 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Towards Real-Time Fast Unmanned Aerial Vehicle Detection Using Dynamic Vision Sensors
Mar 18, 2024
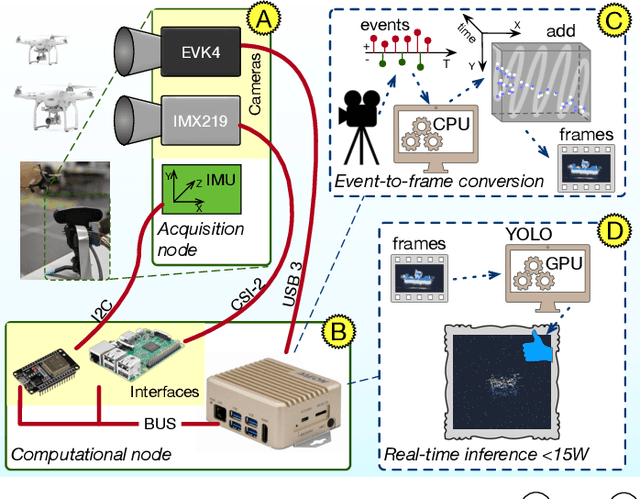



Unmanned Aerial Vehicles (UAVs) are gaining popularity in civil and military applications. However, uncontrolled access to restricted areas threatens privacy and security. Thus, prevention and detection of UAVs are pivotal to guarantee confidentiality and safety. Although active scanning, mainly based on radars, is one of the most accurate technologies, it can be expensive and less versatile than passive inspections, e.g., object recognition. Dynamic vision sensors (DVS) are bio-inspired event-based vision models that leverage timestamped pixel-level brightness changes in fast-moving scenes that adapt well to low-latency object detection. This paper presents F-UAV-D (Fast Unmanned Aerial Vehicle Detector), an embedded system that enables fast-moving drone detection. In particular, we propose a setup to exploit DVS as an alternative to RGB cameras in a real-time and low-power configuration. Our approach leverages the high-dynamic range (HDR) and background suppression of DVS and, when trained with various fast-moving drones, outperforms RGB input in suboptimal ambient conditions such as low illumination and fast-moving scenes. Our results show that F-UAV-D can (i) detect drones by using less than <15 W on average and (ii) perform real-time inference (i.e., <50 ms) by leveraging the CPU and GPU nodes of our edge computer.
Lifting Multi-View Detection and Tracking to the Bird's Eye View
Mar 19, 2024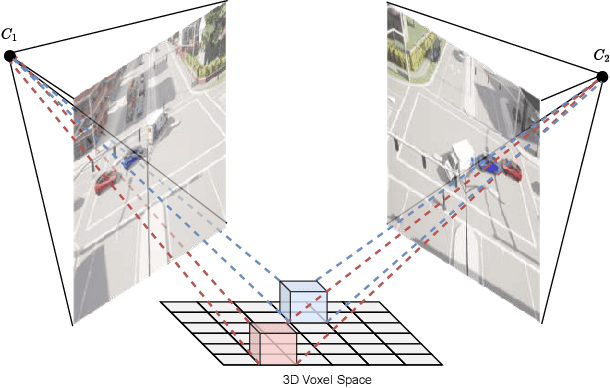
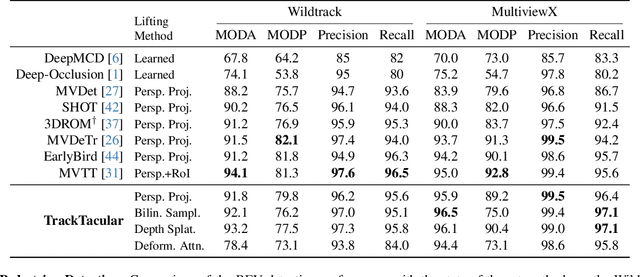
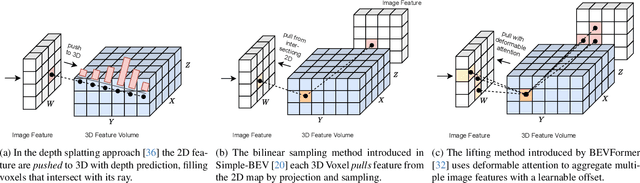
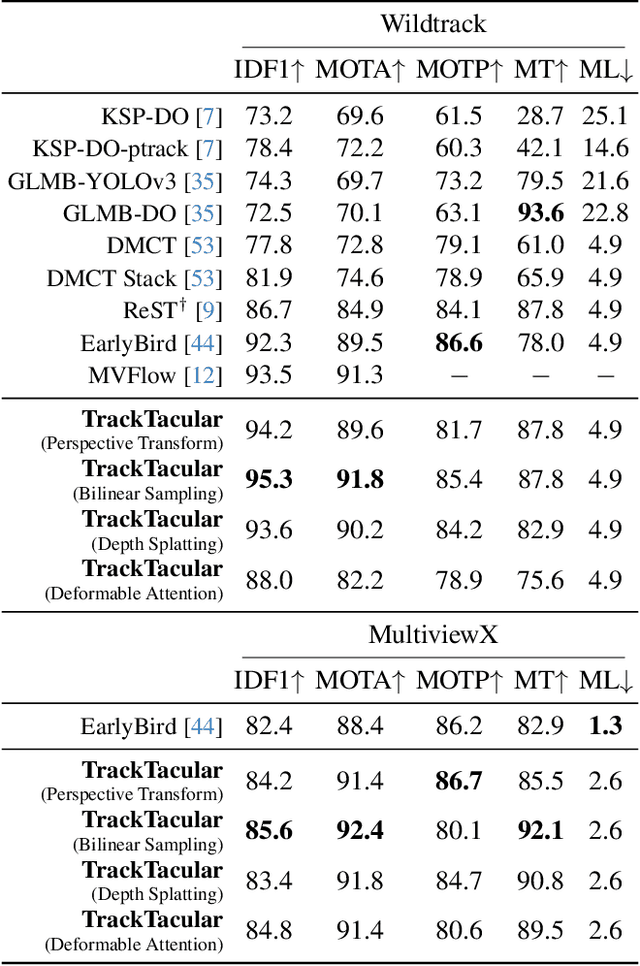
Taking advantage of multi-view aggregation presents a promising solution to tackle challenges such as occlusion and missed detection in multi-object tracking and detection. Recent advancements in multi-view detection and 3D object recognition have significantly improved performance by strategically projecting all views onto the ground plane and conducting detection analysis from a Bird's Eye View. In this paper, we compare modern lifting methods, both parameter-free and parameterized, to multi-view aggregation. Additionally, we present an architecture that aggregates the features of multiple times steps to learn robust detection and combines appearance- and motion-based cues for tracking. Most current tracking approaches either focus on pedestrians or vehicles. In our work, we combine both branches and add new challenges to multi-view detection with cross-scene setups. Our method generalizes to three public datasets across two domains: (1) pedestrian: Wildtrack and MultiviewX, and (2) roadside perception: Synthehicle, achieving state-of-the-art performance in detection and tracking. https://github.com/tteepe/TrackTacular
EAS-SNN: End-to-End Adaptive Sampling and Representation for Event-based Detection with Recurrent Spiking Neural Networks
Mar 19, 2024
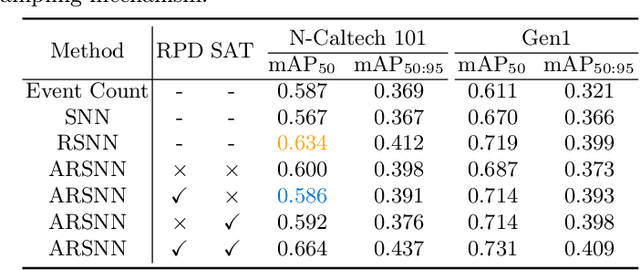
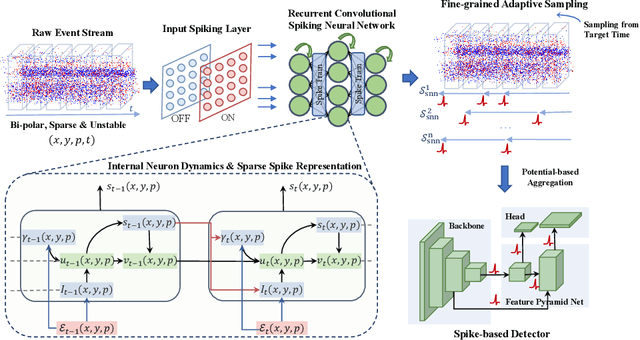
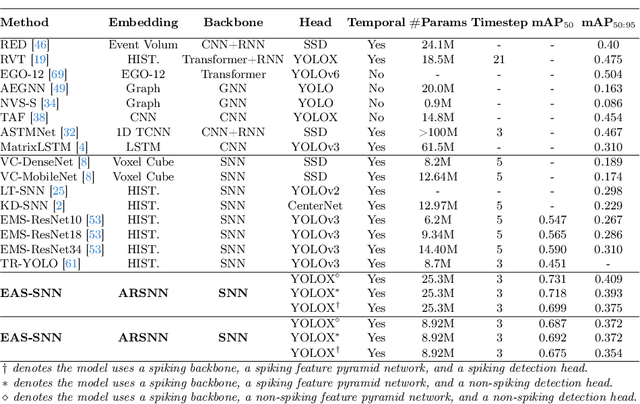
Event cameras, with their high dynamic range and temporal resolution, are ideally suited for object detection, especially under scenarios with motion blur and challenging lighting conditions. However, while most existing approaches prioritize optimizing spatiotemporal representations with advanced detection backbones and early aggregation functions, the crucial issue of adaptive event sampling remains largely unaddressed. Spiking Neural Networks (SNNs), which operate on an event-driven paradigm through sparse spike communication, emerge as a natural fit for addressing this challenge. In this study, we discover that the neural dynamics of spiking neurons align closely with the behavior of an ideal temporal event sampler. Motivated by this insight, we propose a novel adaptive sampling module that leverages recurrent convolutional SNNs enhanced with temporal memory, facilitating a fully end-to-end learnable framework for event-based detection. Additionally, we introduce Residual Potential Dropout (RPD) and Spike-Aware Training (SAT) to regulate potential distribution and address performance degradation encountered in spike-based sampling modules. Through rigorous testing on neuromorphic datasets for event-based detection, our approach demonstrably surpasses existing state-of-the-art spike-based methods, achieving superior performance with significantly fewer parameters and time steps. For instance, our method achieves a 4.4\% mAP improvement on the Gen1 dataset, while requiring 38\% fewer parameters and three time steps. Moreover, the applicability and effectiveness of our adaptive sampling methodology extend beyond SNNs, as demonstrated through further validation on conventional non-spiking detection models.
Fostc3net:A Lightweight YOLOv5 Based On the Network Structure Optimization
Mar 20, 2024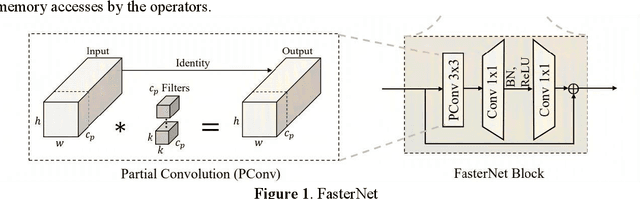
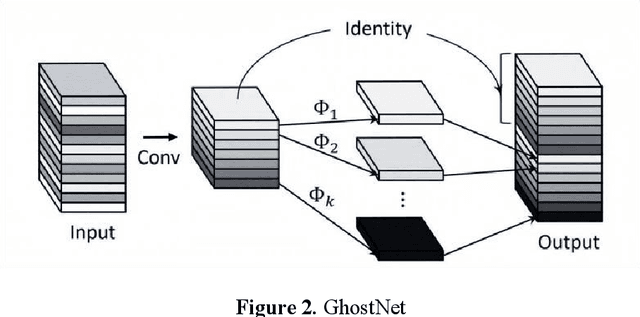
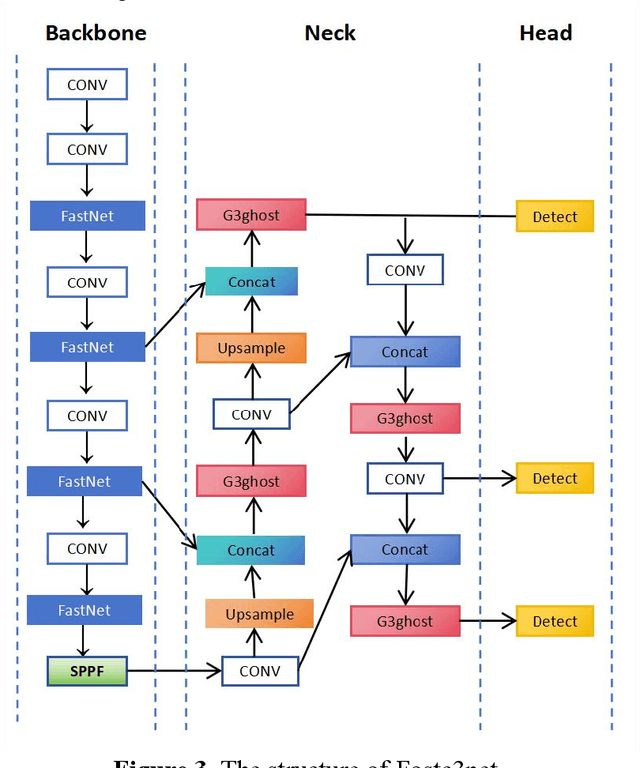

Transmission line detection technology is crucial for automatic monitoring and ensuring the safety of electrical facilities. The YOLOv5 series is currently one of the most advanced and widely used methods for object detection. However, it faces inherent challenges, such as high computational load on devices and insufficient detection accuracy. To address these concerns, this paper presents an enhanced lightweight YOLOv5 technique customized for mobile devices, specifically intended for identifying objects associated with transmission lines. The C3Ghost module is integrated into the convolutional network of YOLOv5 to reduce floating point operations per second (FLOPs) in the feature channel fusion process and improve feature expression performance. In addition, a FasterNet module is introduced to replace the c3 module in the YOLOv5 Backbone. The FasterNet module uses Partial Convolutions to process only a portion of the input channels, improving feature extraction efficiency and reducing computational overhead. To address the imbalance between simple and challenging samples in the dataset and the diversity of aspect ratios of bounding boxes, the wIoU v3 LOSS is adopted as the loss function. To validate the performance of the proposed approach, Experiments are conducted on a custom dataset of transmission line poles. The results show that the proposed model achieves a 1% increase in detection accuracy, a 13% reduction in FLOPs, and a 26% decrease in model parameters compared to the existing YOLOv5.In the ablation experiment, it was also discovered that while the Fastnet module and the CSghost module improved the precision of the original YOLOv5 baseline model, they caused a decrease in the mAP@.5-.95 metric. However, the improvement of the wIoUv3 loss function significantly mitigated the decline of the mAP@.5-.95 metric.
Transfer learning with generative models for object detection on limited datasets
Feb 09, 2024The availability of data is limited in some fields, especially for object detection tasks, where it is necessary to have correctly labeled bounding boxes around each object. A notable example of such data scarcity is found in the domain of marine biology, where it is useful to develop methods to automatically detect submarine species for environmental monitoring. To address this data limitation, the state-of-the-art machine learning strategies employ two main approaches. The first involves pretraining models on existing datasets before generalizing to the specific domain of interest. The second strategy is to create synthetic datasets specifically tailored to the target domain using methods like copy-paste techniques or ad-hoc simulators. The first strategy often faces a significant domain shift, while the second demands custom solutions crafted for the specific task. In response to these challenges, here we propose a transfer learning framework that is valid for a generic scenario. In this framework, generated images help to improve the performances of an object detector in a few-real data regime. This is achieved through a diffusion-based generative model that was pretrained on large generic datasets, and is not trained on the task-specific domain. We validate our approach on object detection tasks, specifically focusing on fishes in an underwater environment, and on the more common domain of cars in an urban setting. Our method achieves detection performance comparable to models trained on thousands of images, using only a few hundreds of input data. Our results pave the way for new generative AI-based protocols for machine learning applications in various domains, for instance ranging from geophysics to biology and medicine.
DAMSDet: Dynamic Adaptive Multispectral Detection Transformer with Competitive Query Selection and Adaptive Feature Fusion
Mar 07, 2024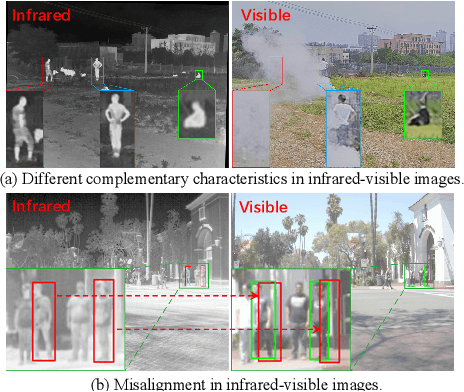
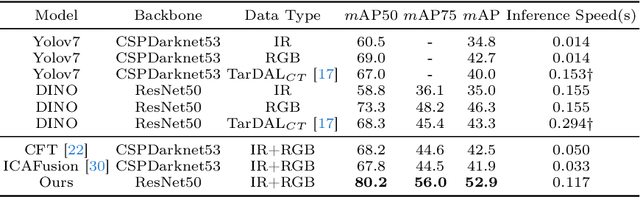
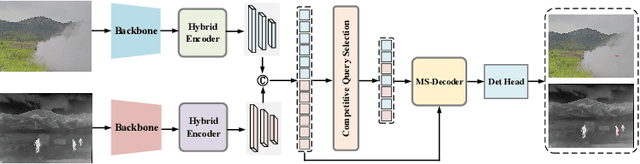
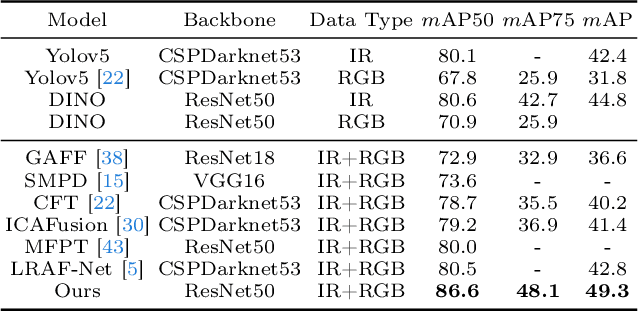
Infrared-visible object detection aims to achieve robust even full-day object detection by fusing the complementary information of infrared and visible images. However, highly dynamically variable complementary characteristics and commonly existing modality misalignment make the fusion of complementary information difficult. In this paper, we propose a Dynamic Adaptive Multispectral Detection Transformer (DAMSDet) to simultaneously address these two challenges. Specifically, we propose a Modality Competitive Query Selection strategy to provide useful prior information. This strategy can dynamically select basic salient modality feature representation for each object. To effectively mine the complementary information and adapt to misalignment situations, we propose a Multispectral Deformable Cross-attention module to adaptively sample and aggregate multi-semantic level features of infrared and visible images for each object. In addition, we further adopt the cascade structure of DETR to better mine complementary information. Experiments on four public datasets of different scenes demonstrate significant improvements compared to other state-of-the-art methods. The code will be released at https://github.com/gjj45/DAMSDet.
Change-Agent: Towards Interactive Comprehensive Remote Sensing Change Interpretation and Analysis
Apr 01, 2024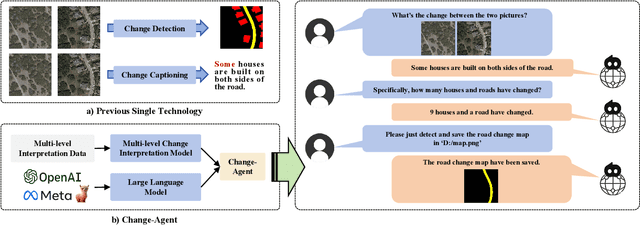
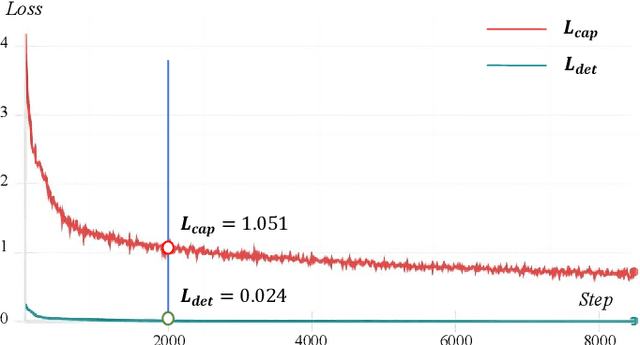
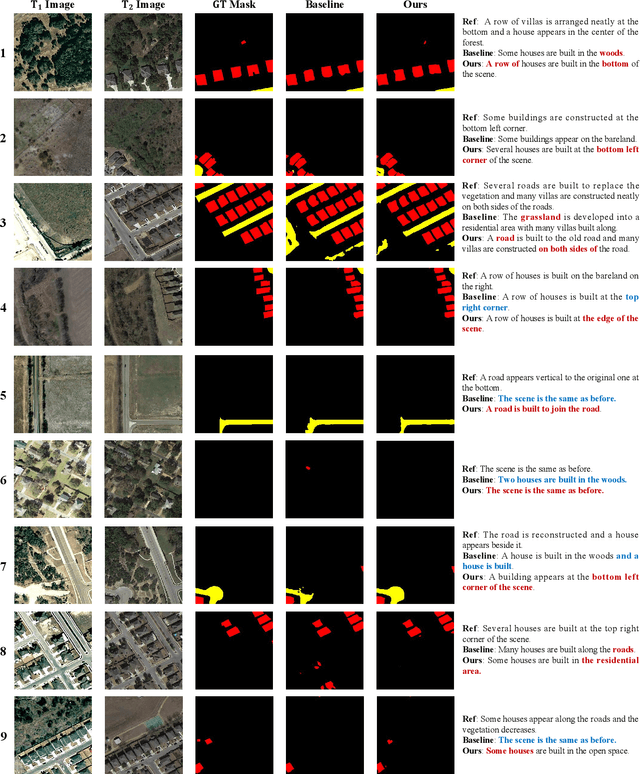
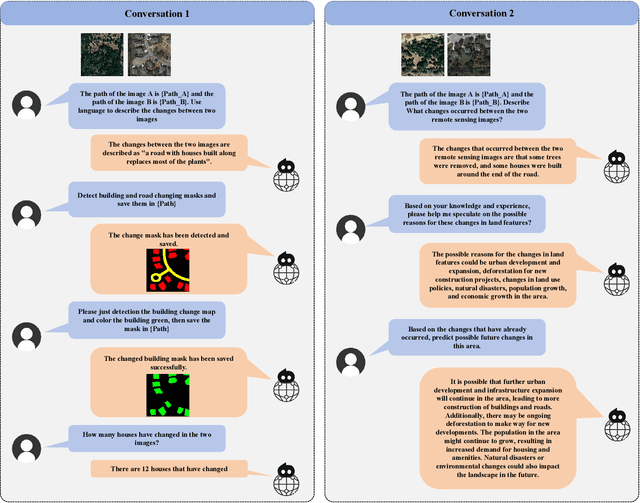
Monitoring changes in the Earth's surface is crucial for understanding natural processes and human impacts, necessitating precise and comprehensive interpretation methodologies. Remote sensing satellite imagery offers a unique perspective for monitoring these changes, leading to the emergence of remote sensing image change interpretation (RSICI) as a significant research focus. Current RSICI technology encompasses change detection and change captioning, each with its limitations in providing comprehensive interpretation. To address this, we propose an interactive Change-Agent, which can follow user instructions to achieve comprehensive change interpretation and insightful analysis according to user instructions, such as change detection and change captioning, change object counting, change cause analysis, etc. The Change-Agent integrates a multi-level change interpretation (MCI) model as the eyes and a large language model (LLM) as the brain. The MCI model contains two branches of pixel-level change detection and semantic-level change captioning, in which multiple BI-temporal Iterative Interaction (BI3) layers utilize Local Perception Enhancement (LPE) and the Global Difference Fusion Attention (GDFA) modules to enhance the model's discriminative feature representation capabilities. To support the training of the MCI model, we build the LEVIR-MCI dataset with a large number of change masks and captions of changes. Extensive experiments demonstrate the effectiveness of the proposed MCI model and highlight the promising potential of our Change-Agent in facilitating comprehensive and intelligent interpretation of surface changes. To facilitate future research, we will make our dataset and codebase of the MCI model and Change-Agent publicly available at https://github.com/Chen-Yang-Liu/Change-Agent
Spiking Neural Networks for Fast-Moving Object Detection on Neuromorphic Hardware Devices Using an Event-Based Camera
Mar 15, 2024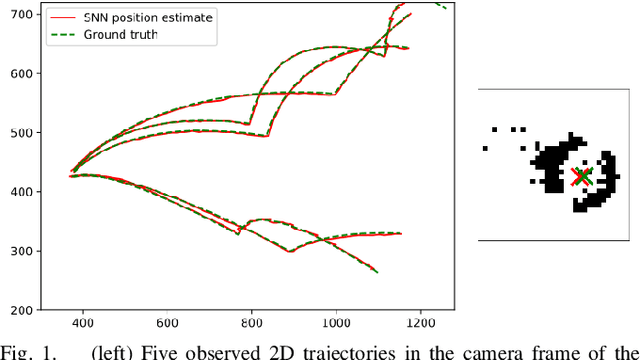
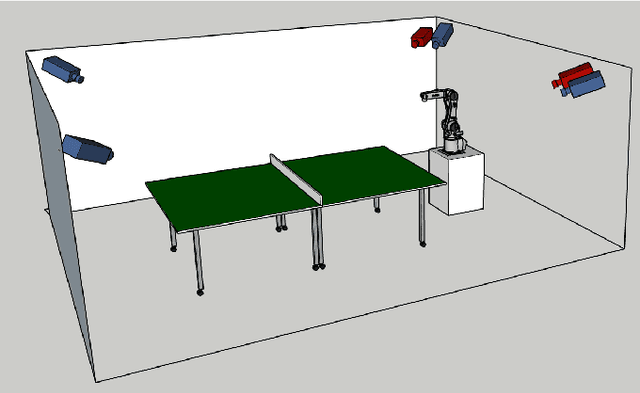
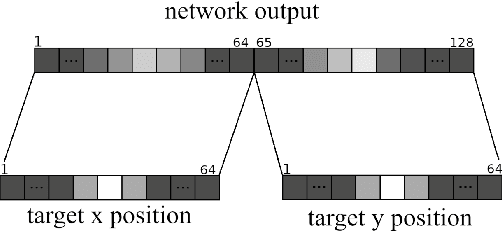
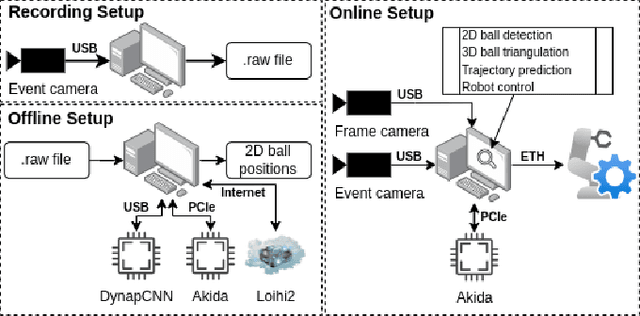
Table tennis is a fast-paced and exhilarating sport that demands agility, precision, and fast reflexes. In recent years, robotic table tennis has become a popular research challenge for robot perception algorithms. Fast and accurate ball detection is crucial for enabling a robotic arm to rally the ball back successfully. Previous approaches have employed conventional frame-based cameras with Convolutional Neural Networks (CNNs) or traditional computer vision methods. In this paper, we propose a novel solution that combines an event-based camera with Spiking Neural Networks (SNNs) for ball detection. We use multiple state-of-the-art SNN frameworks and develop a SNN architecture for each of them, complying with their corresponding constraints. Additionally, we implement the SNN solution across multiple neuromorphic edge devices, conducting comparisons of their accuracies and run-times. This furnishes robotics researchers with a benchmark illustrating the capabilities achievable with each SNN framework and a corresponding neuromorphic edge device. Next to this comparison of SNN solutions for robots, we also show that an SNN on a neuromorphic edge device is able to run in real-time in a closed loop robotic system, a table tennis robot in our use case.
Leveraging Self-Supervised Instance Contrastive Learning for Radar Object Detection
Feb 13, 2024In recent years, driven by the need for safer and more autonomous transport systems, the automotive industry has shifted toward integrating a growing number of Advanced Driver Assistance Systems (ADAS). Among the array of sensors employed for object recognition tasks, radar sensors have emerged as a formidable contender due to their abilities in adverse weather conditions or low-light scenarios and their robustness in maintaining consistent performance across diverse environments. However, the small size of radar datasets and the complexity of the labelling of those data limit the performance of radar object detectors. Driven by the promising results of self-supervised learning in computer vision, this paper presents RiCL, an instance contrastive learning framework to pre-train radar object detectors. We propose to exploit the detection from the radar and the temporal information to pre-train the radar object detection model in a self-supervised way using contrastive learning. We aim to pre-train an object detector's backbone, head and neck to learn with fewer data. Experiments on the CARRADA and the RADDet datasets show the effectiveness of our approach in learning generic representations of objects in range-Doppler maps. Notably, our pre-training strategy allows us to use only 20% of the labelled data to reach a similar mAP@0.5 than a supervised approach using the whole training set.
ManipVQA: Injecting Robotic Affordance and Physically Grounded Information into Multi-Modal Large Language Models
Mar 17, 2024
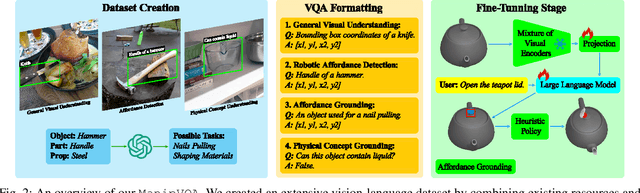


The integration of Multimodal Large Language Models (MLLMs) with robotic systems has significantly enhanced the ability of robots to interpret and act upon natural language instructions. Despite these advancements, conventional MLLMs are typically trained on generic image-text pairs, lacking essential robotics knowledge such as affordances and physical knowledge, which hampers their efficacy in manipulation tasks. To bridge this gap, we introduce ManipVQA, a novel framework designed to endow MLLMs with Manipulation-centric knowledge through a Visual Question-Answering format. This approach not only encompasses tool detection and affordance recognition but also extends to a comprehensive understanding of physical concepts. Our approach starts with collecting a varied set of images displaying interactive objects, which presents a broad range of challenges in tool object detection, affordance, and physical concept predictions. To seamlessly integrate this robotic-specific knowledge with the inherent vision-reasoning capabilities of MLLMs, we adopt a unified VQA format and devise a fine-tuning strategy that preserves the original vision-reasoning abilities while incorporating the new robotic insights. Empirical evaluations conducted in robotic simulators and across various vision task benchmarks demonstrate the robust performance of ManipVQA. Code and dataset will be made publicly available at https://github.com/SiyuanHuang95/ManipVQA.