 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Routing Arena: A Benchmark Suite for Neural Routing Solvers
Oct 06, 2023
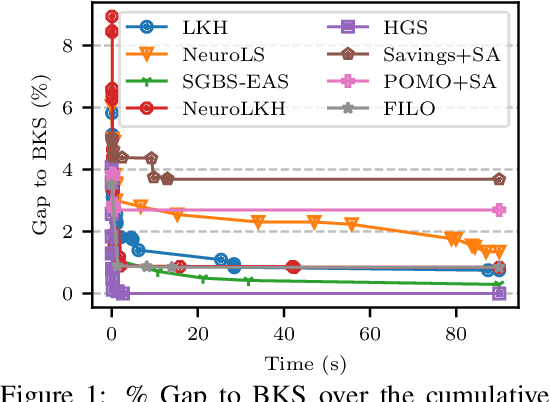
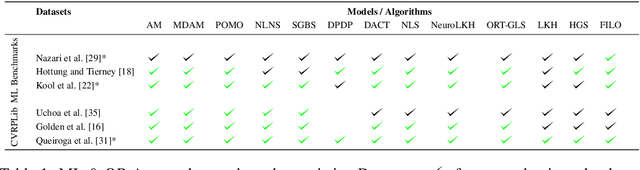
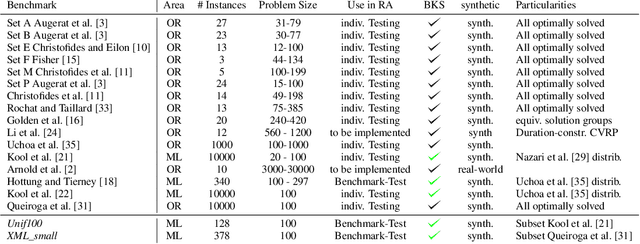
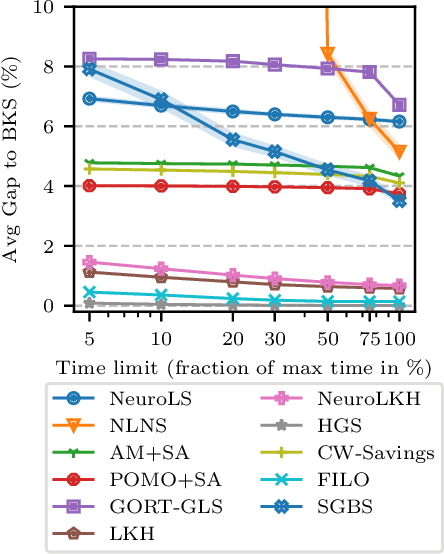
Neural Combinatorial Optimization has been researched actively in the last eight years. Even though many of the proposed Machine Learning based approaches are compared on the same datasets, the evaluation protocol exhibits essential flaws and the selection of baselines often neglects State-of-the-Art Operations Research approaches. To improve on both of these shortcomings, we propose the Routing Arena, a benchmark suite for Routing Problems that provides a seamless integration of consistent evaluation and the provision of baselines and benchmarks prevalent in the Machine Learning- and Operations Research field. The proposed evaluation protocol considers the two most important evaluation cases for different applications: First, the solution quality for an a priori fixed time budget and secondly the anytime performance of the respective methods. By setting the solution trajectory in perspective to a Best Known Solution and a Base Solver's solutions trajectory, we furthermore propose the Weighted Relative Average Performance (WRAP), a novel evaluation metric that quantifies the often claimed runtime efficiency of Neural Routing Solvers. A comprehensive first experimental evaluation demonstrates that the most recent Operations Research solvers generate state-of-the-art results in terms of solution quality and runtime efficiency when it comes to the vehicle routing problem. Nevertheless, some findings highlight the advantages of neural approaches and motivate a shift in how neural solvers should be conceptualized.
Neur2RO: Neural Two-Stage Robust Optimization
Oct 06, 2023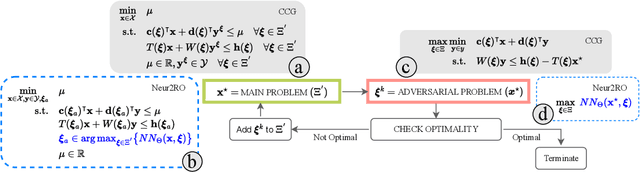
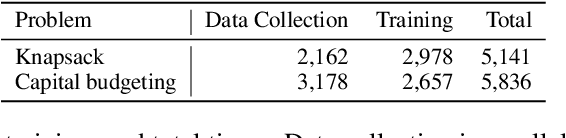
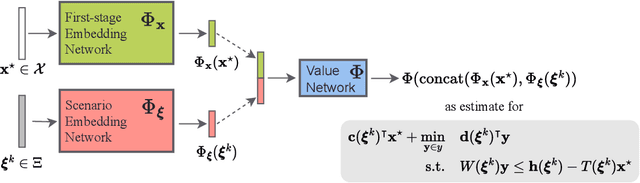
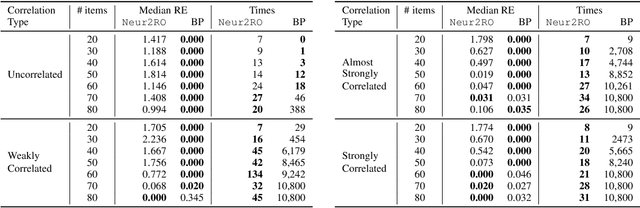
Robust optimization provides a mathematical framework for modeling and solving decision-making problems under worst-case uncertainty. This work addresses two-stage robust optimization (2RO) problems (also called adjustable robust optimization), wherein first-stage and second-stage decisions are made before and after uncertainty is realized, respectively. This results in a nested min-max-min optimization problem which is extremely challenging computationally, especially when the decisions are discrete. We propose Neur2RO, an efficient machine learning-driven instantiation of column-and-constraint generation (CCG), a classical iterative algorithm for 2RO. Specifically, we learn to estimate the value function of the second-stage problem via a novel neural network architecture that is easy to optimize over by design. Embedding our neural network into CCG yields high-quality solutions quickly as evidenced by experiments on two 2RO benchmarks, knapsack and capital budgeting. For knapsack, Neur2RO finds solutions that are within roughly $2\%$ of the best-known values in a few seconds compared to the three hours of the state-of-the-art exact branch-and-price algorithm; for larger and more complex instances, Neur2RO finds even better solutions. For capital budgeting, Neur2RO outperforms three variants of the $k$-adaptability algorithm, particularly on the largest instances, with a 5 to 10-fold reduction in solution time. Our code and data are available at https://github.com/khalil-research/Neur2RO.
Higher-Order DeepTrails: Unified Approach to *Trails
Oct 06, 2023Analyzing, understanding, and describing human behavior is advantageous in different settings, such as web browsing or traffic navigation. Understanding human behavior naturally helps to improve and optimize the underlying infrastructure or user interfaces. Typically, human navigation is represented by sequences of transitions between states. Previous work suggests to use hypotheses, representing different intuitions about the navigation to analyze these transitions. To mathematically grasp this setting, first-order Markov chains are used to capture the behavior, consequently allowing to apply different kinds of graph comparisons, but comes with the inherent drawback of losing information about higher-order dependencies within the sequences. To this end, we propose to analyze entire sequences using autoregressive language models, as they are traditionally used to model higher-order dependencies in sequences. We show that our approach can be easily adapted to model different settings introduced in previous work, namely HypTrails, MixedTrails and even SubTrails, while at the same time bringing unique advantages: 1. Modeling higher-order dependencies between state transitions, while 2. being able to identify short comings in proposed hypotheses, and 3. naturally introducing a unified approach to model all settings. To show the expressiveness of our approach, we evaluate our approach on different synthetic datasets and conclude with an exemplary analysis of a real-world dataset, examining the behavior of users who interact with voice assistants.
Towards Robust Real-Time Scene Text Detection: From Semantic to Instance Representation Learning
Aug 14, 2023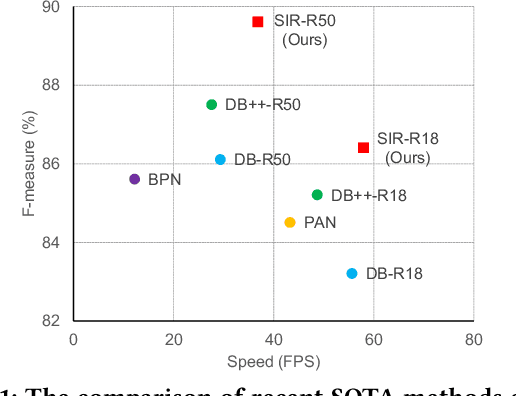
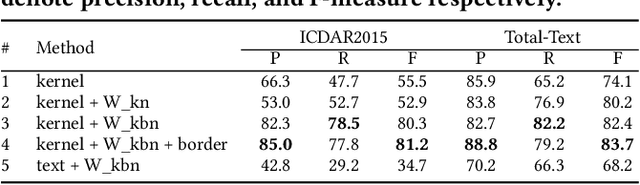
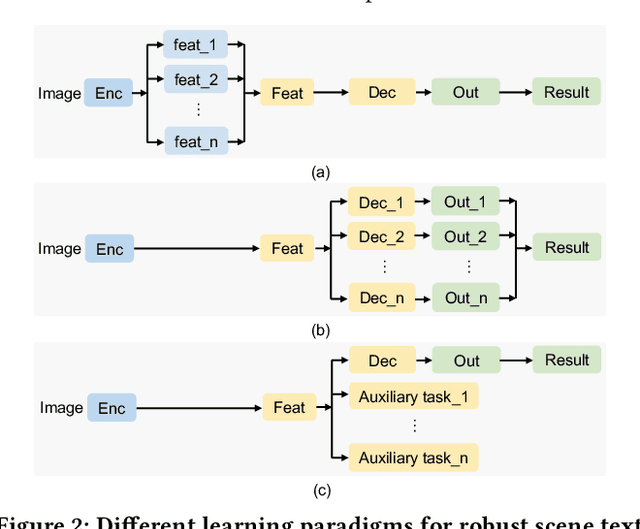
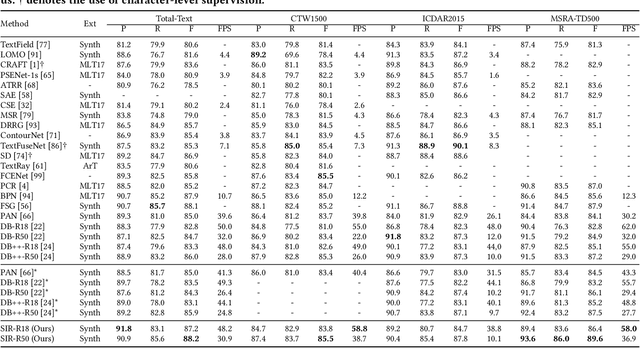
Due to the flexible representation of arbitrary-shaped scene text and simple pipeline, bottom-up segmentation-based methods begin to be mainstream in real-time scene text detection. Despite great progress, these methods show deficiencies in robustness and still suffer from false positives and instance adhesion. Different from existing methods which integrate multiple-granularity features or multiple outputs, we resort to the perspective of representation learning in which auxiliary tasks are utilized to enable the encoder to jointly learn robust features with the main task of per-pixel classification during optimization. For semantic representation learning, we propose global-dense semantic contrast (GDSC), in which a vector is extracted for global semantic representation, then used to perform element-wise contrast with the dense grid features. To learn instance-aware representation, we propose to combine top-down modeling (TDM) with the bottom-up framework to provide implicit instance-level clues for the encoder. With the proposed GDSC and TDM, the encoder network learns stronger representation without introducing any parameters and computations during inference. Equipped with a very light decoder, the detector can achieve more robust real-time scene text detection. Experimental results on four public datasets show that the proposed method can outperform or be comparable to the state-of-the-art on both accuracy and speed. Specifically, the proposed method achieves 87.2% F-measure with 48.2 FPS on Total-Text and 89.6% F-measure with 36.9 FPS on MSRA-TD500 on a single GeForce RTX 2080 Ti GPU.
Self-Calibrating, Fully Differentiable NLOS Inverse Rendering
Sep 21, 2023Existing time-resolved non-line-of-sight (NLOS) imaging methods reconstruct hidden scenes by inverting the optical paths of indirect illumination measured at visible relay surfaces. These methods are prone to reconstruction artifacts due to inversion ambiguities and capture noise, which are typically mitigated through the manual selection of filtering functions and parameters. We introduce a fully-differentiable end-to-end NLOS inverse rendering pipeline that self-calibrates the imaging parameters during the reconstruction of hidden scenes, using as input only the measured illumination while working both in the time and frequency domains. Our pipeline extracts a geometric representation of the hidden scene from NLOS volumetric intensities and estimates the time-resolved illumination at the relay wall produced by such geometric information using differentiable transient rendering. We then use gradient descent to optimize imaging parameters by minimizing the error between our simulated time-resolved illumination and the measured illumination. Our end-to-end differentiable pipeline couples diffraction-based volumetric NLOS reconstruction with path-space light transport and a simple ray marching technique to extract detailed, dense sets of surface points and normals of hidden scenes. We demonstrate the robustness of our method to consistently reconstruct geometry and albedo, even under significant noise levels.
Predicting Temperature of Major Cities Using Machine Learning and Deep Learning
Sep 23, 2023Currently, the issue that concerns the world leaders most is climate change for its effect on agriculture, environment and economies of daily life. So, to combat this, temperature prediction with strong accuracy is vital. So far, the most effective widely used measure for such forecasting is Numerical weather prediction (NWP) which is a mathematical model that needs broad data from different applications to make predictions. This expensive, time and labor consuming work can be minimized through making such predictions using Machine learning algorithms. Using the database made by University of Dayton which consists the change of temperature in major cities we used the Time Series Analysis method where we use LSTM for the purpose of turning existing data into a tool for future prediction. LSTM takes the long-term data as well as any short-term exceptions or anomalies that may have occurred and calculates trend, seasonality and the stationarity of a data. By using models such as ARIMA, SARIMA, Prophet with the concept of RNN and LSTM we can, filter out any abnormalities, preprocess the data compare it with previous trends and make a prediction of future trends. Also, seasonality and stationarity help us analyze the reoccurrence or repeat over one year variable and removes the constrain of time in which the data was dependent so see the general changes that are predicted. By doing so we managed to make prediction of the temperature of different cities during any time in future based on available data and built a method of accurate prediction. This document contains our methodology for being able to make such predictions.
Speeding-up Evolutionary Algorithms to solve Black-Box Optimization Problems
Sep 23, 2023Population-based evolutionary algorithms are often considered when approaching computationally expensive black-box optimization problems. They employ a selection mechanism to choose the best solutions from a given population after comparing their objective values, which are then used to generate the next population. This iterative process explores the solution space efficiently, leading to improved solutions over time. However, these algorithms require a large number of evaluations to provide a quality solution, which might be computationally expensive when the evaluation cost is high. In some cases, it is possible to replace the original objective function with a less accurate approximation of lower cost. This introduces a trade-off between the evaluation cost and its accuracy. In this paper, we propose a technique capable of choosing an appropriate approximate function cost during the execution of the optimization algorithm. The proposal finds the minimum evaluation cost at which the solutions are still properly ranked, and consequently, more evaluations can be computed in the same amount of time with minimal accuracy loss. An experimental section on four very different problems reveals that the proposed approach can reach the same objective value in less than half of the time in certain cases.
Activate and Reject: Towards Safe Domain Generalization under Category Shift
Oct 07, 2023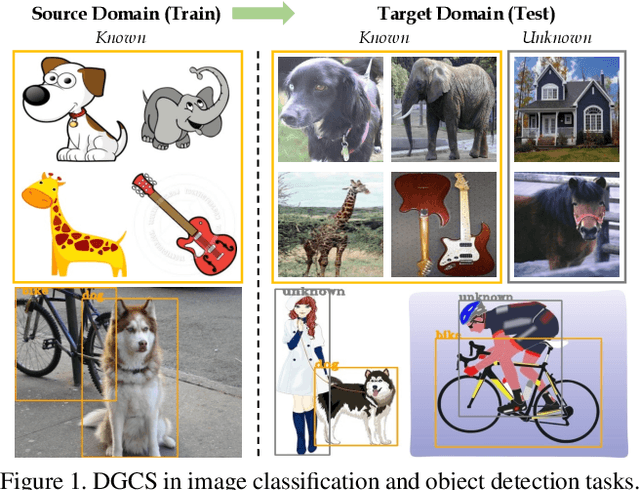

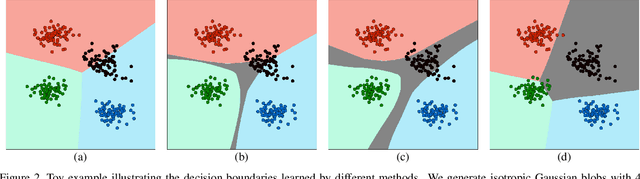
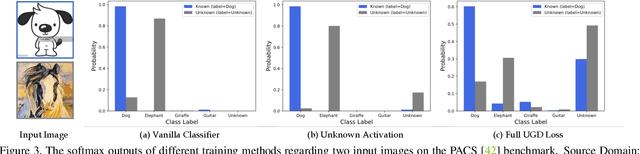
Albeit the notable performance on in-domain test points, it is non-trivial for deep neural networks to attain satisfactory accuracy when deploying in the open world, where novel domains and object classes often occur. In this paper, we study a practical problem of Domain Generalization under Category Shift (DGCS), which aims to simultaneously detect unknown-class samples and classify known-class samples in the target domains. Compared to prior DG works, we face two new challenges: 1) how to learn the concept of ``unknown'' during training with only source known-class samples, and 2) how to adapt the source-trained model to unseen environments for safe model deployment. To this end, we propose a novel Activate and Reject (ART) framework to reshape the model's decision boundary to accommodate unknown classes and conduct post hoc modification to further discriminate known and unknown classes using unlabeled test data. Specifically, during training, we promote the response to the unknown by optimizing the unknown probability and then smoothing the overall output to mitigate the overconfidence issue. At test time, we introduce a step-wise online adaptation method that predicts the label by virtue of the cross-domain nearest neighbor and class prototype information without updating the network's parameters or using threshold-based mechanisms. Experiments reveal that ART consistently improves the generalization capability of deep networks on different vision tasks. For image classification, ART improves the H-score by 6.1% on average compared to the previous best method. For object detection and semantic segmentation, we establish new benchmarks and achieve competitive performance.
Outage-Watch: Early Prediction of Outages using Extreme Event Regularizer
Sep 29, 2023Cloud services are omnipresent and critical cloud service failure is a fact of life. In order to retain customers and prevent revenue loss, it is important to provide high reliability guarantees for these services. One way to do this is by predicting outages in advance, which can help in reducing the severity as well as time to recovery. It is difficult to forecast critical failures due to the rarity of these events. Moreover, critical failures are ill-defined in terms of observable data. Our proposed method, Outage-Watch, defines critical service outages as deteriorations in the Quality of Service (QoS) captured by a set of metrics. Outage-Watch detects such outages in advance by using current system state to predict whether the QoS metrics will cross a threshold and initiate an extreme event. A mixture of Gaussian is used to model the distribution of the QoS metrics for flexibility and an extreme event regularizer helps in improving learning in tail of the distribution. An outage is predicted if the probability of any one of the QoS metrics crossing threshold changes significantly. Our evaluation on a real-world SaaS company dataset shows that Outage-Watch significantly outperforms traditional methods with an average AUC of 0.98. Additionally, Outage-Watch detects all the outages exhibiting a change in service metrics and reduces the Mean Time To Detection (MTTD) of outages by up to 88% when deployed in an enterprise cloud-service system, demonstrating efficacy of our proposed method.
Hierarchical Evaluation Framework: Best Practices for Human Evaluation
Oct 03, 2023Human evaluation plays a crucial role in Natural Language Processing (NLP) as it assesses the quality and relevance of developed systems, thereby facilitating their enhancement. However, the absence of widely accepted human evaluation metrics in NLP hampers fair comparisons among different systems and the establishment of universal assessment standards. Through an extensive analysis of existing literature on human evaluation metrics, we identified several gaps in NLP evaluation methodologies. These gaps served as motivation for developing our own hierarchical evaluation framework. The proposed framework offers notable advantages, particularly in providing a more comprehensive representation of the NLP system's performance. We applied this framework to evaluate the developed Machine Reading Comprehension system, which was utilized within a human-AI symbiosis model. The results highlighted the associations between the quality of inputs and outputs, underscoring the necessity to evaluate both components rather than solely focusing on outputs. In future work, we will investigate the potential time-saving benefits of our proposed framework for evaluators assessing NLP systems.