 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Temporal Shift -- Multi-Objective Loss Function for Improved Anomaly Fall Detection
Nov 06, 2023
Falls are a major cause of injuries and deaths among older adults worldwide. Accurate fall detection can help reduce potential injuries and additional health complications. Different types of video modalities can be used in a home setting to detect falls, including RGB, Infrared, and Thermal cameras. Anomaly detection frameworks using autoencoders and their variants can be used for fall detection due to the data imbalance that arises from the rarity and diversity of falls. However, the use of reconstruction error in autoencoders can limit the application of networks' structures that propagate information. In this paper, we propose a new multi-objective loss function called Temporal Shift, which aims to predict both future and reconstructed frames within a window of sequential frames. The proposed loss function is evaluated on a semi-naturalistic fall detection dataset containing multiple camera modalities. The autoencoders were trained on normal activities of daily living (ADL) performed by older adults and tested on ADLs and falls performed by young adults. Temporal shift shows significant improvement to a baseline 3D Convolutional autoencoder, an attention U-Net CAE, and a multi-modal neural network. The greatest improvement was observed in an attention U-Net model improving by 0.20 AUC ROC for a single camera when compared to reconstruction alone. With significant improvement across different models, this approach has the potential to be widely adopted and improve anomaly detection capabilities in other settings besides fall detection.
Neural Distributed Compressor Discovers Binning
Oct 25, 2023
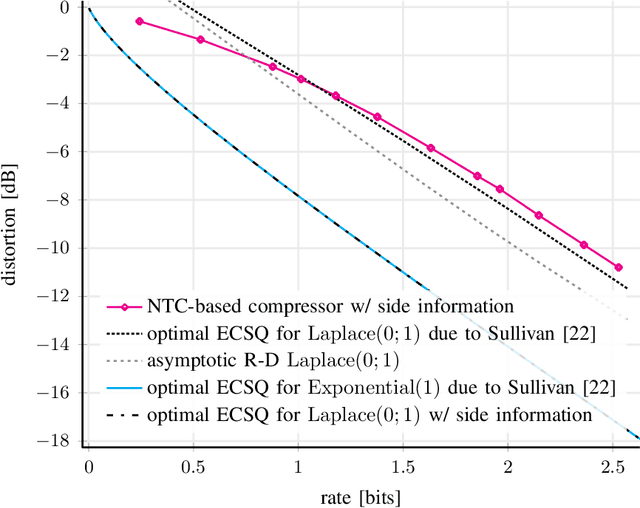
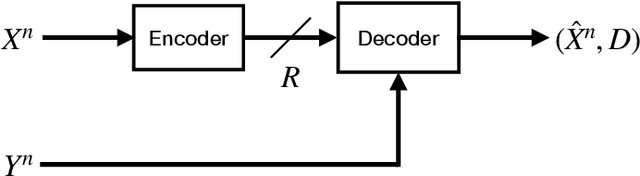
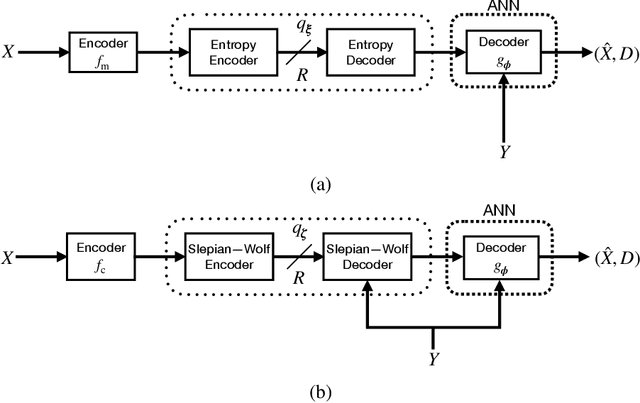
We consider lossy compression of an information source when the decoder has lossless access to a correlated one. This setup, also known as the Wyner-Ziv problem, is a special case of distributed source coding. To this day, practical approaches for the Wyner-Ziv problem have neither been fully developed nor heavily investigated. We propose a data-driven method based on machine learning that leverages the universal function approximation capability of artificial neural networks. We find that our neural network-based compression scheme, based on variational vector quantization, recovers some principles of the optimum theoretical solution of the Wyner-Ziv setup, such as binning in the source space as well as optimal combination of the quantization index and side information, for exemplary sources. These behaviors emerge although no structure exploiting knowledge of the source distributions was imposed. Binning is a widely used tool in information theoretic proofs and methods, and to our knowledge, this is the first time it has been explicitly observed to emerge from data-driven learning.
Non-isotropic Persistent Homology: Leveraging the Metric Dependency of PH
Oct 25, 2023Persistent Homology is a widely used topological data analysis tool that creates a concise description of the topological properties of a point cloud based on a specified filtration. Most filtrations used for persistent homology depend (implicitly) on a chosen metric, which is typically agnostically chosen as the standard Euclidean metric on $\mathbb{R}^n$. Recent work has tried to uncover the 'true' metric on the point cloud using distance-to-measure functions, in order to obtain more meaningful persistent homology results. Here we propose an alternative look at this problem: we posit that information on the point cloud is lost when restricting persistent homology to a single (correct) distance function. Instead, we show how by varying the distance function on the underlying space and analysing the corresponding shifts in the persistence diagrams, we can extract additional topological and geometrical information. Finally, we numerically show that non-isotropic persistent homology can extract information on orientation, orientational variance, and scaling of randomly generated point clouds with good accuracy and conduct some experiments on real-world data.
Enhancing Graph Neural Networks with Structure-Based Prompt
Oct 26, 2023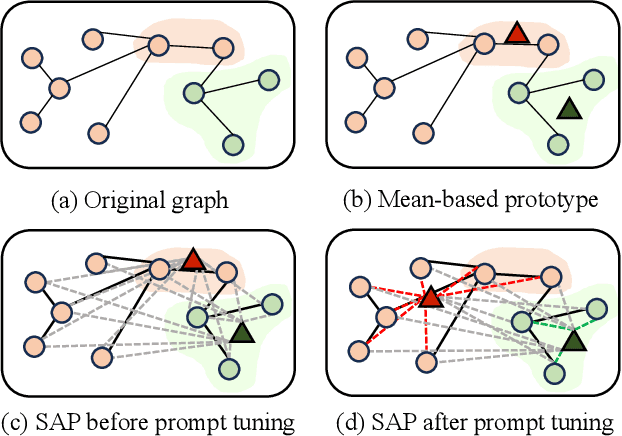
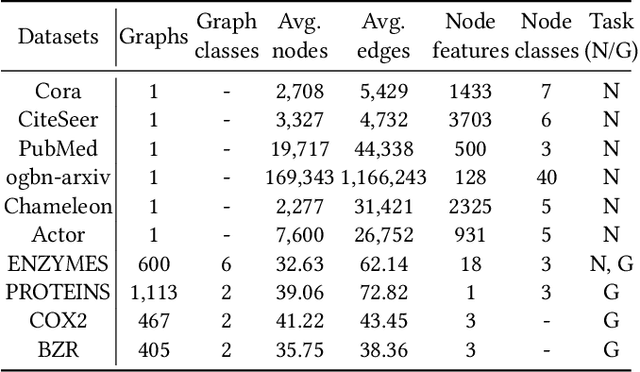
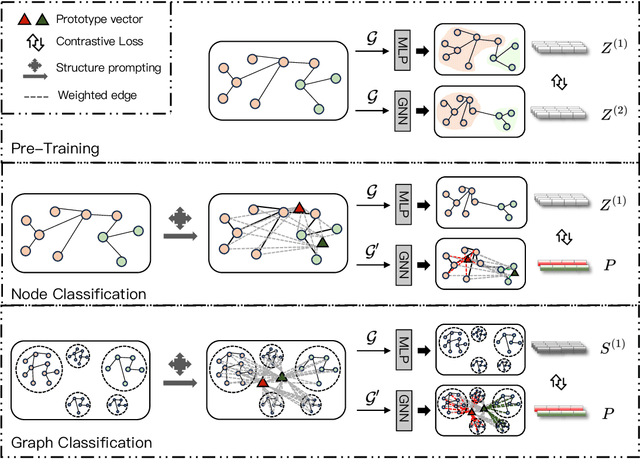
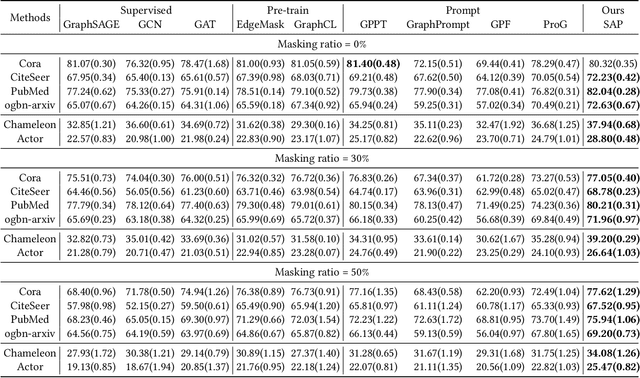
Graph Neural Networks (GNNs) are powerful in learning semantics of graph data. Recently, a new paradigm "pre-train, prompt" has shown promising results in adapting GNNs to various tasks with less supervised data. The success of such paradigm can be attributed to the more consistent objectives of pre-training and task-oriented prompt tuning, where the pre-trained knowledge can be effectively transferred to downstream tasks. However, an overlooked issue of existing studies is that the structure information of graph is usually exploited during pre-training for learning node representations, while neglected in the prompt tuning stage for learning task-specific parameters. To bridge this gap, we propose a novel structure-based prompting method for GNNs, namely SAP, which consistently exploits structure information in both pre-training and prompt tuning stages. In particular, SAP 1) employs a dual-view contrastive learning to align the latent semantic spaces of node attributes and graph structure, and 2) incorporates structure information in prompted graph to elicit more pre-trained knowledge in prompt tuning. We conduct extensive experiments on node classification and graph classification tasks to show the effectiveness of SAP. Moreover, we show that SAP can lead to better performance in more challenging few-shot scenarios on both homophilous and heterophilous graphs.
DP-SGD with weight clipping
Oct 27, 2023Recently, due to the popularity of deep neural networks and other methods whose training typically relies on the optimization of an objective function, and due to concerns for data privacy, there is a lot of interest in differentially private gradient descent methods. To achieve differential privacy guarantees with a minimum amount of noise, it is important to be able to bound precisely the sensitivity of the information which the participants will observe. In this study, we present a novel approach that mitigates the bias arising from traditional gradient clipping. By leveraging public information concerning the current global model and its location within the search domain, we can achieve improved gradient bounds, leading to enhanced sensitivity determinations and refined noise level adjustments. We extend the state of the art algorithms, present improved differential privacy guarantees requiring less noise and present an empirical evaluation.
PET Tracer Conversion among Brain PET via Variable Augmented Invertible Network
Nov 01, 2023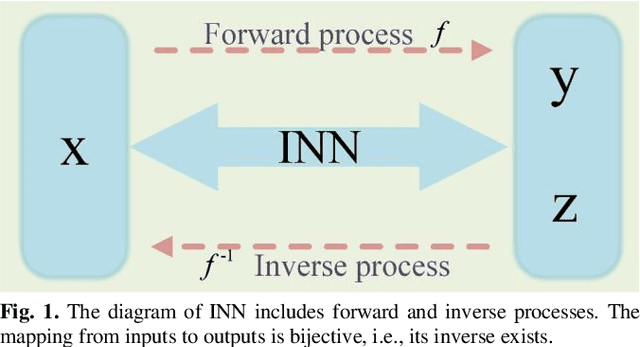
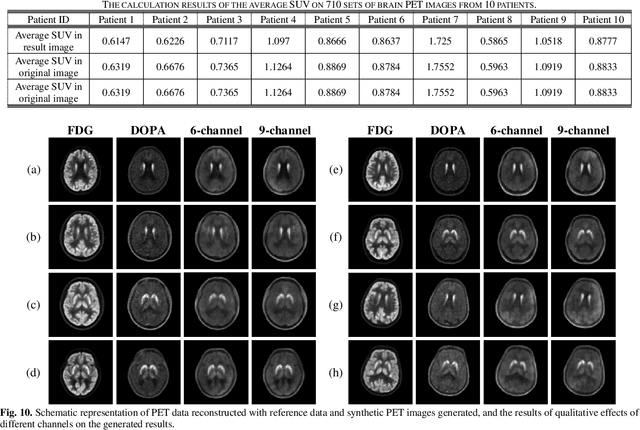
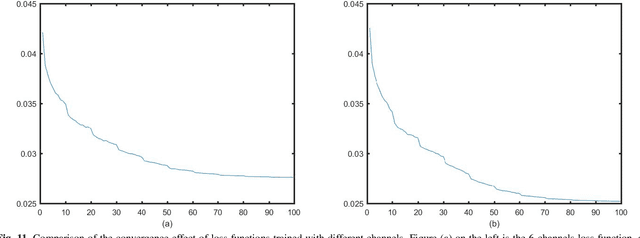
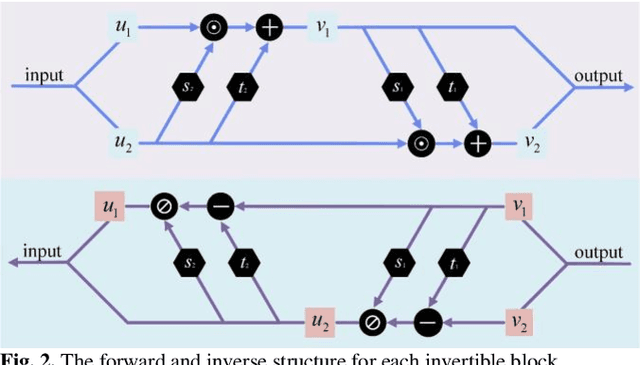
Positron emission tomography (PET), as an imaging technique with high biochemical sensitivity, has been widely used in diagnosis of encephalopathy and brain science research used in brain disease diagnosis and brain science research. Since different tracers present different effects on the same focal area, the choice of tracers is getting more significant for PET imaging. Nowadays, with the wide application of PET imaging in neuropsychiatric treatment, 6-18F-fluoro-3, 4-dihydroxy-L-phenylalanine (DOPA) has been found to be more effective than 18F-labeled fluorine-2-deoxyglucose (FDG) in this field. However, due to the complexity of its preparation and other limitations, DOPA is far less widely used than FDG. To address this issue, a tracer conversion invertible neural network (TC-INN) for image projection is developed to map FDG images to DOPA images through deep learning. More diagnostic information is obtained by generating PET images from FDG to DOPA. Specifically, the proposed TC-INN consists of two separate phases, one for training the traceable data, the other for re-building the new data. The reference DOPA PET image is used as the learning target for the corresponding network during the training process of tracer conversion. Mean-while, the invertible network iteratively estimates the resultant DOPA PET data and compares it to the reference DOPA PET data. Notably, the reversible model employed variable enhancement techniques to achieve better power generation. Moreover, image registration needs to be performed before training due to the angular deviation of the acquired FDG and DOPA data information. Experimental results show generative ability in mapping be-tween FDG images and DOPA images. It demonstrates great potential for PET image conversion in the case of limited tracer applications.
Enhancing Monocular Height Estimation from Aerial Images with Street-view Images
Nov 03, 2023Accurate height estimation from monocular aerial imagery presents a significant challenge due to its inherently ill-posed nature. This limitation is rooted in the absence of adequate geometric constraints available to the model when training with monocular imagery. Without additional geometric information to supplement the monocular image data, the model's ability to provide reliable estimations is compromised. In this paper, we propose a method that enhances monocular height estimation by incorporating street-view images. Our insight is that street-view images provide a distinct viewing perspective and rich structural details of the scene, serving as geometric constraints to enhance the performance of monocular height estimation. Specifically, we aim to optimize an implicit 3D scene representation, density field, with geometry constraints from street-view images, thereby improving the accuracy and robustness of height estimation. Our experimental results demonstrate the effectiveness of our proposed method, outperforming the baseline and offering significant improvements in terms of accuracy and structural consistency.
MixCon3D: Synergizing Multi-View and Cross-Modal Contrastive Learning for Enhancing 3D Representation
Nov 03, 2023Contrastive learning has emerged as a promising paradigm for 3D open-world understanding, jointly with text, image, and point cloud. In this paper, we introduce MixCon3D, which combines the complementary information between 2D images and 3D point clouds to enhance contrastive learning. With the further integration of multi-view 2D images, MixCon3D enhances the traditional tri-modal representation by offering a more accurate and comprehensive depiction of real-world 3D objects and bolstering text alignment. Additionally, we pioneer the first thorough investigation of various training recipes for the 3D contrastive learning paradigm, building a solid baseline with improved performance. Extensive experiments conducted on three representative benchmarks reveal that our method renders significant improvement over the baseline, surpassing the previous state-of-the-art performance on the challenging 1,156-category Objaverse-LVIS dataset by 5.7%. We further showcase the effectiveness of our approach in more applications, including text-to-3D retrieval and point cloud captioning. The code is available at https://github.com/UCSC-VLAA/MixCon3D.
Grounded Intuition of GPT-Vision's Abilities with Scientific Images
Nov 03, 2023
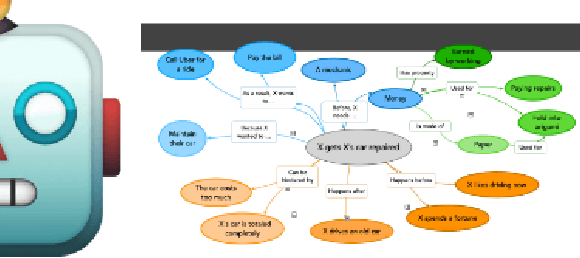


GPT-Vision has impressed us on a range of vision-language tasks, but it comes with the familiar new challenge: we have little idea of its capabilities and limitations. In our study, we formalize a process that many have instinctively been trying already to develop "grounded intuition" of this new model. Inspired by the recent movement away from benchmarking in favor of example-driven qualitative evaluation, we draw upon grounded theory and thematic analysis in social science and human-computer interaction to establish a rigorous framework for qualitative evaluation in natural language processing. We use our technique to examine alt text generation for scientific figures, finding that GPT-Vision is particularly sensitive to prompting, counterfactual text in images, and relative spatial relationships. Our method and analysis aim to help researchers ramp up their own grounded intuitions of new models while exposing how GPT-Vision can be applied to make information more accessible.
Revealing CNN Architectures via Side-Channel Analysis in Dataflow-based Inference Accelerators
Nov 01, 2023Convolution Neural Networks (CNNs) are widely used in various domains. Recent advances in dataflow-based CNN accelerators have enabled CNN inference in resource-constrained edge devices. These dataflow accelerators utilize inherent data reuse of convolution layers to process CNN models efficiently. Concealing the architecture of CNN models is critical for privacy and security. This paper evaluates memory-based side-channel information to recover CNN architectures from dataflow-based CNN inference accelerators. The proposed attack exploits spatial and temporal data reuse of the dataflow mapping on CNN accelerators and architectural hints to recover the structure of CNN models. Experimental results demonstrate that our proposed side-channel attack can recover the structures of popular CNN models, namely Lenet, Alexnet, and VGGnet16.