 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Metric Learning for Deflating Data Bias
Jul 05, 2024Image classification is an essential part of computer vision which assigns a given input image to a specific category based on the similarity evaluation within given criteria. While promising classifiers can be obtained through deep learning models, these approaches lack explainability, where the classification results are hard to interpret in a human-understandable way. In this paper, we present an explainable metric learning framework, which constructs hierarchical levels of semantic segments of an image for better interpretability. The key methodology involves a bottom-up learning strategy, starting by training the local metric learning model for the individual segments and then combining segments to compose comprehensive metrics in a tree. Specifically, our approach enables a more human-understandable similarity measurement between two images based on the semantic segments within it, which can be utilized to generate new samples to reduce bias in a training dataset. Extensive experimental evaluation demonstrates that the proposed approach can drastically improve model accuracy compared with state-of-the-art methods.
Fast Quantum Process Tomography via Riemannian Gradient Descent
Apr 29, 2024Constrained optimization plays a crucial role in the fields of quantum physics and quantum information science and becomes especially challenging for high-dimensional complex structure problems. One specific issue is that of quantum process tomography, in which the goal is to retrieve the underlying quantum process based on a given set of measurement data. In this paper, we introduce a modified version of stochastic gradient descent on a Riemannian manifold that integrates recent advancements in numerical methods for Riemannian optimization. This approach inherently supports the physically driven constraints of a quantum process, takes advantage of state-of-the-art large-scale stochastic objective optimization, and has superior performance to traditional approaches such as maximum likelihood estimation and projected least squares. The data-driven approach enables accurate, order-of-magnitude faster results, and works with incomplete data. We demonstrate our approach on simulations of quantum processes and in hardware by characterizing an engineered process on quantum computers.
Privacy-Preserving Debiasing using Data Augmentation and Machine Unlearning
Apr 19, 2024Data augmentation is widely used to mitigate data bias in the training dataset. However, data augmentation exposes machine learning models to privacy attacks, such as membership inference attacks. In this paper, we propose an effective combination of data augmentation and machine unlearning, which can reduce data bias while providing a provable defense against known attacks. Specifically, we maintain the fairness of the trained model with diffusion-based data augmentation, and then utilize multi-shard unlearning to remove identifying information of original data from the ML model for protection against privacy attacks. Experimental evaluation across diverse datasets demonstrates that our approach can achieve significant improvements in bias reduction as well as robustness against state-of-the-art privacy attacks.
Revealing CNN Architectures via Side-Channel Analysis in Dataflow-based Inference Accelerators
Nov 01, 2023Convolution Neural Networks (CNNs) are widely used in various domains. Recent advances in dataflow-based CNN accelerators have enabled CNN inference in resource-constrained edge devices. These dataflow accelerators utilize inherent data reuse of convolution layers to process CNN models efficiently. Concealing the architecture of CNN models is critical for privacy and security. This paper evaluates memory-based side-channel information to recover CNN architectures from dataflow-based CNN inference accelerators. The proposed attack exploits spatial and temporal data reuse of the dataflow mapping on CNN accelerators and architectural hints to recover the structure of CNN models. Experimental results demonstrate that our proposed side-channel attack can recover the structures of popular CNN models, namely Lenet, Alexnet, and VGGnet16.
Breaking NoC Anonymity using Flow Correlation Attack
Sep 27, 2023



Network-on-Chip (NoC) is widely used as the internal communication fabric in today's multicore System-on-Chip (SoC) designs. Security of the on-chip communication is crucial because exploiting any vulnerability in shared NoC would be a goldmine for an attacker. NoC security relies on effective countermeasures against diverse attacks. We investigate the security strength of existing anonymous routing protocols in NoC architectures. Specifically, this paper makes two important contributions. We show that the existing anonymous routing is vulnerable to machine learning (ML) based flow correlation attacks on NoCs. We propose a lightweight anonymous routing that use traffic obfuscation techniques which can defend against ML-based flow correlation attacks. Experimental studies using both real and synthetic traffic reveal that our proposed attack is successful against state-of-the-art anonymous routing in NoC architectures with a high accuracy (up to 99%) for diverse traffic patterns, while our lightweight countermeasure can defend against ML-based attacks with minor hardware and performance overhead.
Hardware Acceleration of Explainable Artificial Intelligence
May 04, 2023



Machine learning (ML) is successful in achieving human-level artificial intelligence in various fields. However, it lacks the ability to explain an outcome due to its black-box nature. While recent efforts on explainable AI (XAI) has received significant attention, most of the existing solutions are not applicable in real-time systems since they map interpretability as an optimization problem, which leads to numerous iterations of time-consuming complex computations. Although there are existing hardware-based acceleration framework for XAI, they are implemented through FPGA and designed for specific tasks, leading to expensive cost and lack of flexibility. In this paper, we propose a simple yet efficient framework to accelerate various XAI algorithms with existing hardware accelerators. Specifically, this paper makes three important contributions. (1) The proposed method is the first attempt in exploring the effectiveness of Tensor Processing Unit (TPU) to accelerate XAI. (2) Our proposed solution explores the close relationship between several existing XAI algorithms with matrix computations, and exploits the synergy between convolution and Fourier transform, which takes full advantage of TPU's inherent ability in accelerating matrix computations. (3) Our proposed approach can lead to real-time outcome interpretation. Extensive experimental evaluation demonstrates that proposed approach deployed on TPU can provide drastic improvement in interpretation time (39x on average) as well as energy efficiency (69x on average) compared to existing acceleration techniques.
Backdoor Attacks on Bayesian Neural Networks using Reverse Distribution
May 18, 2022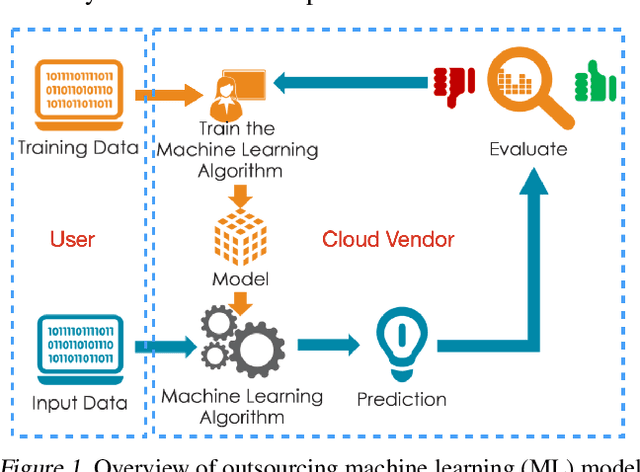

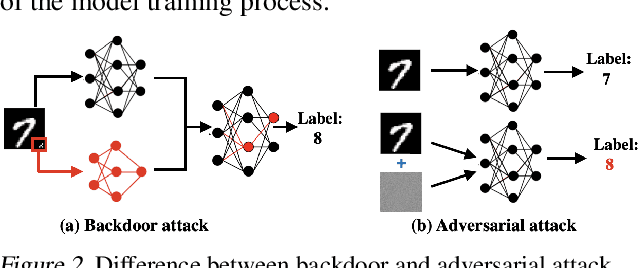
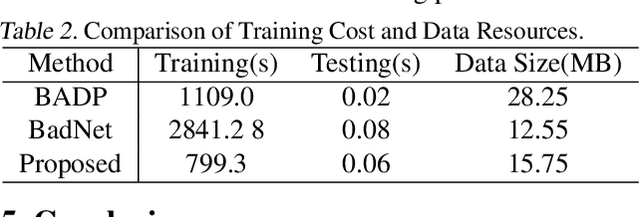
Due to cost and time-to-market constraints, many industries outsource the training process of machine learning models (ML) to third-party cloud service providers, popularly known as ML-asa-Service (MLaaS). MLaaS creates opportunity for an adversary to provide users with backdoored ML models to produce incorrect predictions only in extremely rare (attacker-chosen) scenarios. Bayesian neural networks (BNN) are inherently immune against backdoor attacks since the weights are designed to be marginal distributions to quantify the uncertainty. In this paper, we propose a novel backdoor attack based on effective learning and targeted utilization of reverse distribution. This paper makes three important contributions. (1) To the best of our knowledge, this is the first backdoor attack that can effectively break the robustness of BNNs. (2) We produce reverse distributions to cancel the original distributions when the trigger is activated. (3) We propose an efficient solution for merging probability distributions in BNNs. Experimental results on diverse benchmark datasets demonstrate that our proposed attack can achieve the attack success rate (ASR) of 100%, while the ASR of the state-of-the-art attacks is lower than 60%.
Fast Approximate Spectral Normalization for Robust Deep Neural Networks
Mar 22, 2021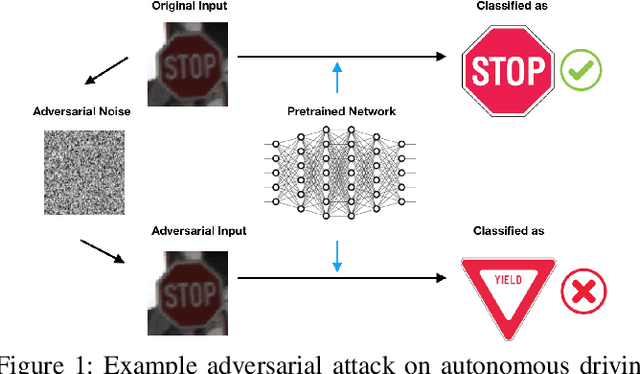
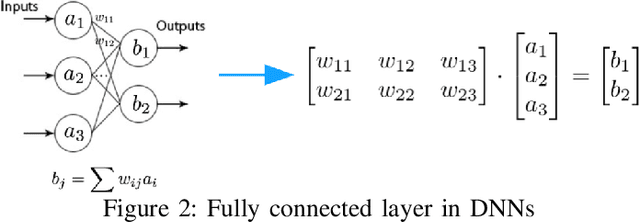
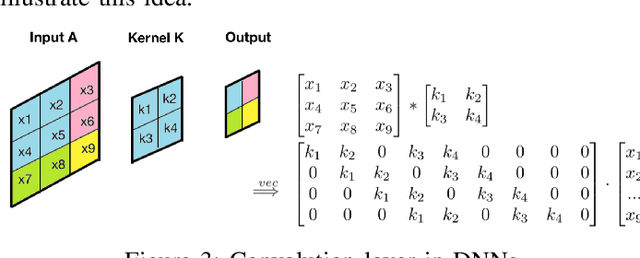
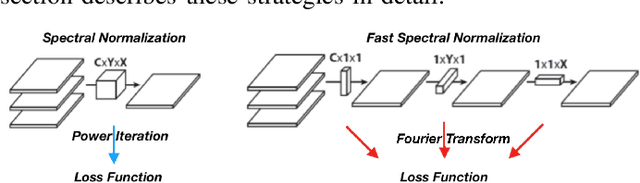
Deep neural networks (DNNs) play an important role in machine learning due to its outstanding performance compared to other alternatives. However, DNNs are not suitable for safety-critical applications since DNNs can be easily fooled by well-crafted adversarial examples. One promising strategy to counter adversarial attacks is to utilize spectral normalization, which ensures that the trained model has low sensitivity towards the disturbance of input samples. Unfortunately, this strategy requires exact computation of spectral norm, which is computation intensive and impractical for large-scale networks. In this paper, we introduce an approximate algorithm for spectral normalization based on Fourier transform and layer separation. The primary contribution of our work is to effectively combine the sparsity of weight matrix and decomposability of convolution layers. Extensive experimental evaluation demonstrates that our framework is able to significantly improve both time efficiency (up to 60\%) and model robustness (61\% on average) compared with the state-of-the-art spectral normalization.
Hardware Acceleration of Explainable Machine Learning using Tensor Processing Units
Mar 22, 2021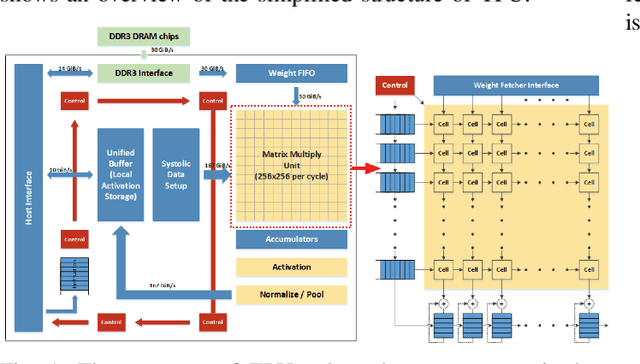
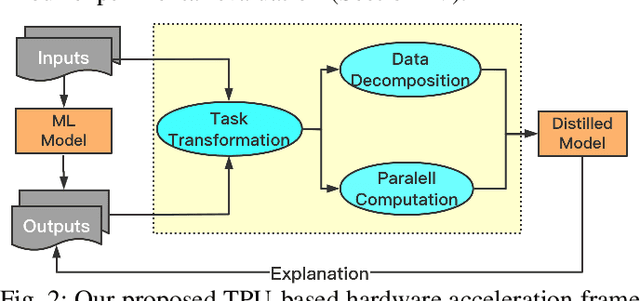
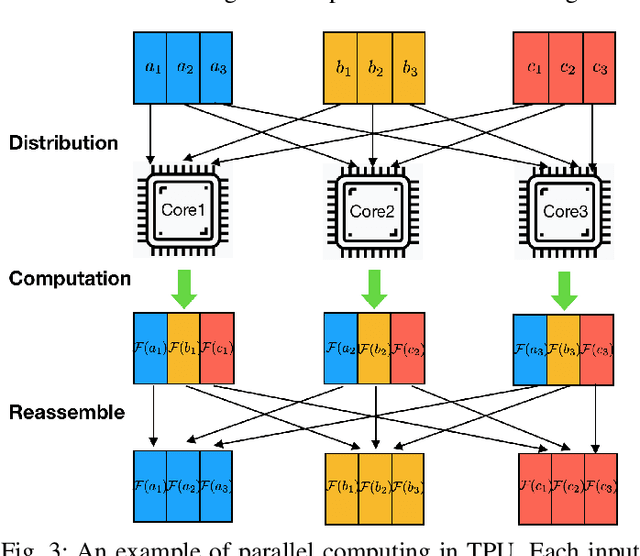
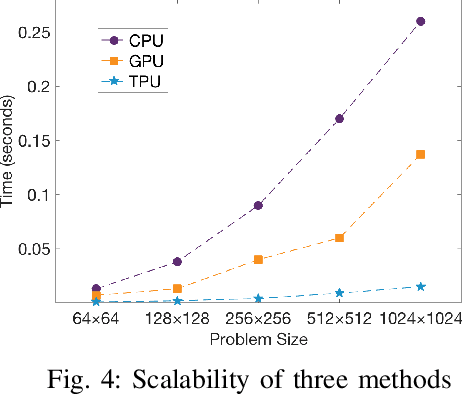
Machine learning (ML) is successful in achieving human-level performance in various fields. However, it lacks the ability to explain an outcome due to its black-box nature. While existing explainable ML is promising, almost all of these methods focus on formatting interpretability as an optimization problem. Such a mapping leads to numerous iterations of time-consuming complex computations, which limits their applicability in real-time applications. In this paper, we propose a novel framework for accelerating explainable ML using Tensor Processing Units (TPUs). The proposed framework exploits the synergy between matrix convolution and Fourier transform, and takes full advantage of TPU's natural ability in accelerating matrix computations. Specifically, this paper makes three important contributions. (1) To the best of our knowledge, our proposed work is the first attempt in enabling hardware acceleration of explainable ML using TPUs. (2) Our proposed approach is applicable across a wide variety of ML algorithms, and effective utilization of TPU-based acceleration can lead to real-time outcome interpretation. (3) Extensive experimental results demonstrate that our proposed approach can provide an order-of-magnitude speedup in both classification time (25x on average) and interpretation time (13x on average) compared to state-of-the-art techniques.