 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobalized Adversarial Regret Optimization: Robust Decisions with Uncalibrated Predictions
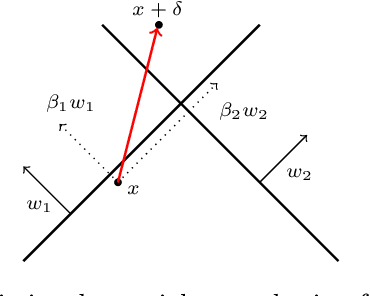
Mar 26, 2026Optimization problems routinely depend on uncertain parameters that must be predicted before a decision is made. Classical robust and regret formulations are designed to handle erroneous predictions and can provide statistical error bounds in simple settings. However, when predictions lack rigorous error bounds (as is typical of modern machine learning methods) classical robust models often yield vacuous guarantees, while regret formulations can paradoxically produce decisions that are more optimistic than even a nominal solution. We introduce Globalized Adversarial Regret Optimization (GARO), a decision framework that controls adversarial regret, defined as the gap between the worst-case cost and the oracle robust cost, uniformly across all possible uncertainty set sizes. By design, GARO delivers absolute or relative performance guarantees against an oracle with full knowledge of the prediction error, without requiring any probabilistic calibration of the uncertainty set. We show that GARO equipped with a relative rate function generalizes the classical adaptation method of Lepski to downstream decision problems. We derive exact tractable reformulations for problems with affine worst-case cost functions and polyhedral norm uncertainty sets, and provide a discretization and a constraint-generation algorithm with convergence guarantees for general settings. Finally, experiments demonstrate that GARO yields solutions with a more favorable trade-off between worst-case and mean out-of-sample performance, as well as stronger global performance guarantees.
Linear Model Extraction via Factual and Counterfactual Queries
Feb 10, 2026In model extraction attacks, the goal is to reveal the parameters of a black-box machine learning model by querying the model for a selected set of data points. Due to an increasing demand for explanations, this may involve counterfactual queries besides the typically considered factual queries. In this work, we consider linear models and three types of queries: factual, counterfactual, and robust counterfactual. First, for an arbitrary set of queries, we derive novel mathematical formulations for the classification regions for which the decision of the unknown model is known, without recovering any of the model parameters. Second, we derive bounds on the number of queries needed to extract the model's parameters for (robust) counterfactual queries under arbitrary norm-based distances. We show that the full model can be recovered using just a single counterfactual query when differentiable distance measures are employed. In contrast, when using polyhedral distances for instance, the number of required queries grows linearly with the dimension of the data space. For robust counterfactuals, the latter number of queries doubles. Consequently, the applied distance function and robustness of counterfactuals have a significant impact on the model's security.
Coherent Local Explanations for Mathematical Optimization
Feb 07, 2025



The surge of explainable artificial intelligence methods seeks to enhance transparency and explainability in machine learning models. At the same time, there is a growing demand for explaining decisions taken through complex algorithms used in mathematical optimization. However, current explanation methods do not take into account the structure of the underlying optimization problem, leading to unreliable outcomes. In response to this need, we introduce Coherent Local Explanations for Mathematical Optimization (CLEMO). CLEMO provides explanations for multiple components of optimization models, the objective value and decision variables, which are coherent with the underlying model structure. Our sampling-based procedure can provide explanations for the behavior of exact and heuristic solution algorithms. The effectiveness of CLEMO is illustrated by experiments for the shortest path problem, the knapsack problem, and the vehicle routing problem.
Counterfactual Explanations for Linear Optimization
May 24, 2024



The concept of counterfactual explanations (CE) has emerged as one of the important concepts to understand the inner workings of complex AI systems. In this paper, we translate the idea of CEs to linear optimization and propose, motivate, and analyze three different types of CEs: strong, weak, and relative. While deriving strong and weak CEs appears to be computationally intractable, we show that calculating relative CEs can be done efficiently. By detecting and exploiting the hidden convex structure of the optimization problem that arises in the latter case, we show that obtaining relative CEs can be done in the same magnitude of time as solving the original linear optimization problem. This is confirmed by an extensive numerical experiment study on the NETLIB library.
From Large Language Models and Optimization to Decision Optimization CoPilot: A Research Manifesto
Feb 26, 2024



Significantly simplifying the creation of optimization models for real-world business problems has long been a major goal in applying mathematical optimization more widely to important business and societal decisions. The recent capabilities of Large Language Models (LLMs) present a timely opportunity to achieve this goal. Therefore, we propose research at the intersection of LLMs and optimization to create a Decision Optimization CoPilot (DOCP) - an AI tool designed to assist any decision maker, interacting in natural language to grasp the business problem, subsequently formulating and solving the corresponding optimization model. This paper outlines our DOCP vision and identifies several fundamental requirements for its implementation. We describe the state of the art through a literature survey and experiments using ChatGPT. We show that a) LLMs already provide substantial novel capabilities relevant to a DOCP, and b) major research challenges remain to be addressed. We also propose possible research directions to overcome these gaps. We also see this work as a call to action to bring together the LLM and optimization communities to pursue our vision, thereby enabling much more widespread improved decision-making.
Neur2BiLO: Neural Bilevel Optimization
Feb 04, 2024



Bilevel optimization deals with nested problems in which a leader takes the first decision to minimize their objective function while accounting for a follower's best-response reaction. Constrained bilevel problems with integer variables are particularly notorious for their hardness. While exact solvers have been proposed for mixed-integer linear bilevel optimization, they tend to scale poorly with problem size and are hard to generalize to the non-linear case. On the other hand, problem-specific algorithms (exact and heuristic) are limited in scope. Under a data-driven setting in which similar instances of a bilevel problem are solved routinely, our proposed framework, Neur2BiLO, embeds a neural network approximation of the leader's or follower's value function, trained via supervised regression, into an easy-to-solve mixed-integer program. Neur2BiLO serves as a heuristic that produces high-quality solutions extremely fast for the bilevel knapsack interdiction problem, the "critical node game" from network security, a donor-recipient healthcare problem, and discrete network design from transportation planning. These problems are diverse in that they have linear or non-linear objectives/constraints and integer or mixed-integer variables, making Neur2BiLO unique in its versatility.
Neur2RO: Neural Two-Stage Robust Optimization
Oct 06, 2023



Robust optimization provides a mathematical framework for modeling and solving decision-making problems under worst-case uncertainty. This work addresses two-stage robust optimization (2RO) problems (also called adjustable robust optimization), wherein first-stage and second-stage decisions are made before and after uncertainty is realized, respectively. This results in a nested min-max-min optimization problem which is extremely challenging computationally, especially when the decisions are discrete. We propose Neur2RO, an efficient machine learning-driven instantiation of column-and-constraint generation (CCG), a classical iterative algorithm for 2RO. Specifically, we learn to estimate the value function of the second-stage problem via a novel neural network architecture that is easy to optimize over by design. Embedding our neural network into CCG yields high-quality solutions quickly as evidenced by experiments on two 2RO benchmarks, knapsack and capital budgeting. For knapsack, Neur2RO finds solutions that are within roughly $2\%$ of the best-known values in a few seconds compared to the three hours of the state-of-the-art exact branch-and-price algorithm; for larger and more complex instances, Neur2RO finds even better solutions. For capital budgeting, Neur2RO outperforms three variants of the $k$-adaptability algorithm, particularly on the largest instances, with a 5 to 10-fold reduction in solution time. Our code and data are available at https://github.com/khalil-research/Neur2RO.
Finding Regions of Counterfactual Explanations via Robust Optimization
Jan 26, 2023



Counterfactual explanations play an important role in detecting bias and improving the explainability of data-driven classification models. A counterfactual explanation (CE) is a minimal perturbed data point for which the decision of the model changes. Most of the existing methods can only provide one CE, which may not be achievable for the user. In this work we derive an iterative method to calculate robust CEs, i.e. CEs that remain valid even after the features are slightly perturbed. To this end, our method provides a whole region of CEs allowing the user to choose a suitable recourse to obtain a desired outcome. We use algorithmic ideas from robust optimization and prove convergence results for the most common machine learning methods including logistic regression, decision trees, random forests, and neural networks. Our experiments show that our method can efficiently generate globally optimal robust CEs for a variety of common data sets and classification models.
Data-driven Prediction of Relevant Scenarios for Robust Optimization
Mar 30, 2022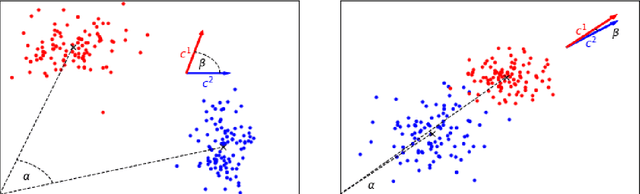
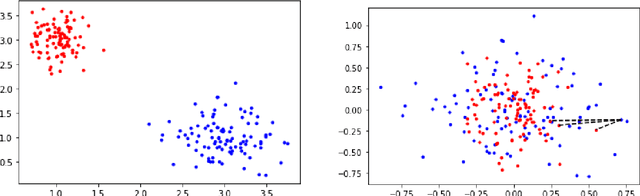
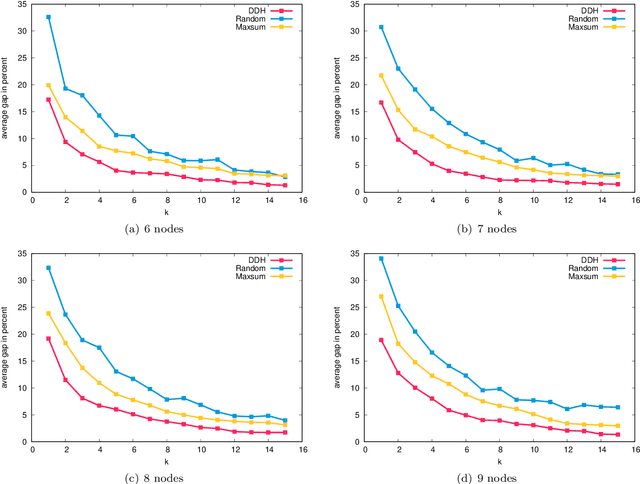
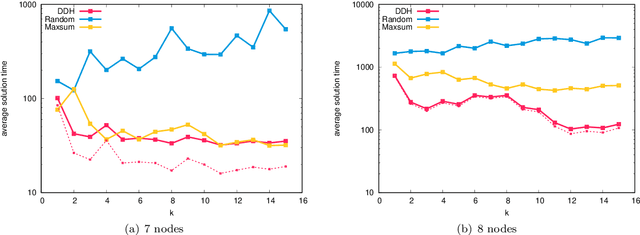
In this work we study robust one- and two-stage problems with discrete uncertainty sets which are known to be hard to solve even if the underlying deterministic problem is easy. Popular solution methods iteratively generate scenario constraints and possibly second-stage variables. This way, by solving a sequence of smaller problems, it is often possible to avoid the complexity of considering all scenarios simultaneously. A key ingredient for the performance of the iterative methods is a good selection of start scenarios. In this paper we propose a data-driven heuristic to seed the iterative solution method with a set of starting scenarios that provide a strong lower bound early in the process, and result in considerably smaller overall solution times compared to other benchmark methods. Our heuristic learns the relevance of a scenario by extracting information from training data based on a combined similarity measure between robust problem instances and single scenarios. Our experiments show that predicting even a small number of good start scenarios by our method can considerably reduce the computation time of the iterative methods.
Ensemble Methods for Robust Support Vector Machines using Integer Programming
Mar 03, 2022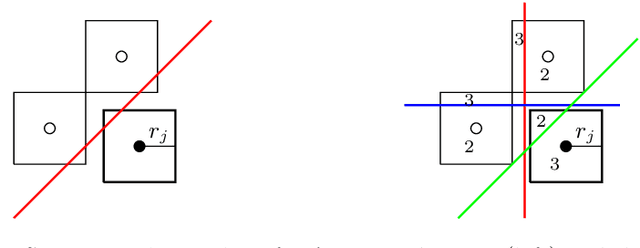

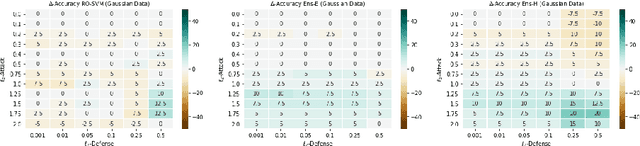
In this work we study binary classification problems where we assume that our training data is subject to uncertainty, i.e. the precise data points are not known. To tackle this issue in the field of robust machine learning the aim is to develop models which are robust against small perturbations in the training data. We study robust support vector machines (SVM) and extend the classical approach by an ensemble method which iteratively solves a non-robust SVM on different perturbations of the dataset, where the perturbations are derived by an adversarial problem. Afterwards for classification of an unknown data point we perform a majority vote of all calculated SVM solutions. We study three different variants for the adversarial problem, the exact problem, a relaxed variant and an efficient heuristic variant. While the exact and the relaxed variant can be modeled using integer programming formulations, the heuristic one can be implemented by an easy and efficient algorithm. All derived methods are tested on random and realistic datasets and the results indicate that the derived ensemble methods have a much more stable behaviour when changing the protection level compared to the classical robust SVM model.