 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Dual-Perspective Knowledge Enrichment for Semi-Supervised 3D Object Detection
Jan 10, 2024
Semi-supervised 3D object detection is a promising yet under-explored direction to reduce data annotation costs, especially for cluttered indoor scenes. A few prior works, such as SESS and 3DIoUMatch, attempt to solve this task by utilizing a teacher model to generate pseudo-labels for unlabeled samples. However, the availability of unlabeled samples in the 3D domain is relatively limited compared to its 2D counterpart due to the greater effort required to collect 3D data. Moreover, the loose consistency regularization in SESS and restricted pseudo-label selection strategy in 3DIoUMatch lead to either low-quality supervision or a limited amount of pseudo labels. To address these issues, we present a novel Dual-Perspective Knowledge Enrichment approach named DPKE for semi-supervised 3D object detection. Our DPKE enriches the knowledge of limited training data, particularly unlabeled data, from two perspectives: data-perspective and feature-perspective. Specifically, from the data-perspective, we propose a class-probabilistic data augmentation method that augments the input data with additional instances based on the varying distribution of class probabilities. Our DPKE achieves feature-perspective knowledge enrichment by designing a geometry-aware feature matching method that regularizes feature-level similarity between object proposals from the student and teacher models. Extensive experiments on the two benchmark datasets demonstrate that our DPKE achieves superior performance over existing state-of-the-art approaches under various label ratio conditions. The source code will be made available to the public.
SDGE: Stereo Guided Depth Estimation for 360$^\circ$ Camera Sets
Feb 29, 2024Depth estimation is a critical technology in autonomous driving, and multi-camera systems are often used to achieve a 360$^\circ$ perception. These 360$^\circ$ camera sets often have limited or low-quality overlap regions, making multi-view stereo methods infeasible for the entire image. Alternatively, monocular methods may not produce consistent cross-view predictions. To address these issues, we propose the Stereo Guided Depth Estimation (SGDE) method, which enhances depth estimation of the full image by explicitly utilizing multi-view stereo results on the overlap. We suggest building virtual pinhole cameras to resolve the distortion problem of fisheye cameras and unify the processing for the two types of 360$^\circ$ cameras. For handling the varying noise on camera poses caused by unstable movement, the approach employs a self-calibration method to obtain highly accurate relative poses of the adjacent cameras with minor overlap. These enable the use of robust stereo methods to obtain high-quality depth prior in the overlap region. This prior serves not only as an additional input but also as pseudo-labels that enhance the accuracy of depth estimation methods and improve cross-view prediction consistency. The effectiveness of SGDE is evaluated on one fisheye camera dataset, Synthetic Urban, and two pinhole camera datasets, DDAD and nuScenes. Our experiments demonstrate that SGDE is effective for both supervised and self-supervised depth estimation, and highlight the potential of our method for advancing downstream autonomous driving technologies, such as 3D object detection and occupancy prediction.
LLMs in Political Science: Heralding a New Era of Visual Analysis
Feb 29, 2024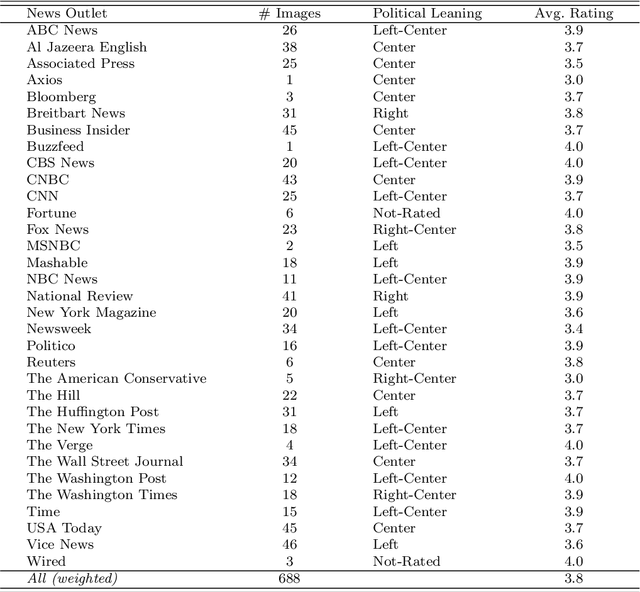

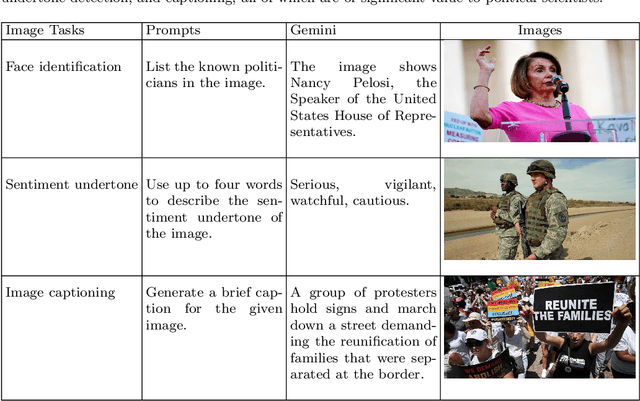
Interest is increasing among political scientists in leveraging the extensive information available in images. However, the challenge of interpreting these images lies in the need for specialized knowledge in computer vision and access to specialized hardware. As a result, image analysis has been limited to a relatively small group within the political science community. This landscape could potentially change thanks to the rise of large language models (LLMs). This paper aims to raise awareness of the feasibility of using Gemini for image content analysis. A retrospective analysis was conducted on a corpus of 688 images. Content reports were elicited from Gemini for each image and then manually evaluated by the authors. We find that Gemini is highly accurate in performing object detection, which is arguably the most common and fundamental task in image analysis for political scientists. Equally important, we show that it is easy to implement as the entire command consists of a single prompt in natural language; it is fast to run and should meet the time budget of most researchers; and it is free to use and does not require any specialized hardware. In addition, we illustrate how political scientists can leverage Gemini for other image understanding tasks, including face identification, sentiment analysis, and caption generation. Our findings suggest that Gemini and other similar LLMs have the potential to drastically stimulate and accelerate image research in political science and social sciences more broadly.
LangXAI: Integrating Large Vision Models for Generating Textual Explanations to Enhance Explainability in Visual Perception Tasks
Feb 19, 2024LangXAI is a framework that integrates Explainable Artificial Intelligence (XAI) with advanced vision models to generate textual explanations for visual recognition tasks. Despite XAI advancements, an understanding gap persists for end-users with limited domain knowledge in artificial intelligence and computer vision. LangXAI addresses this by furnishing text-based explanations for classification, object detection, and semantic segmentation model outputs to end-users. Preliminary results demonstrate LangXAI's enhanced plausibility, with high BERTScore across tasks, fostering a more transparent and reliable AI framework on vision tasks for end-users.
A Multispectral Automated Transfer Technique (MATT) for machine-driven image labeling utilizing the Segment Anything Model (SAM)
Feb 18, 2024Segment Anything Model (SAM) is drastically accelerating the speed and accuracy of automatically segmenting and labeling large Red-Green-Blue (RGB) imagery datasets. However, SAM is unable to segment and label images outside of the visible light spectrum, for example, for multispectral or hyperspectral imagery. Therefore, this paper outlines a method we call the Multispectral Automated Transfer Technique (MATT). By transposing SAM segmentation masks from RGB images we can automatically segment and label multispectral imagery with high precision and efficiency. For example, the results demonstrate that segmenting and labeling a 2,400-image dataset utilizing MATT achieves a time reduction of 87.8% in developing a trained model, reducing roughly 20 hours of manual labeling, to only 2.4 hours. This efficiency gain is associated with only a 6.7% decrease in overall mean average precision (mAP) when training multispectral models via MATT, compared to a manually labeled dataset. We consider this an acceptable level of precision loss when considering the time saved during training, especially for rapidly prototyping experimental modeling methods. This research greatly contributes to the study of multispectral object detection by providing a novel and open-source method to rapidly segment, label, and train multispectral object detection models with minimal human interaction. Future research needs to focus on applying these methods to (i) space-based multispectral, and (ii) drone-based hyperspectral imagery.
YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
Feb 29, 2024Today's deep learning methods focus on how to design the most appropriate objective functions so that the prediction results of the model can be closest to the ground truth. Meanwhile, an appropriate architecture that can facilitate acquisition of enough information for prediction has to be designed. Existing methods ignore a fact that when input data undergoes layer-by-layer feature extraction and spatial transformation, large amount of information will be lost. This paper will delve into the important issues of data loss when data is transmitted through deep networks, namely information bottleneck and reversible functions. We proposed the concept of programmable gradient information (PGI) to cope with the various changes required by deep networks to achieve multiple objectives. PGI can provide complete input information for the target task to calculate objective function, so that reliable gradient information can be obtained to update network weights. In addition, a new lightweight network architecture -- Generalized Efficient Layer Aggregation Network (GELAN), based on gradient path planning is designed. GELAN's architecture confirms that PGI has gained superior results on lightweight models. We verified the proposed GELAN and PGI on MS COCO dataset based object detection. The results show that GELAN only uses conventional convolution operators to achieve better parameter utilization than the state-of-the-art methods developed based on depth-wise convolution. PGI can be used for variety of models from lightweight to large. It can be used to obtain complete information, so that train-from-scratch models can achieve better results than state-of-the-art models pre-trained using large datasets, the comparison results are shown in Figure 1. The source codes are at: https://github.com/WongKinYiu/yolov9.
DiffYOLO: Object Detection for Anti-Noise via YOLO and Diffusion Models
Jan 03, 2024Object detection models represented by YOLO series have been widely used and have achieved great results on the high quality datasets, but not all the working conditions are ideal. To settle down the problem of locating targets on low quality datasets, the existing methods either train a new object detection network, or need a large collection of low-quality datasets to train. However, we propose a framework in this paper and apply it on the YOLO models called DiffYOLO. Specifically, we extract feature maps from the denoising diffusion probabilistic models to enhance the well-trained models, which allows us fine-tune YOLO on high-quality datasets and test on low-quality datasets. The results proved this framework can not only prove the performance on noisy datasets, but also prove the detection results on high-quality test datasets. We will supplement more experiments later (with various datasets and network architectures).
Weakly Supervised Open-Vocabulary Object Detection
Dec 19, 2023Despite weakly supervised object detection (WSOD) being a promising step toward evading strong instance-level annotations, its capability is confined to closed-set categories within a single training dataset. In this paper, we propose a novel weakly supervised open-vocabulary object detection framework, namely WSOVOD, to extend traditional WSOD to detect novel concepts and utilize diverse datasets with only image-level annotations. To achieve this, we explore three vital strategies, including dataset-level feature adaptation, image-level salient object localization, and region-level vision-language alignment. First, we perform data-aware feature extraction to produce an input-conditional coefficient, which is leveraged into dataset attribute prototypes to identify dataset bias and help achieve cross-dataset generalization. Second, a customized location-oriented weakly supervised region proposal network is proposed to utilize high-level semantic layouts from the category-agnostic segment anything model to distinguish object boundaries. Lastly, we introduce a proposal-concept synchronized multiple-instance network, i.e., object mining and refinement with visual-semantic alignment, to discover objects matched to the text embeddings of concepts. Extensive experiments on Pascal VOC and MS COCO demonstrate that the proposed WSOVOD achieves new state-of-the-art compared with previous WSOD methods in both close-set object localization and detection tasks. Meanwhile, WSOVOD enables cross-dataset and open-vocabulary learning to achieve on-par or even better performance than well-established fully-supervised open-vocabulary object detection (FSOVOD).
Large receptive field strategy and important feature extraction strategy in 3D object detection
Jan 22, 2024The enhancement of 3D object detection is pivotal for precise environmental perception and improved task execution capabilities in autonomous driving. LiDAR point clouds, offering accurate depth information, serve as a crucial information for this purpose. Our study focuses on key challenges in 3D target detection. To tackle the challenge of expanding the receptive field of a 3D convolutional kernel, we introduce the Dynamic Feature Fusion Module (DFFM). This module achieves adaptive expansion of the 3D convolutional kernel's receptive field, balancing the expansion with acceptable computational loads. This innovation reduces operations, expands the receptive field, and allows the model to dynamically adjust to different object requirements. Simultaneously, we identify redundant information in 3D features. Employing the Feature Selection Module (FSM) quantitatively evaluates and eliminates non-important features, achieving the separation of output box fitting and feature extraction. This innovation enables the detector to focus on critical features, resulting in model compression, reduced computational burden, and minimized candidate frame interference. Extensive experiments confirm that both DFFM and FSM not only enhance current benchmarks, particularly in small target detection, but also accelerate network performance. Importantly, these modules exhibit effective complementarity.
Combining unsupervised and supervised learning in microscopy enables defect analysis of a full 4H-SiC wafer
Feb 20, 2024Detecting and analyzing various defect types in semiconductor materials is an important prerequisite for understanding the underlying mechanisms as well as tailoring the production processes. Analysis of microscopy images that reveal defects typically requires image analysis tasks such as segmentation and object detection. With the permanently increasing amount of data that is produced by experiments, handling these tasks manually becomes more and more impossible. In this work, we combine various image analysis and data mining techniques for creating a robust and accurate, automated image analysis pipeline. This allows for extracting the type and position of all defects in a microscopy image of a KOH-etched 4H-SiC wafer that was stitched together from approximately 40,000 individual images.