deer. See the project website at: \url{https://celiali.github.io/Dessie/}.
CLHOP: Combined Audio-Video Learning for Horse 3D Pose and Shape Estimation
Jul 01, 2024



In the monocular setting, predicting 3D pose and shape of animals typically relies solely on visual information, which is highly under-constrained. In this work, we explore using audio to enhance 3D shape and motion recovery of horses from monocular video. We test our approach on two datasets: an indoor treadmill dataset for 3D evaluation and an outdoor dataset capturing diverse horse movements, the latter being a contribution to this study. Our results show that incorporating sound with visual data leads to more accurate and robust motion regression. This study is the first to investigate audio's role in 3D animal motion recovery.
Causality for Tabular Data Synthesis: A High-Order Structure Causal Benchmark Framework
Jun 12, 2024Tabular synthesis models remain ineffective at capturing complex dependencies, and the quality of synthetic data is still insufficient for comprehensive downstream tasks, such as prediction under distribution shifts, automated decision-making, and cross-table understanding. A major challenge is the lack of prior knowledge about underlying structures and high-order relationships in tabular data. We argue that a systematic evaluation on high-order structural information for tabular data synthesis is the first step towards solving the problem. In this paper, we introduce high-order structural causal information as natural prior knowledge and provide a benchmark framework for the evaluation of tabular synthesis models. The framework allows us to generate benchmark datasets with a flexible range of data generation processes and to train tabular synthesis models using these datasets for further evaluation. We propose multiple benchmark tasks, high-order metrics, and causal inference tasks as downstream tasks for evaluating the quality of synthetic data generated by the trained models. Our experiments demonstrate to leverage the benchmark framework for evaluating the model capability of capturing high-order structural causal information. Furthermore, our benchmarking results provide an initial assessment of state-of-the-art tabular synthesis models. They have clearly revealed significant gaps between ideal and actual performance and how baseline methods differ. Our benchmark framework is available at URL https://github.com/TURuibo/CauTabBench.
To Adapt or Not to Adapt? Real-Time Adaptation for Semantic Segmentation
Aug 07, 2023

The goal of Online Domain Adaptation for semantic segmentation is to handle unforeseeable domain changes that occur during deployment, like sudden weather events. However, the high computational costs associated with brute-force adaptation make this paradigm unfeasible for real-world applications. In this paper we propose HAMLET, a Hardware-Aware Modular Least Expensive Training framework for real-time domain adaptation. Our approach includes a hardware-aware back-propagation orchestration agent (HAMT) and a dedicated domain-shift detector that enables active control over when and how the model is adapted (LT). Thanks to these advancements, our approach is capable of performing semantic segmentation while simultaneously adapting at more than 29FPS on a single consumer-grade GPU. Our framework's encouraging accuracy and speed trade-off is demonstrated on OnDA and SHIFT benchmarks through experimental results.
Predictive Modeling of Equine Activity Budgets Using a 3D Skeleton Reconstructed from Surveillance Recordings
Jun 08, 2023



In this work, we present a pipeline to reconstruct the 3D pose of a horse from 4 simultaneous surveillance camera recordings. Our environment poses interesting challenges to tackle, such as limited field view of the cameras and a relatively closed and small environment. The pipeline consists of training a 2D markerless pose estimation model to work on every viewpoint, then applying it to the videos and performing triangulation. We present numerical evaluation of the results (error analysis), as well as show the utility of the achieved poses in downstream tasks of selected behavioral predictions. Our analysis of the predictive model for equine behavior showed a bias towards pain-induced horses, which aligns with our understanding of how behavior varies across painful and healthy subjects.
Controllable Motion Synthesis and Reconstruction with Autoregressive Diffusion Models
Apr 03, 2023



Data-driven and controllable human motion synthesis and prediction are active research areas with various applications in interactive media and social robotics. Challenges remain in these fields for generating diverse motions given past observations and dealing with imperfect poses. This paper introduces MoDiff, an autoregressive probabilistic diffusion model over motion sequences conditioned on control contexts of other modalities. Our model integrates a cross-modal Transformer encoder and a Transformer-based decoder, which are found effective in capturing temporal correlations in motion and control modalities. We also introduce a new data dropout method based on the diffusion forward process to provide richer data representations and robust generation. We demonstrate the superior performance of MoDiff in controllable motion synthesis for locomotion with respect to two baselines and show the benefits of diffusion data dropout for robust synthesis and reconstruction of high-fidelity motion close to recorded data.
Learn the Time to Learn: Replay Scheduling in Continual Learning
Sep 18, 2022
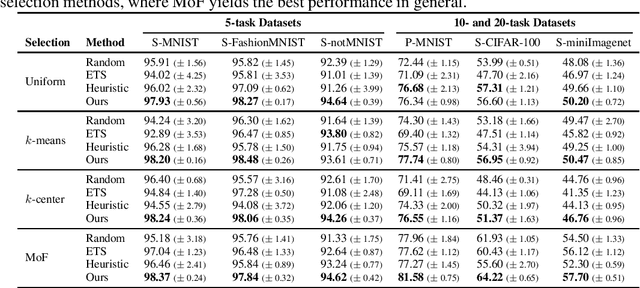
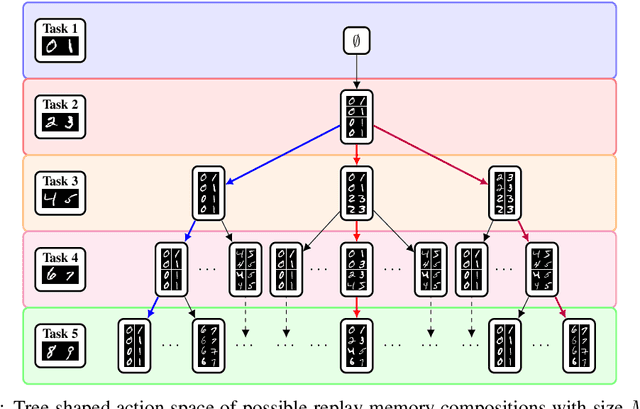
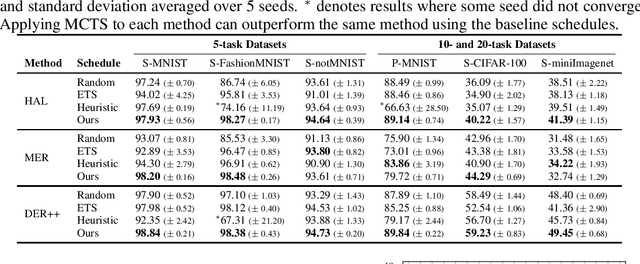
Replay methods have shown to be successful in mitigating catastrophic forgetting in continual learning scenarios despite having limited access to historical data. However, storing historical data is cheap in many real-world applications, yet replaying all historical data would be prohibited due to processing time constraints. In such settings, we propose learning the time to learn for a continual learning system, in which we learn replay schedules over which tasks to replay at different time steps. To demonstrate the importance of learning the time to learn, we first use Monte Carlo tree search to find the proper replay schedule and show that it can outperform fixed scheduling policies in terms of continual learning performance. Moreover, to improve the scheduling efficiency itself, we propose to use reinforcement learning to learn the replay scheduling policies that can generalize to new continual learning scenarios without added computational cost. In our experiments, we show the advantages of learning the time to learn, which brings current continual learning research closer to real-world needs.
Going Deeper than Tracking: a Survey of Computer-Vision Based Recognition of Animal Pain and Affective States
Jun 16, 2022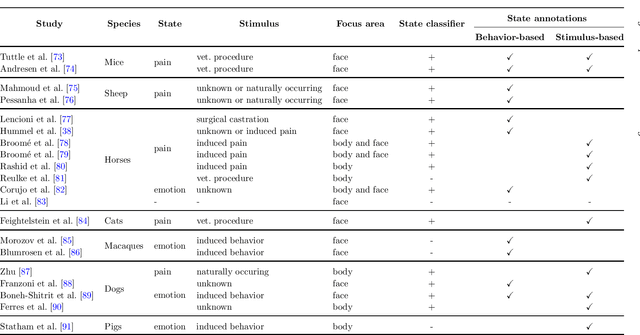
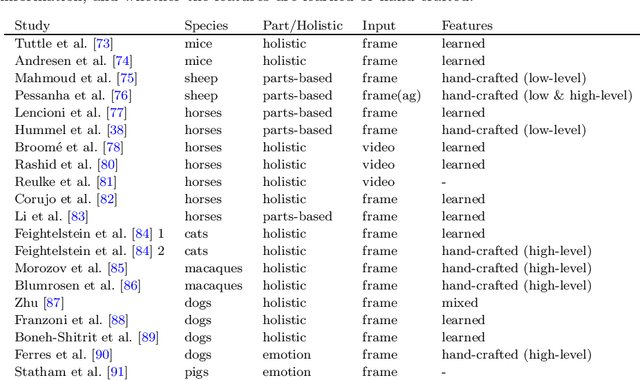
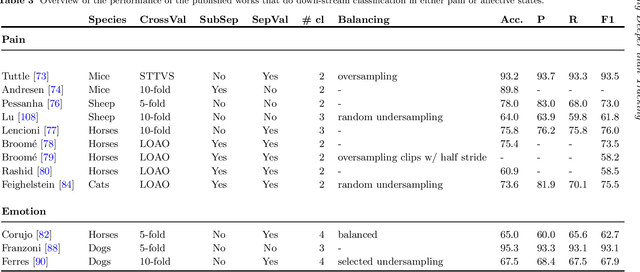

Advances in animal motion tracking and pose recognition have been a game changer in the study of animal behavior. Recently, an increasing number of works go 'deeper' than tracking, and address automated recognition of animals' internal states such as emotions and pain with the aim of improving animal welfare, making this a timely moment for a systematization of the field. This paper provides a comprehensive survey of computer vision-based research on recognition of affective states and pain in animals, addressing both facial and bodily behavior analysis. We summarize the efforts that have been presented so far within this topic -- classifying them across different dimensions, highlight challenges and research gaps, and provide best practice recommendations for advancing the field, and some future directions for research.